
web自动化
- 随着互联网的发展,前端技术也在不断变化,数据的加载方式也不再是单纯的服务端渲染了。 - 现在你可以看到很多网站的数据可能都是通过接口的形式传输的,- 或者即使不是接口那也是一些 JSON 的数据,然后经过 JavaScript 渲染得出来的。
- 这时,如果你还用 requests 来爬取内容,那就不管用了。 - 因为 requests 爬取下来的只能是服务器端网页的源码,这和浏览器渲染以后的页面内容是不一样的。- 因为,真正的数据是经过 JavaScript 执行后,渲染出来的,数据来源可能是 Ajax,也可能是页面里的某些 Data,或者是一些 ifame 页面等。- 不过,大多数情况下极有可能是 Ajax 接口获取的。
- 所以,很多情况我们需要分析 Ajax请求,分析这些接口的调用方式,通过抓包工具或者浏览器的“开发者工具”,找到数据的请求链接,然后再用程序来模拟。 - 但是,抓包分析流的方式,也存在一定的缺点。- 因为有些接口带着加密参数,比如 token、sign 等等,模拟难度较大;
- 那有没有一种简单粗暴的方法, - 这时 Puppeteer、Pyppeteer、Selenium、Splash 等自动化框架出现了。- 使用这些框架获取HTML源码,这样我们爬取到的源代码就是JavaScript 渲染以后的真正的网页代码,数据自然就好提取了。- 同时,也就绕过分析 Ajax 和一些 JavaScript 逻辑的过程。- 这种方式就做到了可见即可爬,难度也不大,同时适合大批量的采集。
- Selenium: - 作为一款知名的Web自动化测试框架,支持大部分主流浏览器,提供了功能丰富的API接口,常常被我们用作爬虫工具来使用。- 然而selenium的缺点也很明显 - 速度太慢- 对版本配置要求严苛- 最麻烦是经常要更新对应的驱动
【一】selenium
【1】安装
- 由于sleenium4.1.0需要python3.7以上方可支持,请注意自己的python版本。
方式一:pip安装
- Python3.x安装后就默认就会有pip(pip.exe默认在python的Scripts路径下),
- 打开 cmd,使用pip安装。
pip install selenium
- 首次安装会有进度条,而且装出来是多个包(依赖于其他第三方库)。
- 如果安装慢(默认连接官网),可以指定国内源。
pip install selenium -i https://mirrors.aliyun.com/pypi/simple/
方式二:Pycharm安装
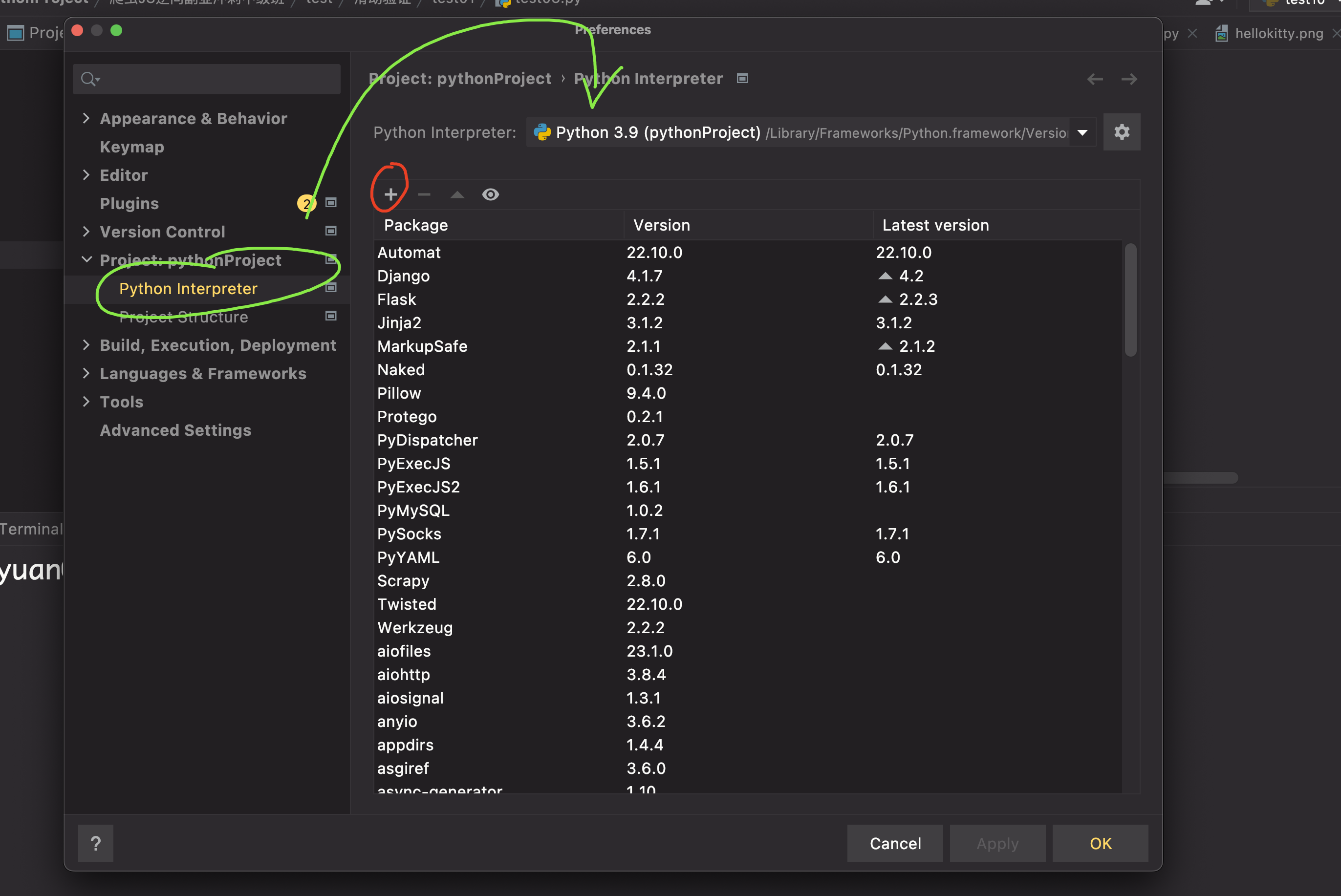
- Pycharm-File-Setting-Project:xxxx-Python Interpreter,点击+号
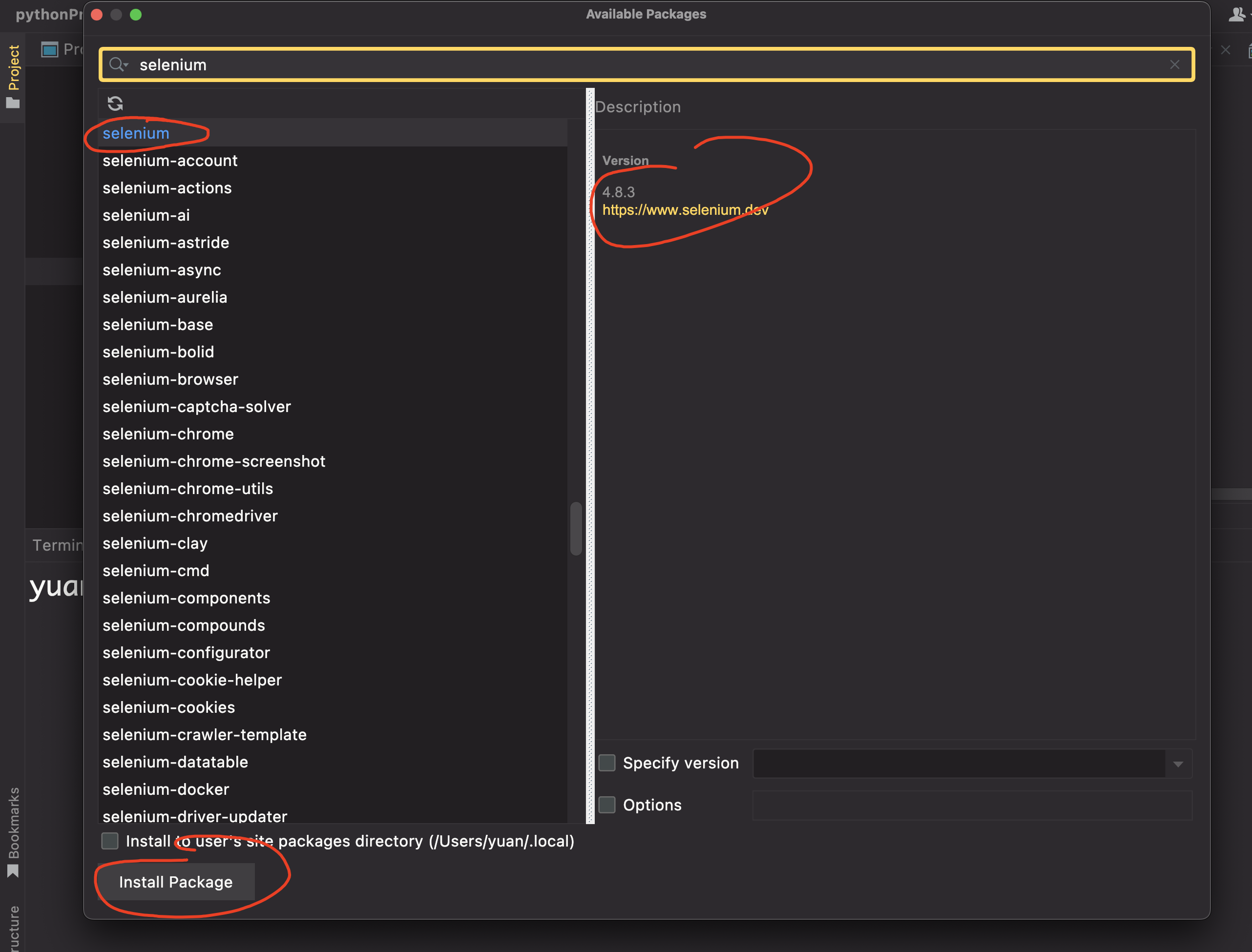

安装chrome驱动
- chrome驱动地址: - http://chromedriver.storage.googleapis.com/index.html
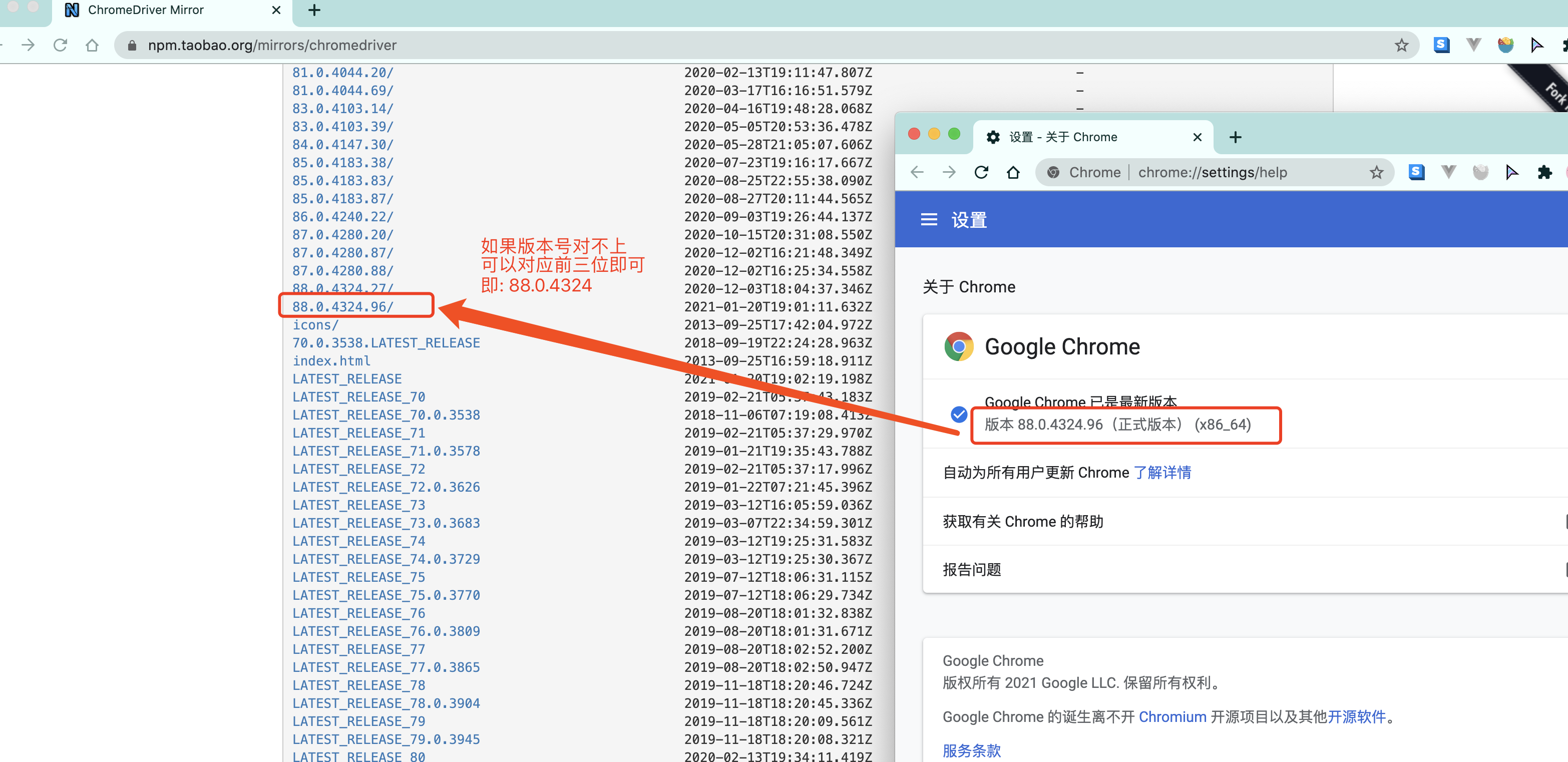
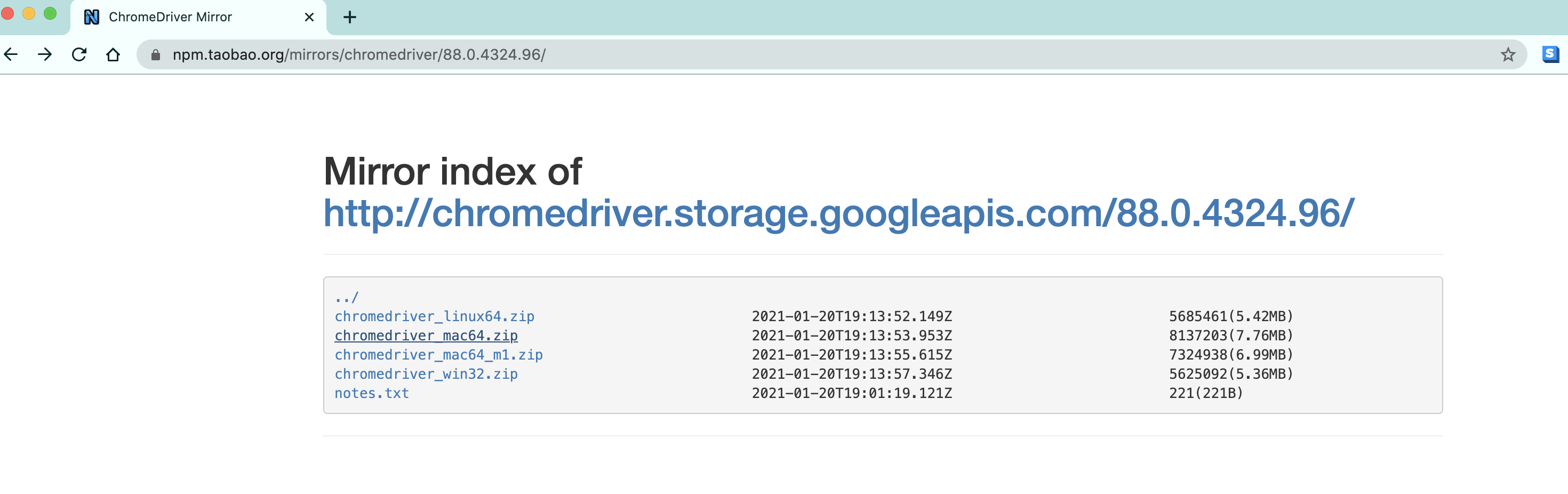
- 根据你电脑的不同自行选择吧. - win64选win32即可.- 把你下载的浏览器驱动放在python解释器所在的文件夹
【2】quick start
- selenium最初是一个自动化测试工具,- 而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题- selenium本质是通过驱动浏览器,完全模拟浏览器的操作,- 比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器
- 安装pip包
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple selenium
- 案例:
from selenium import webdriver
from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys # 键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素
# executable_path : 可以指定驱动位置
# chrome = webdriver.Chrome(executable_path='./chromedriver.exe')
# 也可以将驱动加到环境变量中,自动检索驱动位置
chrome = webdriver.Chrome()
try:
# 自动打开浏览器,请求目标网址
chrome.get('https://www.jd.com')
# 找到搜索框对应的标签
input_tag = chrome.find_element(By.ID, 'key')
# 自动传入关键字
input_tag.send_keys('hellokitty')
# 自动回车(搜索)
# 也可以找到搜索标签 btn.click
input_tag.send_keys(Keys.ENTER)
wait = WebDriverWait(chrome, 10)
# time.sleep(3)
# 等到id为J_goodsList的元素加载完毕,最多等10秒
wait.until(EC.presence_of_element_located((By.ID, 'J_goodsList')))
chrome.save_screenshot("hellokitty.png")
finally:
# 关闭浏览器页面
chrome.close()
【3】元素定位
(1)方式1
el = driver.find_element_by_xxx(value)
(2)方式2(推荐)
from selenium.webdriver.common.by import By
driver.find_element(By.xxx,value)
driver.find_elements(By.xx, value) # 返回列表
(3)定位元素的八种方式:
id
name
class
tag
link
partial
xpath
css
(4)八种方式示例
[1]ID 定位(通过元素的 ID 属性进行定位):
element = bro.find_element(By.ID, 'element_id')
- 使用
find_element方法,通过元素的 ID 属性进行定位。- 将
'element_id'替换为你要查找的元素的实际 ID。
[2]Name 定位(通过元素的 Name 属性进行定位):
element = bro.find_element(By.NAME, 'element_name')
- 使用
find_element方法,通过元素的 Name 属性进行定位。- 将
'element_name'替换为你要查找的元素的实际 Name。
[3]Class 定位(通过元素的 Class 属性进行定位):
element = bro.find_element(By.CLASS_NAME, 'element_class')
- 使用
find_element方法,通过元素的 Class 属性进行定位。- 将
'element_class'替换为你要查找的元素的实际 Class。
[4]Tag 定位(通过标签名进行定位):
elements = bro.find_elements(By.TAG_NAME, 'div')
- 使用
find_elements方法,通过标签名进行定位。- 将
'div'替换为你要查找的具体标签名,如'a'、'span'。
[5]Link 文字定位(精确定位):
element = bro.find_element(By.LINK_TEXT, 'link_text')
- 使用
find_element方法,通过链接文字进行精确定位。- 将
'link_text'替换为你要查找的链接文字。
[6]Partial Link 文字定位(模糊定位):
element = bro.find_element(By.PARTIAL_LINK_TEXT, 'partial_link_text')
- 使用
find_element方法,通过链接文字进行模糊定位。- 将
'partial_link_text'替换为你要查找的部分链接文字。
[7]XPath 定位(XPath 表达式进行定位):
element = bro.find_element(By.XPATH, 'xpath_expression')
- 使用
find_element方法,通过 XPath 表达式进行定位。- 将
'xpath_expression'替换为你要使用的实际 XPath 表达式。
[8]CSS 选择器定位:
element = bro.find_element(By.CSS_SELECTOR, 'css_selector')
- 使用
find_element方法,通过 CSS 选择器进行定位。- 将
'css_selector'替换为你要使用的实际 CSS 选择器。
[9]注意
- 以上示例中的定位方式都是通过
find_element或find_elements方法配合相应的定位器(如 By.ID、By.NAME 等)来定位元素。 -find_element方法返回第一个匹配到的元素-find_elements方法返回所有匹配到的元素的列表。
【4】元素操作(节点交互)
- Selenium可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。 - 比较常见的用法有: - 输入文字时用
send_keys()方法,- 清空文字时用clear()方法,- 点击按钮时用click()方法。- 示例如下:
find_element方法仅仅能够获取元素对象,接下来就可以对元素执行以下操作 从定位到的元素中提取数据的方法
(1)从定位到的元素中获取数据
el.get_attribute(key) # 获取key属性名对应的属性值
el.text # 获取开闭标签之间的文本内容
(2)对定位到的元素的操作
el.click() # 对元素执行点击操作
el.submit() # 对元素执行提交操作
el.clear() # 清空可输入元素中的数据
el.send_keys(data) # 向可输入元素输入数据
【模拟登陆百度账号】
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
# 创建 Chrome 浏览器实例
bro = webdriver.Chrome()
bro.get('https://www.baidu.com') # 打开百度首页
# 隐式等待,设置为 10 秒,即最多等待 10 秒
bro.implicitly_wait(10)
# 最大化浏览器窗口
bro.maximize_window()
# 找到登录按钮并点击
# 如果是a标签,可以根据a标签文字找
submit_login = bro.find_element(By.LINK_TEXT, '登录')
submit_login.click()
# 点击短信登录选项
sms_login = bro.find_element(By.ID, 'TANGRAM__PSP_11__headerLoginTab')
sms_login.click()
time.sleep(1) # 等待 1 秒
# 切换到用户名密码登录方式
username_login = bro.find_element(By.ID, 'TANGRAM__PSP_11__changePwdCodeItem')
username_login.click()
time.sleep(1) # 等待 1 秒
# 输入用户名和密码
username = bro.find_element(By.ID, 'TANGRAM__PSP_11__userName')
username.send_keys('206**[email protected]')
password = bro.find_element(By.ID, 'TANGRAM__PSP_11__password')
password.send_keys('asdfasdfasdfasfds')
# 提交登录表单
login = bro.find_element(By.ID, 'TANGRAM__PSP_11__submit')
time.sleep(1) # 等待 1 秒
login.submit()
time.sleep(3) # 等待 3 秒
bro.close() # 关闭浏览器窗口
【5】动作链
- 在上面的实例中,一些交互动作都是针对某个节点执行的。 - 比如,对于输入框,我们就调用它的输入文字和清空文字方法;- 对于按钮,就调用它的点击方法。- 其实,还有另外一些操作,它们没有特定的执行对象, - 比如鼠标拖曳、键盘按键等,- 这些动作用另一种方式来执行,- 那就是动作链。
(1)方式一
actions=ActionChains(bro) #拿到动作链对象
actions.drag_and_drop(sourse,target) #把动作放到动作链中,准备串行执行
actions.perform()
(2)方式二
ActionChains(bro).click_and_hold(sourse).perform()
distance=target.location['x']-sourse.location['x']
track=0
while track < distance:
ActionChains(bro).move_by_offset(xoffset=2,yoffset=0).perform()
track+=2
(3)演示
演示一
- 比如,现在实现一个节点的拖曳操作,将某个节点从一处拖曳到另外一处,可以这样实现:
from time import sleep
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
# 初始化WebDriver并设置隐式等待时间
driver = webdriver.Chrome()
driver.implicitly_wait(10)
# 窗口最大化
driver.maximize_window()
# 打开网页
driver.get('http://sahitest.com/demo/dragDropMooTools.htm')
# 定位被拖拽元素和目标元素
dragger = driver.find_element(By.ID, 'dragger') # 被拖拽元素
item1 = driver.find_element(By.XPATH, '//div[text()="Item 1"]') # 目标元素1
item2 = driver.find_element(By.XPATH, '//div[text()="Item 2"]') # 目标2
item3 = driver.find_element(By.XPATH, '//div[text()="Item 3"]') # 目标3
item4 = driver.find_element(By.XPATH, '//div[text()="Item 4"]') # 目标4
# 创建ActionChains对象
action = ActionChains(driver)
# 1. 移动dragger到目标1
action.drag_and_drop(dragger, item1).perform()
sleep(2)
# 2. 效果与上句相同,也能起到移动效果
action.click_and_hold(dragger).release(item2).perform()
sleep(2)
# 3. 效果与上两句相同,也能起到移动的效果
action.click_and_hold(dragger).move_to_element(item3).release().perform()
sleep(2)
# 4. 移动dragger到偏移量(800, 0)的位置
action.click_and_hold(dragger).move_by_offset(800, 0).release().perform()
sleep(2)
# 关闭浏览器
driver.quit()
演示二
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素
import time
from selenium.webdriver.common.by import By
# 创建 Chrome WebDriver 实例
driver = webdriver.Chrome()
# 打开网页
driver.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
# 设置隐式等待时间为3秒
driver.implicitly_wait(3)
# 最大化窗口
driver.maximize_window()
try:
# 切换到 iframeResult 框架
driver.switch_to.frame('iframeResult')
# 获取源元素和目标元素
source = driver.find_element(By.ID, 'draggable')
target = driver.find_element(By.ID, 'droppable')
# 方式一:基于同一个动作链串行执行
# actions = ActionChains(driver) # 创建动作链对象
# actions.drag_and_drop(source, target) # 将动作添加到动作链中,准备串行执行
# actions.perform()
# 方式二:不同的动作链,每次移动的位移都不同
ActionChains(driver).click_and_hold(source).perform() # 鼠标按住源元素不放
distance = target.location['x'] - source.location['x'] # 计算鼠标需要移动的距离
track = 0
while track < distance:
ActionChains(driver).move_by_offset(xoffset=2, yoffset=0).perform() # 每次移动2个像素
track += 2
# 松开鼠标
ActionChains(driver).release().perform()
time.sleep(10) # 等待一段时间,观察效果
finally:
# 关闭浏览器窗口
driver.close()
【6】执行JS
- selenium并不是万能的,有时候页面上操作无法实现的,这时候就需要借助JS来完成了。
- 当页面上的元素超过一屏后,想操作屏幕下方的元素,是不能直接定位到,会报元素不可见的。- 这时候需要借助滚动条来拖动屏幕,使被操作的元素显示在当前的屏幕上。- 滚动条是无法直接用定位工具来定位的。- selenium里面也没有直接的方法去控制滚动条,这时候只能借助Js代码了,- 还好selenium提供了一个操作js的方法: - execute_script(),可以直接执行js的脚本。
(1)滚动到页面底部
import time
from selenium import webdriver
# 初始化WebDriver
browser = webdriver.Chrome()
# 打开京东网页
browser.get('https://www.jd.com/')
# 使用JavaScript执行滚动到页面底部的操作
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
# 等待3秒,以便页面加载完成
time.sleep(3)
(2)点击元素
python# 使用JavaScript点击一个按钮
element = browser.find_element_by_id('button_id')
browser.execute_script('arguments[0].click();', element)
- 这里使用了
execute_script方法执行JavaScript脚本来点击按钮。arguments[0]表示传递给JavaScript脚本的第一个参数(即element),通过调用click()方法实现点击操作。
(3)输入文本
python# 使用JavaScript输入文本到文本框
element = browser.find_element_by_id('input_id')
text = 'Hello, World!'
browser.execute_script('arguments[0].value = arguments[1];', element, text)
- 同样地,使用
execute_script方法执行JavaScript脚本来向文本框输入文本。arguments[0]表示传递给JavaScript脚本的第一个参数(即element),通过将value属性设置为arguments[1]来输入文本。
(4)拖动元素
python# 使用JavaScript拖动一个可拖动的元素到目标位置
source_element = browser.find_element_by_id('source_element_id')
target_element = browser.find_element_by_id('target_element_id')
browser.execute_script('''
var source = arguments[0], target = arguments[1];
var offsetX = target.getBoundingClientRect().left - source.getBoundingClientRect().left;
var offsetY = target.getBoundingClientRect().top - source.getBoundingClientRect().top;
var event = new MouseEvent('mousedown', { bubbles: true, cancelable: true, view: window });
source.dispatchEvent(event);
event = new MouseEvent('mousemove', { bubbles: true, cancelable: true, view: window, clientX: offsetX, clientY: offsetY });
source.dispatchEvent(event);
event = new MouseEvent('mouseup', { bubbles: true, cancelable: true, view: window });
source.dispatchEvent(event);
''', source_element, target_element)
- 上述示例中,我们使用
execute_script方法执行了一段JavaScript代码来实现拖动操作。- 首先,获取源元素和目标元素的位置信息,然后创建鼠标事件并分发到源元素上,模拟鼠标按下、移动和松开的动作,从而实现拖动操作。
(5)获取元素属性
python# 使用JavaScript获取元素的属性值
element = browser.find_element_by_id('element_id')
attribute_value = browser.execute_script('return arguments[0].getAttribute("attribute_name");', element)
print(attribute_value)
- 通过
execute_script方法执行JavaScript脚本来获取目标元素的属性值。- 这里使用
getAttribute方法传递属性名参数来返回对应的属性值。
【7】页面等待
(1)为什么需要等待
- 如果网站采用了动态html技术,那么页面上的部分元素出现时间便不能确定,
- 这个时候就可以设置一个等待时间,强制等待指定时间
- 等待结束之后进行元素定位,如果还是无法定位到则报错
(2)页面等待的三种方法
[1]强制等待
- 也叫线程等待, 通过线程休眠的方式完成的等待
- 如等待5秒: Thread sleep(5000)
- 一般情况下不太使用强制等待,主要应用的场景在于不同系统交互的地方。
import time
time.sleep(n) # 阻塞等待设定的秒数之后再继续往下执行
[2]显式等待
- 也称为智能等待,针对指定元素定位指定等待时间
- 在指定时间范围内进行元素查找,找到元素则直接返回
- 如果在超时还没有找到元素,则抛出异常
- 显示等待是 selenium 当中比较灵活的一种等待方式,他的实现原理其实是通过 while 循环不停的尝试需要进行的操作。
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 设置WebDriver等待时间为最多10秒,每隔0.5秒检查一次
#每隔 0.5s 检查一次(默认就是 0.5s)
# 最多等待 10 秒,否则报错。
#如果定位到元素则直接结束等待
#如果在10秒结束之后仍未定位到元素则报错
wait = WebDriverWait(chrome, 10, 0.5)
# 等待页面中的元素"J_goodsList"出现
wait.until(EC.presence_of_element_located((By.ID, 'J_goodsList'))
[3]隐式等待
- 隐式等待设置之后代码中的所有元素定位都会做隐式等待
- 通过implicitly Wait完成的延时等待,注意这种是针对全局设置的等待
- 如设置超时时间为10秒,使用了implicitlyWait后
- 如果第一次没有找到元素,会在10秒之内不断循环去找元素
- 如果超过10秒还没有找到,则抛出异常
- 隐式等待比较智能,它可以通过全局配置,但是只能用于元素定位
driver.implicitly_wait(10)
# 在指定的n秒内每隔一段时间尝试定位元素,如果n秒结束还未被定位出来则报错
(3)显示等待和隐式等待的区别
- selenium的显示等待- 原理:显示等待,就是明确要等到某个元素的出现或者是某个元素的可点击等条件,等不到,就一直等,除非在规定的时间之内都没找到,就会跳出异常Exception- (简而言之,就是直到元素出现才去操作,如果超时则报异常)
- selenium的隐式等待- 原理:隐式等待,就是在创建driver时,为浏览器对象创建一个等待时间,这个方法是得不到某个元素就等待一段时间,直到拿到某个元素位置。- 注意:在使用隐式等待的时候,实际上浏览器会在你自己设定的时间内部断的刷新页面去寻找我们需要的元素
【8】无头浏览器
- 我们已经基本了解了selenium的基本使用了. - 但是呢, 不知各位有没有发现, 每次打开浏览器的时间都比较长. 这就比较耗时了.- 我们写的是爬虫程序. 目的是数据. 并不是想看网页.- 那能不能让浏览器在后台跑呢? - 答案是可以的
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# 创建 ChromeOptions 实例
chrome_options = Options()
# 配置 ChromeOptions 的参数
# 指定浏览器分辨率
chrome_options.add_argument('window-size=1920x3000')
# 规避 bug,需要加上这个属性
chrome_options.add_argument('--disable-gpu')
# 隐藏滚动条,应对特殊页面
chrome_options.add_argument('--hide-scrollbars')
chrome_options.add_argument('blink-settings=imagesEnabled=false')
# 不加载图片,提升速度
chrome_options.add_argument('--headless')
# 无头模式,不提供可视化页面。在 Linux 下,如果系统不支持可视化,不加这条会启动失败
# chrome_options.binary_location = r"C:\Program Files (x86)\Google\Chrome\Application\chrome.exe"
# 手动指定
# 创建 Chrome WebDriver 实例,并传入配置参数
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://www.baidu.com') # 打开百度首页
# 在页面源代码中查找关键词 'hao123' 并打印结果
print('hao123' in driver.page_source)
# True
driver.close() # 关闭浏览器窗口,释放资源
【9】处理cookie
# 通过driver.get_cookies()能够获取所有的cookie
dictCookies = driver.get_cookies()
# 添加cookie
driver.add_cookie(dictCookies)
# 删除一条cookie
driver.delete_cookie("CookieName")
# 删除所有的cookie
driver.delete_all_cookies()
【10】页面前进和后退
driver.forward() # 前进
driver.back() # 后退
driver.refresh() # 刷新
driver.close() # 关闭当前窗口
【11】切换选项卡
from selenium import webdriver
import time
# 创建 Chrome 浏览器的实例
browser = webdriver.Chrome()
# 打开百度网页
browser.get('https://www.baidu.com/')
# 隐式等待2秒,确保页面加载完全
browser.implicitly_wait(2)
# 打印当前窗口句柄
print(browser.window_handles)
# 在当前浏览器实例中新开一个选项卡
browser.execute_script('window.open()')
# 获取所有选项卡的句柄列表
all_handles = browser.window_handles
# 切换到第二个选项卡(下标为1)
browser.switch_to.window(all_handles[1])
# 在第二个选项卡中打开淘宝网页
browser.get('http://www.taobao.com')
# 等待2秒
time.sleep(2)
# 切换回第一个选项卡(下标为0)
browser.switch_to.window(all_handles[0])
# 在第一个选项卡中打开hao123网页
browser.get('http://www.hao123.com')
# 等待2秒
time.sleep(2)
# 关闭当前选项卡
browser.close()
# 关闭浏览器实例
browser.quit()
【案例】登陆博客园
【1】思路分析
- 打开cnblogs - 点进登录页面- 输入用户名密码- 点登录(可能会出现验证码)----手动操作跳过验证码
- 登录成功后 - 拿到cookie- 保存到本地- 关闭浏览器
- 开启selenium,打开浏览器 - 把本地的cookie写入到当前浏览器中- 当前浏览器就是登录状态
【2】代码实现
from selenium import webdriver
from selenium.webdriver.common.by import By
import json
# 创建 Chrome 浏览器的实例
browser = webdriver.Chrome()
# 打开 cnblogs
browser.get('https://www.cnblogs.com/')
# 点击登录按钮,使用 XPATH 定位元素
btn_login = browser.find_element(By.XPATH, '//*[@id="navbar_login_status"]/a[6]')
btn_login.click()
# 输入登录用户名和密码
login_username = browser.find_element(By.XPATH, '//*[@id="mat-input-0"]')
login_password = browser.find_element(By.XPATH, '//*[@id="mat-input-1"]')
login_username.send_keys('206**[email protected]')
login_password.send_keys('zhaochunze521.')
# 点击登录按钮
login_btn = browser.find_element(By.XPATH,
"/html/body/app-root/app-sign-in-layout/div/div/app-sign-in/app-content-container/div/div/div/form/div/button/span[1]")
login_btn.click()
# 登录成功后获取 cookie
cookies = browser.get_cookies()
# 保存 cookie 到本地文件
with open('cnblogs_cookie.json', 'w', encoding='utf-8') as f:
json.dump(cookies, f)
# 关闭浏览器
browser.quit()
# 开启新的浏览器实例
browser = webdriver.Chrome()
# 打开 cnblogs 网页
browser.get('https://www.cnblogs.com/')
# 读取本地保存的 cookie
with open('cnblogs_cookie.json', 'r', encoding='utf-8') as f:
cookies = json.load(f)
# 添加 cookie 到浏览器
for cookie in cookies:
browser.add_cookie(cookie)
# 刷新页面,当前浏览器就处于登录状态
browser.refresh()
# 关闭浏览器
browser.close()
# 继续其他操作...
# ...
【案例】抽屉网半自动点赞
# -*-coding: Utf-8 -*-
# @File : 03chouti .py
# author: Chimengmeng
# blog_url : https://www.cnblogs.com/dream-ze/
# Time:2023/8/19
import json
import threading
import requests
from fake_useragent import UserAgent
from selenium import webdriver
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
from lxml import etree
class ChouTi():
def __init__(self):
self.headers = {
'User-Agent': UserAgent().random,
}
self.browser = webdriver.Edge()
def get_link_id(self):
link_id_list = []
response = requests.get('https://dig.chouti.com/', headers=self.headers)
tree = etree.HTML(response.text)
div_list = tree.xpath('/html/body/main/div/div/div[1]/div/div[2]/div[1]/div')
for div in div_list:
link_id = div.xpath("@data-id")[0]
link_id_list.append(link_id)
return link_id_list
def get_cookies(self, browser):
# 获取Cookie
btn_login = browser.find_element(By.XPATH, '//*[@id="login_btn"]')
# btn_login.click()
browser.execute_script("arguments[0].click()", btn_login)
# self.browser.implicitly_wait(3)
# from_username_to_login = self.browser.find_element(By.XPATH, '/html/body/div[4]/div/div[2]/a[2]')
# from_username_to_login.click()
# self.browser.implicitly_wait(3)
# username_input = self.browser.find_element(By.XPATH, '/html/body/div[4]/div/div[3]/div[2]/div/input')
# password_input = self.browser.find_element(By.XPATH, '/html/body/div[4]/div/div[4]/div[1]/div/input[1]')
browser.implicitly_wait(3)
username_input = browser.find_element(By.XPATH, '/html/body/div[4]/div/div[3]/div[1]/div[2]/input')
password_input = browser.find_element(By.XPATH, '/html/body/div[4]/div/div[4]/div[1]/div/input[1]')
username_input.send_keys('')
password_input.send_keys('')
browser.implicitly_wait(3)
login_btn = browser.find_element(By.XPATH, '/html/body/div[4]/div/div[4]/div[4]/button')
# login_btn.click()
browser.execute_script("arguments[0].click()", login_btn)
browser.implicitly_wait(3)
cookies = browser.get_cookies()
with open('chouti_cookies.json', 'w', encoding='utf-8') as fp:
json.dump(cookies, fp)
browser.close()
def up_blog(self, real_cookie, link_id):
# 缺cookie,如果有了cookie,可以整个页面全点一遍
data = {
'linkId': link_id
}
response = requests.post('https://dig.chouti.com/link/vote', headers=self.headers, data=data,
cookies=real_cookie)
if response.status_code == 200:
print(f'link_id:>>>点赞成功')
def get_news(self):
...
def main_up(self):
link_id_list = self.get_link_id()
self.browser.get('https://dig.chouti.com/')
self.browser.implicitly_wait(3)
self.get_cookies(self.browser)
real_cookie = {}
with open('chouti_cookies.json', 'r', encoding='utf-8') as fp:
cookies = json.load(fp)
for item in cookies:
real_cookie[item['name']] = item['value']
task_list = []
for link_id in link_id_list:
task = threading.Thread(target=self.up_blog, args=(real_cookie, link_id_list))
task.start()
task_list.append(task)
for task in task_list:
task.join()
def main(self):
...
if __name__ == '__main__':
ChouTi().main_up()
【案例】滑动验证
import time
from selenium import webdriver
from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素
import cv2
from urllib import request
from selenium.webdriver.common.action_chains import ActionChains
def get_distance():
background = cv2.imread("background.png", 0)
gap = cv2.imread("gap.png", 0)
res = cv2.matchTemplate(background, gap, cv2.TM_CCOEFF_NORMED)
value = cv2.minMaxLoc(res)[2][0]
print(value)
return value * 278 / 360
def main():
chrome = webdriver.Chrome()
chrome.implicitly_wait(5)
chrome.get('https://passport.jd.com/new/login.aspx?')
login = chrome.find_element(By.CLASS_NAME, 'login-tab-r')
login.click()
loginname = chrome.find_element(By.ID, 'loginname')
loginname.send_keys("[email protected]")
nloginpwd = chrome.find_element(By.ID, 'nloginpwd')
nloginpwd.send_keys("987654321")
loginBtn = chrome.find_element(By.CLASS_NAME, 'login-btn')
loginBtn.click()
img_src = chrome.find_element(By.XPATH, '//*[@class="JDJRV-bigimg"]/img').get_attribute("src")
temp_src = chrome.find_element(By.XPATH, '//*[@class="JDJRV-smallimg"]/img').get_attribute("src")
request.urlretrieve(img_src, "background.png")
request.urlretrieve(temp_src, "gap.png")
distance = int(get_distance())
print("distance:", distance)
print('第一步,点击滑动按钮')
element = chrome.find_element(By.CLASS_NAME, 'JDJRV-slide-btn')
ActionChains(chrome).click_and_hold(on_element=element).perform() # 点击鼠标左键,按住不放
ActionChains(chrome).move_by_offset(xoffset=distance, yoffset=0).perform()
ActionChains(chrome).release(on_element=element).perform()
if __name__ == '__main__':
main()
【案例】登陆12306
import time
from selenium.webdriver import ActionChains
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
# 创建 Chrome 浏览器选项对象
options = Options()
# 去掉自动化控制的特性
options.add_argument("--disable-blink-features=AutomationControlled")
# 实例化 Chrome 浏览器
bro = webdriver.Chrome(options=options)
# 打开 12306 网站登录页面
bro.get('https://kyfw.12306.cn/otn/resources/login.html')
# 隐式等待
bro.implicitly_wait(5)
# 最大化窗口
bro.maximize_window()
# 点击选择扫码登录方式
user_login = bro.find_element(By.CSS_SELECTOR,
'#toolbar_Div > div.login-panel > div.login-box > ul > li.login-hd-code.active > a')
user_login.click()
time.sleep(1)
# 输入用户名和密码,并点击登录按钮
username = bro.find_element(By.ID, 'J-userName')
password = bro.find_element(By.ID, 'J-password')
submit_btn = bro.find_element(By.ID, 'J-login')
# 修改下方的用户名和密码为正确的信息
username.send_keys('1**53675221')
password.send_keys('')
time.sleep(3)
submit_btn.click()
time.sleep(5)
# 找到滑块并进行拖动操作
span = bro.find_element(By.ID, 'nc_1_n1z')
ActionChains(bro).click_and_hold(span).perform()
ActionChains(bro).move_by_offset(xoffset=300, yoffset=0).perform()
ActionChains(bro).release().perform()
time.sleep(5)
# 关闭浏览器窗口
bro.close()
【案例】登录超级鹰
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from chaojiying import ChaojiyingClient
from PIL import Image
# 初始化浏览器
bro = webdriver.Chrome()
# 打开网页
bro.get('http://www.chaojiying.com/apiuser/login/')
bro.implicitly_wait(10)
bro.maximize_window()
try:
# 输入用户名和密码
username = bro.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[1]/input')
password = bro.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[2]/input')
code = bro.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[3]/input')
btn = bro.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[4]/input')
username.send_keys('306334678')
password.send_keys('lqz123')
# 获取验证码图片
# 将整个页面截图保存为 main.png
bro.save_screenshot('main.png')
# 定位验证码图片元素
img = bro.find_element(By.XPATH, '/html/body/div[3]/div/div[3]/div[1]/form/div/img')
# 获取验证码图片在页面中的位置
location = img.location
# 获取验证码图片的尺寸
size = img.size
# 使用Pillow库裁剪出验证码图片
img_tu = (int(location['x']), int(location['y']), int(location['x'] + size['width']), int(location['y'] + size['height']))
# 打开整个页面截图
img = Image.open('./main.png')
# 裁剪出验证码图片
fram = img.crop(img_tu)
# 保存验证码图片
fram.save('code.png')
# 使用超级鹰识别验证码
# 初始化超级鹰账号信息
chaojiying = ChaojiyingClient('', '', '')
# 读取验证码图片
im = open('code.png', 'rb').read()
# 使用超级鹰识别验证码图片
res_code = chaojiying.PostPic(im, 1902)['pic_str']
# 输入识别结果到验证码输入框
code.send_keys(res_code)
time.sleep(5)
btn.click()
time.sleep(10)
except Exception as e:
print(e)
finally:
bro.close()
【案例】抓京东商品信息
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys # 键盘按键操作
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.edge.options import Options
def get_goods(bro):
# 往下滑动一下屏幕
bro.execute_script('scrollTo(0,5000)')
goods = bro.find_elements(By.CLASS_NAME, 'gl-item')
print(len(goods))
for good in goods:
try:
price = good.find_element(By.CSS_SELECTOR, 'div.p-price i').text
url = good.find_element(By.CSS_SELECTOR, 'div.p-img>a').get_attribute('href')
commit = good.find_element(By.CSS_SELECTOR, 'div.p-commit a').text
name = good.find_element(By.CSS_SELECTOR, 'div.p-name em').text
img = good.find_element(By.CSS_SELECTOR, 'div.p-img img').get_attribute('src')
if not img:
img = 'https:' + good.find_element(By.CSS_SELECTOR, 'div.p-img img').get_attribute('data-lazy-img')
print('''
商品名字:%s
商品价格:%s
商品评论:%s
商品图片:%s
商品链接:%s
''' % (name, price, commit, img, url))
except Exception as e:
print(e)
continue
# 找出下一页按钮,点击
next = bro.find_element(By.PARTIAL_LINK_TEXT, '下一页')
next.click()
get_goods(bro) # 递归调用
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled") # 去掉自动化控制
# bro = webdriver.Chrome(options=options) # 在新版本的Selenium中,'chrome_options'已被替换为'options'
bro = webdriver.Edge(options=options) # 在新版本的Selenium中,'chrome_options'已被替换为'options'
bro.get('https://www.jd.com/')
bro.maximize_window()
bro.implicitly_wait(10)
try:
search_input = bro.find_element(By.ID, 'key')
search_input.send_keys('mac pro')
search_input.send_keys(Keys.ENTER)
# search_input.send_keys(Keys.BACKSPACE)
get_goods(bro)
except Exception as e:
print(e)
finally:
bro.close()
【二】 pyppeteer
- 由于Selenium流行已久,现在稍微有点反爬的网站都会对selenium和webdriver进行识别,网站只需要在前端js添加一下判断脚本,很容易就可以判断出是真人访问还是webdriver。 - 虽然也可以通过中间代理的方式进行js注入屏蔽webdriver检测,- 但是webdriver对浏览器的模拟操作(输入、点击等等)都会留下webdriver的标记,- 同样会被识别出来,要绕过这种检测,只有重新编译webdriver,麻烦自不必说,难度不是一般大。
- 由于Selenium具有这些严重的缺点。 - pyperteer成为了爬虫界的又一新星。- 相比于selenium具有异步加载、速度快、具备有界面/无界面模式、伪装性更强不易被识别为机器人,- 同时可以伪装手机平板等终端;- 虽然支持的浏览器比较单一,- 但在安装配置的便利性和运行效率方面都要远胜selenium。
- pyppeteer无疑为防爬墙撕开了一道大口子, - 针对selenium的淘宝、美团、文书网等网站,目前可通过该库使用selenium的思路继续突破,毫不费劲。
- 介绍Pyppeteer之前先说一下Puppeteer, - Puppeteer是谷歌出品的一款基于Node.js开发的一款工具,- 主要是用来操纵Chrome浏览器的 API,- 通过Javascript代码来操纵Chrome浏览器,完成数据爬取、Web程序自动测试等任务。
- pyppeteer是非官方 Python 版本的 Puppeteer 库, - 浏览器自动化库,- 由日本工程师开发。
- Puppeteer是 Google 基于 Node.js 开发的工具, - 调用 Chrome 的 API,- 通过 JavaScript 代码来操纵 Chrome 完成一些操作,- 用于网络爬虫、Web 程序自动测试等。
- pyppeteer 使用了 Python 异步协程库asyncio,可整合 Scrapy 进行分布式爬虫。
puppet 木偶,puppeteer 操纵木偶的人。
pip3 install pyppeteer
【1】Pyppeteer简介
- 异步的selenium。
- 在 Pyppetter的背后是有一个类似 Chrome 浏览器的 Chromium 浏览器在执行一些动作进行网页渲染,首先说下 Chrome 浏览器和 Chromium 浏览器的渊源。- Chromium 是谷歌为了研发 Chrome 而启动的项目,是完全开源的。- 二者基于相同的源代码构建,Chrome 所有的新功能都会先在 Chromium 上实现,待验证稳定后才会移植,因此 Chromium 的版本更新频率更高,也会包含很多新的功能,但作为一款独立的浏览器,Chromium 的用户群体要小众得多。- 两款浏览器“同根同源”,它们有着同样的 Logo,但配色不同,Chrome 由蓝红绿黄四种颜色组成,而 Chromium 由不同深度的蓝色构成。
- Pyppeteer 就是依赖于 Chromium 这个浏览器来运行的。
- 那么有了 Pyppeteer 之后,我们就可以免去那些繁琐的环境配置等问题。
- 如果第一次运行的时候,Chromium 浏览器没有安装,那么程序会帮我们自动安装和配置,就免去了繁琐的环境配置等工作。
- 另外 Pyppeteer 是基于 Python 的新特性 async 实现的,所以它的一些执行也支持异步操作,效率相对于 Selenium 来说也提高了。
【2】环境安装
- 由于 Pyppeteer 采用了 Python 的 async 机制,所以其运行要求的 Python 版本为 3.5 及以上
pip install pyppeteer
【3】快速上手
- 爬取http://quotes.toscrape.com/js/ 全部页面数据
import asynciofrom pyppeteer import launchfrom lxml import etreeasync def main(): browser = await launch(headless=False) page = await browser.newPage() await page.goto('http://quotes.toscrape.com/js/') page_text = await page.content() tree = etree.HTML(page_text) div_list = tree.xpath('//div[@class="quote"]') print(len(div_list)) await browser.close()c = main()asyncio.get_event_loop().run_until_complete(c)- 代码解释:- 解释:launch 方法会新建一个 Browser 对象,然后赋值给 browser,然后调用 newPage 方法相当于浏览器中新建了一个选项卡,同时新建了一个 Page 对象。- 然后 Page 对象调用了 goto 方法就相当于在浏览器中输入了这个 URL,浏览器跳转到了对应的页面进行加载,加载完成之后再调用 content 方法,返回当前浏览器页面的源代码。- 在这个过程中,我们没有配置 Chrome 浏览器,没有配置浏览器驱动,免去了一些繁琐的步骤,同样达到了 Selenium 的效果,还实现了异步抓取,爽歪歪!
【4】详细用法
- 开启浏览器- 调用 launch() 方法即可,相关参数介绍:- ignoreHTTPSErrors (bool): 是否要忽略 HTTPS 的错误,默认是 False。- headless (bool): 是否启用 Headless 模式,即无界面模式,默认是开启无界面模式的。如果设置为 False则是有界面模式。- executablePath (str): 可执行文件的路径,如果指定之后就不需要使用默认的 Chromium 了,可以指定为已有的 Chrome 或 Chromium。- devtools (bool): 是否为每一个页面自动开启调试工具(浏览器开发者工具),默认是 False。如果这个参数设置为 True,那么 headless 默认参数就会无效,会被强制设置为 False。- args (List[str]): 在执行过程中可以传入的额外参数。- 关闭提示条:”Chrome 正受到自动测试软件的控制”,这个提示条有点烦,那咋关闭呢?这时候就需要用到 args 参数了,禁用操作如下:-
browser = await launch(headless=False, args=['--disable-infobars']) - 处理页面显示问题:访问淘宝首页-
import asynciofrom pyppeteer import launchasync def main(): browser = await launch(headless=False) page = await browser.newPage() await page.goto('https://www.taobao.com') await asyncio.sleep(3) await browser.close()asyncio.get_event_loop().run_until_complete(main())- 发现页面显示出现了问题,需要手动调用setViewport方法设置显示页面的长宽像素。设置如下:-import asynciofrom pyppeteer import launchwidth, height = 1366, 768async def main(): browser = await launch(headless=False) page = await browser.newPage() await page.setViewport({'width': width, 'height': height}) await page.goto('https://www.taobao.com') await asyncio.sleep(3) await browser.close()asyncio.get_event_loop().run_until_complete(main()) - 执行js程序:拖动滚轮。调用evaluate方法。-
import asynciofrom pyppeteer import launchwidth, height = 1366, 768async def main(): browser = await launch(headless=False) page = await browser.newPage() await page.setViewport({'width': width, 'height': height}) await page.goto('https://www.taobao.com') await asyncio.sleep(2) #执行js代码 await page.evaluate('window.scrollTo(0,document.body.scrollHeight)') await asyncio.sleep(2) await browser.close()asyncio.get_event_loop().run_until_complete(main()) - 规避检测-
import asynciofrom pyppeteer import launchwidth, height = 1366, 768async def main(): #规避检测 browser = await launch(headless=False, args=['--disable-infobars']) page = await browser.newPage() await page.setViewport({'width': width, 'height': height}) await page.goto('https://login.taobao.com/member/login.jhtml?redirectURL=https://www.taobao.com/') #规避检测 await page.evaluate( '''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }''') await asyncio.sleep(3) await browser.close()asyncio.get_event_loop().run_until_complete(main()) - 节点交互-
import asynciofrom pyppeteer import launchasync def main(): # headless参数设为False,则变成有头模式 browser = await launch( headless=False ) page = await browser.newPage() # 设置页面视图大小 await page.setViewport(viewport={'width': 1280, 'height': 800}) await page.goto('https://www.baidu.com/') # 节点交互 await page.type('#kw', '周杰伦', {'delay': 1000}) await asyncio.sleep(3) #点击搜索按钮 await page.click('#su') await asyncio.sleep(3) # 使用选择器选中标签进行点击 alist = await page.querySelectorAll('.s_tab_inner > a') a = alist[3] await a.click() await asyncio.sleep(3) await browser.close()asyncio.get_event_loop().run_until_complete(main())
【5】爬虫练习
- 异步爬取头条和网易新闻首页的新闻标题 - https://www.toutiao.com/- https://news.163.com/domestic/
import asyncio
from pyppeteer import launch
from lxml import etree
async def main():
# headless参数设为False,则变成有头模式
browser = await launch(
headless=False
)
page1 = await browser.newPage()
# 设置页面视图大小
await page1.setViewport(viewport={'width': 1280, 'height': 800})
await page1.goto('https://www.toutiao.com/')
await asyncio.sleep(2)
# 打印页面文本
page_text = await page1.content()
page2 = await browser.newPage()
await page2.setViewport(viewport={'width': 1280, 'height': 800})
await page2.goto('https://news.163.com/domestic/')
await page2.evaluate('window.scrollTo(0,document.body.scrollHeight)')
page_text1 = await page2.content()
await browser.close()
return {'wangyi': page_text1, 'toutiao': page_text}
def parse(task):
content_dic = task.result()
wangyi = content_dic['wangyi']
toutiao = content_dic['toutiao']
tree = etree.HTML(toutiao)
a_list = tree.xpath('//div[@class="title-box"]/a')
for a in a_list:
title = a.xpath('./text()')[0]
print('toutiao:', title)
tree = etree.HTML(wangyi)
div_list = tree.xpath('//div[@class="data_row news_article clearfix "]')
for div in div_list:
title = div.xpath('.//div[@class="news_title"]/h3/a/text()')[0]
print('wangyi:', title)
tasks = []
task1 = asyncio.ensure_future(main())
task1.add_done_callback(parse)
tasks.append(task1)
asyncio.get_event_loop().run_until_complete(asyncio.wait(tasks))
【6】滑动验证
import random
from pyppeteer import launch
import asyncio
import cv2
from urllib import request
async def get_track():
background = cv2.imread("background.png", 0)
gap = cv2.imread("gap.png", 0)
res = cv2.matchTemplate(background, gap, cv2.TM_CCOEFF_NORMED)
value = cv2.minMaxLoc(res)[2][0]
print(value)
return value * 278 / 360
async def main():
browser = await launch({
# headless指定浏览器是否以无头模式运行,默认是True。
"headless": False,
#设置窗口大小
"args": ['--window-size=1366,768'],
})
# 打开新的标签页
page = await browser.newPage()
# 设置页面大小一致
await page.setViewport({"width": 1366, "height": 768})
# 访问主页
await page.goto("https://passport.jd.com/new/login.aspx?")
# 单击事件
await page.click('div.login-tab-r')
# 模拟输入用户名和密码,输入每个字符的间隔时间delay ms
await page.type("#loginname", '[email protected]', {
"delay": random.randint(30, 60)
})
await page.type("#nloginpwd", '345653332', {
"delay": random.randint(30, 60)
})
# page.waitFor 通用等待方式,如果是数字,则表示等待具体时间(毫秒): 等待2秒
await page.waitFor(2000)
await page.click("div.login-btn")
await page.waitFor(2000)
# page.jeval(selector,pageFunction)#定位元素,并调用js函数去执行
#=>表示js的箭头函数:el = function(el){return el.src}
img_src = await page.Jeval(".JDJRV-bigimg > img", "el=>el.src")
temp_src = await page.Jeval(".JDJRV-smallimg > img", "el=>el.src")
request.urlretrieve(img_src, "background.png")
request.urlretrieve(temp_src, "gap.png")
# 获取gap的距离
distance = await get_track()
"""
# Pyppeteer 三种解析方式
Page.querySelector() # 选择器
Page.querySelectorAll()
Page.xpath() # xpath 表达式
# 简写方式为:
Page.J(), Page.JJ(), and Page.Jx()
"""
#定位到滑动按钮标签
el = await page.J("div.JDJRV-slide-btn")
# 获取元素的边界框,包含x,y坐标
box = await el.boundingBox()
#box={'x': 86, 'y': 34, 'width': 55.0, 'height': 55.0}
#将鼠标悬停/一定到指定标签位置
await page.hover("div.JDJRV-slide-btn")
#按下鼠标
await page.mouse.down()
#模拟人的行为进行滑动
# steps 是指分成几步来完成,steps越大,滑动速度越慢
#move(x,y)表示将鼠标移动到xy坐标位置
await page.mouse.move(box["x"] + distance + random.uniform(10, 30),
box["y"],
{"steps": 100})
await page.waitFor(1000)
await page.mouse.move(box["x"] + distance + random.uniform(10, 30),
box["y"], {"steps": 100})
await page.mouse.up()
await page.waitFor(2000)
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
【三】appnium
- Appium 是一种开源的移动应用自动化测试工具,用于测试原生移动应用、混合应用和移动网页应用。
- 它支持多种编程语言包括 Java、Python、C# 等,可以在不同的平台(iOS、Android)上进行自动化测试。
- 以下是一个使用 Appium 进行移动应用自动化测试的示例演示:
from appium import webdriver
from appium.webdriver.common.touch_action import TouchAction
desired_caps = {
'platformName': 'Android', # 指定平台为 Android
'platformVersion': '9', # 设备的 Android 版本号
'deviceName': 'Android Emulator', # 设备名称
'appPackage': 'com.example.myapp', # 应用的包名
'appActivity': '.MainActivity' # 应用的启动 Activity
}
# 连接到 Appium 服务器
driver = webdriver.Remote('http://localhost:4723/wd/hub', desired_caps)
# 启动应用
driver.launch_app()
# 执行自动化操作
el = driver.find_element_by_id('com.example.myapp:id/button')
el.click()
# 使用 TouchActions 进行手势操作,例如滑动、长按等
action = TouchAction(driver)
element1 = driver.find_element_by_id('com.example.myapp:id/element1')
element2 = driver.find_element_by_id('com.example.myapp:id/element2')
action.press(element1).move_to(element2).release().perform()
# 断言检查结果
result_text = driver.find_element_by_id('com.example.myapp:id/result').text
assert result_text == 'Success'
# 关闭应用
driver.close_app()
driver.quit()
- 上述代码展示了一个使用 Appium 进行 Android 应用自动化测试的示例演示。 - 首先通过传递
desired_caps字典来指定测试的设备和应用信息- 然后通过连接到 Appium 服务器创建一个远程驱动程序对象。 - 在执行自动化操作之前,可以使用各种定位方式(如 id、class name、xpath 等)找到元素并进行交互,最后可以进行结果断言并关闭应用。
- 需要注意的是,示例中的一些元素的 id 和包名/Activity 名称需要替换为实际应用的元素 id 和包名/Activity 名称。
- 此外,还需要安装并配置好 Appium 环境,并启动 Appium 服务器,以便运行测试脚本。
本文转载自: https://blog.csdn.net/Chimengmeng/article/details/132442288
版权归原作者 Chimengmeng 所有, 如有侵权,请联系我们删除。
版权归原作者 Chimengmeng 所有, 如有侵权,请联系我们删除。