
技术是为了业务服务的
hive
hive sql调优
count(distinct)

Join优化

mapjoin是大表join小表 将小表读入内存 写 hint的方式:
select /*+ MAPJOIN(a) */ a.c1, b.c1 ,b.c2 from a join b where a.c1 = b.c1;
groupby 聚合倾斜
解决方法:
set hive.map.aggr=true;
set hive.groupby.skewindata=true;
hive.map.aggr=true 这个配置代表开启map端聚合;
hive.groupby.skewindata=true,当选项设定为true,生成的查询计划会有两个MR Job。当第一个MR Job中,Map的输出结果结合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果。这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的。第二个MR Job再根据预处理的数据结果按照Group By Key分布到reduce中,这个过程可以保证相同的key被分到同一个reduce中,最后完成最终的聚合操作。
合理控制 MapTask,ReduceTask数量
原因1:当出现小文件过多或者
原因2:输入数据存在大块和小块的严重问题,比如 说:一个大文件128M,还有1000个小文件,每 个1KB。 解决方法:任务输入前做文件合并,将众多小文件合并成一个大文件。通过set hive.merge.mapredfiles=true解决;
原因3:单个文件大小稍稍大于配置的block块的大小,此时需要适当增加map的个数。解决方法:set mapred.map.tasks的个数;
原因4:文件大小适中,但是map端计算量非常大,如:select id,count(*),sum(case when…),sum(case when …)…需要增加map个数。解决方法:set mapred.map.tasks个数,set mapred.reduce.tasks个数
内部表外部表

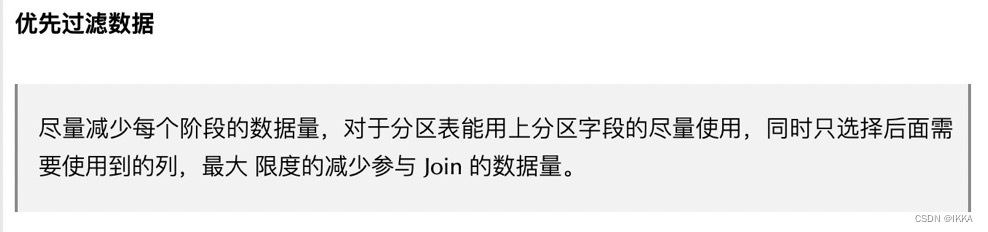
连续登陆问题
行转列 列转行

distribute by
字段相同的会到同一个task处理
order by 全局排序,且只有一个task在处理
sort by 在task内部进行排序 一般签名会接distribute by
row_number
row_number无并列,一直连续
dense_rank有并列,一直连续
rank有并列,有间隔(非一直连续)
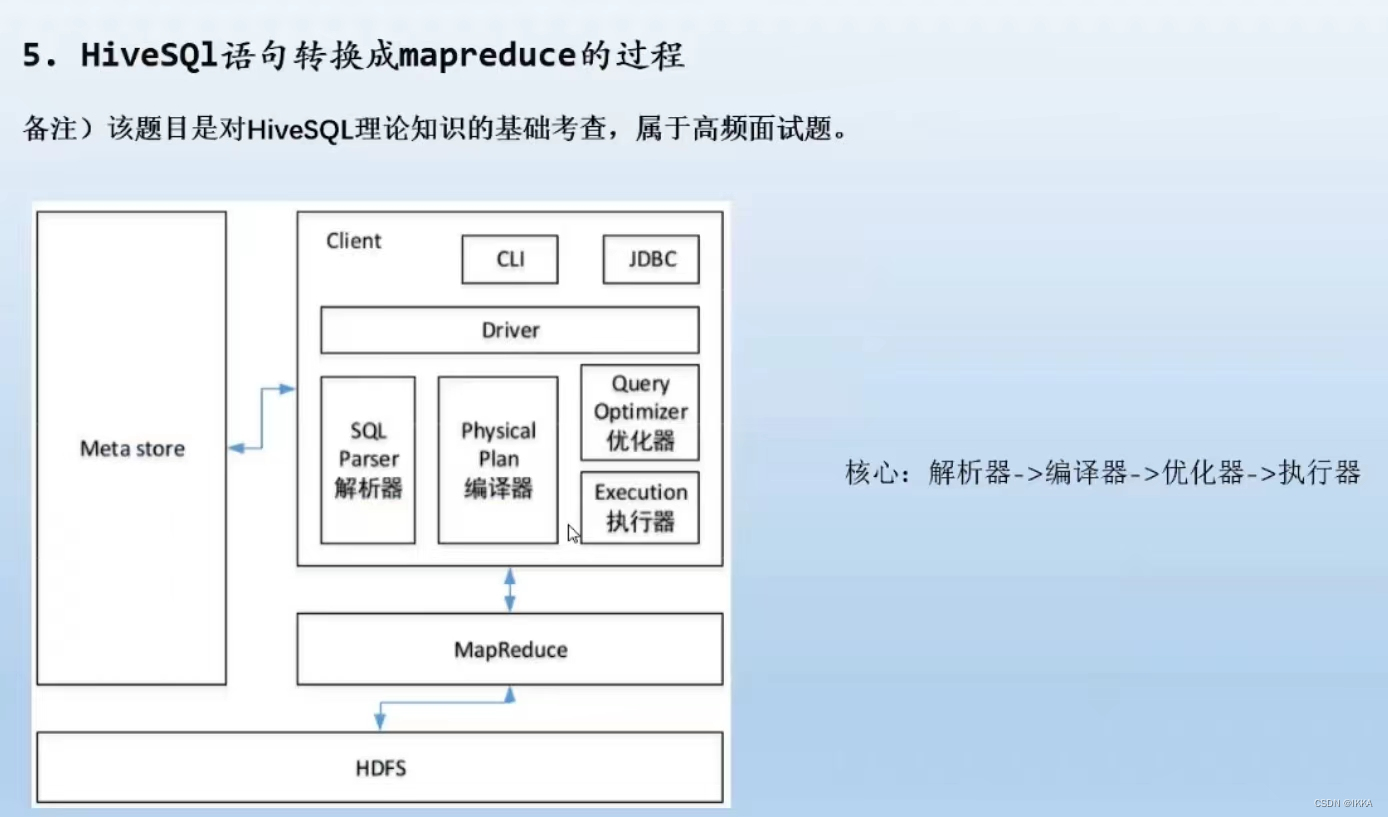
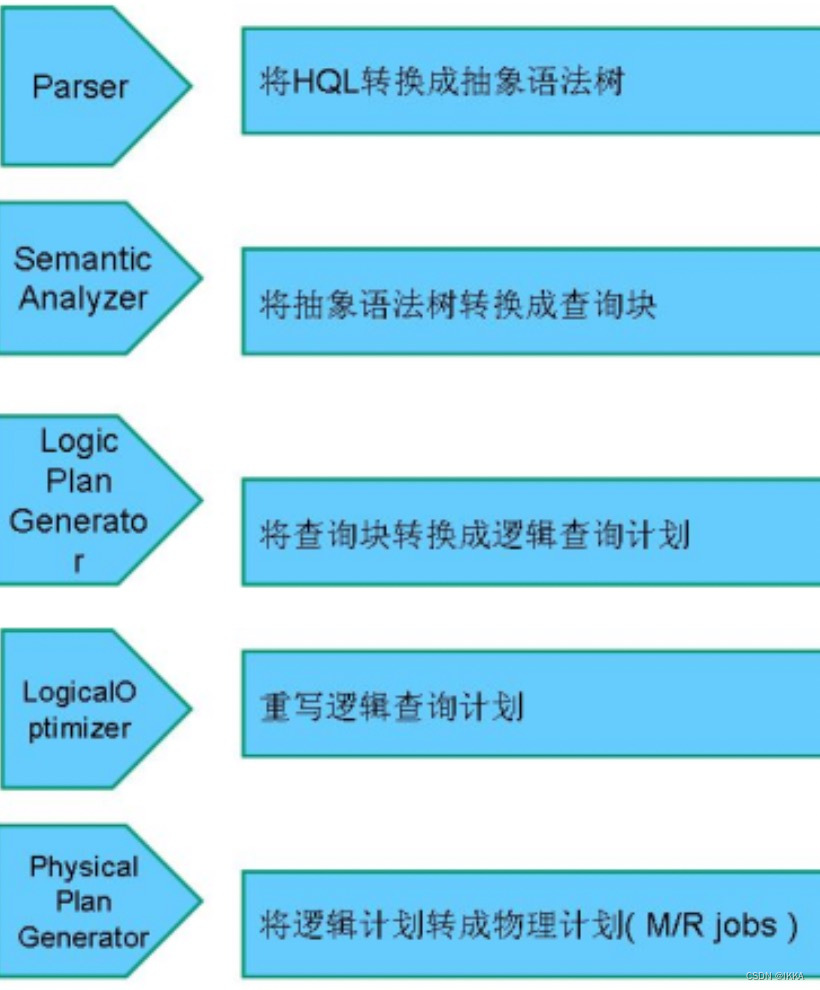
hivesql转换成mapreduce

数据仓库
数仓分层
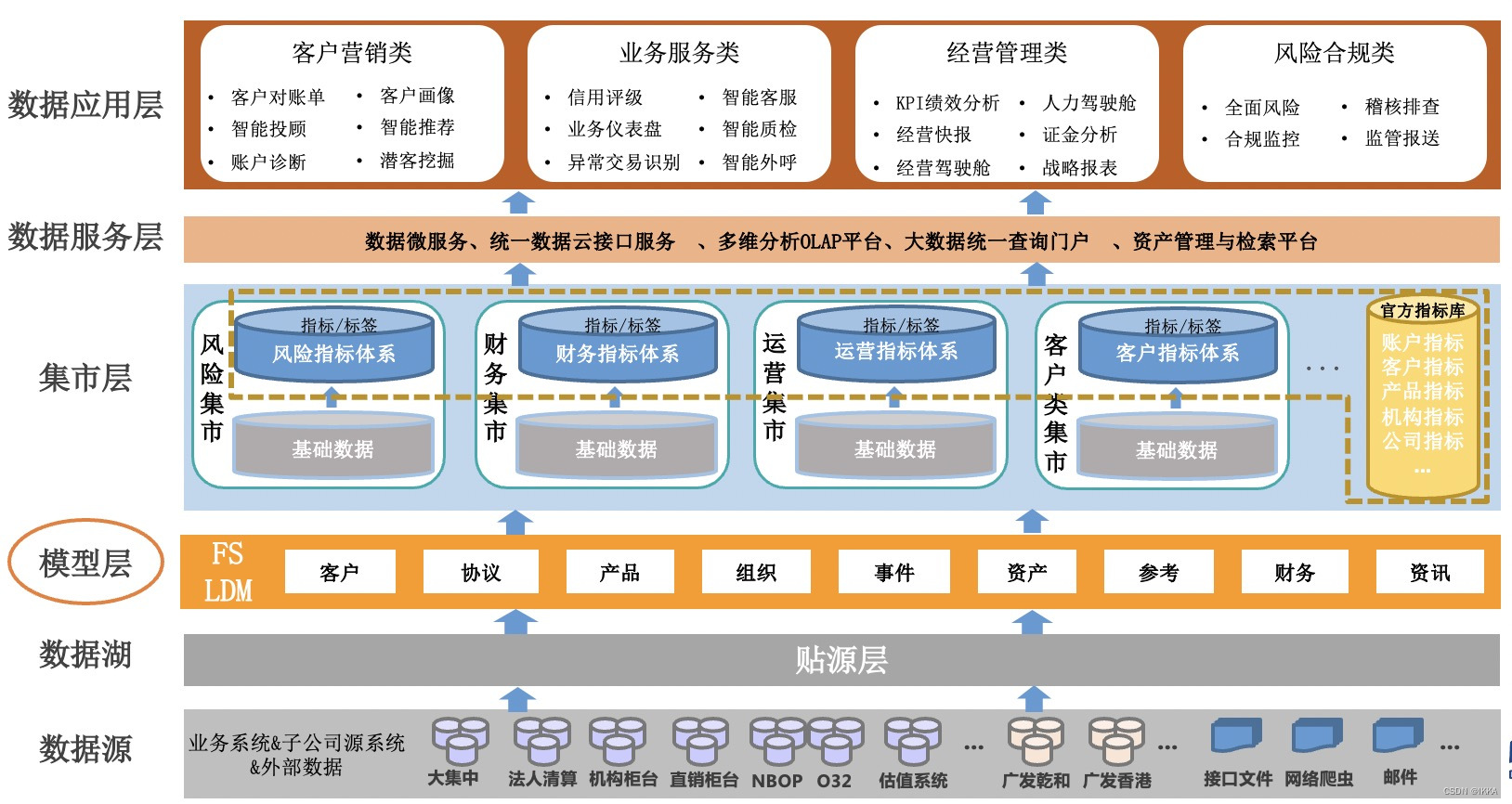


好的数据仓库满足要求

数据建模过程
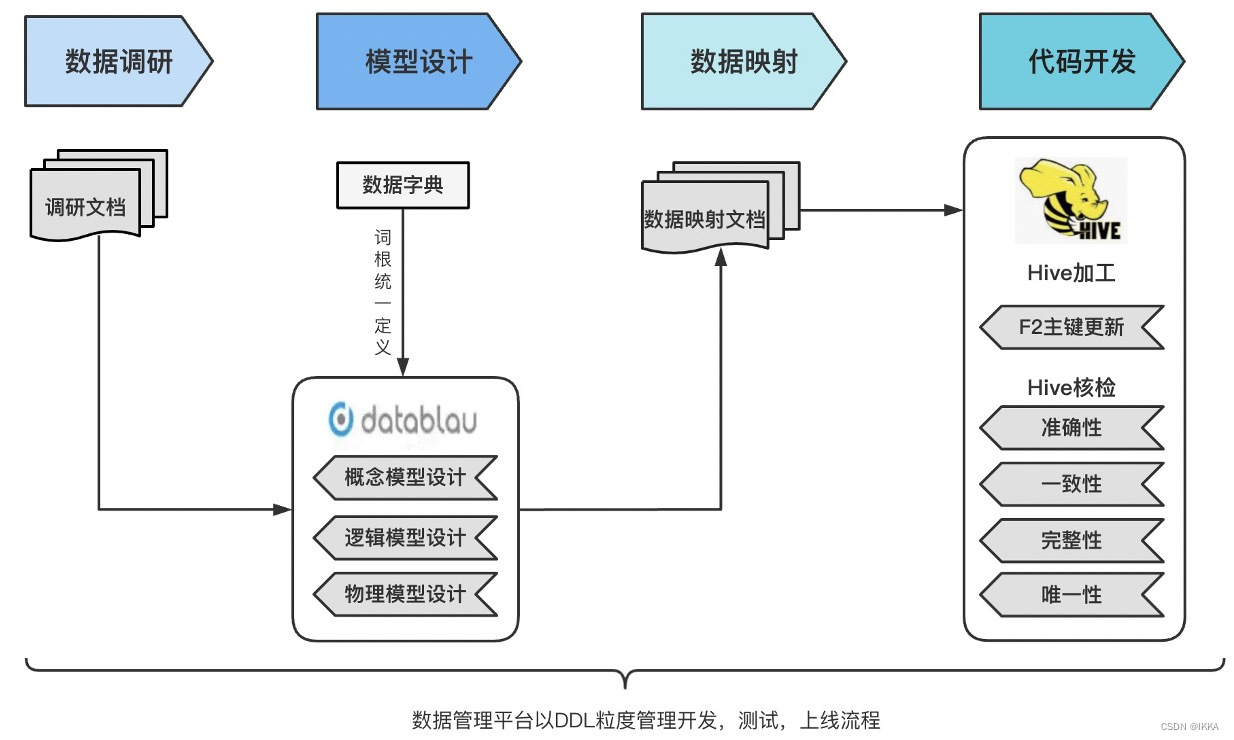
数据建模作为基础模型层工作中最重要,也是最有挑战性的一环,我会首先对这个进行基础知识框架梳理。
- 概念建模: 从纷繁的业务表象背后通过实体建模法,抽象出实体,事件,说明等抽象的实体,从而找出业务表象后抽象实体间的相互的关联性,保证了我们数据仓库数据按照数据模型所能达到的一致性和关联性。
- 逻辑建模:概念实体化,并考虑其具体的属性;逻辑建模中会涉及到几个细化的工作:分别是分析源系统,统一业务定义以及逻辑模型设计。
- 物理建模:综合现实的大数据平台、采集工具、etl工具、数仓组件、性能要求、管理要求等多方面因素,设计出具体的项目代码,完成数仓的搭建。
范式建模:三范式
1NF 域是原子性的,每一列应该不可再分
2NF消除了某些属性只依赖混合主键中的部分属性
3NF消除了消除了非主属性对于主键(复合主键)的传递依赖
范式建模和维度建模对比
- 范式建模自上而下、事实维度建模自下而上

- 稳定:范式建模适合业务稳定的行业,事实维度建模适合业务过程更新迭代快的行业
- 范式建模符合三范式,事实维度建模不需要
- 范式建模开发周期长,开发人员要求高,事实维度建模开发周期短,可以快速支持业务分析
- 范式建模相比于事实维度建模冗余程度低,一致性程度高
维度建模的具体实现方式
选择业务过程 —— 声明粒度 —— 确认维度 —— 确认事实(确认指标)
订单 —— 下单 ——商家,商品,用户,区域等维度 ——金额,gmv,退货率等指标
星型模型和雪花模型

事实维度建模步骤
度量是事实,环境描述为维度
比如交易这个主题,有买家,卖家,商品,时间等维度去描述这个环境
维度也是查询 的where条件,分组,报表标签生成的来源
选取业务 – 选择业务过程 —— 声明粒度 —— 确认维度 —— 确认事实-- 事实表冗余一些维度
销售事实表

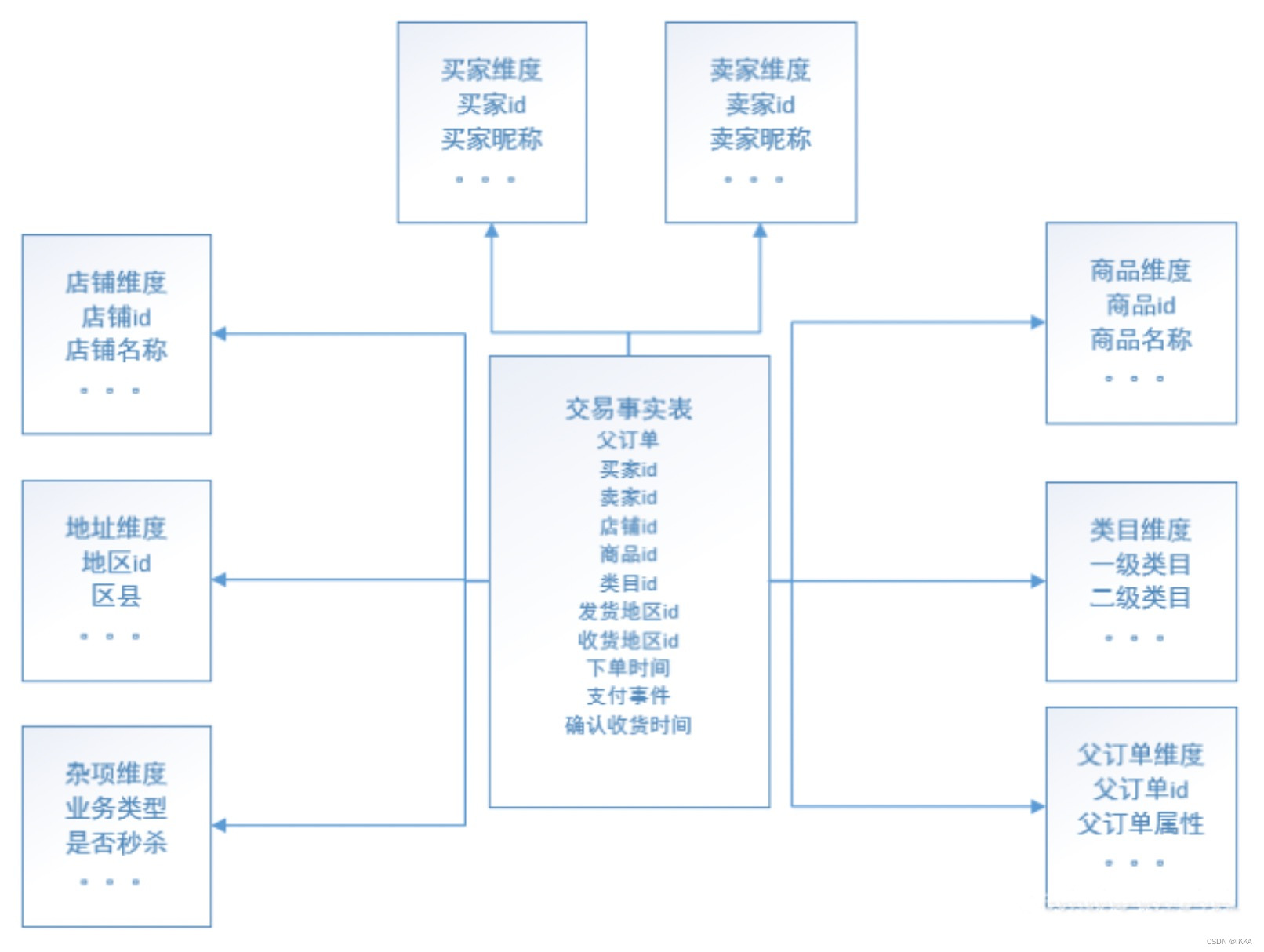
选择业务过程 —— 声明粒度 —— 确认维度 —— 确认事实–将一些常用的维度冗余进事实表中 减少查询过程的join
三种事实表比较

一致性


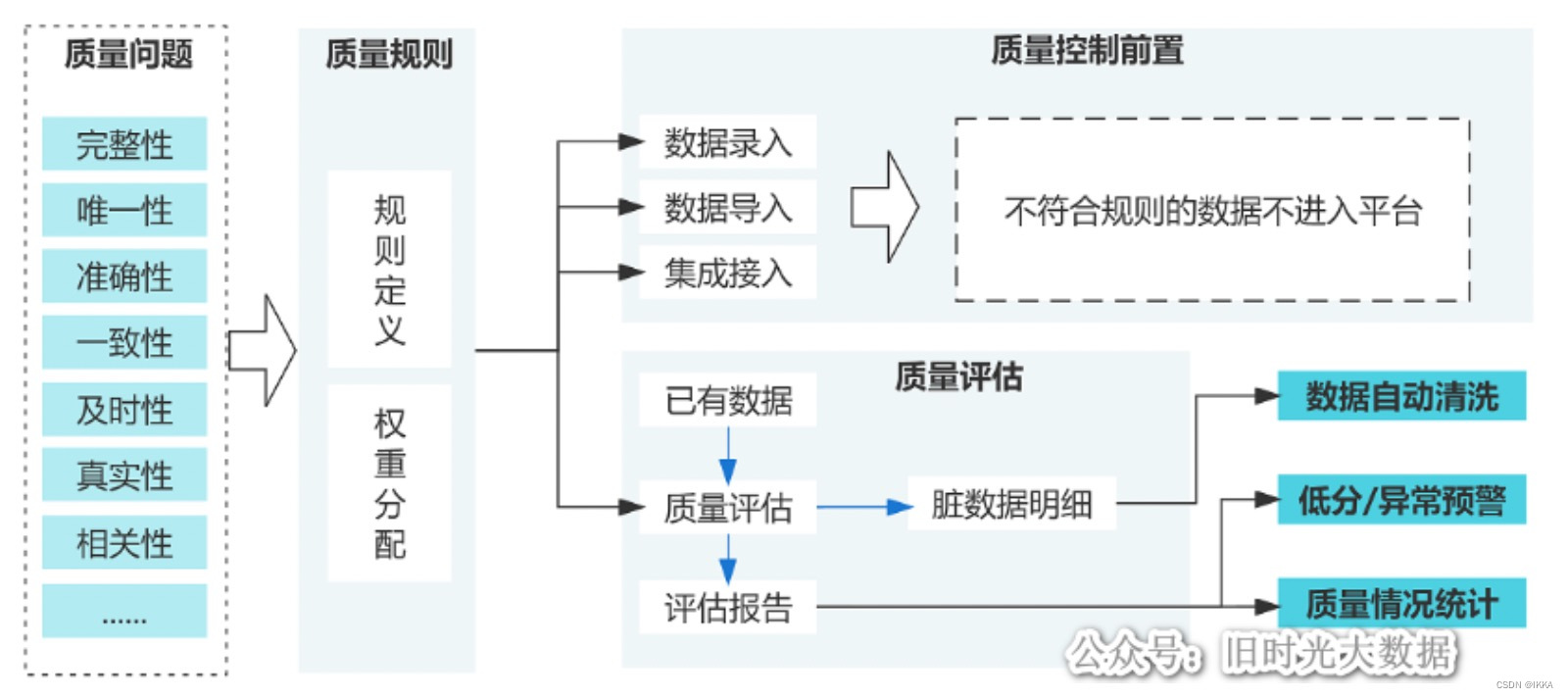
数据治理
SPARK
mapreduce和spark的shuffle异同
spark的shuffle实在mr的shuffle基础上进行了调优,对排序/合并逻辑上做了一些优化
mapreduce的shuffle
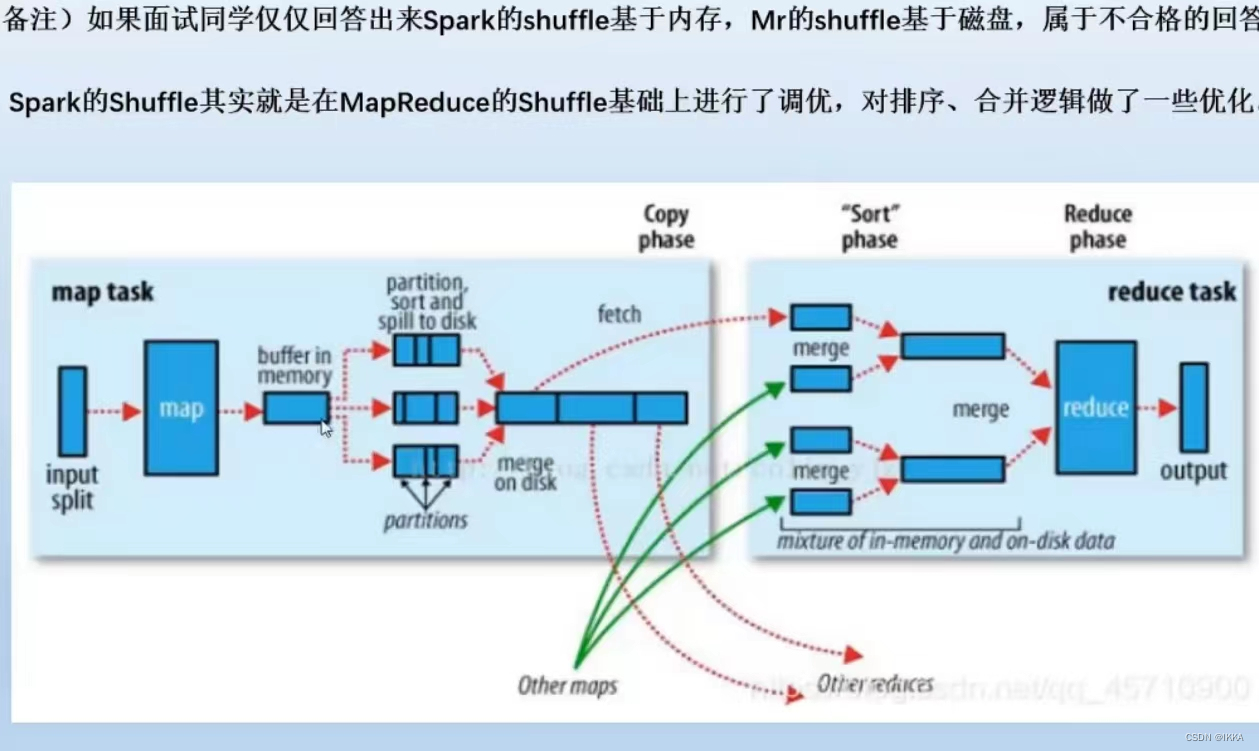
内存缓冲区达到80% — 溢写到磁盘上(分区并排序) — 溢写的很多磁盘小文件会merge成一个大的on disk(map的结果)
缓冲区到磁盘 快排 — 磁盘合并成大的 归并排序 — reduce阶段也是归并排序
spark的shuffle 分成了hash和sort shuffle
hash shuffle
普通机制的hash shuffle 产生m*r个磁盘小文件
合并机制的hash shuffle 无论有过多少个task 都会把同样的key放在同一个buffer里
sort shuffle
基本上跟mapreduce的shuffle是一致的
bypass sort shuffle 少了对数据进行排序的过程 就直接进行分区
spark数据倾斜 如何解决
在代码里找(groupbykey、countBykey、reduceBykey、join),或者查看log发现 定位第几个stage,是哪个stage task慢,定位代码。
1. 过滤少数导致倾斜的key

直接where过滤掉
2. 提高shuffle操作算子的并行度
一个task的有多个key
groupByKey(1000) .set(“spark.sql.shuffle.partitions”,“2000”) 默认200
3. join:reduce join 转为map join

map join .set(“spark.sql/autoBroadcastJoinThreshold”,“”)默认是10485760
4. group:局部聚合 + 全局聚合
将相同key做数据分拆处理,接着进行两阶段聚合(局部聚合 + 全局聚合)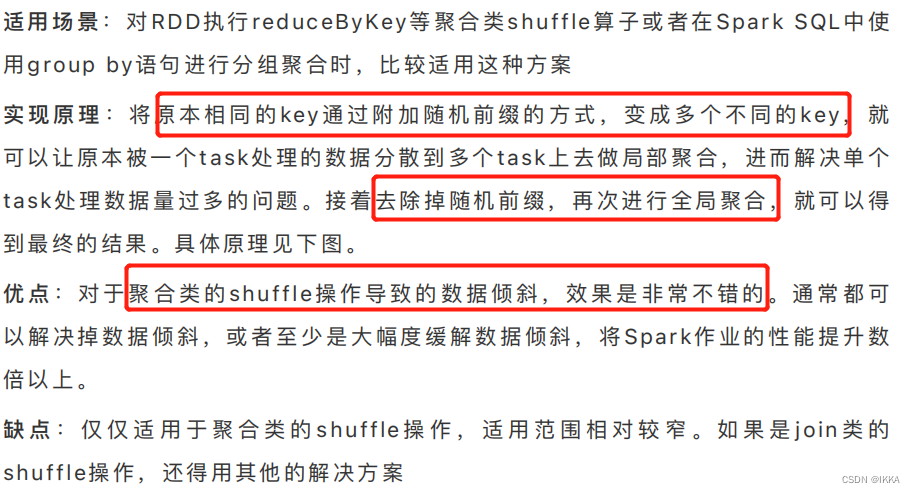
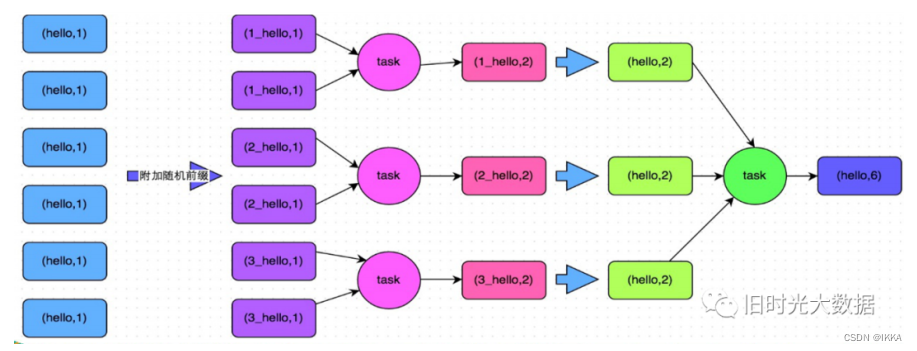
5. join:随机前缀和扩容RDD

RDD宽依赖 窄依赖
窄依赖是 每一个parent RDD的Partition 最多被 子RDD的一个Partition 使用
宽依赖是 同一个parent RDD的Partition 被 多个子RDD的partition 依赖
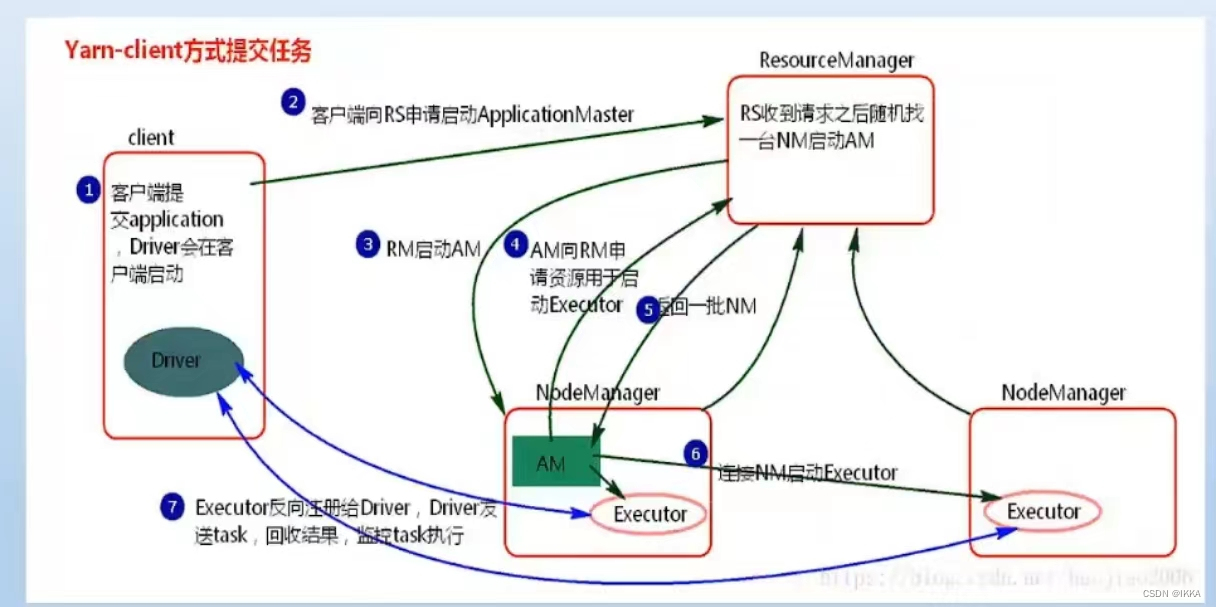
spark执行流程

yarn-client
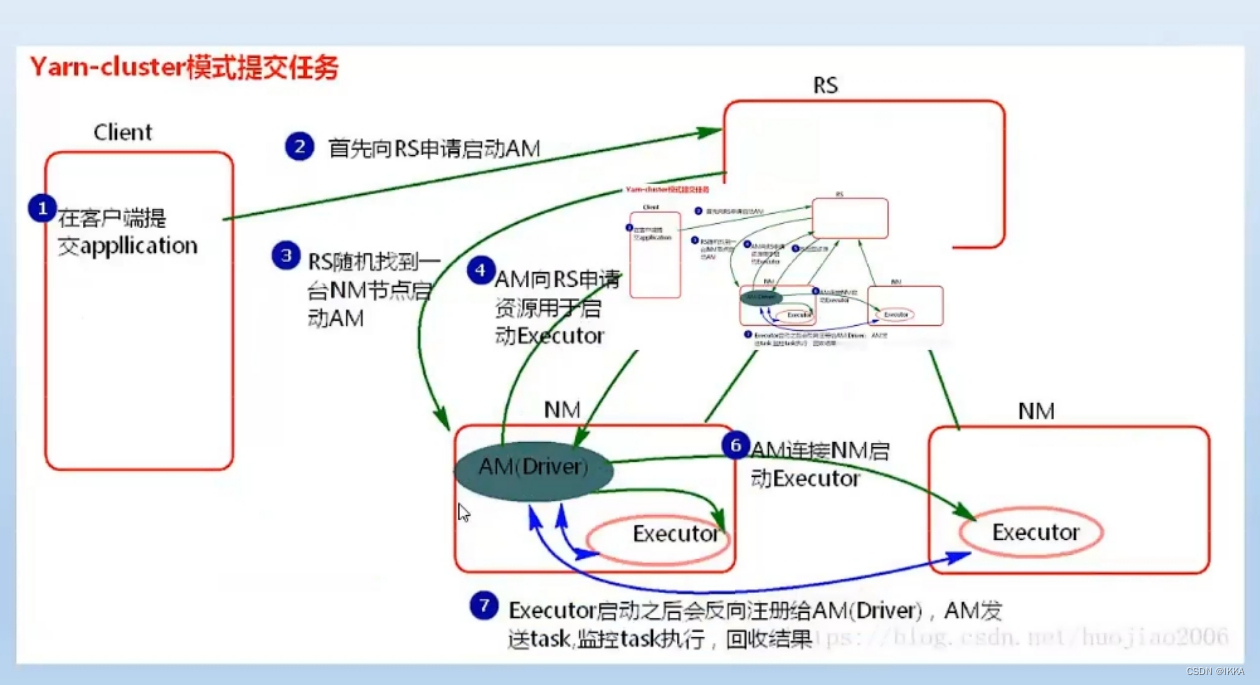
yarn-cluster

spark reduceByKey和GroupByKey的区别

foreach和foreachPartition算子的区别

Hbase
Hbase和MySQL的区别

Hbase官网列族推荐
TTL

Hbase列蔟
多线程创建方式
第一种,通过继承Thread类创建线程类
第二种,通过实现Runnable接口创建线程类
2.3 第三种,通过Callable和Future接口创建线程
线程池
kafka
结构



kafka作用

如何保证数据可靠性
topic分区副本
Kafka 可以保证单个分区里的事件是有序的,分区可以在线(可用),也可以离线(不可用)。在众多的分区副本里面有一个副本是 Leader,其余的副本是 follower,所有的读写操作都是经过 Leader 进行的,同时 follower 会定期地去 leader 上的复制数据。当 Leader 挂了的时候,其中一个 follower 会重新成为新的 Leader。通过分区副本,引入了数据冗余,同时也提供了 Kafka 的数据可靠性。
ISR机制

每个分区的 leader 会维护一个 ISR 列表,ISR 列表里面就是 follower 副本的 Borker 编号,只有 ISR 里的成员才有被选为 leader 的可能,当leader挂掉之后,就会从ISR的follower中选举新的leader
ack消息确认机制

根据实际的应用场景,我们设置不同的 acks,以此保证数据的可靠性。
Kafka数据有序性
针对部分消息有序(message.key相同的message要保证消费顺序)场景,可以在producer往kafka插入数据时控制,同一key分发到同一partition上面。因为每个partition是固定分配给某个消费者线程进行消费的,所以对于在同一个分区的消息来说,是严格有序的
Flink
flink数据一致性


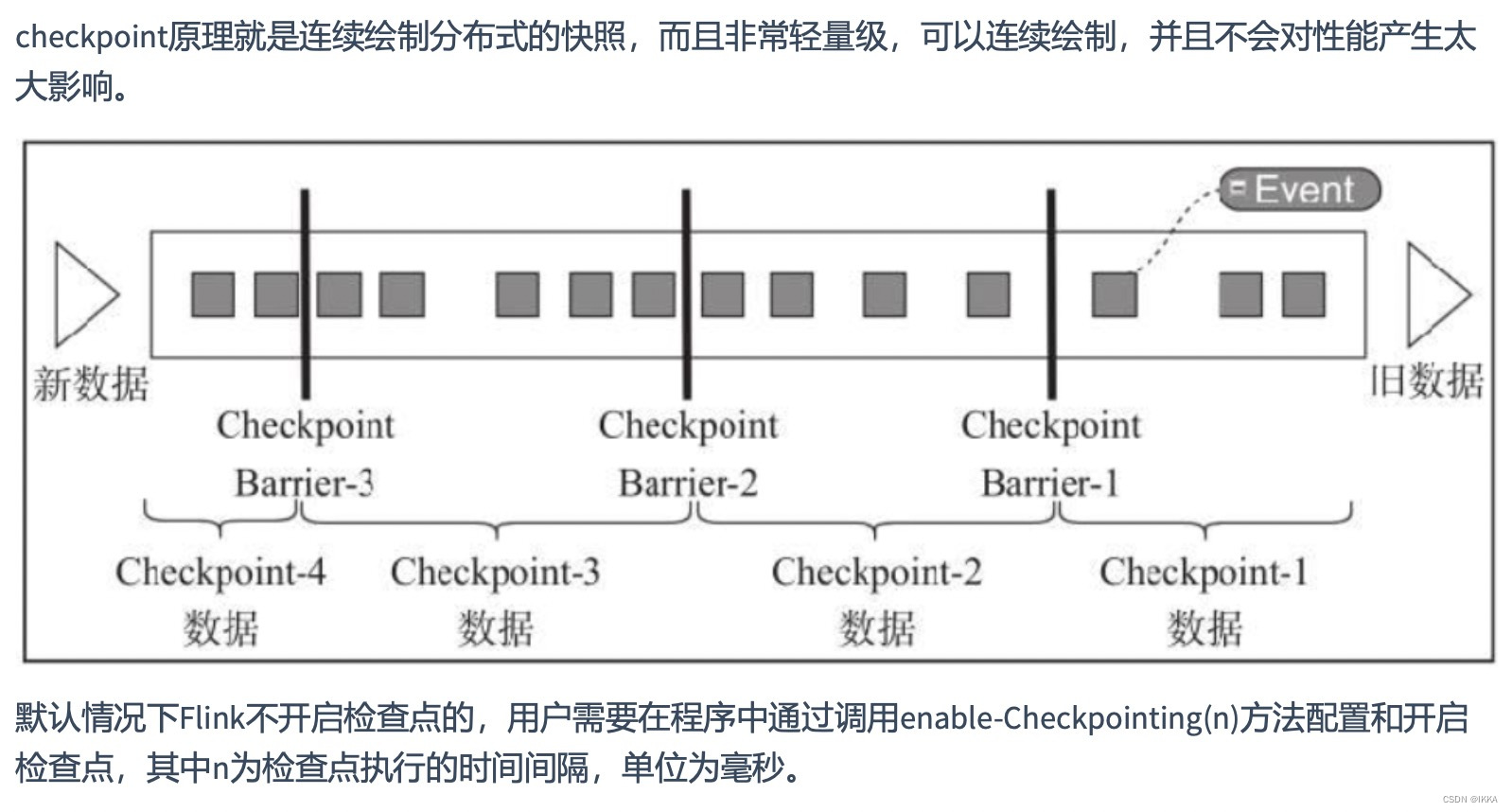
端到端exactly once


怎么实现exactly once

窗口函数

时间语义

watermark

版权归原作者 IKKA 所有, 如有侵权,请联系我们删除。