
一、数据介绍
1.数据链接
2.数据内容
此数据集包含北京市出租车从2008年2月2日到2008年2月8日的GPS轨迹数据,其中共包含10357辆出租车的数据,其中每个文件由出租车ID,时间、经度、纬度构成。该数据集中的轨迹点总数约为1500 万条,轨迹的总距离达到900万公里。其中连续两个轨迹坐标点的平均采样间隔约为 177秒,距离约为623米。这个数据集的每个文件,由出租车ID命名,包含一个出租车的轨迹。以下是一个文件的样例:
id time longitude latitude
1,2008-02-02 15:36:08,116.51172,39.92123
1,2008-02-02 15:46:08,116.51135,39.93883
1,2008-02-02 15:46:08,116.51135,39.93883
1,2008-02-02 15:56:08,116.51627,39.91034
二、数据预处理
1.合并文件
首先将所有的轨迹数据合并到一个文件中方便处理
import os
path = '数据所在文件夹路径'
files = [f for f in os.listdir(path) if f.endswith('.txt')]
#保存到merged_file.txt文件中
with open('merged_file.txt', 'w') as outfile:
for file in files:
with open(os.path.join(path, file)) as infile:
outfile.write(infile.read() + '\n')
2.读取文件
利用pandas读取合并后的文件
import pandas as pd
gps_data = pd.read_csv('合并文件路径',names=['id','time','longitude','latitude'])
- 读取结果

3.排序
按照id号和时间进行排序
gps_data=gps_data.sort_values(by=['id','time']).reset_index(drop=True)
- 排序后的结果

4.统计原始数据量
一共有17662984条gps数据
raw_length = len(gps_data) #值为17662984
5.加入时间戳
6.计算采样点之间的时间差
7.计算采样点之间的经纬度距离(Haversine距离计算)
8.计算采样点之间的速度
9.按照日期划分数据集
三、数据清洗
1.清除重复数据
2.清除超出地理坐标范围的轨迹
3.删除微小轨迹
【后面内容待更改】
5. 数据去重
由于数据中重复的数据是无效数据,因此需要去除
gps_data_drop_dup = gps_data.drop_duplicates().reset_index(drop=True)
- 去重之后的结果
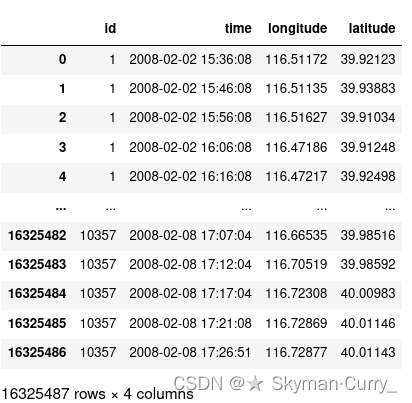
6.统计去重后的数据量
去重之后共有16325487条数据,去除了1337497条数据(7.5%的数据)
7.经纬度坐标分布
- 查看数据中最大与最小的经纬度
max_latitude = max(gps_data_1.latitude)
max_longitude =max(gps_data_1.longitude)
min_latitude =min(gps_data_1.latitude)
min_longitude =min(gps_data_1.longitude)
#运行结果
#(96.06767, 0.0, 255.3, 0.0)
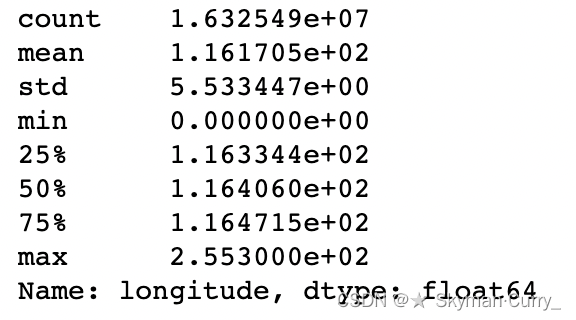
可以由此推断出经纬度坐标数据中存在异常,因此进一步查看情况
- 查看经纬度的数据分布
#查看经度数据分布
gps_data_1.longitude.describe()
#查看纬度分布
gps_data_1.latitude.describe()
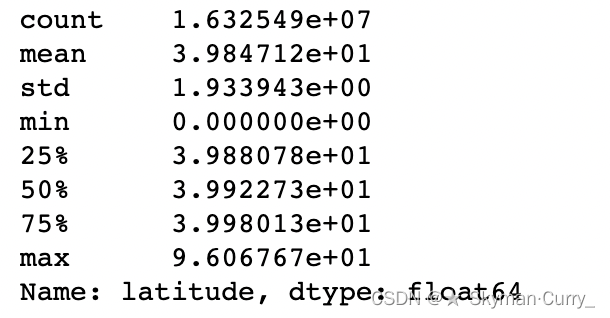
由此推断部分坐标点超出北京坐标范围,因此需要将这部分数据进行删除,为了方便后续研究,这里的范围采取北京是五环的坐标范围。
8.去除超出范围的数据
#如果坐标范围限定在北京市五环内那么范围是116.17 - 116.62,39.83 - 40.05,对gps数据进行筛选
gps_data_2 = gps_data_1[(gps_data_1['latitude']>39.83)&
(gps_data_1['latitude']<40.05)&
(gps_data_1['longitude']>116.17)&
(gps_data_1['longitude']<116.62)]
gps_data_2 = gps_data_2.reset_index(drop=True)
- 对坐标异常值清洗后的数据
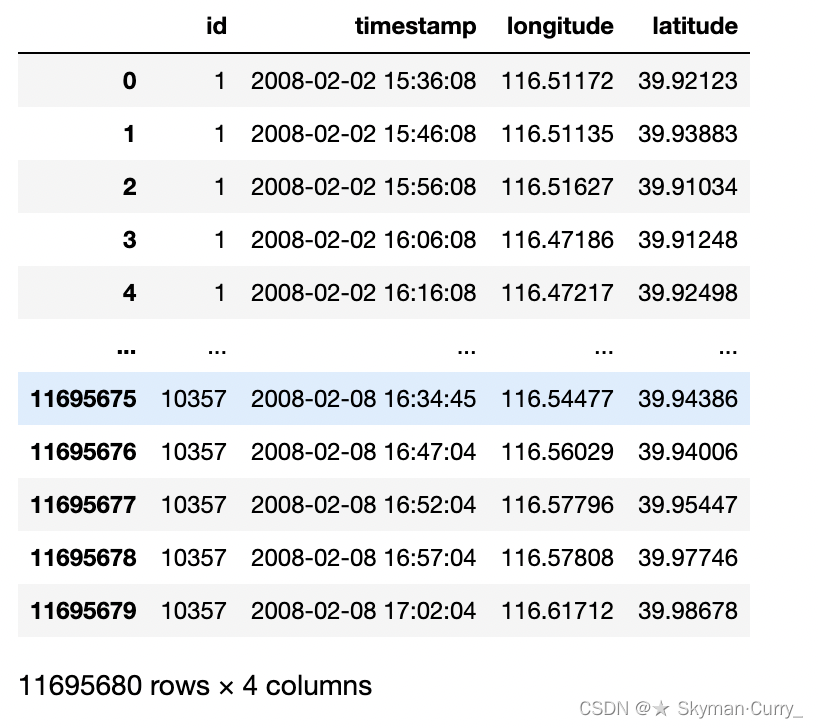
其中共清除4629807条数据(占26%)
9.保存数据
#保存数据清理之后的gps数据
gps_data_2.to_csv('文件路径',index=False)
**【由于以上处理方式会误删很多点,因此没有往后继续做】 **
二、数据预处理【第二版】
三、地图匹配
1.获取路网数据
路网数据从openstreatmap获取,利用osmnx包下载,获取之后保存为shapefile文件以便地图匹配时需要
import osmnx as ox
#获取路网数据
beijing_road=ox.graph_from_bbox(40.05,39.83,116.62,116.17,network_type='drive')
#保存为shapefile文件
ox.save_graph_shapefile(beijing_road,'文件路径')
2.可视化路网
#可视化路网
ox.plot_graph(beijing_road,figsize=(15,15),show=False,close=False,node_size=4)

3.将gps数据投影到路网上
- 先投影一部分数据看看
import matplotlib.pyplot as plt
#1.先将gps点的经纬度提取出来
latitude = gps_data_2.latitude.to_list()
longitude = gps_data_2.longitude.to_list()
#投影
fig,ax = ox.plot_graph(beijing_road,figsize=(15,15),show=False,close=False,node_size=4)
ax.scatter(longitude[:100000],latitude[:100000],s=0.5,alpha=1,c='red')#投影10万个坐标点
plt.show()

- 投影全部坐标点

很明显,坐标点大部分都偏离了路网 ,由第一个图看出,路网坐标系和gps轨迹点的坐标系应该是一致的,不然会发生大的偏移,因次这里只需要进行地图匹配即可
版权归原作者 ★ Skyman·Curry_ 所有, 如有侵权,请联系我们删除。