
引入 ——为什么分布式系统需要用第三方软件?
这里会讨论线程与线程之间的通信以及进程与进程之间的通信。
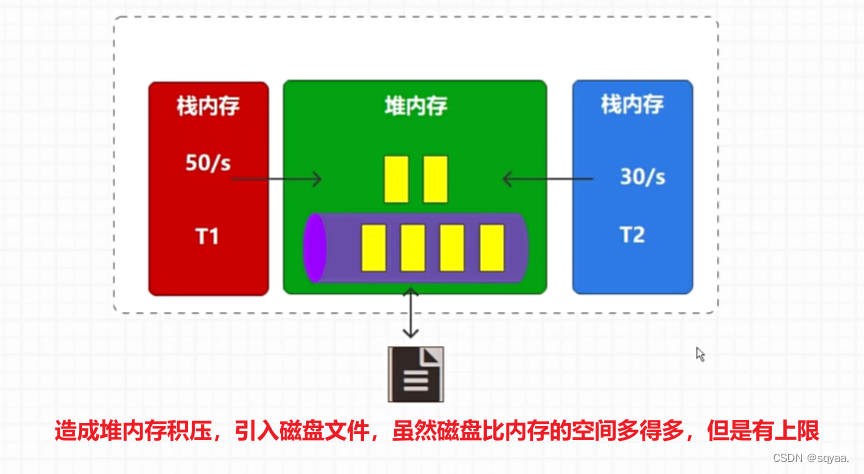
- 1.线程与线程之间通信,每个线程都有自己的栈空间,共享堆完全可以,通过共享内存来实现消息共享,如下图。
存在的问题:但是如果一个线程t1给堆内存发布数据比较快,接收数据的t2线程接收比较慢,就会导致每秒20条数据被积压来不及处理,积压数据就会导致内存不够用(对吞吐量造成影响,导致系统不稳定,严重情况会导致系统不可用),内存溢出,然后引入磁盘文件,虽然磁盘文件存储的数据比内存多,但也有上限。

- 2.进程和进程之间通过socket(网络数据流)来通信 ,两个不同的进程申请到的内存是不一样的,所以不能像线程那样去共用内存,
存在问题:第一个进程用于生产数据,第二个进程和第三个进程用来接收数据,如果进程1的数据要同时发给进程二和进程3,那进程1就要同时发送两份数据.如果是进程一发送不同的数据给进程2和进程3,就会增加进程1的逻辑处理难度,会增加系统响应的时间,消耗更多的系统资源,耦合性也高·。如果数据重复发送,也会对系统吞吐量造成影响,最根本还是系统资源不太够。这里谈到的问题也就是进程之间直接交互造成的问题,即耦合性高。
所以就引入中间缓冲区——第三方软件,又称为消息中间件,缓冲区的目的就是中转和临时存储,从而降低系统之间的耦合性。解耦合,负载均衡,削峰填谷。
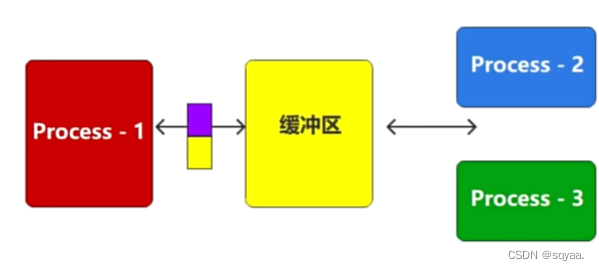
JMS
kafka没有完全遵循jms思想,但是借鉴了jms思想。
JMS(Java Message Service)是Java平台上用于消息传递的API标准。它定义了一种用于创建、发送、接收和读取消息的方式,使得不同应用程序之间可以通过消息进行通信。JMS的核心思想包括以下几个方面:
- 消息模型:JMS定义了两种基本消息模型,即点对点模型(Point-to-Point)和 发布/订阅模型(Publish/Subscribe)。点对点模型中,消息被发送到特定的队列,只有一个消费者可以接收并处理消息。发布/订阅模型中,消息被发送到主题(Topic),多个消费者可以订阅主题并接收消息。
- 消息生产者:负责创建并发送消息到消息中间件。消息生产者将消息发送到指定的队列或主题,并且可能会设置消息的属性、头信息等。
- 消息消费者:负责从消息中间件接收并处理消息。消息消费者可以根据需要从特定队列或主题中订阅消息,并在消息到达时进行处理。
- 消息中间件:提供消息传递的基础设施,负责存储、路由和传递消息。消息中间件通常是一个独立的服务器,它提供了可靠的消息传递机制,以及高效的消息路由和处理能力。暂时存储和中转。
Kafka借鉴了JMS的一些思想,比如消息模型中的发布/订阅模型,以及消息的生产者和消费者模式。但Kafka与JMS也有一些不同之处,比如Kafka更加注重持久化和水平扩展等方面的设计。因此,虽然Kafka没有完全遵循JMS的思想,但在某些方面受到了JMS的启发和借鉴。

各类消息中间件对比


在 **单机吞吐量 **方面,activemq,rabbitmq要比rocketmq,kafka第一个数量级,rocketmq和Kafka都是十万级吞吐量,支持高吞吐。
在 **消息可靠性 **方面,rocketmq和Kafka可以通过参数优化配置,做到0丢失。rabbitmq基本不丢失,activemq有较低的概率丢失数据。
在 **时效性 **方面,rabbitmq可以达到微秒级别,其他都是毫秒级别。
在 **topic主题分区数量对吞吐量的影响 **方面上,对于rocketmq,topic数量可以达到几百/几千量级,但是对于Kafka,topic数量可以达到几百,如果再多的话,吞吐量会大幅度下降。
在 **可用性 **方面,rocketmq和Kafka的可用性非常高,支持分布式架构,rabbitmq和activemq的可用性高,支持分布式架构,
** 功能支持 方面以及其他**方面。
rocketmq是阿里开发,社区活跃度不高,mq功能较为完整,分布式,扩展性好。
Kafka是开源的,社区活跃度极高,高吞吐量,只是借鉴了jms规范,并没有完全的遵守,所以只支持简单的mq功能,在大数据领域应用广泛。、
rabbitmq开源稳定,社区活跃度高,并发能力强,延时低,性能极好。
通过上面各种消息中间件的对比,大概可以了解,在大数据场景中我们主要采用 kafka 作为消息中间件,而在JaveEE开发中我们主要采用 ActiveMQ、RabbitMQ、RocketMQ作为消息中间件。如果将 JavaEE和大数据在项目中进行融合的话,那么 Kafka 其实是一个不错的选择。
组件
消息队列就是内存模型,为了数据存储更加可靠,就不能只存储在内存中,引入磁盘文件。这样既保证了数据的高效,也保证了安全可靠。为了不仅仅能存储数据,并且保证数据的顺序不会被打乱,引入了偏移量,方便数据的有序访问,就可以按照某个标记或者某种标记的顺序进行访问,
以下是 Kafka 的一些主要组件:将JMS中的message换成record。
- Broker:Kafka 集群中的每个节点都是一个 Kafka Broker。Broker 负责存储和管理数据,以及处理来自生产者和消费者的请求。
- Topic:在 Kafka 中,消息被发布到特定的主题(Topic)。每个主题都是一个逻辑的数据流,可以有一个或多个生产者向其发布消息,并且可以有一个或多个消费者从中读取消息。每个主题可以有多个分区,从而实现消息的水平扩展和并行处理。
- Producer:生产者是将消息发布到 Kafka 主题的应用程序。生产者负责将消息发送到 Kafka Broker。
- Consumer:消费者是从 Kafka 主题中读取消息的应用程序。消费者订阅一个或多个主题,并从中拉取消息。
- Consumer Group:消费者组是一组消费者的集合,它们共同消费一个或多个主题中的消息。Kafka 使用消费者组来实现消息的负载均衡和水平扩展。
- ZooKeeper:ZooKeeper 是 Kafka 集群的协调服务。它用于管理和协调 Kafka Broker 的状态、主题配置和消费者组的信息。
- Partition:每个主题可以分成多个分区,每个分区在物理上由一个或多个 Broker 托管。分区使得主题能够水平扩展,允许 Kafka 处理大规模数据流。
- Replication:Kafka 使用副本来提供容错性和高可用性。每个分区都有一个或多个副本,这些副本被分布在不同的 Broker 上,以防止数据丢失。
这些组件共同构成了 Kafka 的核心架构,使其成为一个高效、可靠的流处理平台。

bin/kafka-topics.sh --create --topic <topic_name> --bootstrap-server <bootstrap_server_address> --partitions <num_partitions> --replication-factor <replication_factor>

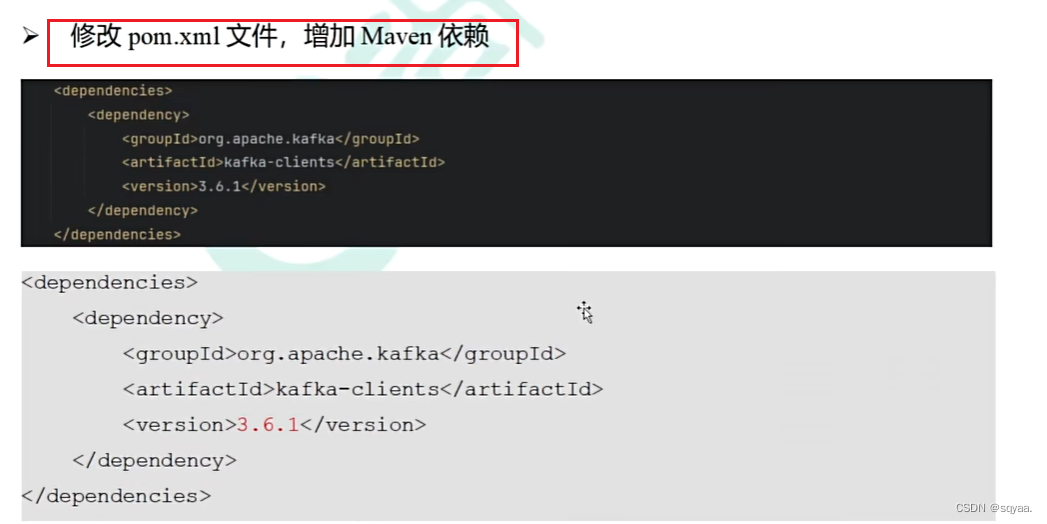
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.6.1</version>
</dependency>
</dependencies>
架构推演发展历程——备份实现安全可靠
**🤔1. **分析下图架构存在的问题:
当只有一个节点broker,当他宕机了,其他consumer就发从.log磁盘文件中获取数据了,甚至有可能数据还没存到文件中就丢失了。所以不行。引入横向扩展(增加集群)或者纵向扩展(增加系统资源配置,采用io效率更好的固态硬盘)。这里纵向扩展是解决不了问题的,采用横向扩展增加多个broker。这种可以在一定程度缓解io热点问题但不能解决,如下图:其实并没有解决,因为从同一个topic中进行获取。
**🤔2. **所以引入对topic进行分区partition,并用不同的标记进行区分。此时consumer就可以订阅到相关主题中的所有数据如图1.2,
1.2


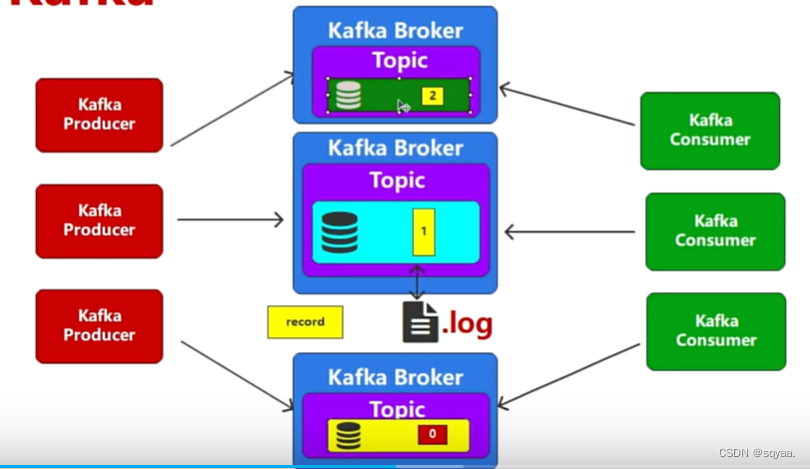

**🤔3. ** 但是观察1.2图,相当于consumer发送了更多的请求,那这个还是不行呀,于是kafka
将多个消费者当作一个整体对主题进行消费,

🤔4. 当partition-1宕机,可以发现即使数据保存在文件中也不是完全可靠安全的,
所以进行交叉备份,kafka称之为副本,多个副本中只有一个可以进行读写,其他都是用来备份,

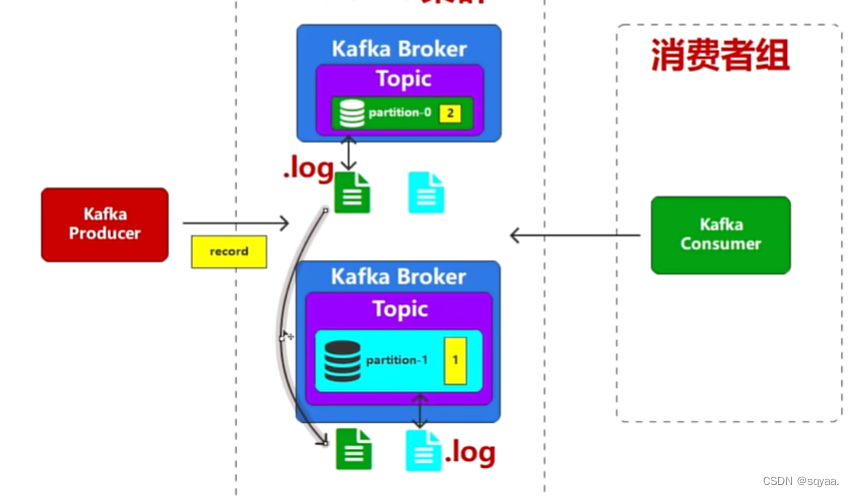
小结:
1.多个节点broker形成集群;
2.分区(编号);
- 副本leader和follower
不能因为某个节点由于网络或者某些问题宕掉 而导致整个集群不可用,所以一般在所有broker中会选择一个管理者
在Kafka中,每个主题被分成一个或多个分区,每个分区可以有多个副本(leader,follower)。这些副本分布在不同的Kafka节点上,确保了数据的冗余和容错性。当主题中的消息被发布到一个分区时,这些消息会被复制到该分区的所有副本中。这意味着即使某个节点发生故障,仍然可以从其他节点的副本中获取数据,确保了系统的高可用性和持久性。
因此,在Kafka中,副本的概念实际上是一种备份机制,它确保了数据的可靠性和可恢复性。每个副本都可以提供数据的读写操作,这样就实现了数据的高可用性和负载均衡。

kafka中的broker(节点)相当于一台服务器,用于存储和管理生产者发送的消息以及消费者获取的消息。每个Broker都有一个唯一的ID,并且可以在集群中进行扩展和复制,以提供高可用性和容错性。存储处理负载均衡
controller控制整个集群,某个节点出现问题对集群影响不大,但是如果controller出现问题就会影响很大,所以1.管理者备份, 2让节点都可能做管理者,zookeeper选举

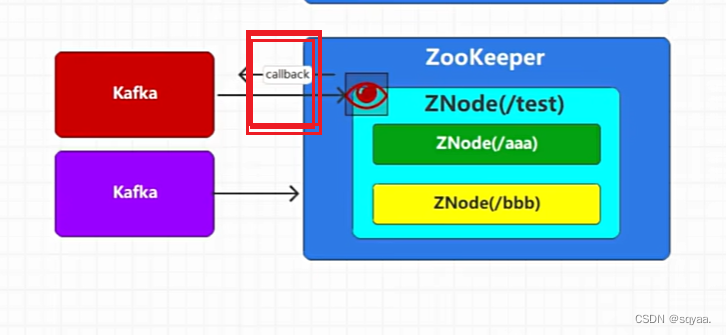
Zookeeper ,Znode
每个Kafka 的broker都会在Zookeeper中注册一个节点znode,用于存储broker的元数据信息,znode包含了broker的id信息,主机号,端口号,znode还扮演着协调集群的各种操作,如领导选举,分区分配,副本管理,Kafka集群中的broker们通过与ZooKeeper交互,可以实时感知集群的状态以及变化,从而协同工作并保持整个集群的稳定性和可靠性。

- 集群协调: Zookeeper 管理 Kafka 集群中的 broker 节点,并协调它们的工作。它负责选举 leader,维护集群的元数据以及监控 broker 的健康状态。
- Leader 选举: 在 Kafka 中,每个分区都有一个 leader broker 负责处理读写请求,而其他副本(replica)只是用来备份数据。Zookeeper 负责协调 leader 的选举过程,确保在 leader 失效时能够快速选举出新的 leader。
- 元数据管理: Kafka 集群的元数据包括 topic、partition、replica 等信息。Zookeeper 负责存储和维护这些元数据,以及通知 broker 有关元数据变更的消息。
- 消费者组管理: Zookeeper 也负责管理 Kafka 消费者组的状态。它跟踪每个消费者的偏移量(offset),确保每个消费者从正确的位置开始消费消息。
- 心跳检测: Zookeeper 监控 Kafka 集群中各个节点的健康状态,包括 broker 和消费者。它定期发送心跳消息,以确保集群中的各个节点都处于正常运行状态。
kafka连接Zookeeper就会创建节点,kafka就可以进行数据的存储和访问,但是创建节点只能创建一次,持久性节点:kafka切断和zookepper之间的连接,节点自动被删除就是临时(黄色)节点,否则就是持久化节点。
znode节点有自动监听功能,连接超时数据变化,回调,从而对集群管理

controller的选举
,broker是kafka集群当中有很多broker,每个broker都有自己的id,对于broker启动zookeeper的时候就会出现一个黄色字体的controller_broker id=1,临时节点,关闭连接就会消失。多个集群节点的kafka会选择一个管理者,管理者作为controller,
当1挂掉,2,3都在对它建立连接请求,
对于kafka实现节点管理还用到zookeeper这样的软件,以后会根据kafka自身的算法实现集群管理从而提高性能降低耦合性。
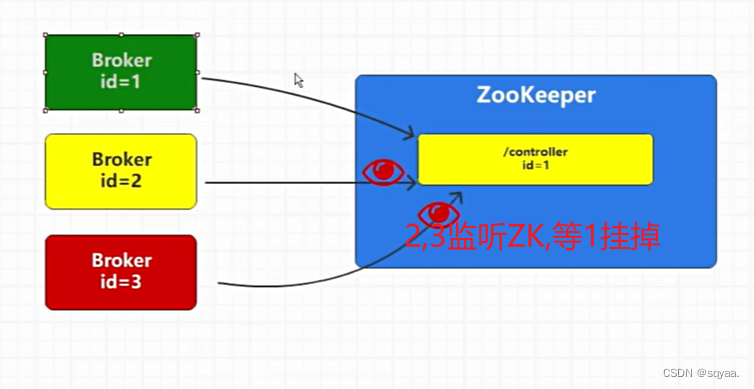

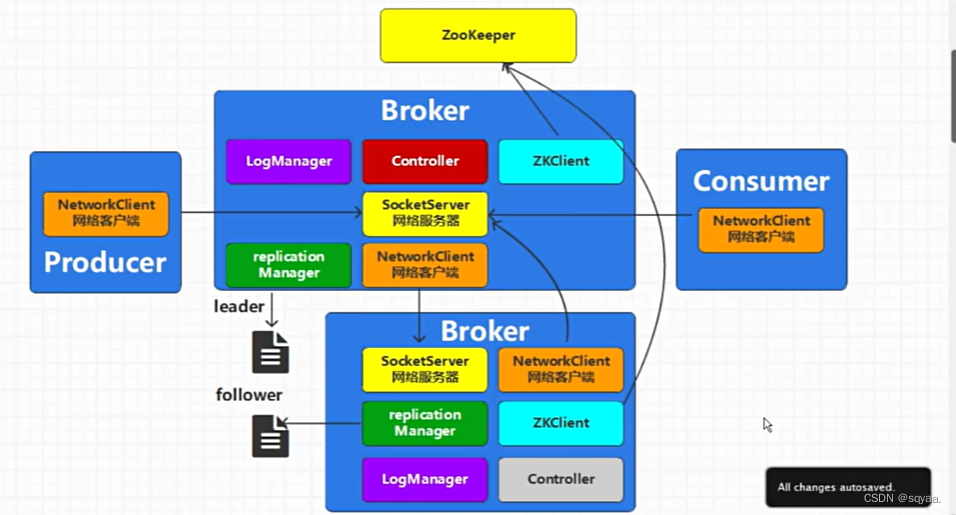
controller和broker底层通信原理
在 Apache Kafka 中,Controller 和 Broker 的通信是 Kafka 集群管理的核心部分。Kafka 集群由多个 brokers 组成,其中一个 broker 会被选举为 Controller。Controller 负责管理集群的元数据和各种关键的管理任务,如负载均衡、broker 故障处理、topic 分区的分配和复制等。
集群中有很多broker节点,第一个被创建的节点会被选举成为controller,

监听controller和brokers/ids不同。后者是监听子节点的变化。



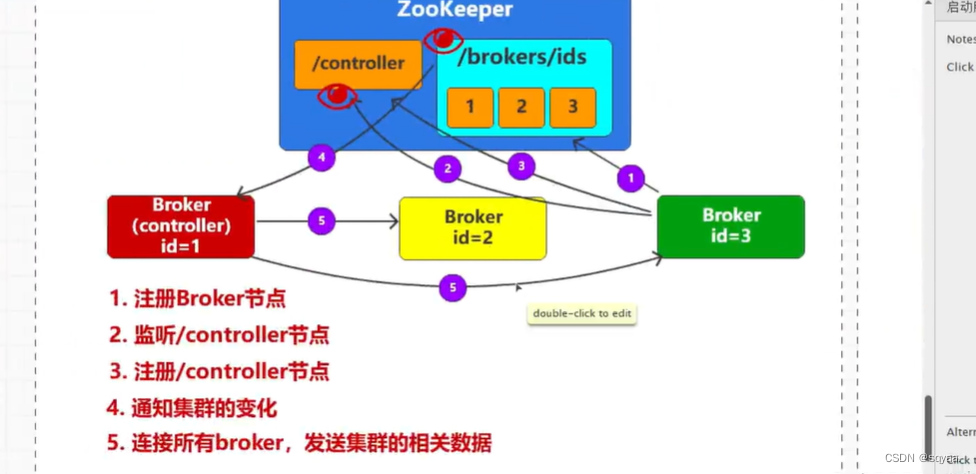
** 底层实现:**
一部分是broker和zookeeper之间的通信,broker内部会有zookepper的客户端工具
controller与broker之间是进程之间的通信,

BROKER内部组件

replication Manager 副本管理器
Kafkacontroller
kafak接受数据的处理是由kafka的apis处理的 ,应用处理接口


所以我们来想一想broker到底有什么用吧!
- 是kafka集群中的每个节点,节点就是服务器,可以用来处理生产者和消费者的请求, 存储分区 副本
- 每个 Broker 可以存储一个或多个分区的副本,当生产者发送消息时,消息会被写入对应分区的 Leader 副本,然后通过副本同步机制复制到其他副本。
- 生产者和消费者通过与 Broker 进行通信来发送和接收消息,Broker 之间也会进行数据的同步和复制,以保持数据的一致性和可用性。同步和复制就是副本同步机制,防止单个节点故障,提高整个机群的容错能力。
topic创建
 默认情况下,topic自动创建好,修改参数auto.create.topics.enaable,
默认情况下,topic自动创建好,修改参数auto.create.topics.enaable,
NewTopic newTopic = new NewTopic("my_topic", 1, (short) 1);
主题名称:._字母英文构成;
分区数量:int类型
副本因子·replicationcount:short类型
版权归原作者 sqyaa. 所有, 如有侵权,请联系我们删除。