
聚合函数与分组查询
一、聚合函数
说明:聚合函数用来计算一组数据的集合并返回单个值,通常用这些函数完成:个数的统计,某列数据的求和,某列数据的最大值,最小值,或者是平均值。
1、常见的聚合函数
函数说明COUNT([DISTINCT] expr)返回查询到的数据的数量SUM([DISTINCT] expr)返回查询到的数据的总和,不是数字没有意义AVG([DISTINCT] expr)返回查询到的数据的平均值,不是数字没有意义MAX([DISTINCT] expr)返回查询到的数据的最大值,不是数字没有意义MIN([DISTINCT] expr)返回查询到的数据的最小值,不是数字没有意义
聚合函数一般在
select
语句中使用,此时
select
每处理一条记录时都会将对应的参数传递给这些聚合函数。
需要注意的是:聚合函数忽略空值,即
NULL
值不会参与运算的。
2、实例
2.1 统计班级共有多少同学
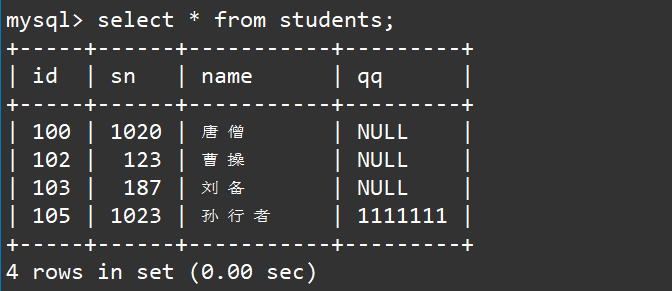
这里我们使用下面的学生表来进行演示,学生表中的内容如下:
使用
*做统计
这里我们直接使用
count(*)
进行聚合统计,表示对所有的列数据进行统计:
select count(*) from students;
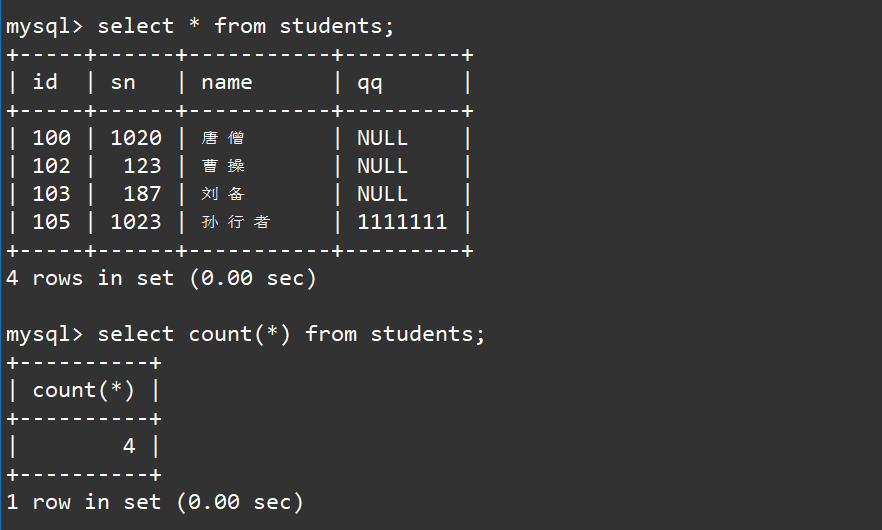
这里的统计原理也很简单,其实就是使用了
select *
将每一条记录都拿到,然后将每一条待处理记录时都传递给这个
count
聚合函数,然后我们就能够拿到数据的总个数了。
2.2 统计班级收集的QQ号有多少个
值得注意的是:我们没有对qq号码进行非空约束,我们继续使用聚会函数
count
进行统计。
select count(qq) from students;
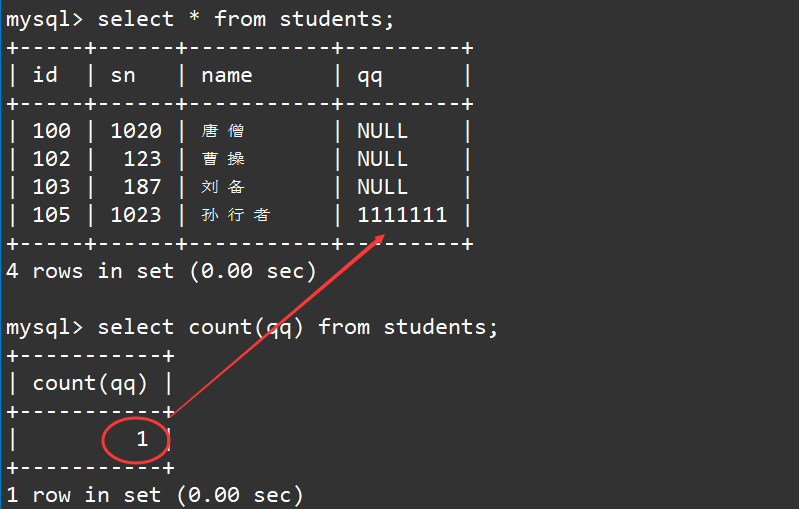
结果为1,这证明聚合函数确实会忽略空值,即
NULL
值不会参与运算的。
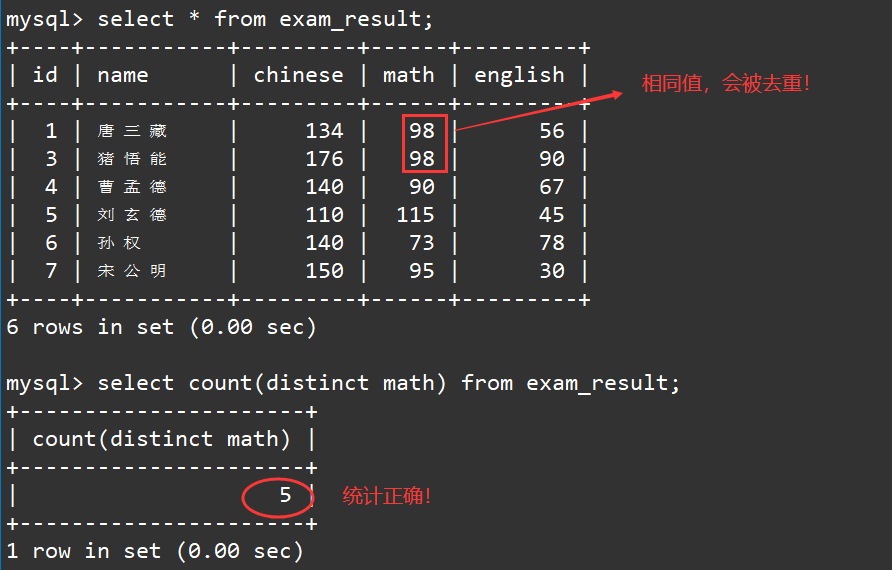
2.3 统计本次考试的数学成绩分数的个数有几个
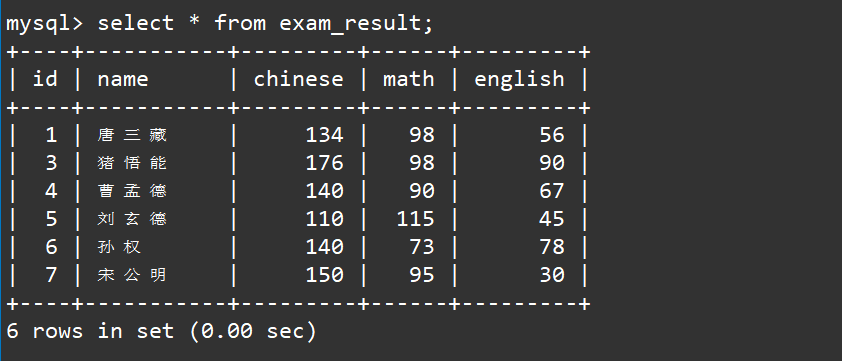
下面是我们的测试用例表:
注意本题目要求的是数学成绩的个数,不是数学成绩的值,这意味着我们需要对相同的数学成绩的值进行先去重,然后再进行聚合统计,对于去重我们可以使用
distinct
进行去重,然后再使用
count
进行聚合统计。
select count(distinct math) from exam_result;
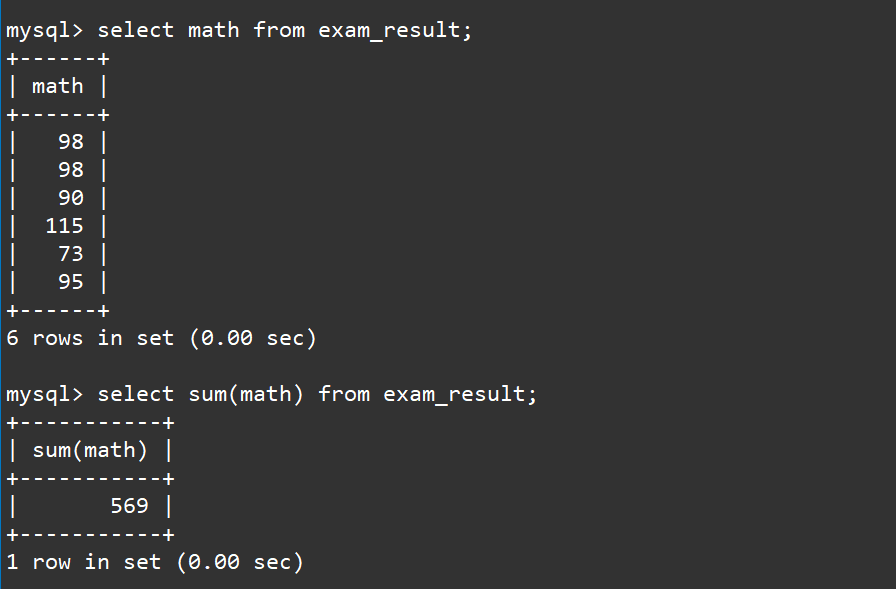
2.4 统计数学成绩总分
对于统计数学成绩的总分其实就是对数据进行求和,我们可以使用
sum
函数来进行求和:
select sum(math) from exam_result;
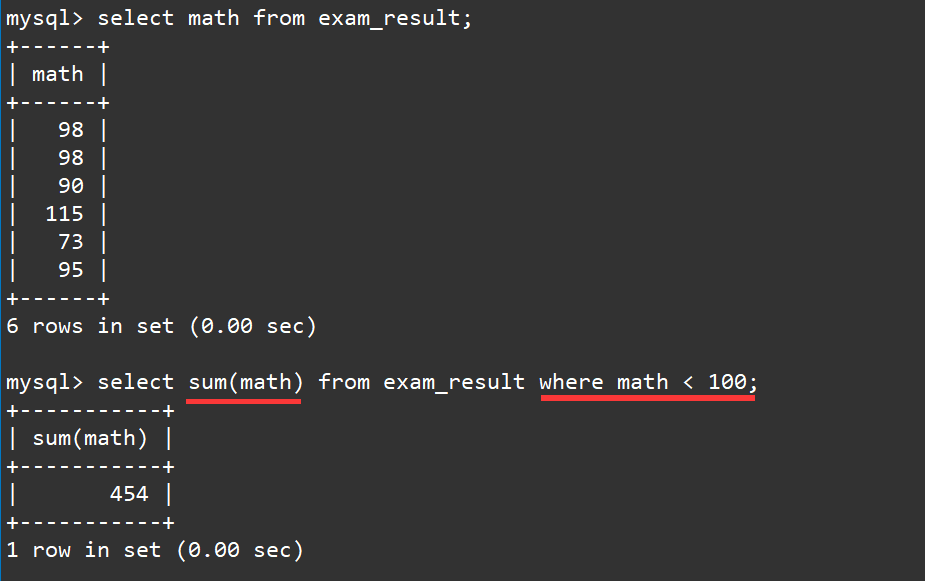
2.5 统计不满100分的数学成绩总分
在刚才的示例中我们已经求得数学成绩的总分了,对于不满100分的人我们可以使用
where
子句进行筛选得到。
select sum(math) from exam_result where math <100;
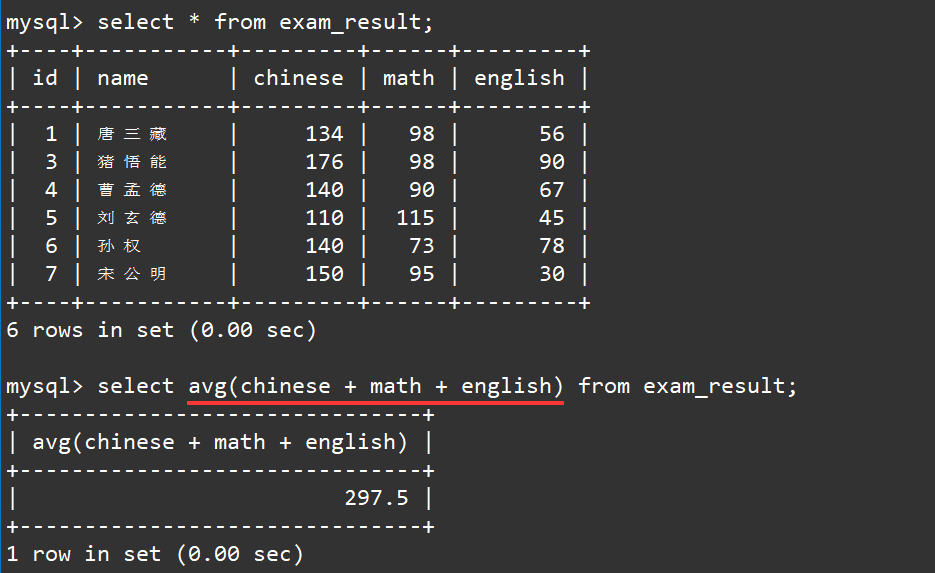
2.6 统计总分的平均分
对于平均分我们可以使用
avg
函数进行求得:
select avg(chinese + math + english) from exam_result;
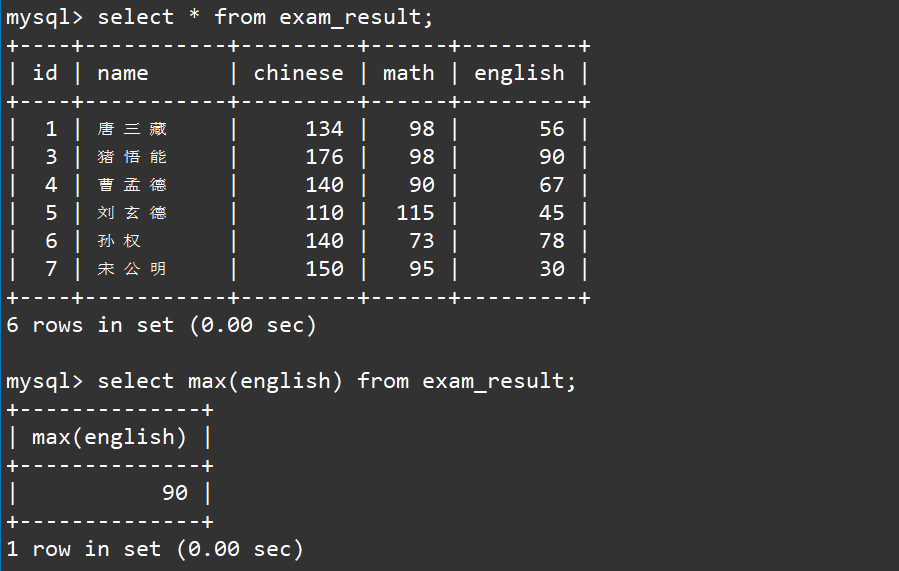
2.7 求英语最高分
求最高分其实就是求最大值,我们可以使用
max
函数进行求最大值:
select max(english) from exam_result;
二、分组查询
不知刚才你注意到没,前面我们进行聚合统计时都是在对整张表进行聚合统计,但是有时我们想要对不同的情况进行分别统计。
例如在一个班级之中,有男生和女生,我们想要得到男生和女生中英语成绩的最高分分别是多少?我们发现我们再使用
max
函数是没有办法达到我们想要的目的的,但是如果我们先对班级中的男女生进行分组,然后又分别进行聚合统计,使用
max
函数就能够达到我们想要的目的了!
所以分组是数据库最重要任务之一,要将行分组,我们可以使用
GROUP BY
子句。
1、group by子句
分组查询的SQL语法如下:
SELECT column1 [, column2], ... FROM table_name [WHERE ...] GROUP BY column[, ...][order by ...][LIMIT ...];
(小声bb:虽然语法看起来很难,但是在使用一两次以后你就会发现其实很简单)
说明一下:
- SQL中大写的表示关键字,[ ]中代表的是可选项。
- 查询SQL中各语句的执行顺序为:
where、group by、select、order by、limit。 group by后面的列名,表示按照指定列进行分组查询。
2、准备工作
分组查询测试表 —— 雇员信息表
准备工作,创建一个雇员信息表(来自oracle 9i的经典测试表)
- EMP员工表
- DEPT部门表
- SALGRADE工资等级表
雇员信息表数据库文件
拿到该数据库文件以后,我们可以先打开该文件进行查看其内容:
vim scott_data.sql
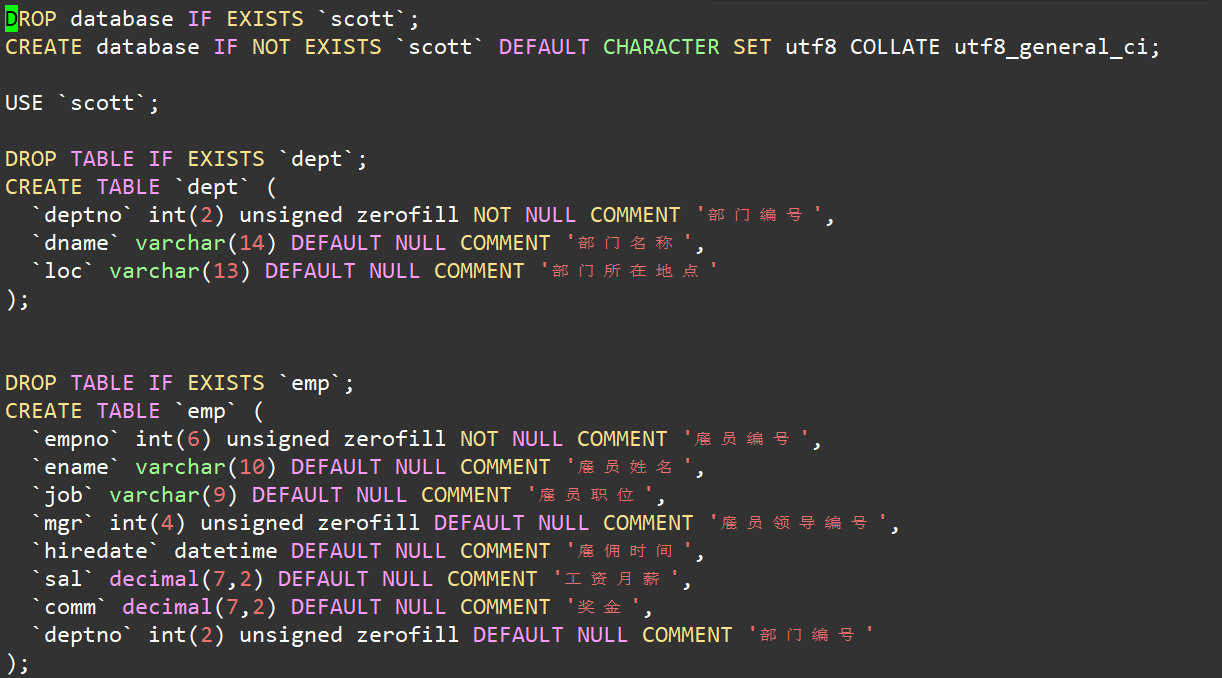
我们会发现其里面都是SQL记录,对于MySQL我们备份其数据库时,其实备份的全部都是一条条有效的SQL记录,通过重新执行这些SQL,我们便能够得到和原来一摸一样数据库。
接下来我们就可以在
mysql
中将这个数据库给创建出来了:
source 该文件的绝对路径;
例如我这里是:
source /root/MySQL/scott_data.sql;
执行成功!
然后我们查询我们的数据库,发现数据库中多了一个scott的数据库:
show databases;
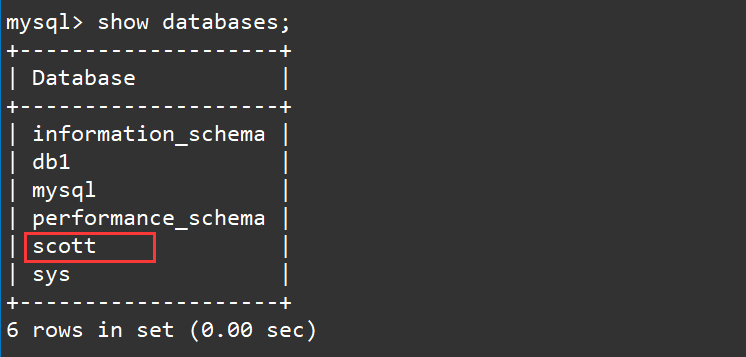
我们使用这个数据库并显示数据库中的所有表
use scott;
show tables;
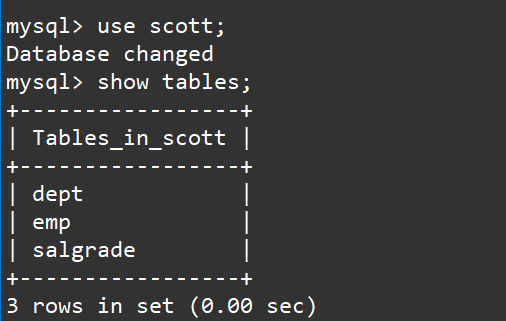
这三张表就是我们所说的:
- EMP员工表
- DEPT部门表
- SALGRADE工资等级表
我们先分别查看一下表结构和表内容:
- 查看员工表结构
desc emp;
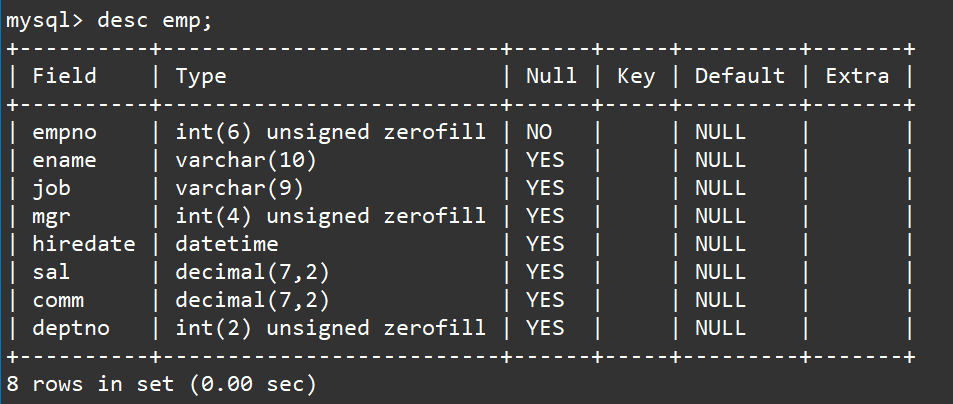
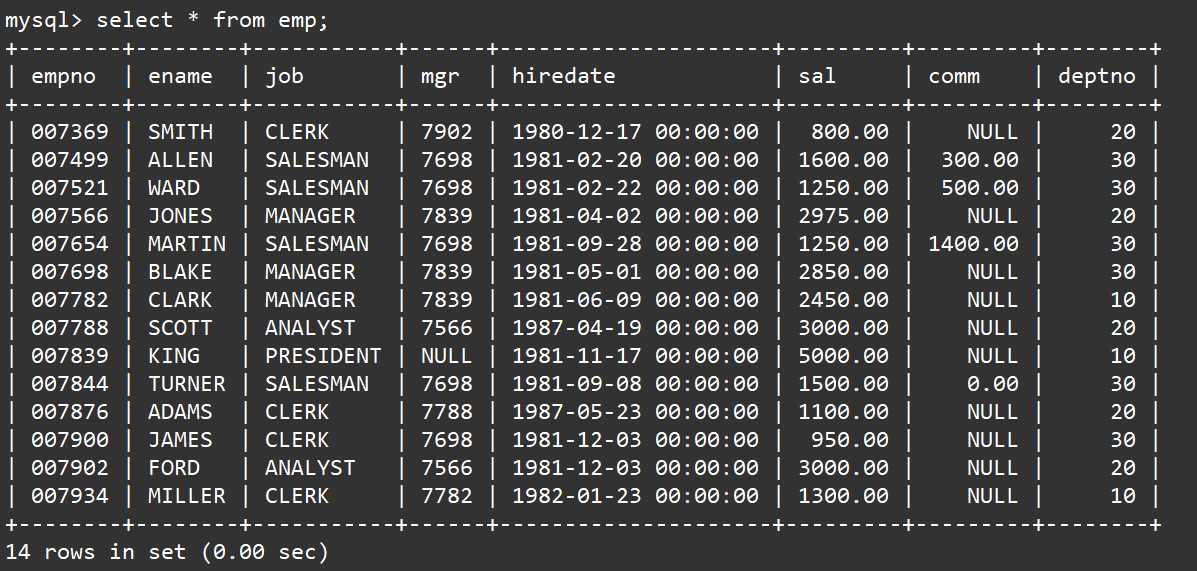
- 查看员工表内容
select * from emp;
- 查看部门表结构
desc dept;
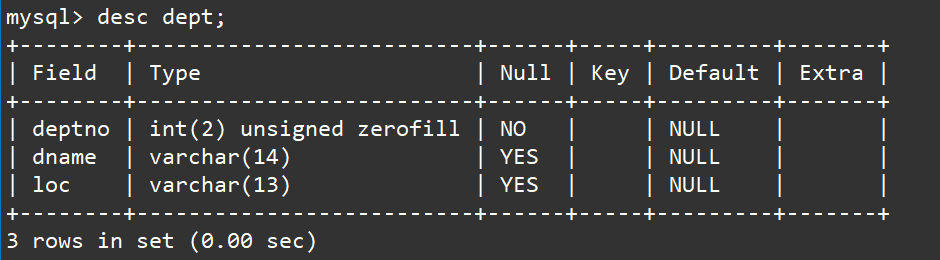
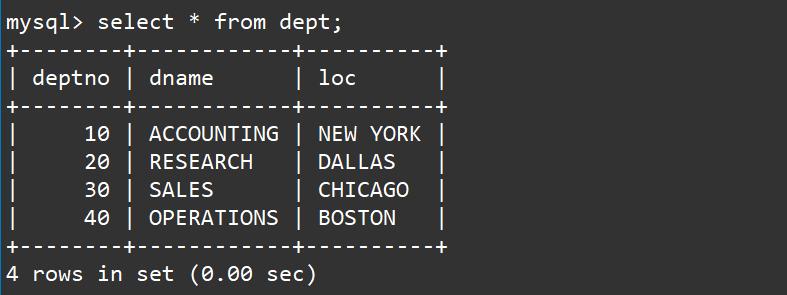
- 查看部门表内容
select * from dept;
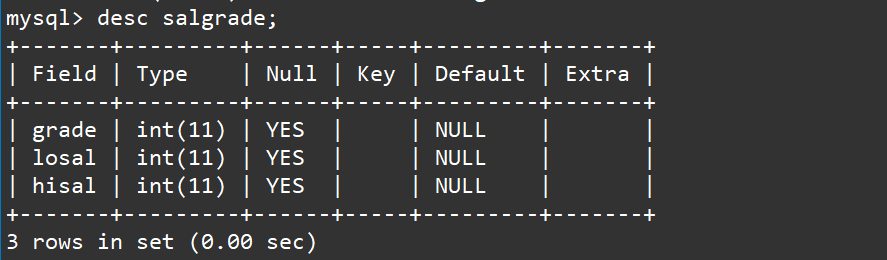
- 查看工资等级表结构
desc salgrade;
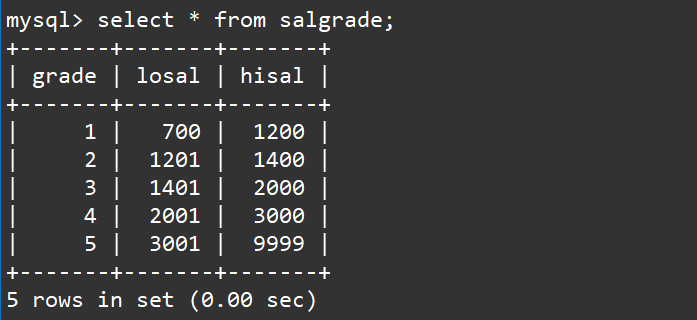
- 查看工资等级表内容
select * from salgrade;
3、实例
3.1 显示每个部门的平均工资和最高工资
由于要显示每个部门平均工资和最高工资,所以我们一定要借助
group by
来将这个整表进行划分为多个组,然后我们再使用
avg
与
max
函数来对工资分别求平均和最高工资。
所以我们可以这样进行查询:
select deptno,avg(sal),max(sal)from emp groupby deptno;
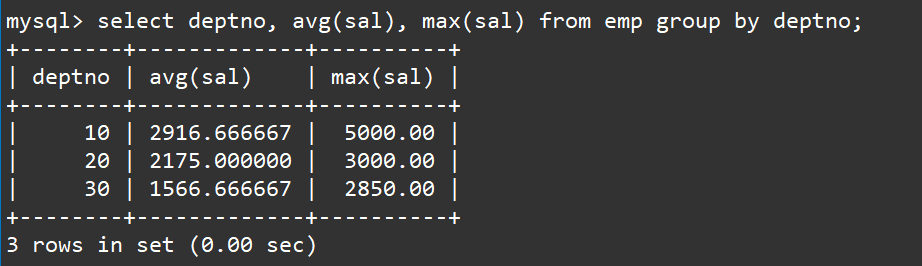
说明一下: 上述SQL会先将表中的数据按照部门号进行分组,然后各自在组内做聚合查询得到每个组的平均工资和最高工资。
3.2 显示每个部门的每种岗位的平均工资和最低工资
现在对于我们来说:“求平均工资和最低工资”,是很简单的事情,但是题目的要求:显示每个部门的每种岗位,显然要求我们进行两次分组,对于
group by
子句来说,我们可以使用
,
分割,来进行多个条件分组。
select deptno, job,avg(sal),min(sal)from emp groupby deptno, job;
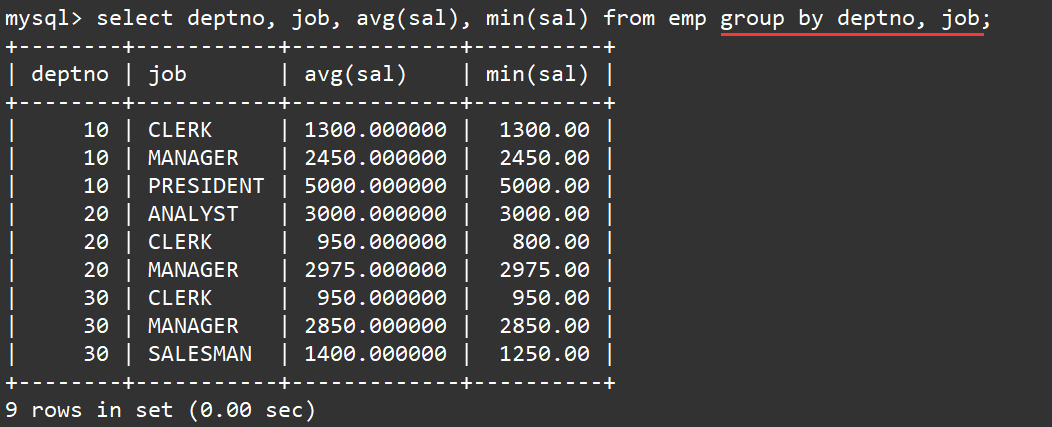
说明:
group by
子句中可以指明按照多个字段进行分组,各个字段之间使用逗号隔开,分组优先级与书写顺序相同。
4、having 条件
在讲解此条件之前我们先继续来解决下面的问题:
3.3 显示平均工资低于2000的部门和它的平均工资
在这里我们会发现,我们必须先要拿到平均工资的值,然后再根据平均工资进行筛选。
假设这里我们使用
where
子句,我们会发现在
where
子句中我们无法表示平均工资的(聚合函数不能够在
where
子句中使用的,因为
where
子句是对单个记录进行筛选,而聚合函数是对整个结果集进行计算的)
就算假设我们能够表示平均工资,我们知道
where
子句的执行优先级是很高的,于是就会先按平均工资进行筛选,然后再拿到平均工资的值。显然这个逻辑是有问题的。
为了解决这个问题我们就要学习一下
HAVING
条件了,
having
也是一个筛选条件。
含有
having
子句的SQL如下:
SELECT...FROM table_name [WHERE...][GROUPBY...][HAVING...][orderby...][LIMIT...];
说明一下:
- SQL中大写的表示关键字,[ ]中代表的是可选项。
- SQL中各语句的执行顺序为:
where、group by、select、having、order by、limit。 having子句中可以指明一个或多个筛选条件。
having子句和where子句的区别
where子句放在表名后面,而having子句必须搭配group by子句使用,放在group by子句的后面。where子句是对整表的数据进行筛选,having子句是对分组后的数据进行筛选。where子句中不能使用聚合函数和别名,而having子句中可以使用聚合函数和别名。where子句的执行优先级很高,而having的执行优先级很低。
于是上面的问题就被转化为了下面的问题了:
- 先统计每个部门的平均工资。
- 然后通过
having子句筛选出平均工资低于2000的部门。
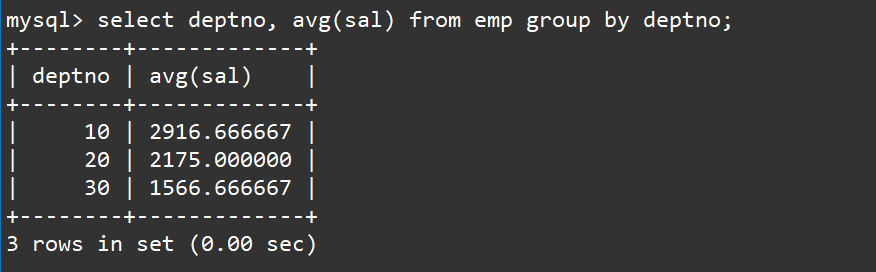
统计每个部门的平均工资
select deptno, avg(sal) from emp group by deptno;
通过
having
子句筛选出平均工资低于
2000
的部门
select deptno, avg(sal) 平均工资 from emp group by deptno having 平均工资<2000;

需要注意的是:聚合函数的执行优先级通常是在SQL查询中确定的,这句的SQL执行顺序如下:
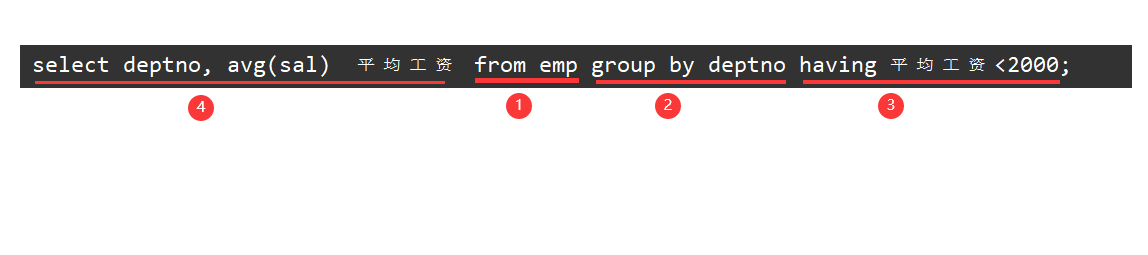
这句SQL的执行顺序如下:
- FROM子句:首先,从"emp"表中检索数据。
- GROUP BY子句:然后,根据"deptno"列将结果集分组。相同"deptno"值的行将被分为一组。(AVG函数计算:接下来,在每个分组中计算"sal"列的平均工资)。
- HAVING子句:然后,在HAVING子句中筛选出平均工资小于2000的分组。
- SELECT子句:最后,在SELECT子句中选择"deptno"和平均工资作为结果返回。
面试题:SQL查询中各个关键字的执行先后顺序:
from > on> join > where > group by > with > having > select > distinct > order by > limit
版权归原作者 看到我请叫我滚去学习Orz 所有, 如有侵权,请联系我们删除。