
一、开发环境:Linux Centos7
二、下载datax工具
DataX工具下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
三、搭建环境
3.1 上传压缩包并解压
使用远程连接工具连接服务器,将下载好的datax.tar.gz上传到指定位置(我是自定义文件夹下,方便自己好找)。
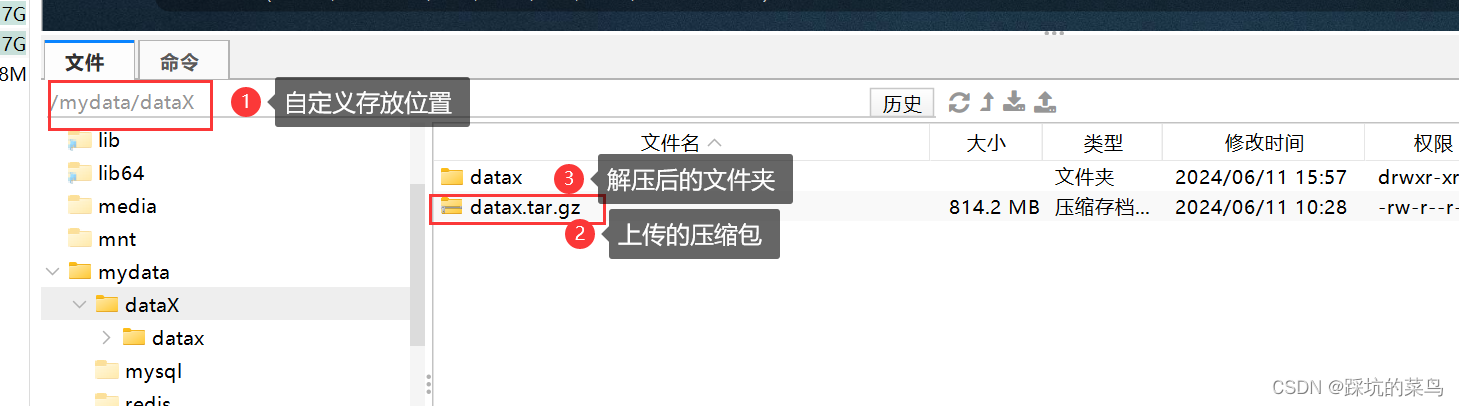
3.1.1 进入安装目录:
cd /mydata/dataX

3.1.2 解压
解压之后会出现如上图序号3所示文件夹 datax。
tar -xzvf datax.tar.gz

3.2 删除隐藏文件
不删除会影响的执行.
3.2.1 进入datax文件夹
cd datax

3.2.2 删除隐藏文件
find ./ -name '._*' -print0 |xargs -0 rm -rf

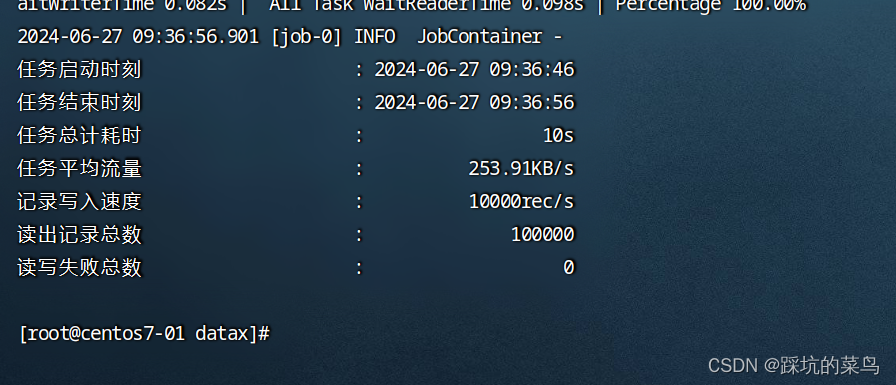
3.3 执行datax自带的测试脚本
./bin/datax.py job/job.json

如果执行结果如下图效果,就没问题。
四、全量同步数据
4.1 获取脚本模板
./bin/datax.py -r oraclereader -w mysqlwriter

结果如下:
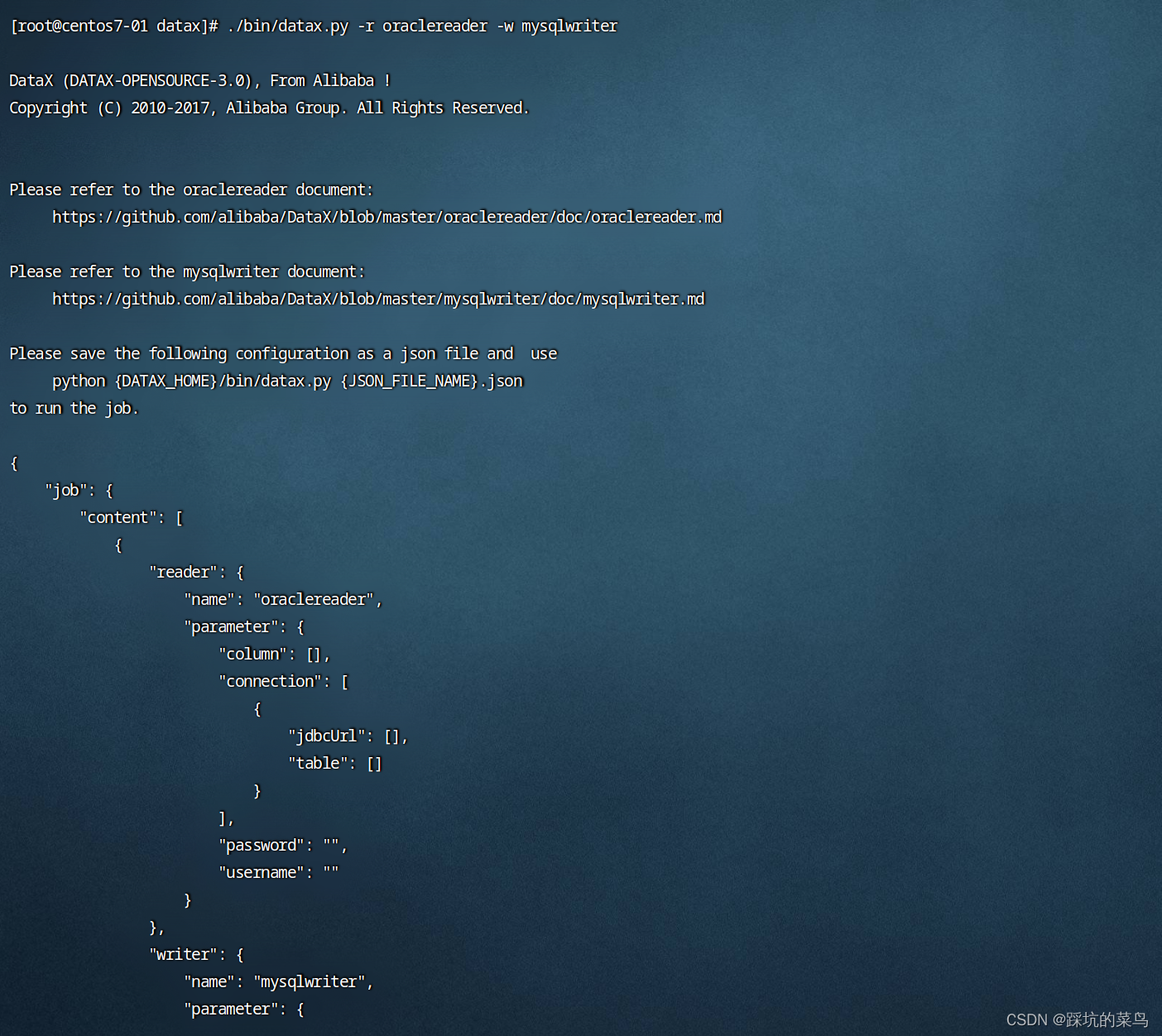
复制脚本json代码。
4.2 编写脚本
执行以下命令,新建json脚本文件,并粘贴刚才复制的脚本模板,然后根据自己的需求修改脚本。
vi job/oracle_to_mysql.json

{
"job": {
"content": [
{
"reader": {
"name": "oraclereader",
"parameter": {
"column": [
"ID",
"NAME",
"TYPE",
"NO",
"CREATE_TIME"
],
"splitPk": "ID",
"where" : "NAME is not null",
"connection": [
{
"jdbcUrl": ["jdbc:oracle:thin:@172.xx.xx.xx:1521:orcl"],
"table": ["XXX.XXX"]
}
],
"password": "xxxxxx",
"username": "xxxx"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"id",
"name",
"type",
"no",
"create_time"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://172.xxx.xxx.xx:3306/xxx?useUnicode=true&characterEncoding=UTF-8",
"table": ["xxxx"]
}
],
"username": "xxxxx",
"password": "xxxxx",
"preSql": [],
"session": ["set session sql_mode='ANSI'"],
"writeMode": "insert"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
tips1: (如果执行脚本报错连接不上oracle数据库,再看此提示)
"jdbcUrl": ["jdbc:oracle:thin:@172.xx.xx.xx:1521:orcl"], 这里我在此狠狠栽跟头了【流下没有技术的眼泪】。端口号1521后边的“xx”通常情况下就是“orcl”,但是有的数据库不是orcl。具体请看附录-温馨提示-tips1.
tips2: 带条件的读取源库数据同步到目标库。上图所示:"where" : "NAME is not null",表示只把源库中NAME字段值不为空的数据同步到目标库。
4.3 执行脚本
tips3:先看一下datax使用的mysql连接依赖是哪个版本的,在下图所示:
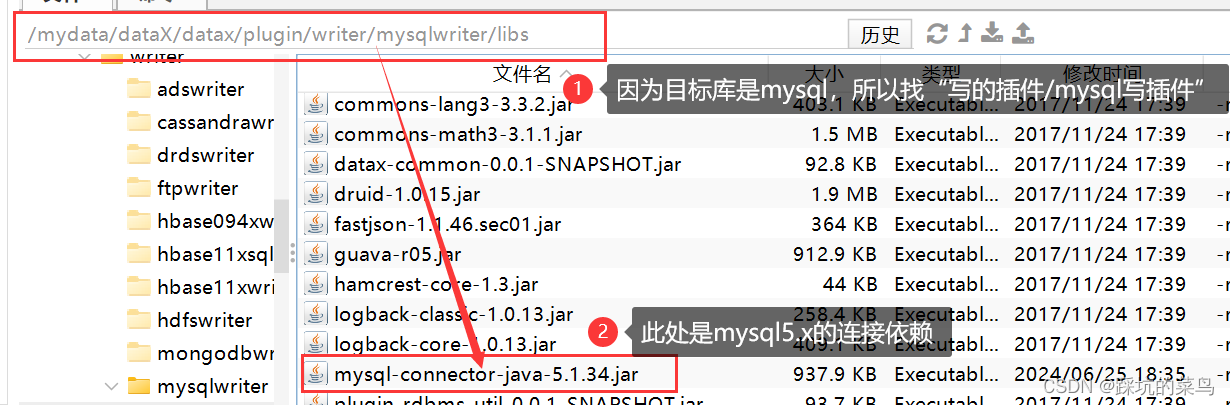

如果你是装的mysql8, 那需要对应版本的依赖,替换到此处的5.x。如果装的5.x的,可以忽略此提示。
./bin/datax.py job/oracle_to_mysql.json

等待他解析并执行脚本即可,执行完毕会打印如下日志:
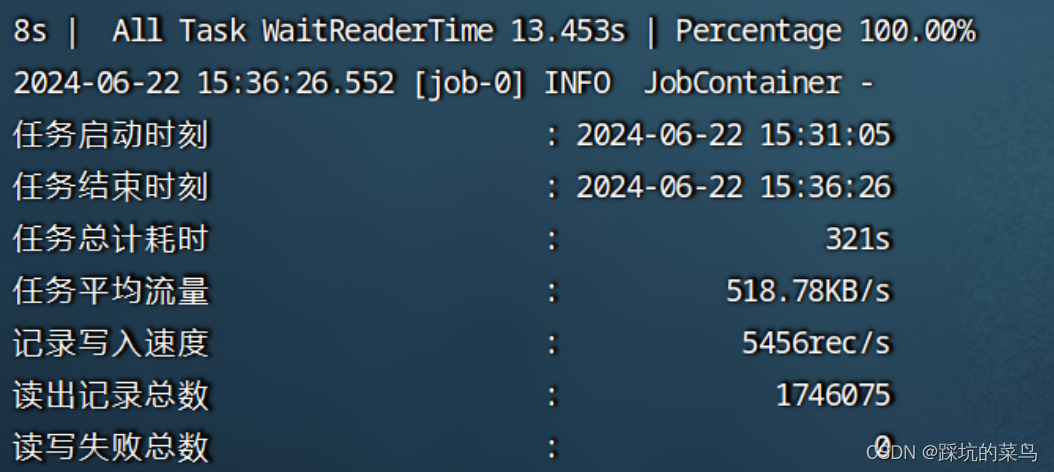
五、增量同步
5.0 修改json脚本
vi job/oracle_to_mysql.json

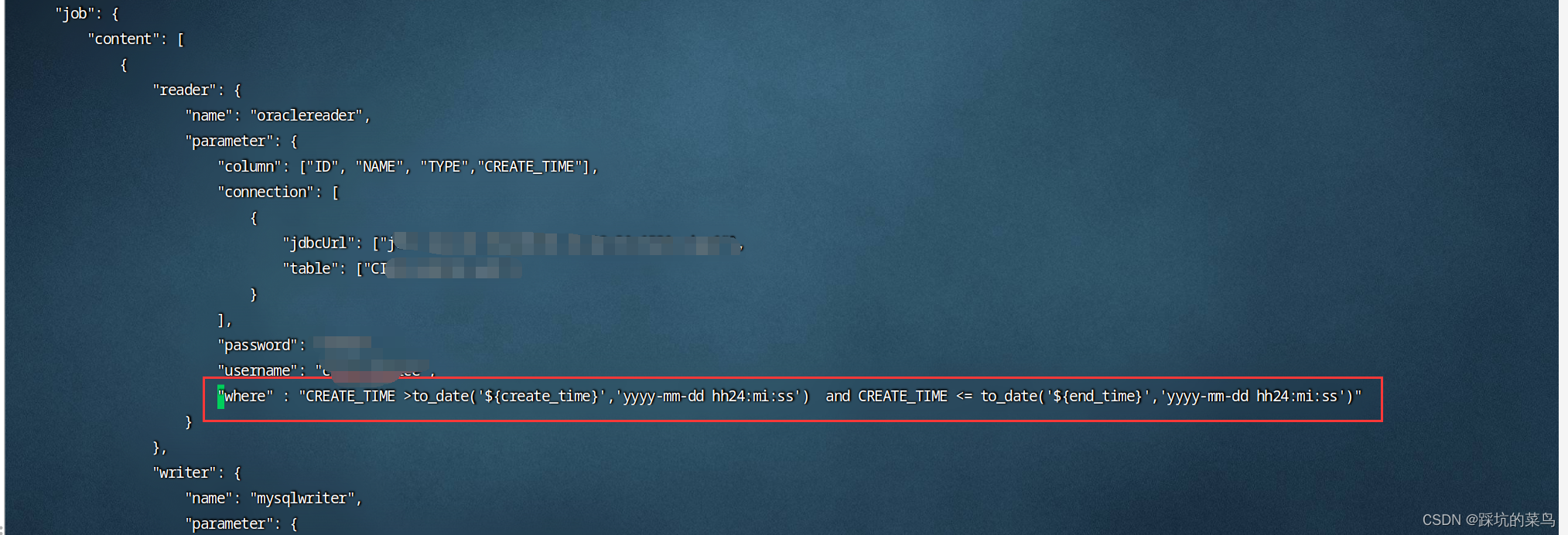
修改reader的where值
"where" : "CREATE_TIME >to_date('${create_time}','yyyy-mm-dd hh24:mi:ss') and CREATE_TIME <= to_date('${end_time}','yyyy-mm-dd hh24:mi:ss')"
tips4: 表中需要有个“CREATE_TIME”字段且有值,不然不同步,我自己测试的
5.1 创建增量脚本文件
vi job/increment_sync.sh

5.2 编写脚本
#!/bin/bash
source /etc/profile
#当前时间戳
cur_time=$(date +%s)
#结束时间
end_time="'$(date -d @$cur_time +"%Y-%m-%d %H:%M:%S")'"
#开始时间,为当前时间的前120s
create_time="'$(date -d @$(($cur_time-120)) +"%Y-%m-%d %H:%M:%S")'"
# 执行datax脚本,传入时间范围
/mydata/dataX/datax/bin/datax.py /mydata/dataX/datax/job/oracle_to_mysql.json -p "-Dcreate_time=$create_time -Dend_time=$end_time" &
5.3 给脚本文件赋权限
chmod -R 777 job/increment_sync.sh

5.4 设置 crontab 定时任务
vi /etc/crontab


然后保存并退出即可。
六、附录
6.1 温馨提醒
tips1:
总是报数据库连接失败:数据库名称错误,请检查数据库实例名称或者联系DBA确认该实例是否存在并且在正常服务]. - 具体错误信息为:
java.sql.SQLException: Listener refused the connection with the following error:
ORA-12505, TNS:listener does not currently know of SID given in connect descriptor
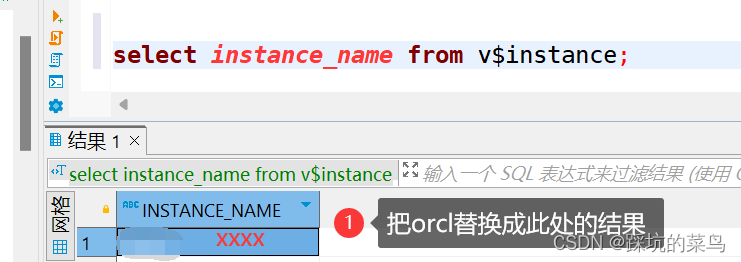
已解决 ,是SID的问题.错误重点是:listener does not currently know of SiDa given in connect descriptor,以及强调:SID!SERVICE NAME。查询数据库的SID,发现数据库的SID确实变了,不一样,导致连接错误,更换连接的SID,就可以解决。查询数据库的SID:
select instance name from V$instance
6.2 声明与感谢
该教程也是我工作中要完成数据库同步的需求时,参考大佬们的教程,并且实践后结合自己遇见的问题总结出来的笔记,希望对大家有用,避免踩坑,提高效率!非常感谢大佬的教程解我燃眉之急!以下是大佬具体教程:
DataX oracle同步mysql(全量和增量)_oracle 全量 增量-CSDN博客
最后,如果朋友您发现有不足之处或者错误,非常欢迎您的指正,一起交流学习,菜鸟互啄哈哈哈共同进步!
(总结不易,求免费的赞一下,感谢!)
版权归原作者 踩坑的菜鸟 所有, 如有侵权,请联系我们删除。