
文章目录
一、Kafka简介
在讲解为何Kafka在2.8版本开始会“抛弃”Zookeeper?之前,先来介绍一下kafka和Zookeeper在kafka中的作用?
Apache Kafka最早是由Linkedin公司开发,后来捐献给了Apack基金会。
Kafka被官方定义为分布式流式处理平台,因为具备高吞吐、可持久化、可水平扩展等特性而被广泛使用。目前Kafka具体如下功能:
- 消息队列,Kafka具有系统解耦、流量削峰、缓冲、异步通信等消息队列的功能。
- 分布式存储系统,Kafka可以把消息持久化,同时用多副本来实现故障转移,可以作为数据存储系统来使用。
- 实时数据处理,Kafka提供了一些和数据处理相关的组件,比如Kafka Streams、Kafka Connect,具备了实时数据的处理功能。
下面这张图是Kafka的消息模型:
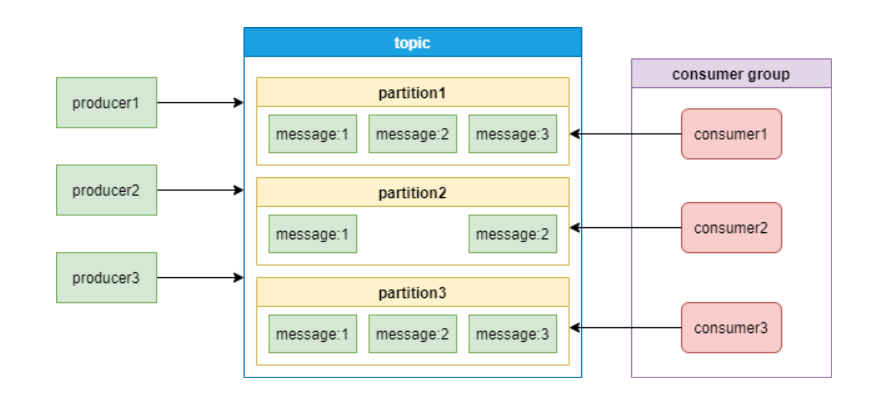
通过上面这张图,介绍一下Kafka中的几个主要概念:
- producer和consumer: 消息队列中的生产者和消费者,生产者将消息推送到队列,消费者从队列中拉取消息。
- consumer group:消费者集合,这些消费者可以并行消费同一个topic下不同partition中的消息。
- broker:Kafka集群中的服务器。
- topic:消息的分类。
- partition:topic物理上的分组,一个topic可以有partition,每个partition中的消息会被分配一个有序的id作为offset。每个consumer group只能有一个消费者来消费一个partition。
想了解关于kafka和Zookeeper更多的的知识点可以参考我以下几篇文章:
- 分布式开源协调服务——Zookeeper
- 大数据Hadoop之——Zookeeper鉴权认证(Kerberos认证+账号密码认证)
- Kafka原理介绍+安装+基本操作(kafka on k8s)
- kafka 磁盘扩容与数据均衡实在操作讲解
二、Kafka和Zookeeper关系
Kafka架构如下图: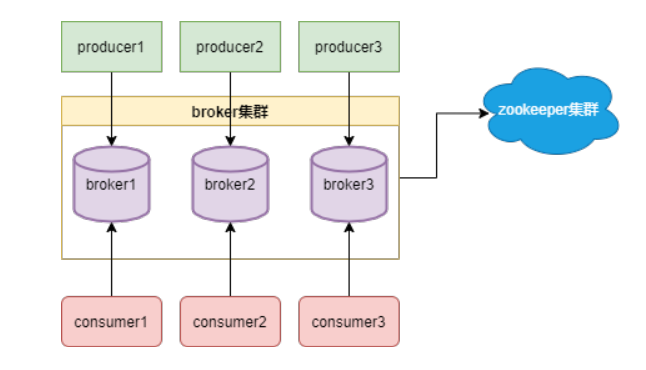
Kafka 和 ZooKeeper 是两个独立但通常一起使用的分布式系统组件。它们之间的关系可以简述为 Kafka 使用 ZooKeeper 来进行一些集群管理和协调任务。以下是它们之间主要的关系和合作方面:
- 协调服务: ZooKeeper 通常用于提供分布式系统的协调服务。在 Kafka 中,ZooKeeper 负责维护 Kafka 集群的一些元数据(metadata)和领导者选举(leader election)等协调工作。Kafka 利用 ZooKeeper 来确保在集群中的不同节点之间进行协调和通信。
- 元数据存储: Kafka 利用 ZooKeeper 存储一些关键的元数据,如主题(topics)、分区(partitions)的分布情况、Broker 节点的信息等。这些元数据对于 Kafka 的正常运行非常重要,ZooKeeper 提供了一个可靠的存储和协调的环境。
- Leader 选举: 在 Kafka 中,每个分区都有一个领导者(leader)负责处理读写请求,而其他副本(followers)用于备份。ZooKeeper 参与了领导者选举的过程,确保在分区的多个副本之间选出一个合适的领导者。
- 健康监控: Kafka 可以利用 ZooKeeper 来进行集群的健康监控。通过与 ZooKeeper 通信,Kafka 节点可以了解到集群中其他节点的状态信息,以及集群是否处于正常运行状态。
- 消费者组协调: 在 Kafka 消费者群体中,ZooKeeper 用于协调和追踪消费者的位置信息,确保每个分区只有一个消费者处理,以实现负载均衡。
需要注意的是,随着 Kafka 版本的升级,Kafka 在一定程度上减少了对 ZooKeeper 的依赖,引入了 Kafka Controller 来执行一些元数据的管理和协调任务,目标是逐步减少对 ZooKeeper 的使用。这一变化被称为 KIP-500,已在 Kafka 2.8.0 版本中引入。这意味着未来的 Kafka 版本可能会更加独立于 ZooKeeper。
三、Kafka Controller介绍
我们看到了Kafka对Zookeeper的依赖非常大,Kafka离开Zookeeper是没有办法独立运行的。那Kafka是怎么跟Zookeeper进行交互的呢?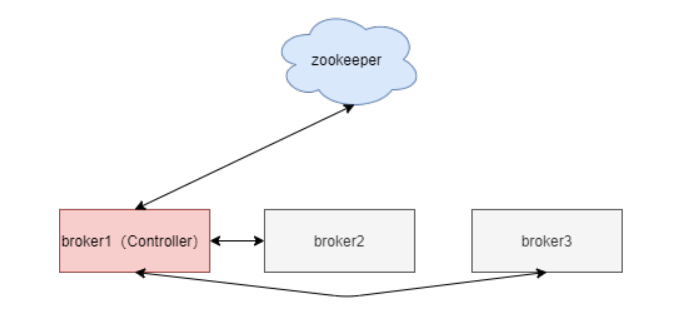
Kafka集群中会有一个broker被选举为Controller负责跟Zookeeper进行交互,它负责管理整个Kafka集群中所有分区和副本的状态。其他broker监听Controller节点的数据变化。
Controller的选举工作依赖于Zookeeper,选举成功后,Zookeeper会创建一个/controller临时节点。
Controller具体职责如下:
- 监听分区变化:比如当某个分区的leader出现故障时,Controller会为该分区选举新的leader。当检测到分区的ISR集合发生变化时,Controller会通知所有broker更新元数据。当某个topic增加分区时,Controller会负责重新分配分区。
- 监听topic相关的变化
- 监听broker相关的变化
- 集群元数据管理
下面这张图展示了Controller、Zookeeper和broker的交互细节: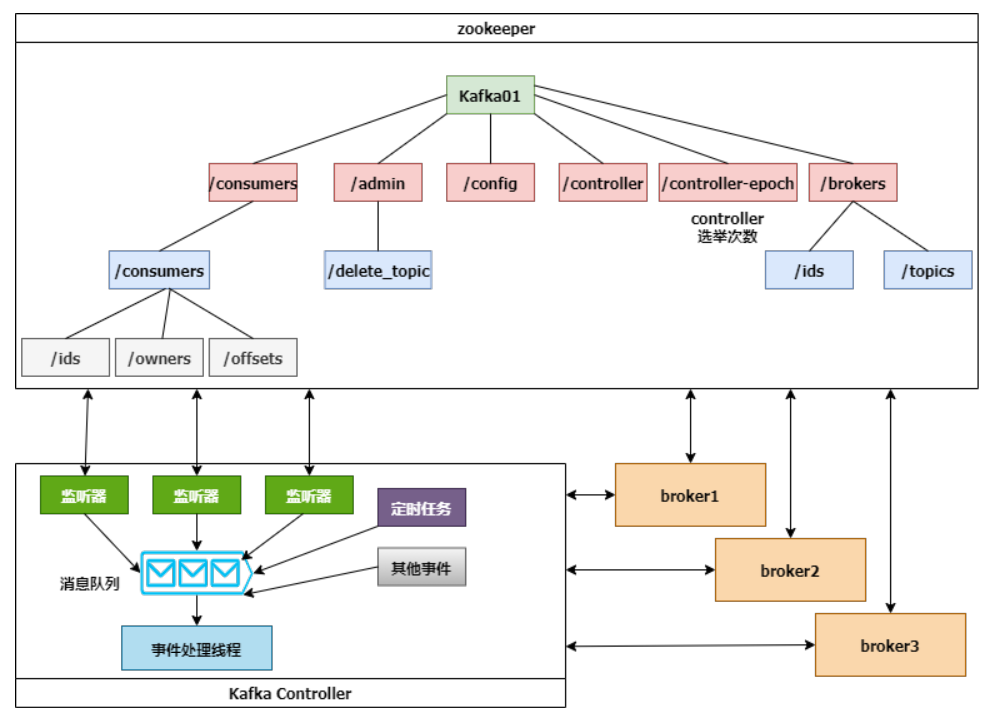
Controller选举成功后,会从Zookeeper集群中拉取一份完整的元数据初始化ControllerContext,这些元数据缓存在Controller节点。当集群发生变化时,比如增加topic分区,Controller不仅需要变更本地的缓存数据,还需要将这些变更信息同步到其他Broker。
Controller监听到Zookeeper事件、定时任务事件和其他事件后,将这些事件按照先后顺序暂存到LinkedBlockingQueue中,由事件处理线程按顺序处理,这些处理多数需要跟Zookeeper交互,Controller则需要更新自己的元数据。
四、Zookeeper的致命弱点
Zookeeper是集群部署,只要集群中超过半数节点存活,即可提供服务,例如一个由3个节点的Zookeeper,允许1个Zookeeper节点宕机,集群仍然能提供服务;一个由5个节点的Zookeeper,允许2个节点宕机。Zookeeper带来的问题有以下几点:
- 复杂度增加:Kafka本身就是一个分布式系统,但是需要另一个分布式系统来管理,复杂性无疑增加了。
- 必须要具备Zookeeper的运维能力:使用了Zookeeper,部署Kafka的时候必须要部署两套系统,Kafka的运维人员必须要具备Zookeeper的运维能力。
- Controller故障处理:Kafaka依赖一个单一Controller节点跟Zookeeper进行交互,如果这个Controller节点发生了故障,就需要从broker中选择新的Controller。如下图,新的Controller变成了broker3。
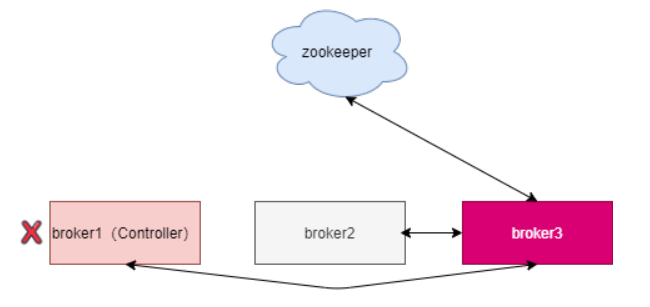
新的Controller选举成功后,会重新从Zookeeper拉取元数据进行初始化,并且需要通知其他所有的broker更新ActiveControllerId。老的Controller需要关闭监听、事件处理线程和定时任务。分区数非常多时,这个过程非常耗时,而且这个过程中Kafka集群是不能工作的。
- 分区瓶颈:当分区数增加时,Zookeeper保存的元数据变多,Zookeeper集群压力变大,达到一定级别后,监听延迟增加,给Kafaka的工作带来了影响。所以,Kafka单集群承载的分区数量是一个瓶颈。而这又恰恰是一些业务场景需要的。
五、架构升级(去掉Zookeeper依赖)
升级前后的架构图对比如下: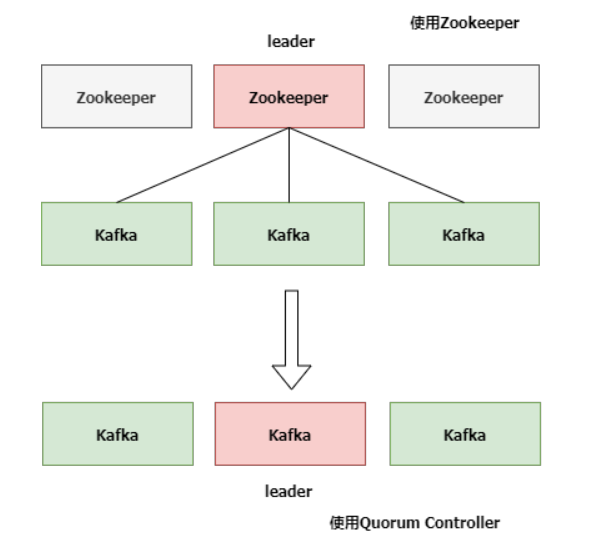
KIP-500用Quorum Controller代替之前的Controller,Quorum中每个Controller节点都会保存所有元数据,通过KRaft协议保证副本的一致性。这样即使Quorum Controller节点出故障了,新的Controller迁移也会非常快。
官方介绍,升级之后,Kafka可以轻松支持百万级别的分区。
Kafak团队把通过Raft协议同步数据的方式Kafka Raft Metadata mode,简称KRaft
- Kafka的用户体量非常大,在不停服的情况下升级是必要的。
- 目前去除Zookeeper的Kafka代码KIP-500已经提交到trunk分支,并且已经在的2.8版本发布。
- Kafaka计划在3.0版本会兼容Zookeeper Controller和Quorum Controller,这样用户可以进行灰度测试。
六、Raft协议介绍
随着分布式领域相关技术的不断完善,去中心化的思想逐步兴起,去Zookeeper的呼声也越来越高,在这个进程中涌现了一个非常优秀的算法:Raft协议。
Raft协议的两个重要组成部分:Leader选举、日志复制,而日志复制为多个副本提供数据强一致性提供了强一致性,并且一个显著的特点是Raft节点是去中心化的架构,不依赖外部的组件,而是作为一个协议簇嵌入到应用中的,即与应用本身是融合为一体的。
再以Kafka Topic的分布图举例,引用Raft协议的示例图如下:
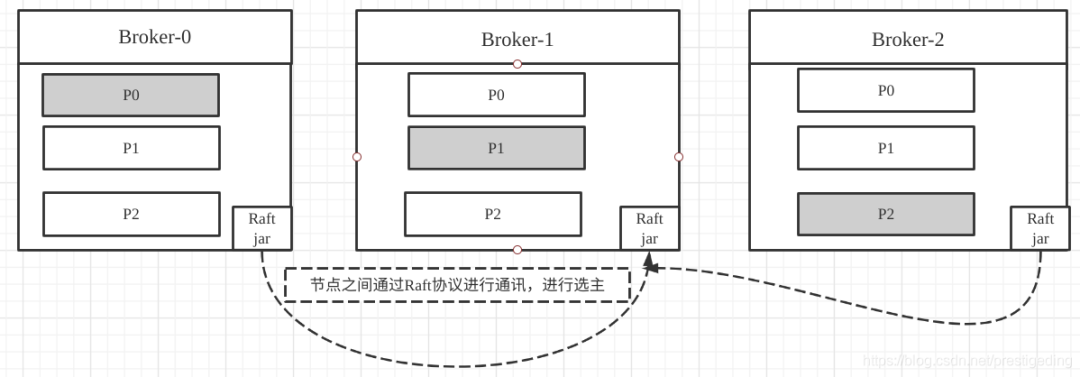
Raft 协议介绍只是简单提了一下,考虑文章篇幅过长问题,就将Raft 协议精讲放到下篇文章了,同时还会增加新版Kafka配置部署(不依赖Zookeeper)实战讲解,请小伙伴敬请期待哦~。
有任何疑问也可关注我公众号:大数据与云原生技术分享,进行技术交流,如本篇文章对您有所帮助,麻烦帮忙一键三连(点赞、转发、收藏)~
版权归原作者 大数据老司机 所有, 如有侵权,请联系我们删除。