
开源GPT?nanoGPT啃代码记实(二)

项目github:https://link.zhihu.com/?target=https%3A//github.com/karpathy/nanoGPT
今天继续来啃nanoGPT的代码,这个专栏的代码解析讲究一个从0开始,以完全不懂的身份0基础讲解,同时附上扒代码时候的个人理解。
文件准备脚本prepare.py
按照作者的示例运行流程,应该是从prepare.py开始
import os
import pickle
import requests
import numpy as np
# download the tiny shakespeare dataset
input_file_path = os.path.join(os.path.dirname(__file__),'input.txt')ifnot os.path.exists(input_file_path):
data_url ='https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt'withopen(input_file_path,'w')as f:
f.write(requests.get(data_url).text)withopen(input_file_path,'r')as f:
data = f.read()
首先是一段字符的读取,这个和我们的正常读取没什么区别,一样的with open和.read()读入文件到data,随后对data中的字符进行去冗余得到一个排序好的list。
chars =sorted(list(set(data)))
vocab_size =len(chars)
接下来是用这里是很重要的方法,用字符把位置对应出来作为编码encoder,再把字符中的东西用映射会对应的字符,作为解码decoder的过程。这是transformer的基操。
# create a mapping from characters to integers
stoi ={ ch:i for i,ch inenumerate(chars)}
itos ={ i:ch for i,ch inenumerate(chars)}#stoi {'\n':0,' ':1,'!':2}#itos {0:'\n', 1:' ', 2:'!'}defencode(s):return[stoi[c]for c in s]# encoder: take a string, output a list of integersdefdecode(l):return''.join([itos[i]for i in l])# decoder: take a list of integers, output a string
transformer的位置信息,是为了让输入数据携带位置信息,让模型能够找出位置特点。可以看到,这一步的两个极简encoder和decoder的作用是用字符把位置对应出来,再把字符中的东西用映射会对应的字符,作为解码的过程。
# export to bin files
train_ids = np.array(train_ids, dtype=np.uint16)#将list转化为一个一行的np array能够对其位置进行编码
val_ids = np.array(val_ids, dtype=np.uint16)
train_ids.tofile(os.path.join(os.path.dirname(__file__),'train.bin'))#写入bin文件当中
val_ids.tofile(os.path.join(os.path.dirname(__file__),'val.bin'))
最后用tofile写入到二进制格式的bin文件当中,prepare.py基本就告一段落了。
模型架构model.py
来一一介绍作者的类
首先是LayerNorm类,这个类也常用,是用来改善神经网络内部层间信号传播和训练稳定性的归一化方法,
对每个样本的每个特征(在选定维度上),用它们自身的均值和标准差(σ)进行归一化
y
i
=
x
i
−
μ
i
σ
i
2
+
ϵ
y_i = \frac{x_i - \mu_i}{\sqrt{\sigma_i^2 + \epsilon}}
yi=σi2+ϵxi−μi
ε是一个非常小的正值(默认为1e-5),用于防止分母过小导致的数值不稳定。
最后,将归一化后的结果乘以一个可学习的标量权重矩阵weight,并加上一个可学习的偏置向量bias。这两个参数允许模型在归一化之后进行额外的线性变换,即仿射变换。
y
i
=
x
i
−
μ
i
σ
i
2
+
ϵ
∗
γ
+
β
y_i = \frac{x_i - \mu_i}{\sqrt{\sigma_i^2 + \epsilon}} * \gamma + \beta
yi=σi2+ϵxi−μi∗γ+β
classLayerNorm(nn.Module):""" LayerNorm but with an optional bias. PyTorch doesn't support simply bias=False """def__init__(self, ndim, bias):super().__init__()
self.weight = nn.Parameter(torch.ones(ndim))
self.bias = nn.Parameter(torch.zeros(ndim))if bias elseNonedefforward(self,input):return F.layer_norm(input, self.weight.shape, self.weight, self.bias,1e-5)
接下来是CausalSelfAttention 类就是大名鼎鼎的注意力机制模块了
classCausalSelfAttention(nn.Module):def__init__(self, config):super().__init__()assert config.n_embd % config.n_head ==0# key, query, value projections for all heads, but in a batch
self.c_attn = nn.Linear(config.n_embd,3* config.n_embd, bias=config.bias)# output projection
self.c_proj = nn.Linear(config.n_embd, config.n_embd, bias=config.bias)# regularization
self.attn_dropout = nn.Dropout(config.dropout)
self.resid_dropout = nn.Dropout(config.dropout)
self.n_head = config.n_head
self.n_embd = config.n_embd
self.dropout = config.dropout
# flash attention make GPU go brrrrr but support is only in PyTorch >= 2.0
self.flash =hasattr(torch.nn.functional,'scaled_dot_product_attention')ifnot self.flash:print("WARNING: using slow attention. Flash Attention requires PyTorch >= 2.0")# causal mask to ensure that attention is only applied to the left in the input sequence
self.register_buffer("bias", torch.tril(torch.ones(config.block_size, config.block_size)).view(1,1, config.block_size, config.block_size))defforward(self, x):
B, T, C = x.size()# batch size, sequence length, embedding dimensionality (n_embd)# calculate query, key, values for all heads in batch and move head forward to be the batch dim
q, k, v = self.c_attn(x).split(self.n_embd, dim=2)
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1,2)# (B, nh, T, hs)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1,2)# (B, nh, T, hs)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1,2)# (B, nh, T, hs)# causal self-attention; Self-attend: (B, nh, T, hs) x (B, nh, hs, T) -> (B, nh, T, T)if self.flash:# efficient attention using Flash Attention CUDA kernels
y = torch.nn.functional.scaled_dot_product_attention(q, k, v, attn_mask=None, dropout_p=self.dropout if self.training else0, is_causal=True)else:# manual implementation of attention
att =(q @ k.transpose(-2,-1))*(1.0/ math.sqrt(k.size(-1)))
att = att.masked_fill(self.bias[:,:,:T,:T]==0,float('-inf'))
att = F.softmax(att, dim=-1)
att = self.attn_dropout(att)
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
y = y.transpose(1,2).contiguous().view(B, T, C)# re-assemble all head outputs side by side# output projection
y = self.resid_dropout(self.c_proj(y))return y
首先铺垫介绍Transformer注意力机制

如图,我们作为观察者在观察这张图的过程中,自然形成的三个元素:观察者我 Q,图片 K,观察重点 V,
所谓1000个人有1000个哈姆雷特,每个眼中的图片都不一样,我们对图片的不同区域的关注是不一样的,这也是图上热图所显示的。所以:Q可以为人通过自己的主观‘有色眼镜’看到的图片的向量表示,K是图片原本的向量表示,通过点乘来提取Q与K的相似度信息,也就是我们看到的覆盖在这张图上的这一层热图,也就是V。这一层V实际上就是把这张图的重点选取出来后的一个矩阵,因为我们的计算机就是对这种重点明确的数据更加敏感,而transformer通过多层的这种操作,encode后吐出的数据更加“爱憎分明”,这些内容在这位up的视频中讲的非常清楚https://www.bilibili.com/video/BV1QW4y167iq/?spm_id_from=333.999.0.0&vd_source=769ff3753997160a1ea8b796c9cbd242,在这里我做一个转述。
其次,注意力机制要如何操作呢?简单地说,一个词先embedding,然后和WQ,WK,WV三个矩阵做乘法得到QKV,然后再把这三个作为input,对这三个矩阵进行注意力机制运算之后得到输出矩阵Z借用李宏毅老师的课件就是
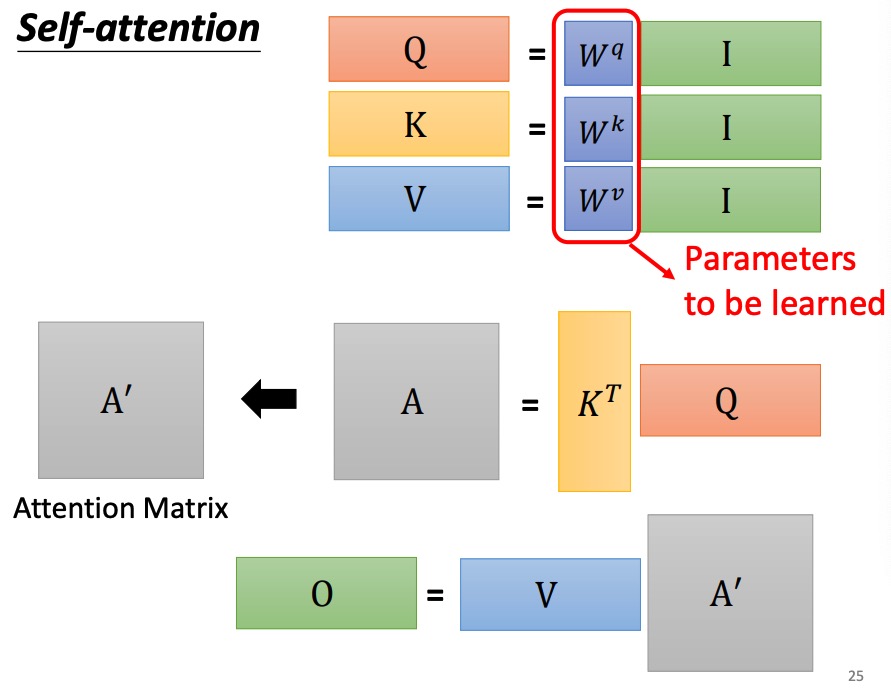
https://speech.ee.ntu.edu.tw/~hylee/ml/ml2021-course-data/self_v7.pdf
- 首先将输入文本中的单词(视频、图片的最小单位)通过Embedding处理成向量$ X = \lbrace x_1,x_2,…,x_n\rbrace$
- 将X 乘以矩阵$ W_q,W_k,W_v ,得到 ,得到 ,得到 Q,K,V $矩阵。
- 对$ Q,K $矩阵进行attention计算,除以向量维度的平方根后进行softmax. A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V) = softmax{(\frac{Q K^T}{\sqrt d_k})}V Attention(Q,K,V)=softmax(dkQKT)V
- 在并行的运算中,每一个q都与其他所有k相乘,softmax后与所有V相乘,这样输出的张量就浓缩了一个句子中所有文字的字意信息和位置信息。 具体如下图
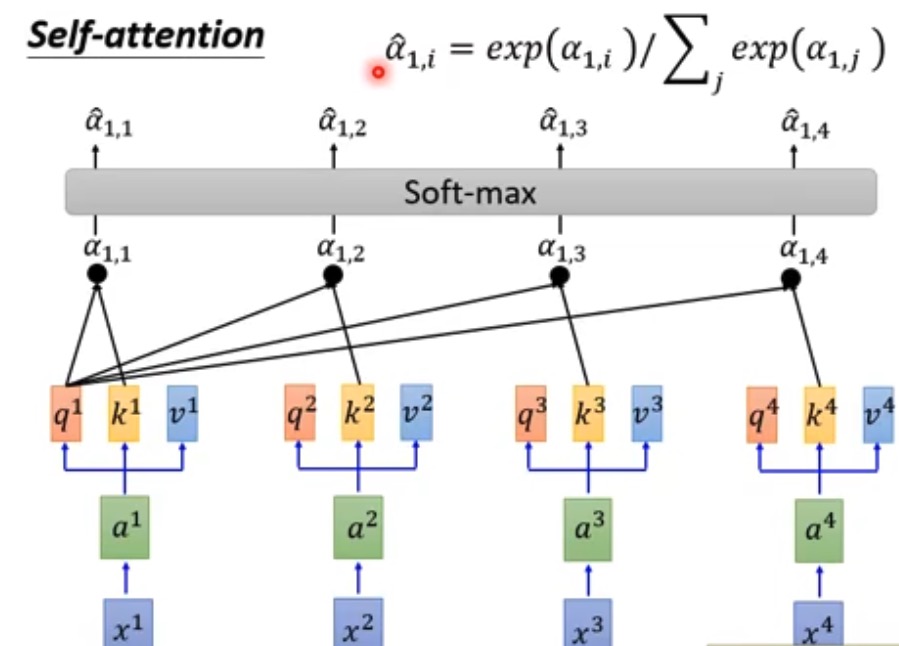
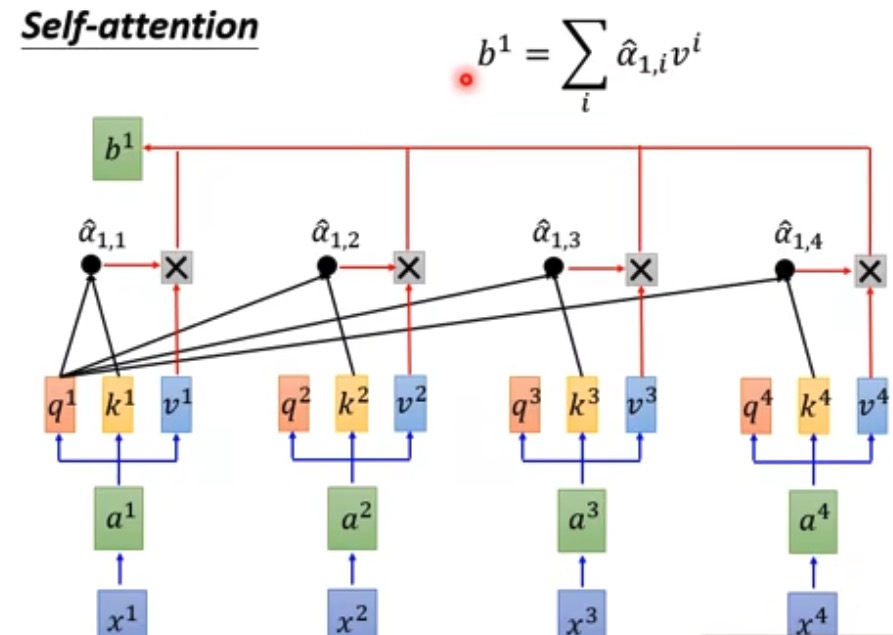
https://speech.ee.ntu.edu.tw/~hylee/ml/ml2021-course-data/self_v7.pdf
————————————————————————
介绍过QKV之后我们再上代码
Query, Key, Value投影:
#这里config.n_embd为输入, 3 * config.n_embd为输出是将输入的序列复制为三份投射到3倍
self.c_attn = nn.Linear(config.n_embd,3* config.n_embd, bias=config.bias)# output projection
self.c_proj = nn.Linear(config.n_embd, config.n_embd, bias=config.bias)
Query, Key, Value投影:首先,对输入序列
x ∈ R^(B×T×C)
进行线性变换,其中
B
是批次大小,
T
是序列长度,
C
是嵌入维度。通过单个全连接层
self.c_attn
投影到
3*C
维度的空间。这里的BTC的具体理解如下,先用视频类比,比如说对5段视频进行拆分,
- B代表5段视频;这里对应的是将文章拆成的N个片段
- T代表每个样本的视频数据可能被截断或窗化成固定长度,比如10秒长的音频片段,采样率为16kHz,那么T就是160000(10秒 * 16000样本/秒);在这里比如一个句子包含30个词,那么该句子的T就是30。
- C是每个时间步的特征维度,比如一个视频片段里面,有图片的RGB三个维度红绿蓝,音频的Mel频率或其它声学特征,假设有40个特征维度,则C=43;而这里每个词或字符映射为一个固定维度的词向量,这个维度就是C。
B, T, C = x.size()# batch size, sequence length, embedding dimensionality (n_embd)# calculate query, key, values for all heads in batch and move head forward to be the batch dim
q, k, v = self.c_attn(x).split(self.n_embd, dim=2)
其中split(self.n_embd, dim=2) 表示将上述自注意力层输出的张量沿第二个维度(dim=2实际上是第三个轴)分割成三部分,每部分的大小为 self.n_embd也就是每一部分的特征维度等于原始嵌入维度的三分之一,因为Query、Key、Value通常有相同的维度。
然后拆分为多头注意力的(query, key, value),各维度为
R^(B×T×C/n_head)
,其中
n_head
表示注意力头数。
q = self.c_attn(x)[:,:,:C/n_head]#Query
k = self.c_attn(x)[:,:, C/n_head:C*2/n_head]#Key
v = self.c_attn(x)[:,:, C*2/n_head:]#Value
随后在自注意力机制(如Transformer中的多头注意力)处理完输入后,进行重新整合和输出投影的步骤:
#重新整合(Reassemble):
y = y.transpose(1,2).contiguous().view(B, T, C)# output projection
y = self.resid_dropout(self.c_proj(y))
代码解析
- 将 y 这个张量的第二个维度(即头部数量)和第三个维度(即序列长度)进行交换。在多头注意力机制中,y 的维度通常是 (B, n_heads, T, C/head_count),通过转置,可以将所有注意力头的输出并排放在同一个序列长度维度上。
- self.c_proj(y):将上一步得到的整合后的序列嵌入 y 通过一个线性层 self.c_proj 进行投影,self.resid_dropout对线性层输出结果应用残差连接后进行Dropout
好的,最主要的类介绍完了!下一篇准备介绍剩下的MLP和Block模块以及train.py时作者的训练技巧。
版权归原作者 kirov1024 所有, 如有侵权,请联系我们删除。