
一.实验内容
MapReduce编程实践:
使用MapReduce实现多个文本文件中WordCount词频统计功能,实验编写Map处理逻辑、编写Reduce处理逻辑、编写main方法。
二.实验目的
1、通过实验掌握基本的MapReduce编程方法。
2、实现统计HDFS系统中多个文本文件中的单词出现频率。
三.实验过程截图及说明
1、在本地创建多个文本文件并上传到Hadoop:
(1)创建本地存放文件的文件夹:

(2)使用vim命令向文件里添加内容:
创建3个文件(words1.txt、words2.txt、words3.txt):

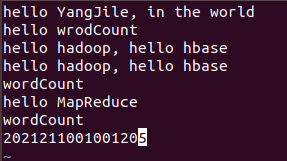

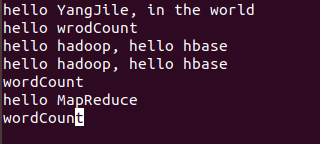

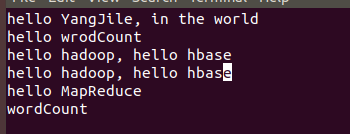
(3)在Hadoop里创建存放文件的目录:

(4)将本地的3个文件上传到Hadoop上【put命令】:

2、编写java代码来操作读取文件并统计:
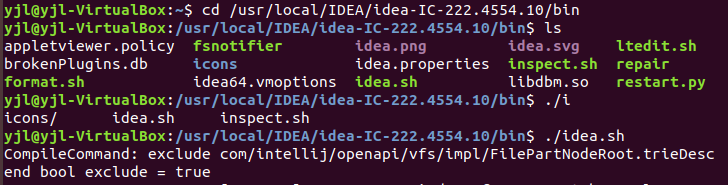
(1)启动idea【我这里是用命令打开,你也可直接点图标打开】:
命令是:先切换到你安装idea的目录里面的bin目录,然后输入./idea.sh,不知道是输入什么的可以先输入./i,然后按下tab就会有提示,你就可以继续输入了。
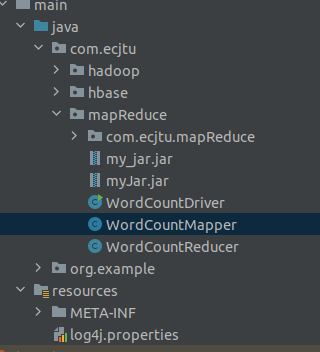
(2)目录结构【这里只需要创建MapReduce即可,前面的是上次的两个实验】:
(3)编写log4j.properties文件:

(4)引入需要用到的依赖:

引入后记得点右边浮现出的Maven标志,下载一下依赖,或者右键任意空白处,找到Maven选项,然后reload。
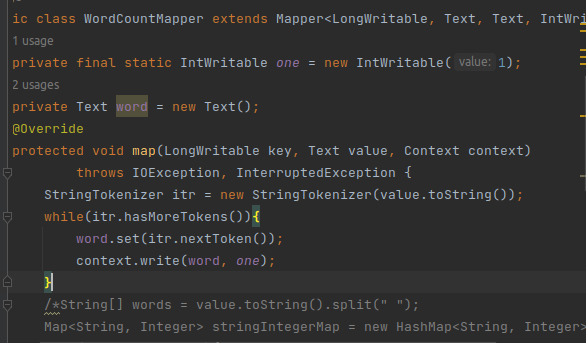
(5)编写Mapper处理逻辑:
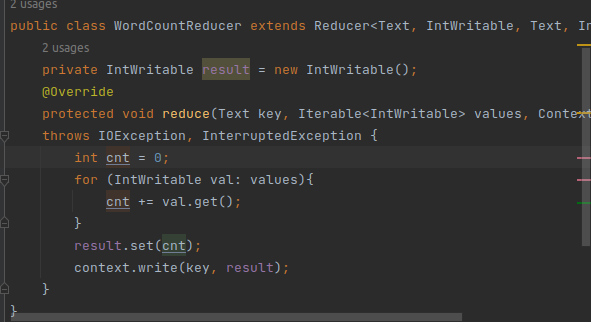
(6)编写Reducer处理逻辑:
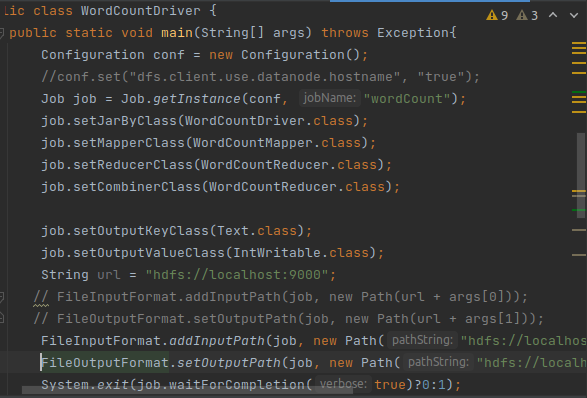
(7)编写main函数驱动模块:

(8)运行main函数方法:

(9)运行成功后查看输出文件内容:
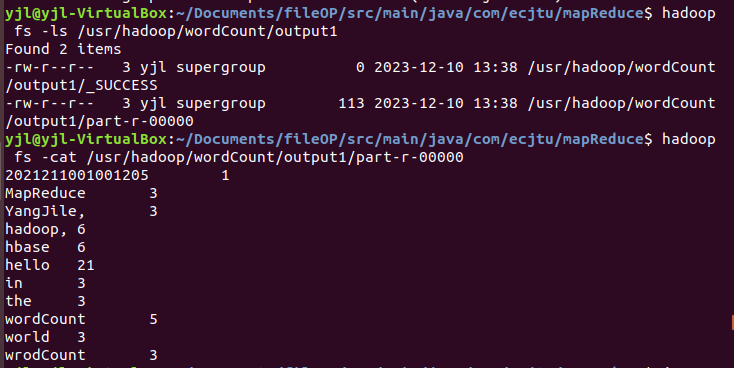
统计结果无误,试验完成。
四.** **实验总结及心得体会
实验总结:
本实验使用了MapReduce框架实现了多个文本文件中的WordCount词频统计功能。通过编写Map处理逻辑,将每个文本文件中的单词进行拆分并统计数量。在Reduce处理逻辑中,对相同的单词进行合并统计,并输出最终结果。在main方法中,设置了作业的配置信息、任务类型、输入输出路径等。实验结果展示了MapReduce在大数据处理领域的高效性和可靠性。在实际应用中,可以根据需求对代码进行优化,提高性能。
心得体会:
MapReduce是一种强大的分布式计算模型,可以帮助我们高效地处理大规模数据。通过本次实验,我掌握了MapReduce的基本概念和编程实践,对分布式计算有了更深入的了解。
在实验过程中,我学会了如何编写Map和Reduce逻辑,以及如何配置MapReduce运行环境。这为我今后处理类似问题时提供了实用的技能。
实验让我认识到,分布式计算并非万能。在实际应用中,我们需要根据数据规模和计算需求来选择合适的计算框架。这对于我今后在项目中选择合适的计算技术具有重要意义。
通过本次实验,我对Hadoop框架有了初步了解。在未来的学习中,我会继续探索Hadoop的相关技术,以提高数据处理能力和扩展知识面。
最后,本次实验提高了我的编程能力和动手实践能力。通过不断地编写代码和调试,我掌握了更多实用的编程技巧,为今后的学习和工作打下了坚实的基础。
五、完整报告获取在开头资源挂载里。
版权归原作者 我要八百米跑 所有, 如有侵权,请联系我们删除。