
分词器
将一段文本,按照一定的逻辑,分析成多个词语的一种工具
ES有很多内置的分词器,但是对中文不友好,处理的方式为一字分一词
IK分词器
- IKAnalyzer是一个开源的,基于Java语言开发的轻量级的中文分词工具包
- 是基于Maven构建的项目(安装之前要先安装Maven)
- 具有60万字/秒的高速处理能力
- 支持用户词典扩展定义
安装IK分词器
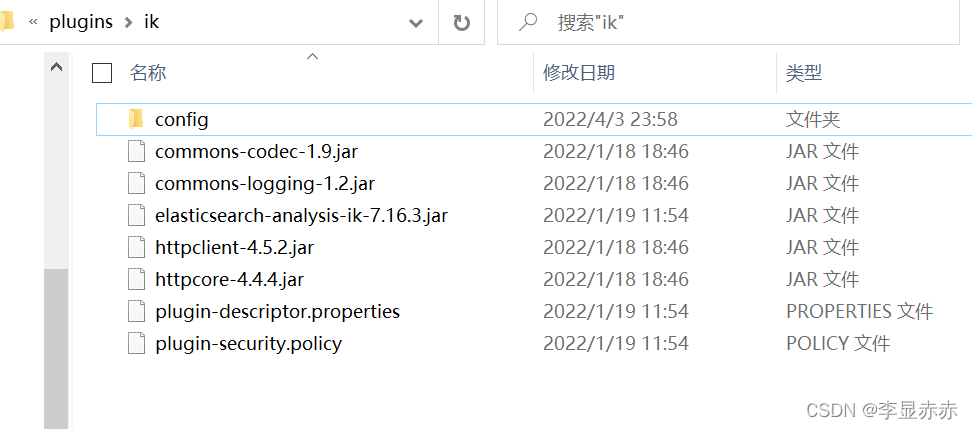
在ElasticSearch的plugins下创建一个文件夹ik,解压在这个文件夹中
IK分词器有两种分词模式:
- ik_max_word(细粒度):最细粒度划分
- ik_smart(粗粒度):最小切分
GET _analyze
{
"analyzer": "ik_smart",
"text": ["我爱北京天安门"]
}
创建索引的时候,指定IK分词器,创建的时候不指定默认使用自带的,中文分词一字一词
PUT person
{
"mappings": {
"properties": {
"name":{
"type": "keyword"
},
"age":{
"type": "integer"
},
"desc":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
ik分词器扩展自己的词典
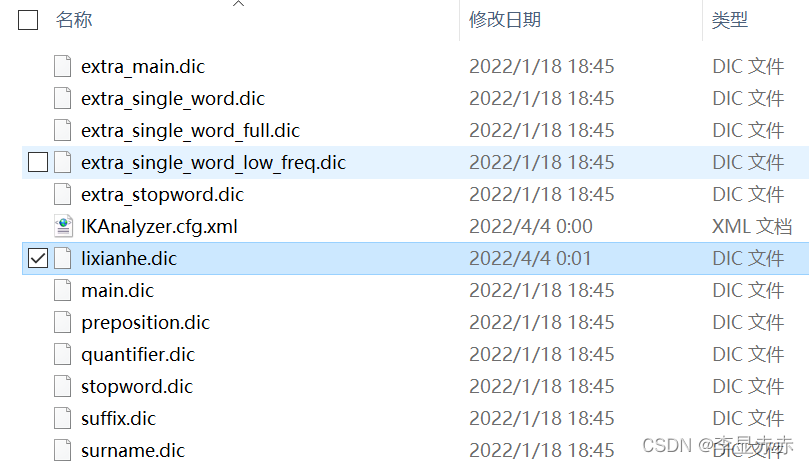
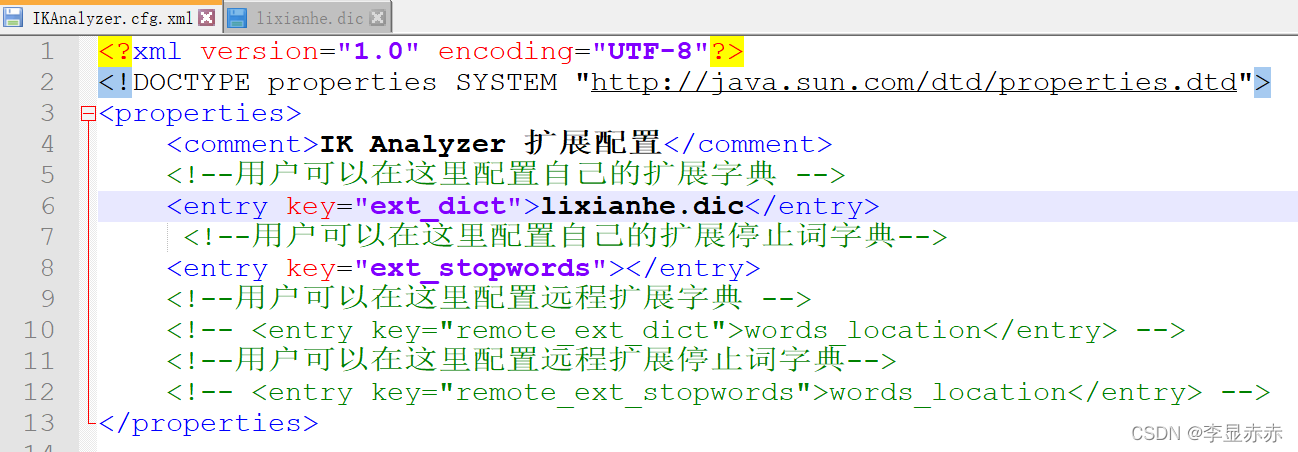
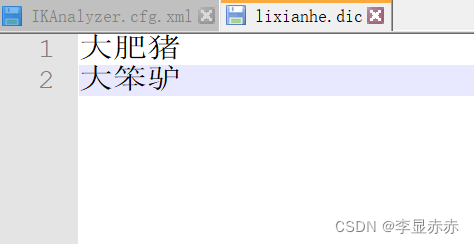
在elasticsearch-7.16.3\plugins\ik\config创建一个后缀名为.dic的文件,然后在xml中配置
标签:
java
elasticsearch
本文转载自: https://blog.csdn.net/m0_56750901/article/details/123953624
版权归原作者 李显赤赤 所有, 如有侵权,请联系我们删除。
版权归原作者 李显赤赤 所有, 如有侵权,请联系我们删除。