
1、简介
Hive的hiveserver2服务的作用是提供jdbc/odbc接口,为用户
提供远程访问Hive数据的功能
,例如用户期望在个人电脑中访问远程服务中的Hive数据,就需要用到Hiveserver2。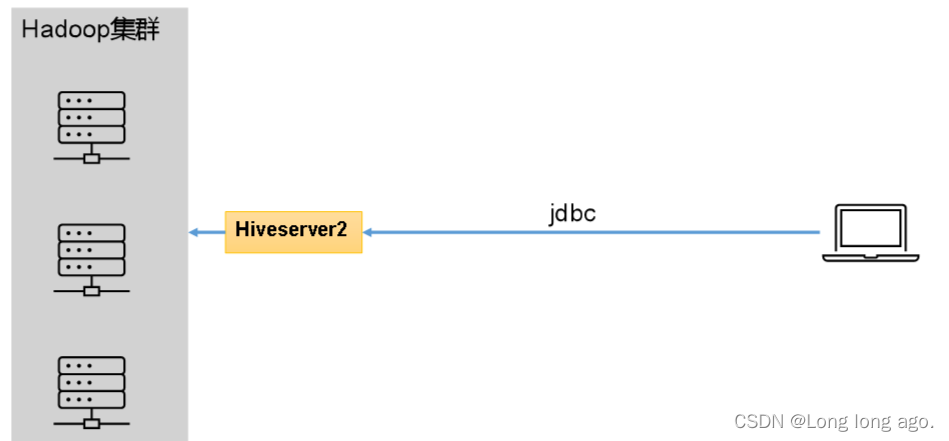
2、用户模拟功能
在远程访问Hive数据时,客户端并未直接访问Hadoop集群,而是由Hivesever2代理访问。由于Hadoop集群中的数据具备访问权限控制,所以此时需考虑一个问题:那就是
访问Hadoop集群的用户身份是谁?
是Hiveserver2的启动用户?还是客户端的登录用户?
答案是都有可能,具体是谁,由Hiveserver2的
hive.server2.enable.doAs
参数决定,该参数的含义是是否启用Hiveserver2用户模拟的功能。若启用,则Hiveserver2会模拟成客户端的登录用户去访问Hadoop集群的数据,不启用,则Hivesever2会直接使用启动用户访问Hadoop集群数据。模拟用户的功能,默认是开启的。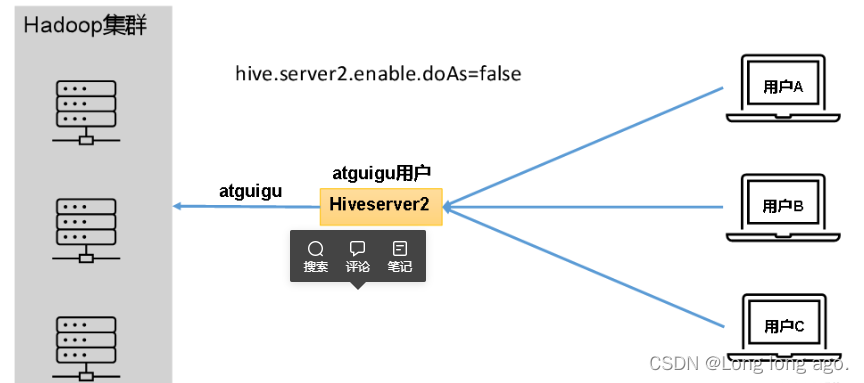
开启用户模拟功能: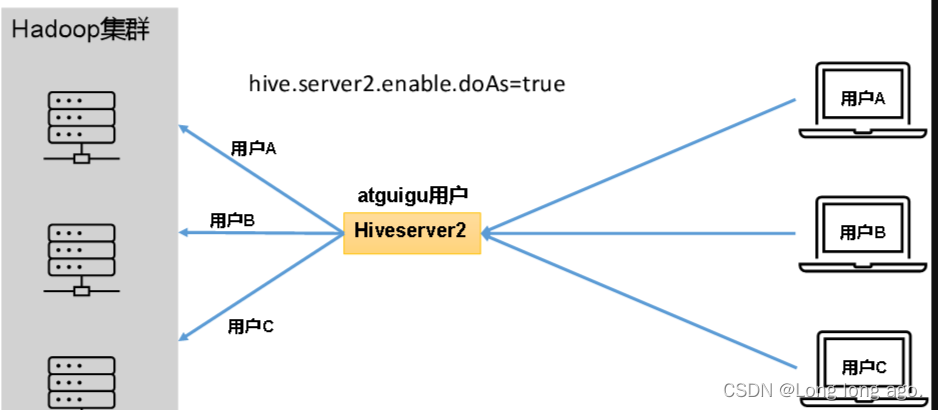
生产环境,推荐开启用户模拟功能,因为开启后才能保证各用户之间的权限隔离。
3、配置hiveserver2
3.1修改hadoop配置hive-site.xml
vim $HADOOP_HOME/etc/hadoop/core-site.xml
<!--配置所有节点的root用户都可作为代理用户--><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><!--配置root用户能够代理的用户组为任意组--><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property><!--配置root用户能够代理的用户为任意用户--><property><name>hadoop.proxyuser.root.users</name><value>*</value></property>
记得分发给其他hadoop节点
3.2 修改hive配置hive-site.xml
vim $HIVE_HOME/conf/hive-site.xml
<!-- 指定hiveserver2连接的host --><property><name>hive.server2.thrift.bind.host</name><value>hadoop100</value></property><!-- 指定hiveserver2连接的端口号 --><property><name>hive.server2.thrift.port</name><value>10000</value></property>
3.3重启hadoop
$HADOOP_HOME/sbin/stop-all.sh
$HADOOP_HOME/sbin/start-all.sh
3.4启动hiveserver2
$HIVE_HOME/bin/hive --service hiveserver2
后台挂起启动
nohup $HIVE_HOME/bin/hive --service hiveserver2 &
3.5连接
$HIVE_HOME/bin/beeline -u jdbc:hive2://hadoop100:10000 -n root
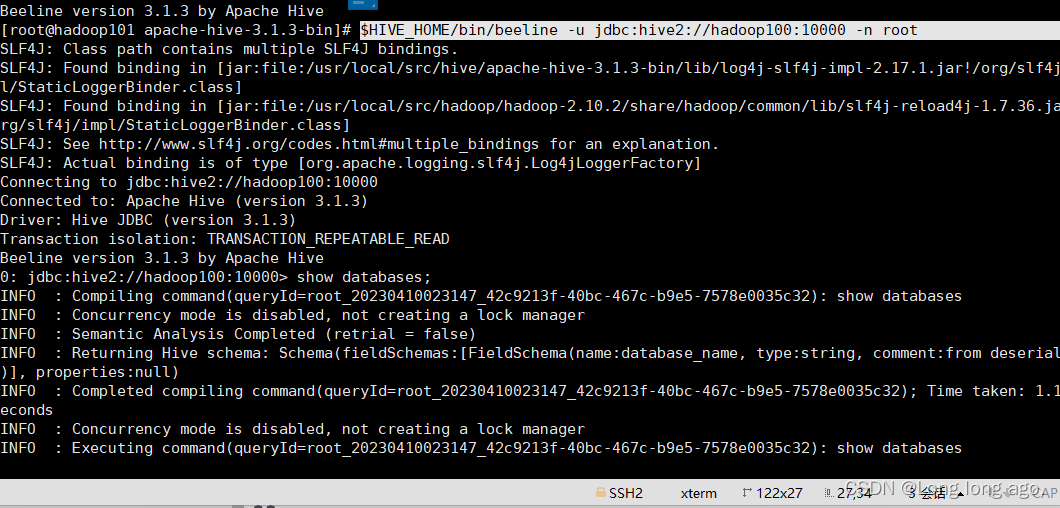
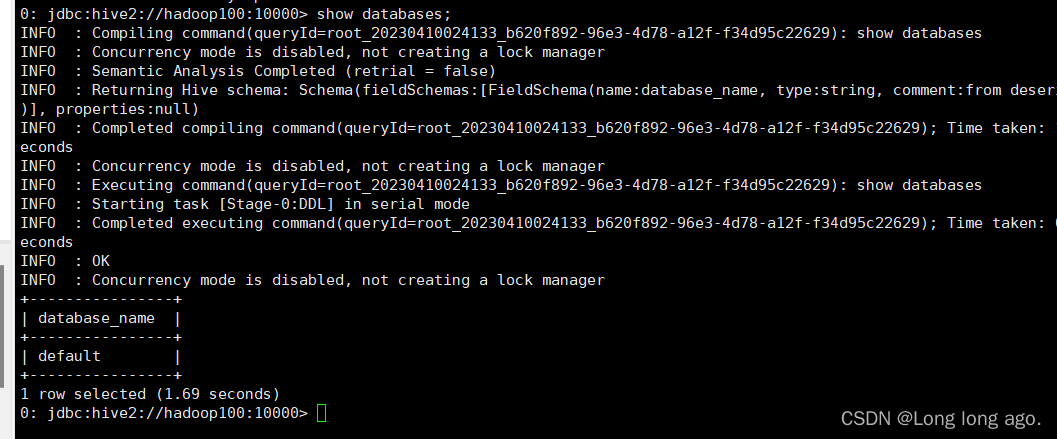
4、使用idea连接工具
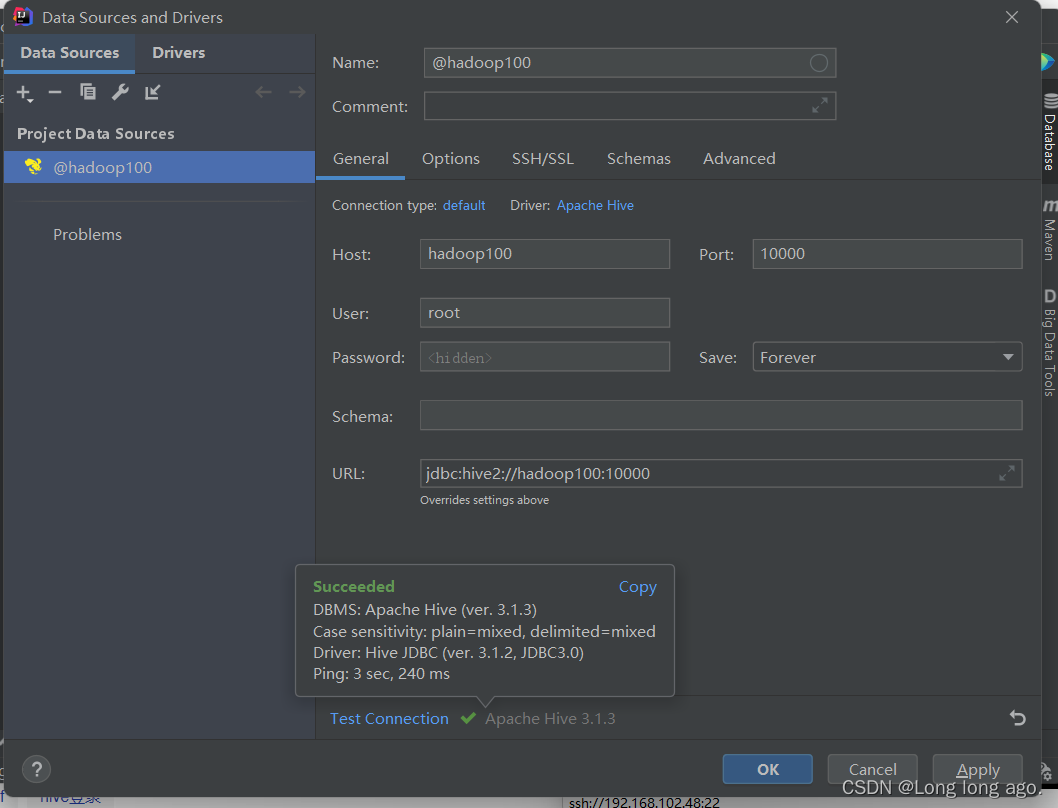
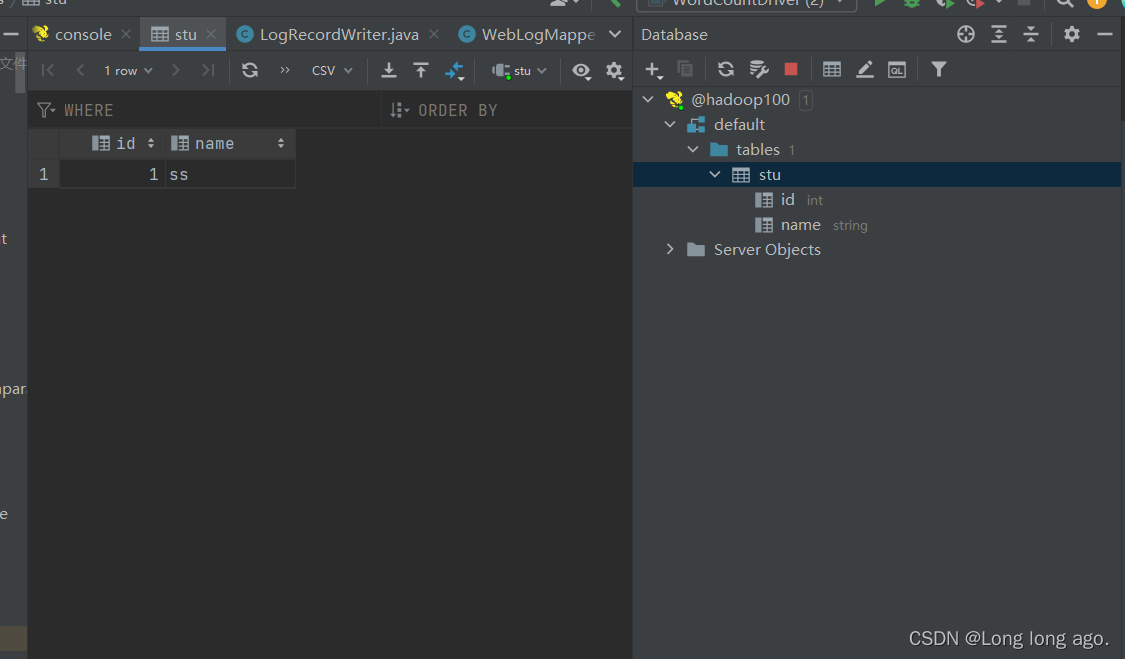
也可以使用dbeaver作为客户端工具
本文转载自: https://blog.csdn.net/weixin_43205308/article/details/130057663
版权归原作者 Long long ago. 所有, 如有侵权,请联系我们删除。
版权归原作者 Long long ago. 所有, 如有侵权,请联系我们删除。