

本文将从简单到复杂介绍典型架构的特点以及其优缺点。
介绍
一旦数据科学家对模型的性能感到满意,下一步便是“模型生产环境部署”, 没有系统的合理配置,您的Kaggle Top1模型可能只是垃圾。
在本文中,我想谈一谈机器学习生产环境部署的的4种典型体系结构设计。

每个正式生产的体系结构均应至少具有两个功能:
学习:系统应允许模型根据业务需求进行重做。
预测:系统应根据前端(例如需要预测的Web应用程序)的要求返回预测。
尽管我用简单的图表讨论了四种体系结构,以显示系统的起源,但实际的系统配置还是带有特定的库或服务来填充主体。
另外,请注意,一种架构中的配置可以应用于另一种架构中的配置(例如,如果输入数据为流数据,则Apache Kafka始终用于预处理数据。)
1.在数据库中存储预测
在这种体系结构中,预测结果在预测阶段(模型预生成预测时)存储在数据存储中,并且当请求在应用程序端(前端)上发布时,将返回那些结果。 预测发生的频率比训练(例如每个月)更为频繁(例如每天),预测需求发生的频率比预测本身更频繁(例如每小时100)。
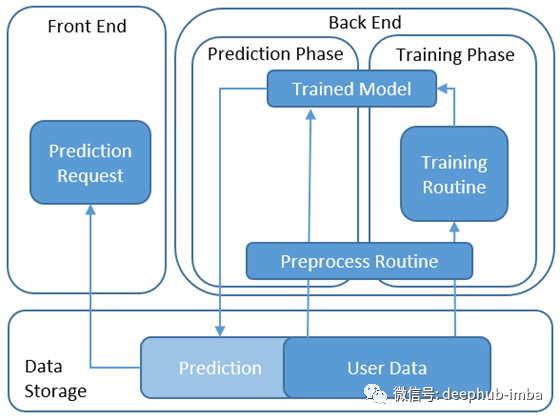
优点:
- 几乎没有PoC架构。
- 对前端的请求响应的延迟低。
- 前端和后端没有系统依赖性。例如,长时间进行预测不会影响应用程序侧延迟。语言的差异也不会影响两者的性能(例如,前端的java与后端的Python)。
缺点:
无法反映实时输入。例如,当您在网站上提供推荐时,在该体系结构中将无法使用对网站上的实时用户选择敏感的推荐(例如Glassdoor中的“角色”或“位置”)。
使用场景:
这种体系结构至少非常适合基于ML的Web应用程序的第一个版本,如果它们的健壮性不需要实时输入,则甚至更高的版本也是如此。当第一个版本运行良好时,如果您想使用实时输入进行改进,则可以添加API服务器。
2.在模型对象上预测
在这种架构中,经过训练的模型被放置在前端和后端共享的存储中。前端收到预测请求后,它将获取预处理数据,并在模型上运行预测逻辑。通过模型训练例程定期对模型进行重新训练并将其转储到存储中。
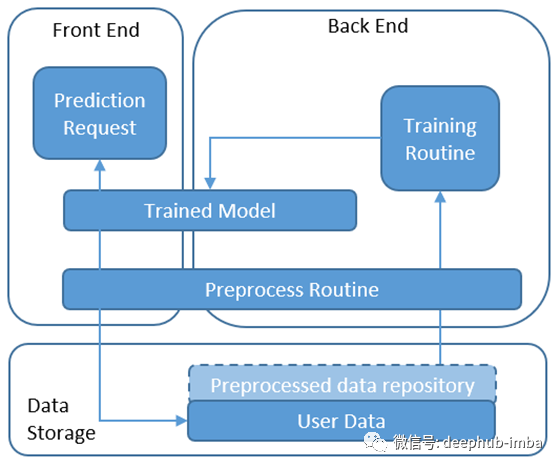
优点:
- 能够反映前端收集的实时输入。
- 几乎没有PoC架构。
缺点:
- 预测中可能存在高延迟。为了使架构可操作,可能需要降低等待时间,例如在实际的预测请求发生之前,除了源数据之外,还将预处理的数据存储在数据存储中,或者使用花费较短预测时间的简单模型。
- 后端与前端之间的高度依赖性。代码需要基于相同的语言,或者模型必须完全转换为前端语言,这最终会给PoC带来额外的开销。
使用场景:
此体系结构适用于模型或扩展PoC的较小规模的业务用例,尤其是在需要实时预测的情况下。
3.基于API预测
在该架构中,预测由运行在API服务器上的API提供(例如通过Python Flask)或由无服务器功能(例如AWS Lambda或GCP Cloud Functions)托管。API从存储中加载模型。一旦收到请求,它将获得预处理的数据,运行预测并返回结果。通过模型训练例程定期对模型进行重新训练并将其转储到存储中。
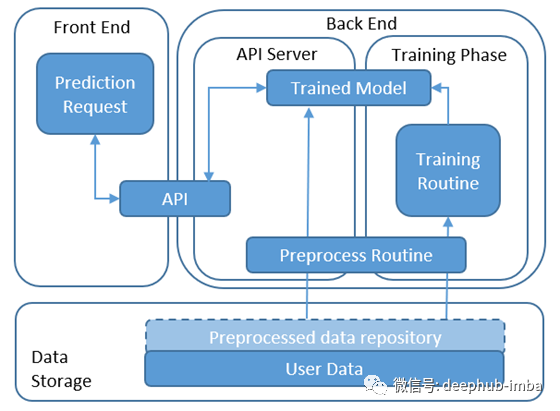
优点:
- 能够反映在前端收集并在API参数中提供的实时输入。
- 能够减少后端和前端之间的依赖性。例如,语言差异确实会影响性能(例如,前端的Ruby on Rails与后端的Python。)
- 通常,更高的可伸缩性,需要准备在需要扩展时使用的API服务器的Docker映像。基于云的托管无服务器功能(例如AWL Lambda或GCP Cloud Functions)可以自动管理扩展。
缺点:
- API部分的额外系统配置和维护成本
- 由于在API之前和之后进行额外的通信,可能会导致更高的延迟。
使用场景:
这种架构非常适合大型ML系统,该系统需要在前端进行独立的阐述,并在后端进行持续的改进或实验(例如A / B测试)。
4.实时学习
流数据(例如从物联网设备)实时传送到系统中,或当我们有特殊需要基于新到达的数据实时更新ML模型时,才需要这种体系结构。
新的训练数据到达API网关并发送到预处理步骤。新数据通过消息传递功能(例如Apache Kafka)排队以将数据排队以进行下一步处理,并通过流功能(例如Spark Streaming)实时处理。接下来,处理后的数据将触发模型的重新训练,例如,使用sklearn或Spark MLlib。同时,可以响应前端请求经过预处理和预测来提供预测,就像“ 3架构”中所述。预测基于上面的API。总体架构可以使用更多受管编排服务(如Jubatas)来处理。
这种架构使配置最复杂,并且需要其他架构中最有经验的架构师。
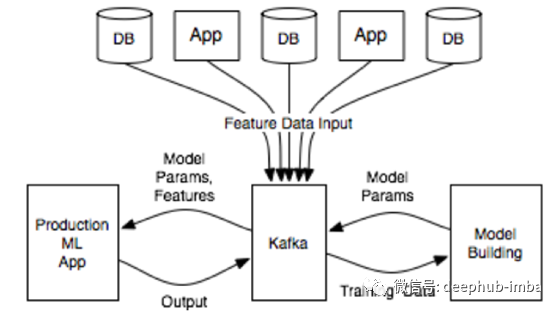
使用Apache Kafka的实时学习架构示例
优点:
它可以反映实时数据,并且模型始终是最新的。
缺点:
复杂的架构,需要经验丰富的架构师参与以及系统维护成本。
应用场景:尽管我们知道该架构看起来很酷,并且每个数据人员都佩服它是一个激动人心的工程挑战,但我们应该记住:几乎仅在新数据以24/7的流传输到达时以及当我们有特殊需要更新ML时才需要这种架构 实时建模。
否则,对复杂数据管道的投资将毫无价值,更糟糕的是这将是技术债务。
结论
我介绍了在ML模型的生产化中应该考虑的四种可能的体系结构类型,从简单到复杂。
他们每个人都有优点和缺点。因此,我们应该选择哪一种最适合我们目前的条件。此外,仍然可以将每种体系结构中的组件组合在一起,以最适合你的业务。
作者:Moto DEI
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********