

Apache Flink架构介绍
一、Flink组件栈
在Flink的整个软件架构体系中,同样遵循这分层的架构设计理念,在降低系统耦合度的同时,也为上层用户构建Flink应用提供了丰富且友好的接口。
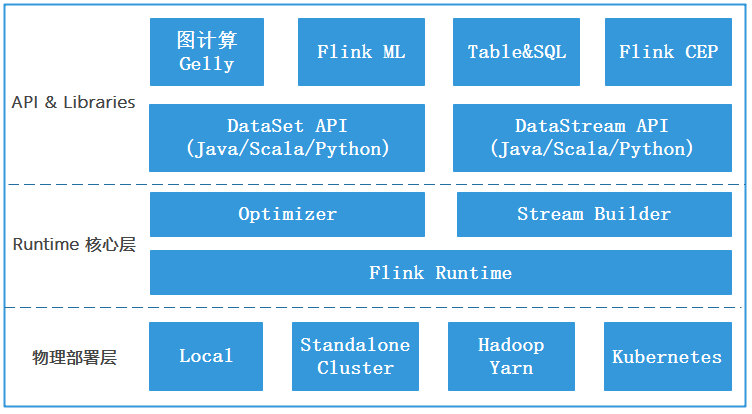
上图是Flink基本组件栈,从上图可以看出整个Flink的架构体系可以分为三层,从下往上依次是物理部署层、Runtime 核心层、API&Libraries层。
- 物理部署层:
该层主要涉及Flink的部署模式,目前Flink支持多种部署模式:本地Local、集群(Standalone/Yarn)、Kubernetes,Flink能够通过该层支撑不同平台的部署,用户可以根据需要来选择对应的部署模式,目前在企业中使用最多的是基于Yarn进行部署,也就是Flink On Yarn。
- Runtime核心层:
该层主要负责对上层不同接口提供基础服务,也是Flink分布式计算框架的核心实现层,支持分布式Stream作业的执行、JobGraph到ExecutionGraph的映射转换、任务调度等,将DataStream和DataSet转成统一可执行的Task Oparator,达到在流式引擎下同时处理批量计算和流式计算的目的。
- API & Libraries层:
作为分布式计算框架,Flink同时提供了支撑流计算和批计算接口,未来批计算接口会被弃用,在Flink1.15 版本中批计算接口已经标记为Legacy(已过时),后续版本建议使用Flink流计算接口,基于此接口之上抽象出不同应用类型的组件库,例如:FlinkML 机器学习库、FlinkCEP 复杂事件处理库、Flink Gelly 图处理库、SQL&Table 库。DataSet API 和DataStream API 两者都提供给用户丰富的数据处理高级API,例如:Map、FlatMap操作等,同时也提供了比较底层的ProcessFunction API ,用户可以直接操作状态和时间等底层数据。这些API将在后面进行介绍。
二、Flink运行时架构
Flink整个系统主要由两个组件组成,分别为JobManager和TaskManager,Flink架构也遵循Master-Slave架构设计原则,JobManager为Master节点,TaskManager为Worker(Slave)节点。所有组件之间的通信都是借助于Akka Framework,包括任务的状态以及Checkpoint触发等信息。
Flink运行时架构如下,下面分别介绍下架构中涉及到的角色作用。


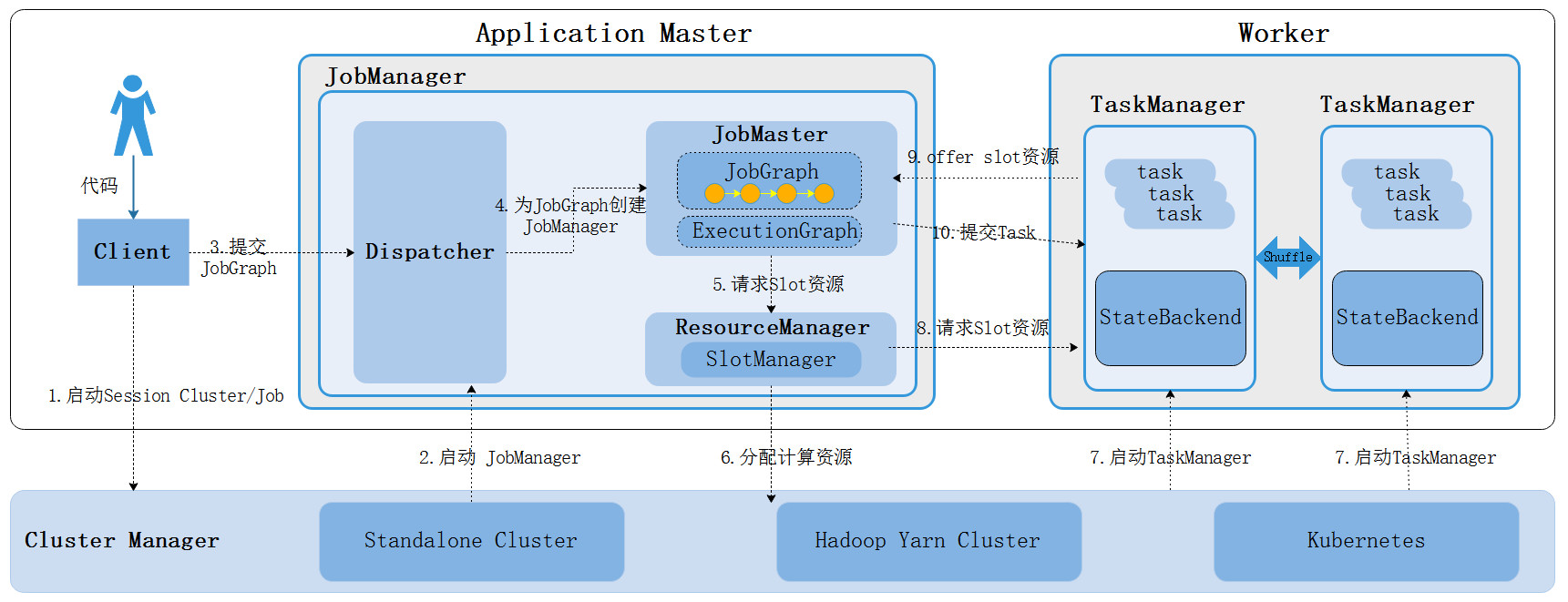
- Flink Clients客户端
Flink客户端负责将任务提交到集群,与JobManager构建Akka连接,然后将任务提交到JobManager,通过和JobManager之间进行交互获取任务执行状态。Flink客户端Clients不是Flink程序运行时的一部分,作用是向JobManager准备和发送dataflow,之后,客户端可以断开(detached mode)连接或者保持连接(attached mode)。客户端提交任务可以采用CLI方式或者通过使用Flink WebUI提交,也可以在应用程序中指定JobManager的RPC网络端口构建ExecutionEnvironment提交Flink应用。
- JobManager
JobManager负责整个Flink集群任务的调度以及资源的管理,从客户端中获取提交的应用,然后根据集群中TaskManager上TaskSlot的使用情况,为提交的应用分配相应的TaskSlots资源并命令TaskManger启动从客户端中获取的应用。
JobManager相当于整个集群的Master节点,Flink HA 集群中可以有多个JobManager,但整个集群中有且仅有一个活跃的JobManager,其他的都是StandBy。JobManager和TaskManager之间通过Actor System进行通信,获取任务执行的情况并通过Actor System将应用的任务执行情况发送给客户端。同时在任务执行过程中,Flink JobManager会触发Checkpoints操作,每个TaskManager节点收到Checkpoint触发指令后,完成Checkpoint操作,所有的Checkpoint协调过程都是在Flink JobManager中完成。当任务完成后,Flink会将任务执行的信息反馈给客户端,并且释放掉TaskManager中的资源以供下一次提交任务使用。
JobManager由三个不同的组件组成:
- ResourceManager:
这里说的ResourceManager不是Yarn资源管理中的ResourceManager,而是Flink中的ResourceManager,其主要负责Flink集群资源分配、管理和回收。在Flink中这里说的资源主要是TaskManager节点上的Task Slot计算资源,Flink中每个提交的任务最终会转换成task,每个task需要发送到TaskManager 上的slot中执行(slot是资源调度最小的单位),Flink为不同的环境和资源提供者(例如:Yarn/Kubernetes和Standalone)实现了对应的ResourceManager,这些ResourceManager负责申请启动TaskManager获取Slot资源。
在Standalone集群中,集群启动会同时启动TaskManager,不支持提交任务时启动TaskManager(没有Per-Job任务提交模式),ResourceManager只能分配可用TaskManager的slots,而不支持自行启动新的TaskManager,而基于其他资源调度框架执行任务时,当ResourceManager管理对应的TaskManager没有足够的slot,会申请启动新的TaskManager进程。
- Dispatcher
Dispatcher提供了一个REST接口,用来提交Flink应用程序执行,例如CLI客户端或Flink Web UI提交的任务最终都会发送至Dispatcher组件,由Dispatcher组件对JobGraph进行分发和执行,并为每个提交的作业启动一个新的 JobMaster,它还运行 Flink WebUI 用来提供作业执行信息。
- JobMaster
JobMaster负责管理整个任务的生命周期,负责将Dispatcher提交上来的JobGraph转换成ExecutionGraph(执行图)结构,通过内部调度程序对ExecutionGraph执行图进行调度和执行,最终向TaskManager中提交和运行Task实例,同时监控各个Task的运行状况,直到整个作业中所有的Task都执行完毕。
JobManager和ResourceManager组件一样,JobManager组件本身也是RPC服务,具备通信能力,可以与ResourceManager进行RPC通信申请任务的计算资源,资源申请到位后,就会将对应Task任务发送到TaskManager上执行,当Flink Task任务执行完毕后,JobMaster服务会关闭,同时释放任务占用的计算资源。所以JobMaster与对应的Flink job是一一对应的。
- TaskManager
TaskManager负责向整个集群提供Slot计算资源,同时管理了JobMaster提交的Task任务。TaskManager会提供JobManager从ResourceManager中申请和分配的Slot计算资源,JobMaster最终会根据分配到的Slot计算资源将Task提交到TaskManager上运行。另外,TaskManager还可缓存数据,TaskManager之间可以进行DataStream数据的交换。
一个Flink集群中至少有一个TaskManager,在TaskManager中资源调度的最小单位是 task slot ,一个TaskManger中的task Slot个数决定了当前TaskManger最高支持的并发task个数,一个task Slot中可以执行多个算子。
可以看出,Flink的任务运行其实是采用多线程的方式,这和MapReduce多JVM进程的方式有很大的区别Fink能够极大提高CPU使用效率,在多个任务和Task之间通过TaskSlot方式共享系统资源,每个TaskManager中通过管理多个TaskSlot资源池进行对资源进行有效管理。
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 Lansonli 原创,首发于 CSDN博客🙉
📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
版权归原作者 Lansonli 所有, 如有侵权,请联系我们删除。