
Hadoop 之 Hbase 配置与使用
一.Hbase 下载
HBase 是一个分布式的、面向列的开源数据库:Hbase API
1.Hbase 下载
Hbase 下载
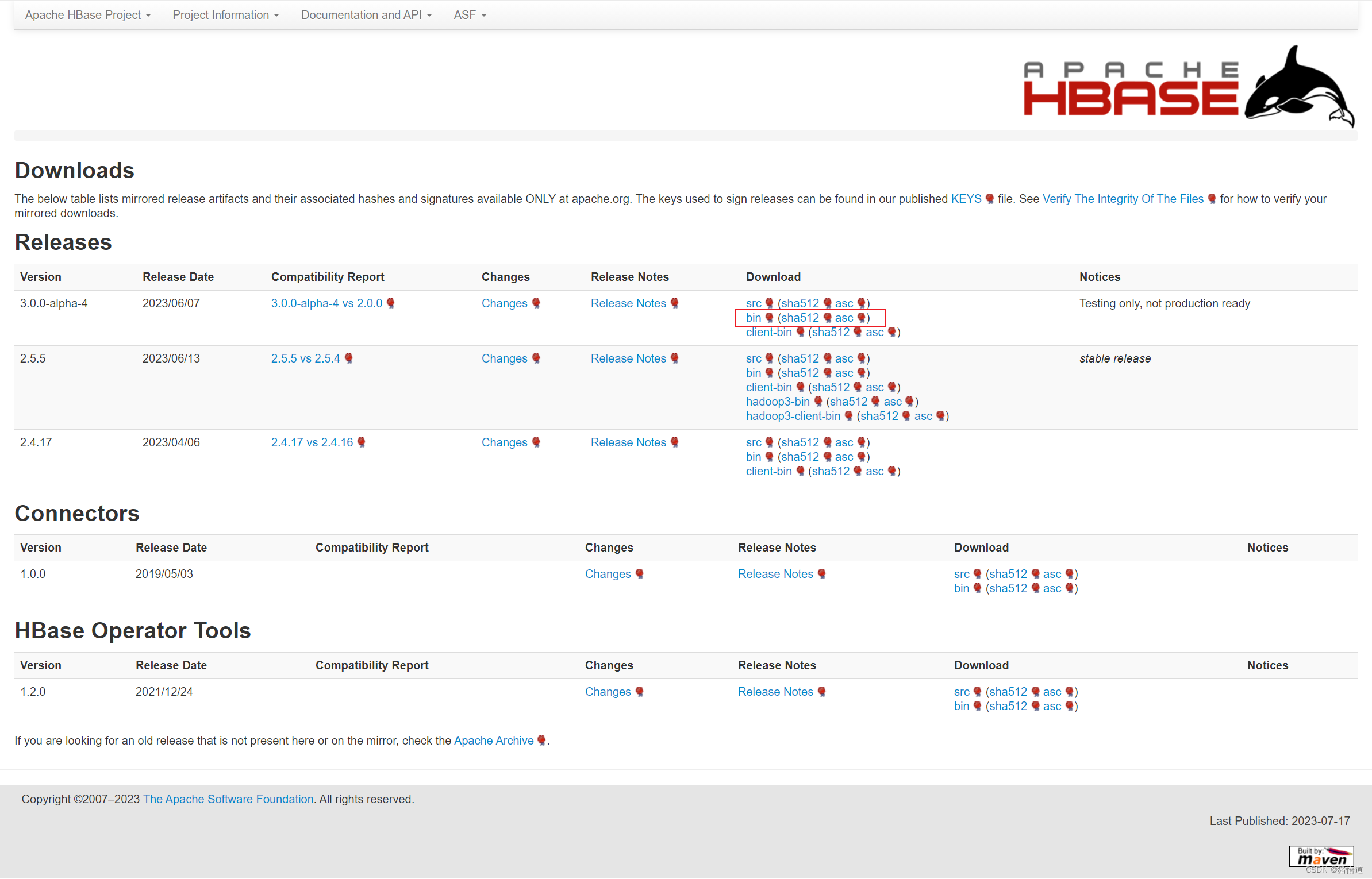
跳转到下载链接
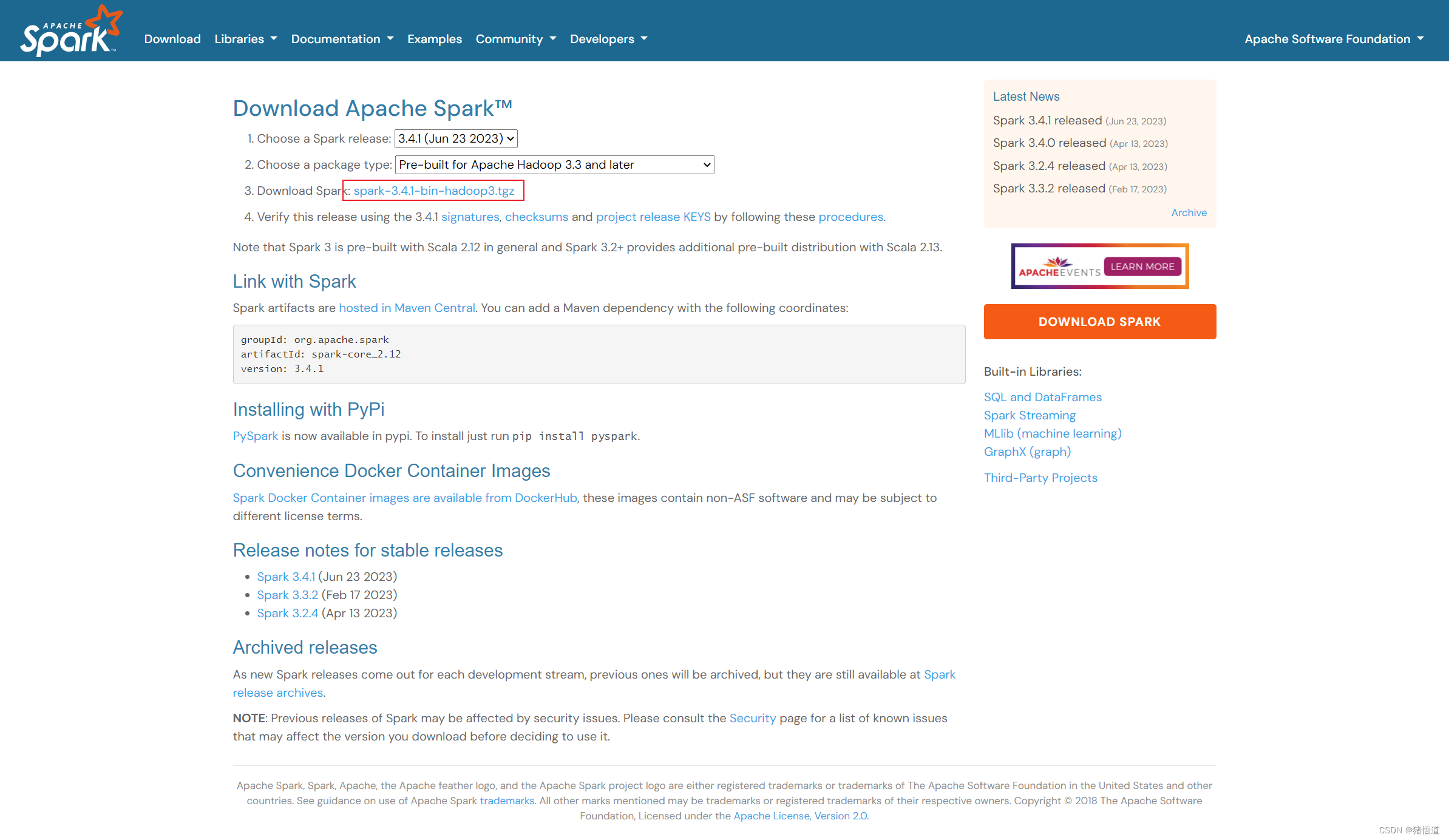
二.Hbase 配置
1.单机部署
## 1.创建安装目录
mkdir -p /usr/local/hbase
## 2.将压缩包拷贝到虚拟机并解压缩
tar zxvf hbase-3.0.0-alpha-4-bin.tar.gz -C /usr/local/hbase/
## 3.添加环境变量echo'export HBASE_HOME=/usr/local/hbase/hbase-3.0.0-alpha-4' >> /etc/profile
echo'export PATH=${HBASE_HOME}/bin:${PATH}' >> /etc/profile
source /etc/profile
## 4.指定 JDK 版本echo'export JAVA_HOME=/usr/local/java/jdk-11.0.19' >> $HBASE_HOME/conf/hbase-env.sh
## 5.创建 hbase 存储目录
mkdir -p /home/hbase/data## 6.修改配置
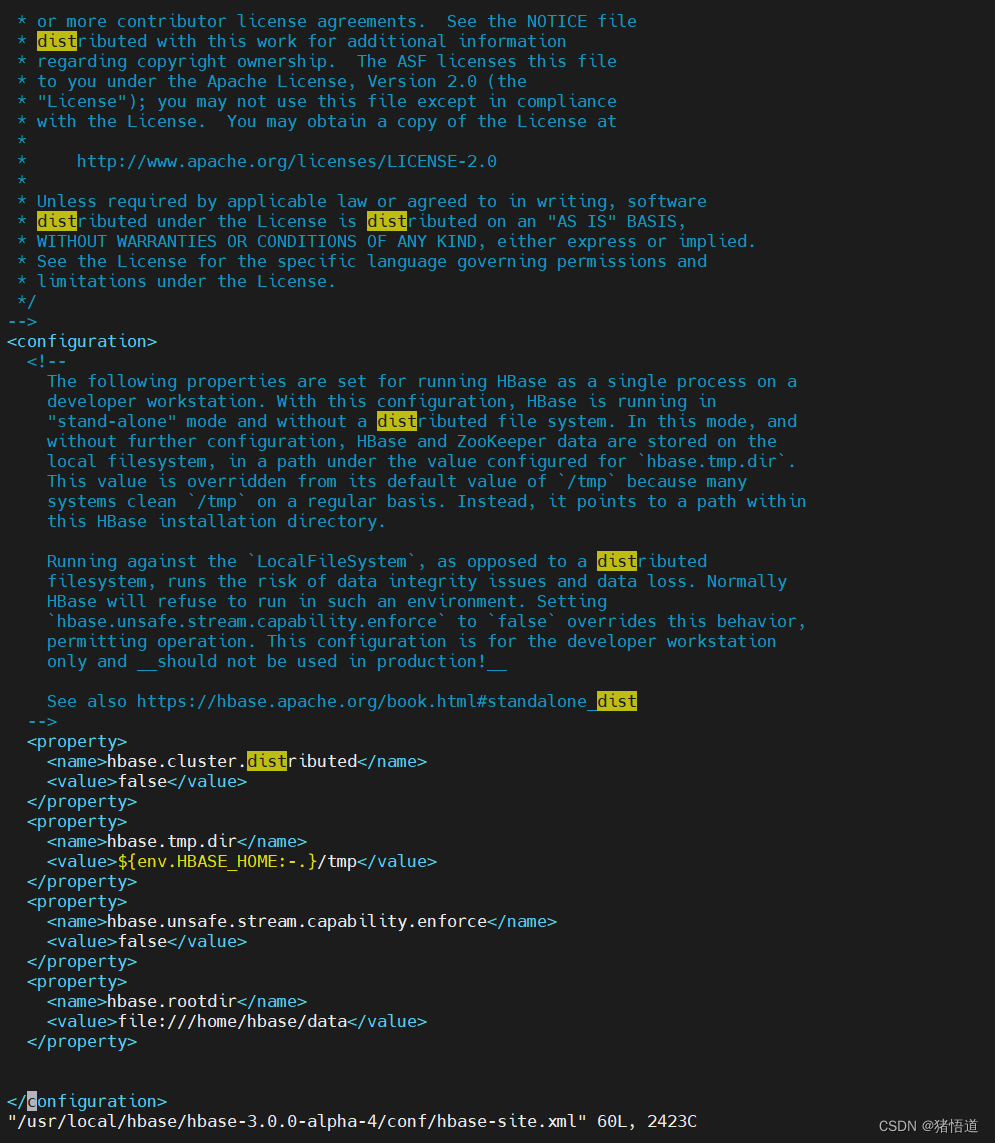
vim $HBASE_HOME/conf/hbase-site.xml
添加如下信息
<property>
<name>hbase.rootdir</name>
<value>file:///home/hbase/data</value>
</property>
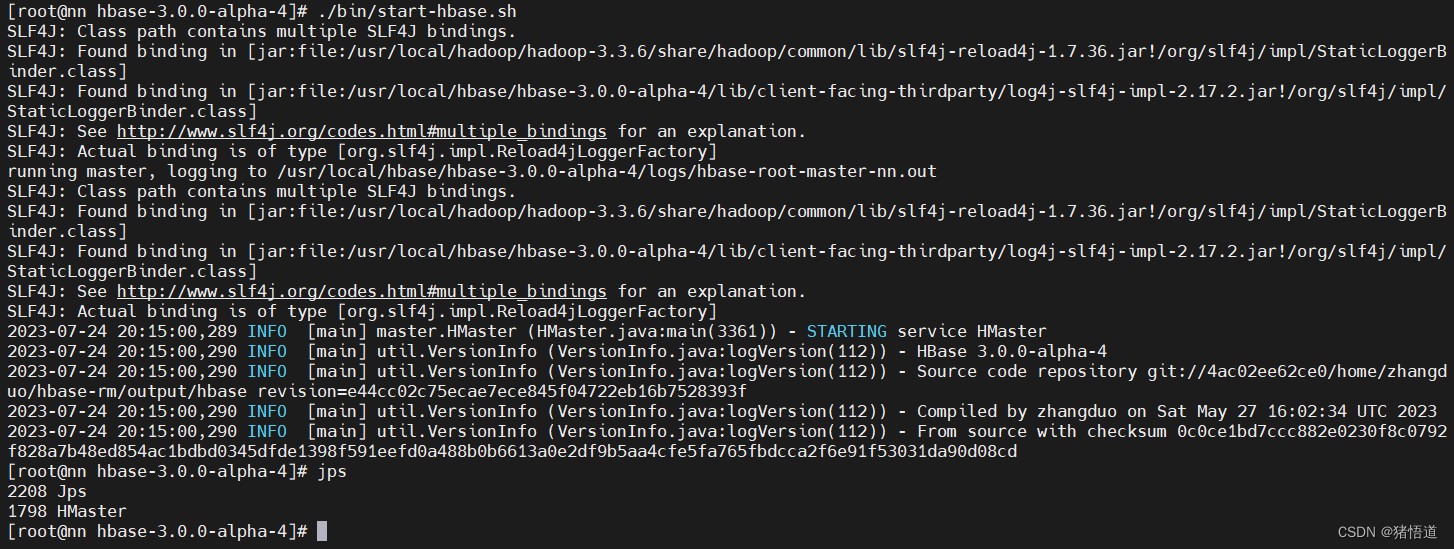
## 1.进入安装目录
cd $HBASE_HOME## 2.启动服务./bin/start-hbase.sh
## 1.进入安装目录
cd $HBASE_HOME## 2.关闭服务./bin/stop-hbase.sh

2.伪集群部署(基于单机配置)
## 1.修改 hbase-env.sh echo'export JAVA_HOME=/usr/local/java/jdk-11.0.19' >> $HBASE_HOME/conf/hbase-env.sh
echo'export HBASE_MANAGES_ZK=true' >> $HBASE_HOME/conf/hbase-env.sh
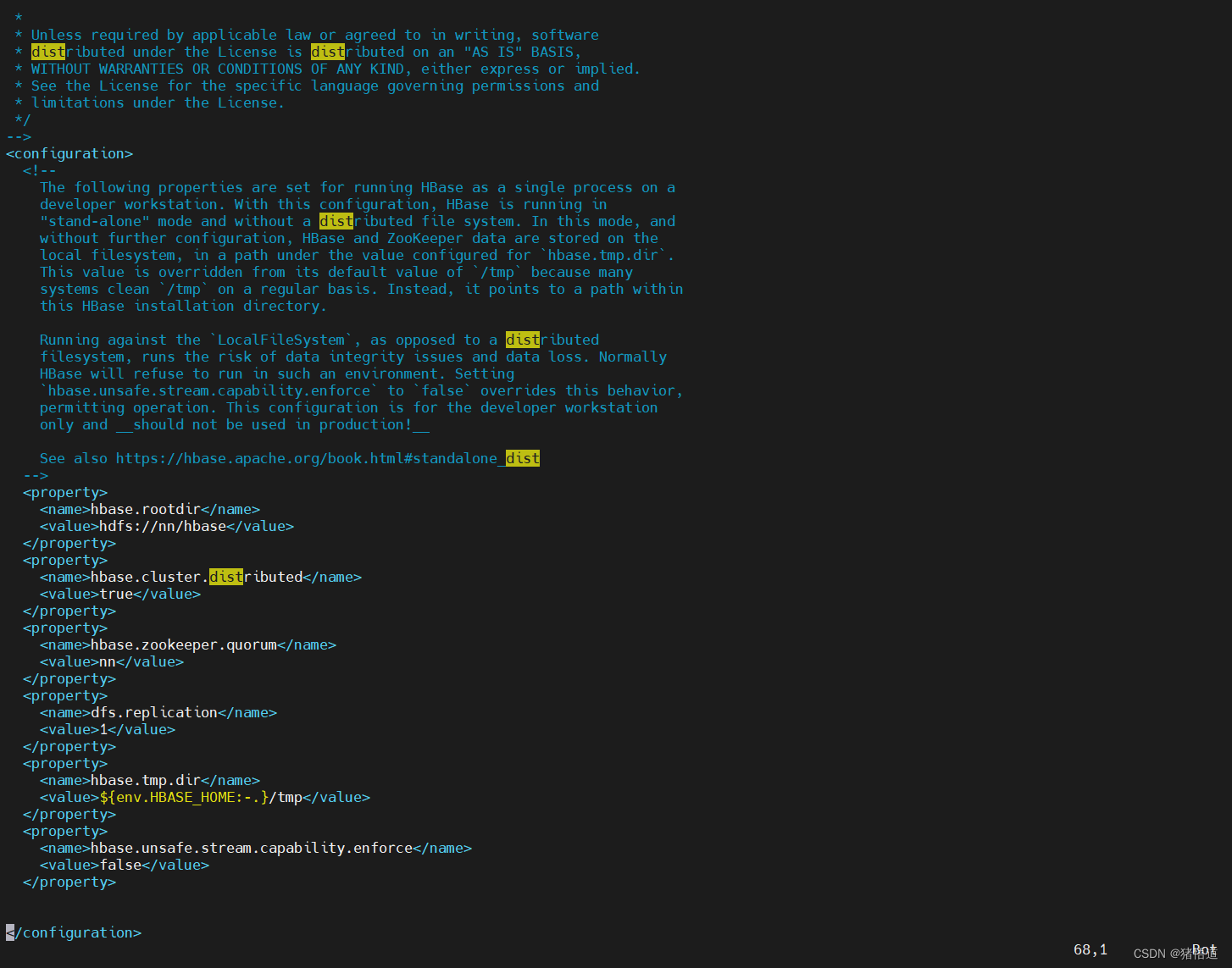
## 2.修改 hbase_site.xml
vim $HBASE_HOME/conf/hbase-site.xml
<!-- 将 hbase 数据保存到 hdfs -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://nn/hbase</value>
</property>
<!-- 分布式配置 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 配置 ZK 地址 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>nn</value>
</property>
<!-- 配置 JK 地址 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
## 3.修改 regionservers 的 localhost 为 nnecho nn > $HBASE_HOME/conf/regionservers
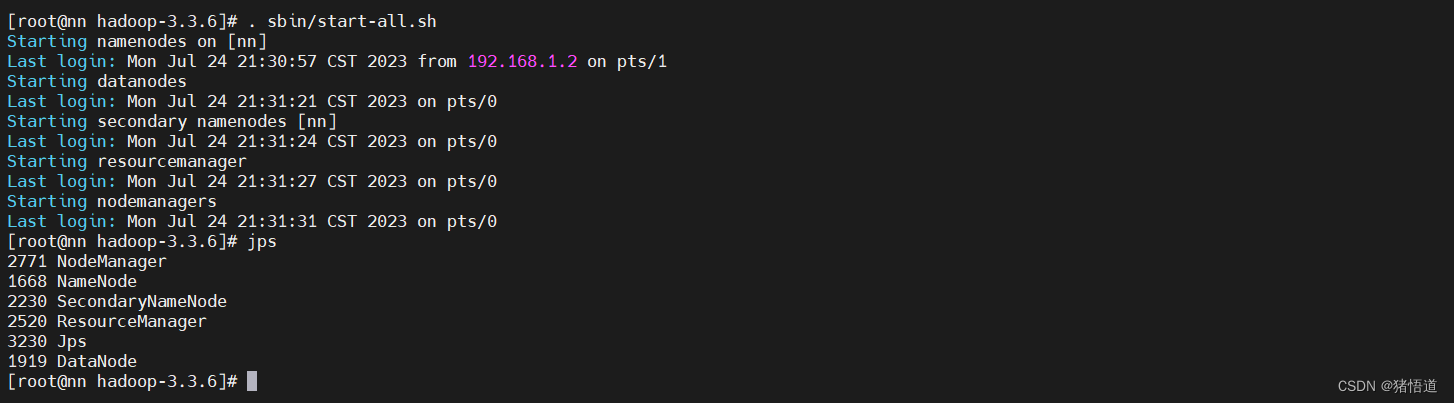
## 1.进入安装目录
cd $HADOOP_HOME## 2.启动 hadoop 服务./sbin/start-all.sh
## 1.进入安装目录
cd $HBASE_HOME## 2.启动服务./bin/start-hbase.sh

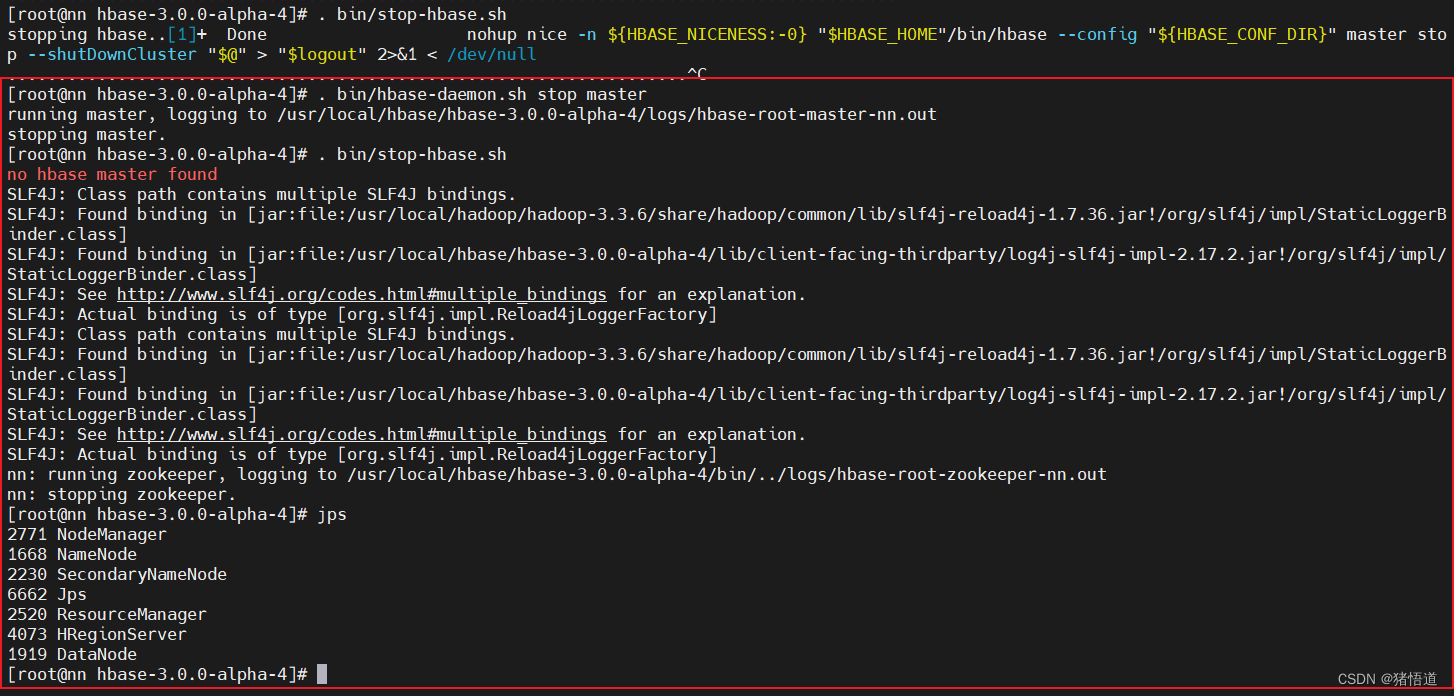
## 1.进入安装目录
cd $HBASE_HOME## 2.关闭主节点服务(直接关服务是关不掉的,如图). bin/hbase-daemon.sh stop master
## 3.关闭服务./bin/stop-hbase.sh
3.集群部署
## 1.创建 zookeeper 数据目录
mkdir -p $HBASE_HOME/zookeeper/data## 2.进入安装目录
cd $HBASE_HOME/conf
## 3.修改环境配置
vim hbase-env.sh
## 添加 JDK / 启动外置 Zookeeper# JDK
export JAVA_HOME=/usr/local/java/jdk-11.0.19
# Disable Zookeeper
export HBASE_MANAGES_ZK=false
## 4.修改 hbase-site.xml
vim hbase-site.xml
## 配置如下信息
<!--允许的最大同步时钟偏移-->
<property>
<name>hbase.master.maxclockskew</name>`
<value>6000</value>
</property>
<!--配置 HDFS 存储实例-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://nn:9000/hbase</value>
</property>
<!--启用分布式配置-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--配置 zookeeper 集群节点-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>zk1,zk2,zk3</value>
</property>
<!--配置 zookeeper 数据目录-->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/hbase/hbase-3.0.0-alpha-4/zookeeper/data</value>
</property>
<!-- Server is not running yet -->
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
## 5.清空 regionservers 并添加集群节点域名echo'' > regionservers
echo'nn' >> regionservers
echo'nd1' >> regionservers
echo'nd2' >> regionservers
## 6.分别为 nd1 / nd2 创建 hbase 目录
mkdir -p /usr/local/hbase
## 7.分发 hbase 配置到另外两台虚拟机 nd1 / nd2
scp -r /usr/local/hbase/hbase-3.0.0-alpha-4 root@nd1:/usr/local/hbase
scp -r /usr/local/hbase/hbase-3.0.0-alpha-4 root@nd2:/usr/local/hbase
## 8.分发环境变量配置
scp /etc/profile root@nd1:/etc/profile
scp /etc/profile root@nd2:/etc/profile
1.启动 hadoop 集群
Hadoop 集群搭建参考:Hadoop 搭建
## 1.启动 hadoop
cd $HADOOP_HOME. sbin/start-all.sh
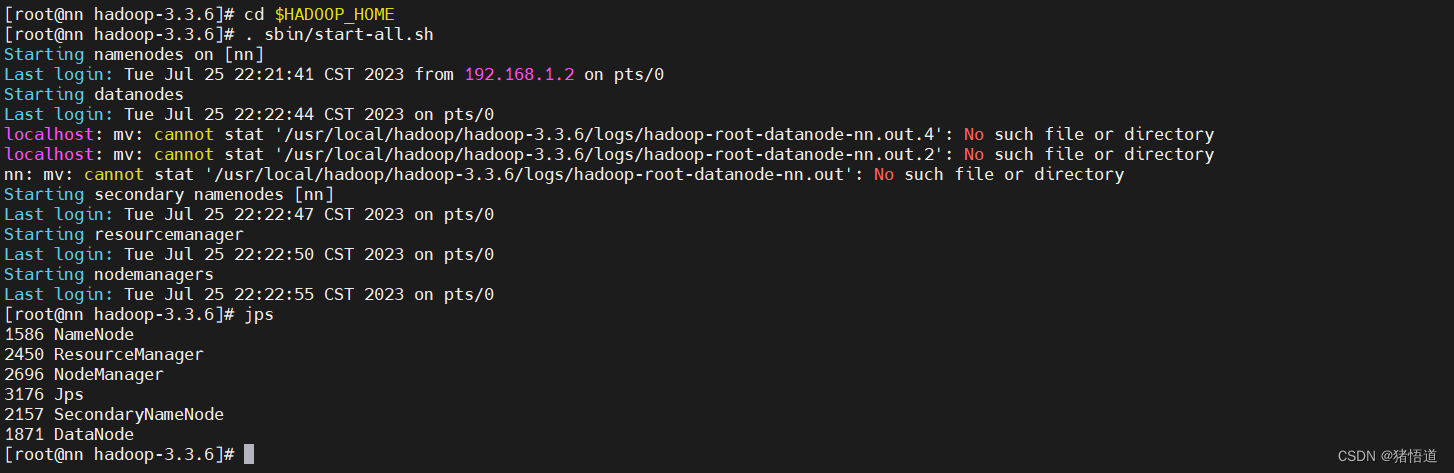
## 1.关闭 hadoop 安全模式
hadoop dfsadmin -safemode leave

2.启动 zookeeper 集群
ZOOKEEPER 集群搭建说明
## 1.启动 zookeeper 集群
zkServer.sh start && ssh root@zk2 "source /etc/profile && zkServer.sh start && exit" && ssh root@zk3 "source /etc/profile && zkServer.sh start && exit"## 2.查看状态
zkServer.sh status && ssh root@zk2 "source /etc/profile && zkServer.sh status && exit" && ssh root@zk3 "source /etc/profile && zkServer.sh status && exit"
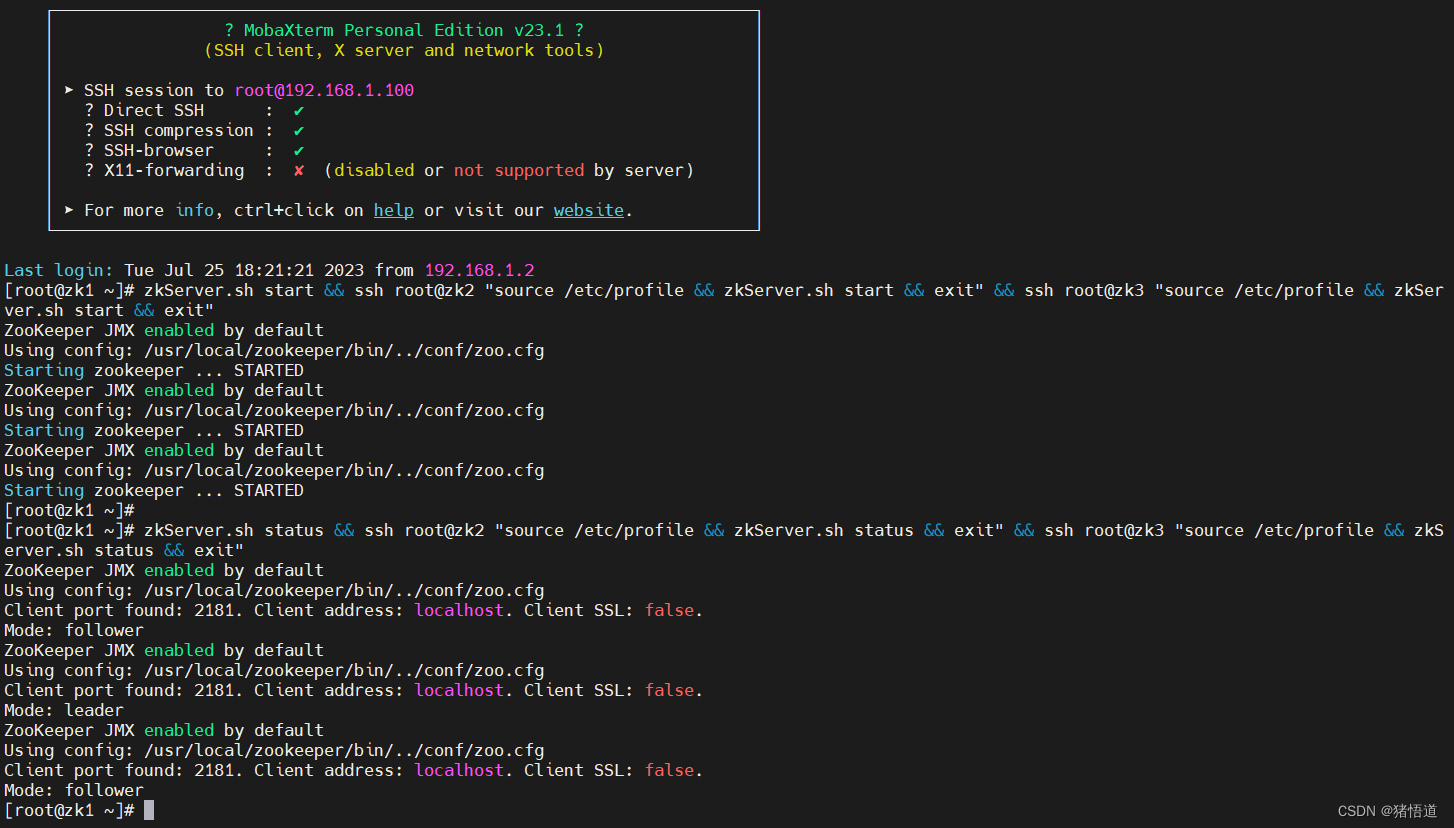
3.启动 hbase 集群
## 1.分别为 nn /nd1 / nd2 配置 zookeeper 域名解析echo'192.168.1.100 zk1' >> /etc/hosts
echo'192.168.1.101 zk2' >> /etc/hosts
echo'192.168.1.102 zk3' >> /etc/hosts
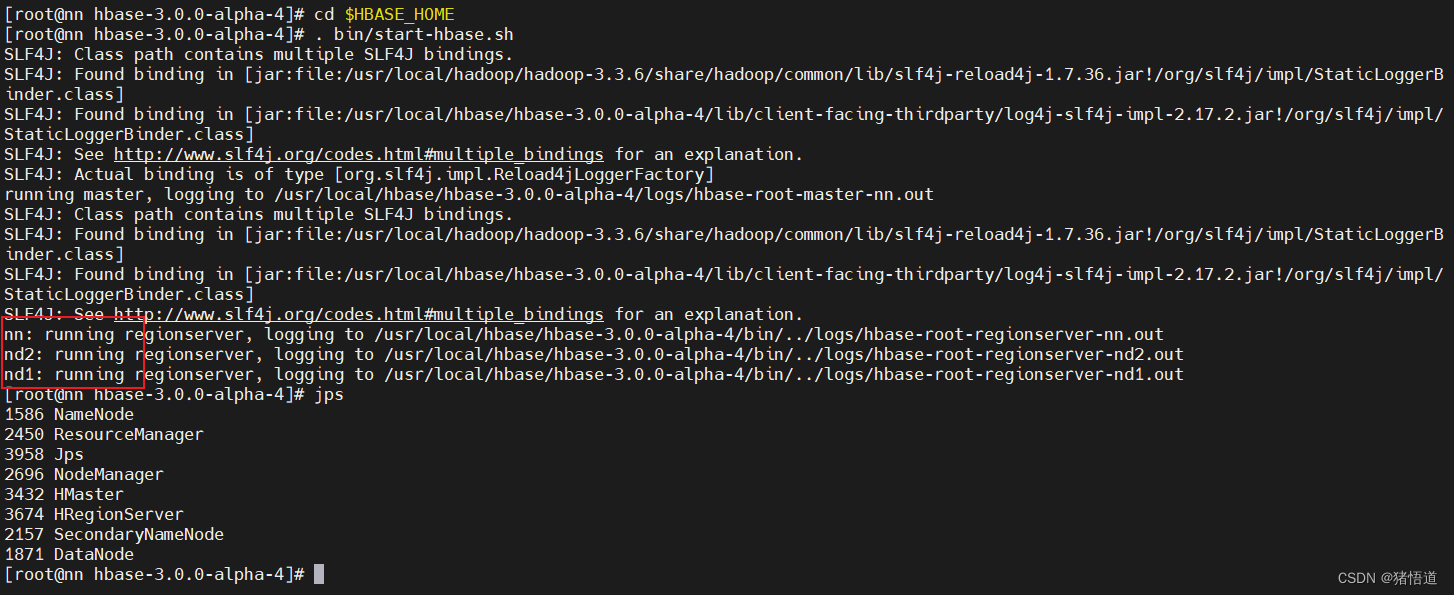
## 2.启动 habase
cd $HBASE_HOME. bin/start-hbase.sh
## 3.停止服务. bin/hbase-daemon.sh stop master
. bin/hbase-daemon.sh stop regionserver
. bin/stop-hbase.sh
查看 UI 监控:http://192.168.1.6:16010/master-status
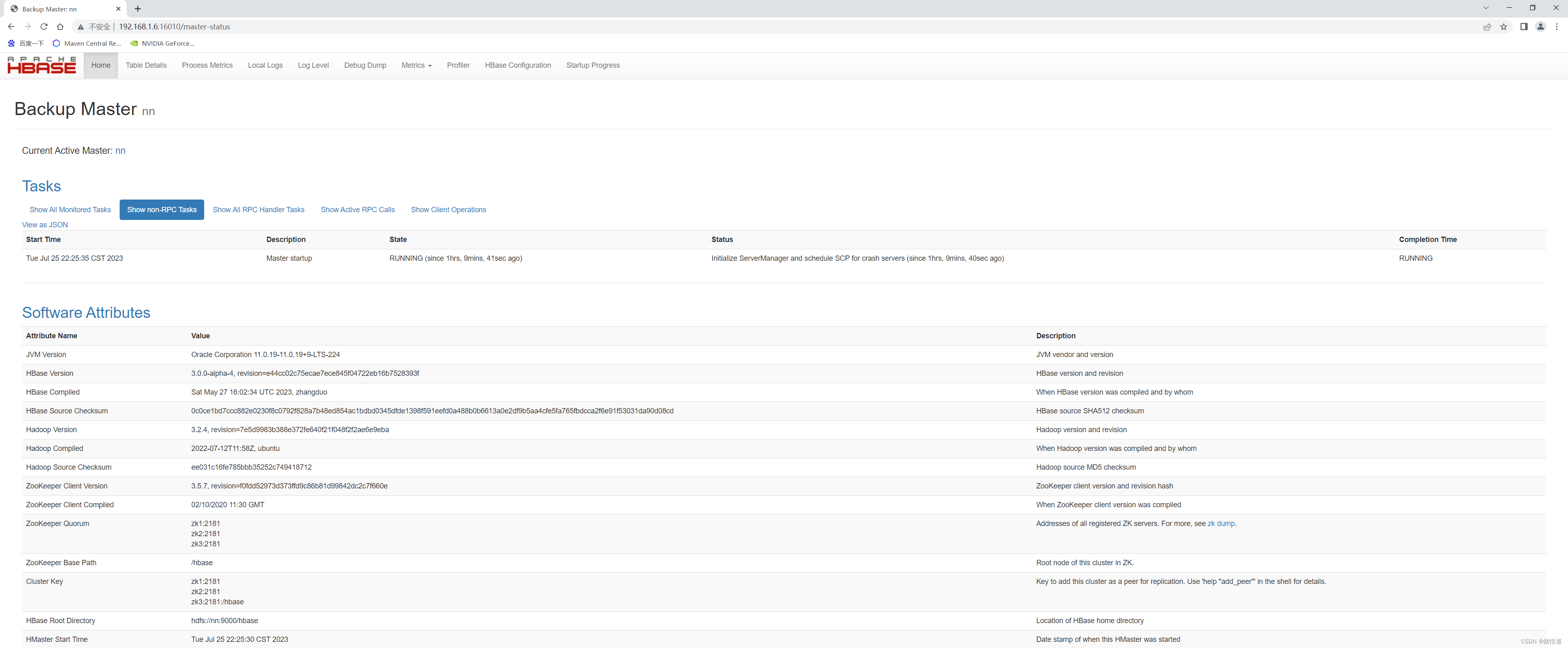
4.集群启停脚本
#!/bin/bash
case $1 in
"start")## start hadoopstart-all.sh
## start zookeeper (先配置免密登录)
zkServer.sh start && ssh root@zk2 "source /etc/profile && zkServer.sh start && exit" && ssh root@zk3 "source /etc/profile && zkServer.sh start && exit"## start hbasestart-hbase.sh
;;"stop")## stop hbase
ssh root@nd1 "source /etc/profile && hbase-daemon.sh stop regionserver && stop-hbase.sh && exit"
ssh root@nd2 "source /etc/profile && hbase-daemon.sh stop regionserver && stop-hbase.sh && exit"
hbase-daemon.sh stop master && hbase-daemon.sh stop regionserver && stop-hbase.sh
## stop zookeeper
zkServer.sh stop && ssh root@zk2 "source /etc/profile && zkServer.sh stop && exit" && ssh root@zk3 "source /etc/profile && zkServer.sh stop && exit"## stop hadoopstop-all.sh
;;*)echo"pls inout start|stop";;
esac
三.测试
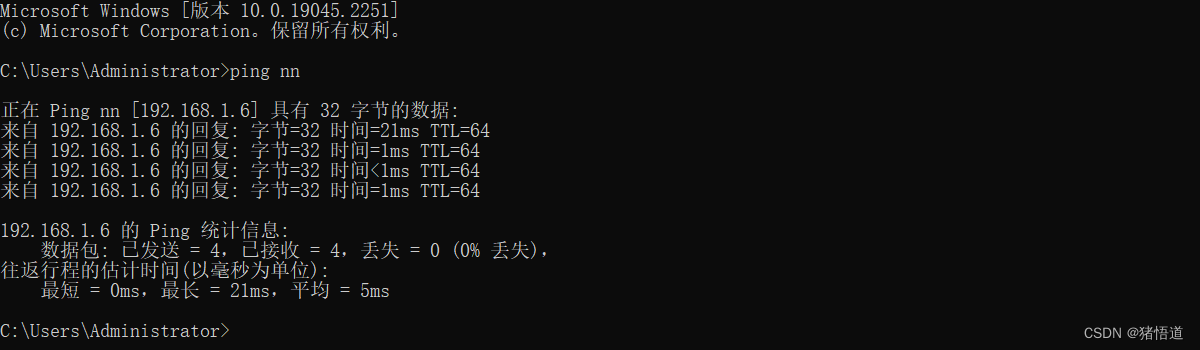
## 1.为 Windows 增加 Hosts 配置,添加 Hbase 集群域名解析 编辑如下文件
C:\Windows\System32\drivers\etc\hosts
## 2.增加如下信息
192.168.1.6 nn
192.168.1.7 nd1
192.168.1.8 nd2
测试配置效果
JDK 版本

工程结构
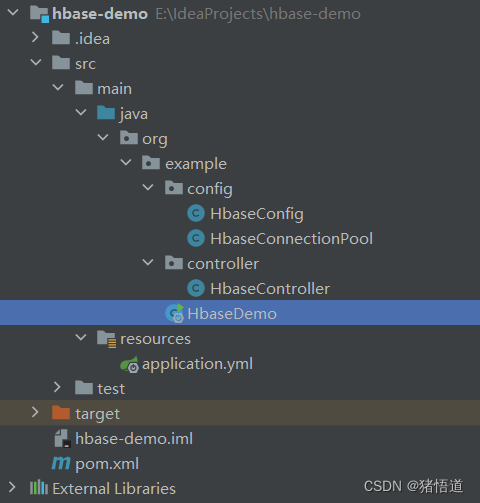
1.Pom 配置
<?xml version="1.0" encoding="UTF-8"?><projectxmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>hbase-demo</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>11</maven.compiler.source><maven.compiler.target>11</maven.compiler.target><spring.version>2.7.8</spring.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><version>${spring.version}</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.28</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>2.0.32</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>3.0.0-alpha-4</version></dependency></dependencies></project>
2.Yml 配置
hbase:zookeeper:quorum: 192.168.1.100,192.168.1.101,192.168.1.102
property:clientPort:2181master:ip: 192.168.1.6
port:16000
3.Hbase 配置类
packageorg.example.config;importorg.apache.hadoop.hbase.HBaseConfiguration;importorg.springframework.beans.factory.annotation.Value;importorg.springframework.context.annotation.Bean;importorg.springframework.context.annotation.Configuration;/**
* @author Administrator
* @Description
* @create 2023-07-25 0:26
*/@ConfigurationpublicclassHbaseConfig{@Value("${hbase.zookeeper.quorum}")privateString zookeeperQuorum;@Value("${hbase.zookeeper.property.clientPort}")privateString clientPort;@Value("${hbase.master.ip}")privateString ip;@Value("${hbase.master.port}")privateint masterPort;@Beanpublicorg.apache.hadoop.conf.ConfigurationhbaseConfiguration(){org.apache.hadoop.conf.Configuration conf =HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum",zookeeperQuorum);
conf.set("hbase.zookeeper.property.clientPort",clientPort);
conf.set("hbase.masters", ip +":"+ masterPort);
conf.set("hbase.client.keyvalue.maxsize","20971520");returnHBaseConfiguration.create(conf);}}
4.Hbase 连接池配置
packageorg.example.config;importlombok.Data;importlombok.extern.slf4j.Slf4j;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.hbase.client.Connection;importorg.apache.hadoop.hbase.client.ConnectionFactory;importorg.springframework.stereotype.Component;importjavax.annotation.PostConstruct;importjavax.annotation.Resource;importjava.util.Enumeration;importjava.util.Vector;/**
* @author Administrator
* @Description
* @create 2023-07-25 22:39
*/@Slf4j@ComponentpublicclassHbaseConnectionPool{/**
* 连接池的初始大小
* 连接池的创建步长
* 连接池最大的大小
*/privateint nInitConnectionAmount =3;privateint nIncrConnectionAmount =3;privateint nMaxConnections =20;/**
* 存放连接池中数据库连接的向量
*/privateVector vcConnections =newVector();/**
* 注入连接配置
*/@ResourceprivateConfiguration hbaseConfiguration;/**
* 初始化连接
*/@PostConstructpublicvoidinit(){createConnections(nInitConnectionAmount);}/**
* 获取可用连接
* @return
*/publicsynchronizedConnectiongetConnection(){Connection conn;while(null==(conn =getFreeConnection())){try{wait(1000);}catch(InterruptedException e){
e.printStackTrace();}}// 返回获得的可用的连接return conn;}/**
* 释放连接
* @param conn
*/publicsynchronizedvoidreleaseConnection(Connection conn){ConnectionWrapper connWrapper;Enumeration enumerate =this.vcConnections.elements();while(enumerate.hasMoreElements()){
connWrapper =(ConnectionWrapper) enumerate.nextElement();if(conn == connWrapper.getConnection()){
connWrapper.setBusy(false);break;}}}/**
* 获取可用连接 当前无可用连接则创建 如果已达到最大连接数则返回 null 阻塞后重试获取
* @return
*/privateConnectiongetFreeConnection(){Connection conn;if(null==(conn =findFreeConnection())){// 创建新连接createConnections(nIncrConnectionAmount);// 查看是否有可用连接if(null==(conn =findFreeConnection())){returnnull;}}return conn;}/**
* 查找可用连接
* @return
*/privateConnectionfindFreeConnection(){ConnectionWrapper connWrapper;//遍历向量内连接对象Enumeration enumerate = vcConnections.elements();while(enumerate.hasMoreElements()){
connWrapper =(ConnectionWrapper) enumerate.nextElement();//判断当前连接是否被占用if(!connWrapper.isBusy()){
connWrapper.setBusy(true);return connWrapper.getConnection();}}// 返回 NULLreturnnull;}/**
* 创建新连接
* @param counts
*/privatevoidcreateConnections(int counts){// 循环创建指定数目的数据库连接try{for(int i =0; i < counts; i++){if(this.nMaxConnections >0&&this.vcConnections.size()>=this.nMaxConnections){
log.warn("已达到最大连接数...");break;}// 创建一个新连接并加到向量
vcConnections.addElement(newConnectionWrapper(newConnection()));}}catch(Exception e){
log.error("创建连接失败...");}}/**
* 创建新连接
* @return
*/privateConnectionnewConnection(){/** hbase 连接 */Connection conn =null;// 创建一个数据库连接try{
conn =ConnectionFactory.createConnection(hbaseConfiguration);}catch(Exception e){
log.error("HBase 连接失败...");}// 返回创建的新的数据库连接return conn;}/**
* 封装连接对象
*/@DataclassConnectionWrapper{/**
* 数据库连接
*/privateConnection connection;/**
* 此连接是否正在使用的标志,默认没有正在使用
*/privateboolean busy =false;/**
* 构造函数,根据一个 Connection 构告一个 PooledConnection 对象
*/publicConnectionWrapper(Connection connection){this.connection = connection;}}}
5.测试类
packageorg.example.controller;importlombok.extern.slf4j.Slf4j;importorg.apache.hadoop.hbase.Cell;importorg.apache.hadoop.hbase.CompareOperator;importorg.apache.hadoop.hbase.TableName;importorg.apache.hadoop.hbase.client.*;importorg.apache.hadoop.hbase.filter.ColumnValueFilter;importorg.apache.hadoop.hbase.filter.Filter;importorg.apache.hadoop.hbase.util.Bytes;importorg.example.config.HbaseConnectionPool;importorg.springframework.web.bind.annotation.GetMapping;importorg.springframework.web.bind.annotation.RequestMapping;importorg.springframework.web.bind.annotation.RestController;importjavax.annotation.Resource;importjava.io.IOException;importjava.util.*;/**
* @author Administrator
*
* 可利用 aop 进行连接获取和释放处理
*
* @Description
* @create 2023-07-25 23:06
*/@Slf4j@RestController@RequestMapping("/hbase")publicclassHbaseController{@ResourceprivateHbaseConnectionPool pool;/**
* 表名
*/privateString tbl_user ="tbl_user";/**
* 创建表(不允许重复创建)
*/@GetMapping("/create")publicvoidcreateTable(){Connection conn =null;//获取连接try{
conn = pool.getConnection();Admin admin = conn.getAdmin();TableName tableName =TableName.valueOf(tbl_user);if(!admin.tableExists(tableName)){//指定表名TableDescriptorBuilder tdb_user =TableDescriptorBuilder.newBuilder(tableName);//添加列族(info,data)ColumnFamilyDescriptor hcd_info =ColumnFamilyDescriptorBuilder.of("name");ColumnFamilyDescriptor hcd_data =ColumnFamilyDescriptorBuilder.of("age");
tdb_user.setColumnFamily(hcd_info);
tdb_user.setColumnFamily(hcd_data);//创建表TableDescriptor td = tdb_user.build();
admin.createTable(td);}}catch(IOException e){thrownewRuntimeException(e);}finally{if(null!= conn){
pool.releaseConnection(conn);}}}/**
* 删除表(不允许删除不存在的表)
*/@GetMapping("/drop")publicvoiddropTable(){Connection conn =null;try{
conn = pool.getConnection();Admin admin = conn.getAdmin();TableName tableName =TableName.valueOf(tbl_user);if(admin.tableExists(tableName)){
admin.disableTable(tableName);
admin.deleteTable(tableName);}}catch(IOException e){thrownewRuntimeException(e);}finally{if(null!= conn){
pool.releaseConnection(conn);}}}/**
* 插入测试
*/@GetMapping("/insert")publicvoidinsert(){
log.info("---插入一列数据---1");putData(tbl_user,"row1","name","a","zhangSan");putData(tbl_user,"row1","age","a","18");
log.info("---插入多列数据---2");putData(tbl_user,"row2","name",Arrays.asList("a","b","c"),Arrays.asList("liSi","wangWu","zhaoLiu"));
log.info("---插入多列数据---3");putData(tbl_user,"row3","age",Arrays.asList("a","b","c"),Arrays.asList("18","19","20"));
log.info("---插入多列数据---4");putData(tbl_user,"row4","age",Arrays.asList("a","b","c"),Arrays.asList("30","19","20"));}/**
* 插入数据(单条)
* @param tableName 表名
* @param rowKey rowKey
* @param columnFamily 列族
* @param column 列
* @param value 值
* @return true/false
*/publicbooleanputData(String tableName,String rowKey,String columnFamily,String column,String value){returnputData(tableName, rowKey, columnFamily,Arrays.asList(column),Arrays.asList(value));}/**
* 插入数据(批量)
* @param tableName 表名
* @param rowKey rowKey
* @param columnFamily 列族
* @param columns 列
* @param values 值
* @return true/false
*/publicbooleanputData(String tableName,String rowKey,String columnFamily,List<String> columns,List<String> values){Connection conn =null;try{
conn = pool.getConnection();Table table = conn.getTable(TableName.valueOf(tableName));Put put =newPut(Bytes.toBytes(rowKey));for(int i=0; i<columns.size(); i++){
put.addColumn(Bytes.toBytes(columnFamily),Bytes.toBytes(columns.get(i)),Bytes.toBytes(values.get(i)));}
table.put(put);
table.close();returntrue;}catch(IOException e){
e.printStackTrace();returnfalse;}finally{if(null!= conn){
pool.releaseConnection(conn);}}}/**
* 查询测试
*/@GetMapping("/query")publicvoidgetResultScanner(){
log.info("全表数据:{}",getData(tbl_user));
log.info("过滤器,按年龄 [18]:{}",getData(tbl_user,newColumnValueFilter(Bytes.toBytes("age"),Bytes.toBytes("a"),CompareOperator.EQUAL,Bytes.toBytes("18"))));
log.info("根据 rowKey [row1]:{}",getData(tbl_user,"row1"));
log.info("根据 rowKey 列族 列 [row2 name a]:{}",getData(tbl_user,"row2","name","a"));}/**
* 获取数据(全表数据)
* @param tableName 表名
* @return map
*/publicList<Map<String,String>>getData(String tableName){List<Map<String,String>> list =newArrayList<>();Connection conn =null;try{
conn = pool.getConnection();Table table = conn.getTable(TableName.valueOf(tableName));Scan scan =newScan();ResultScanner resultScanner = table.getScanner(scan);for(Result result : resultScanner){HashMap<String,String> map =newHashMap<>(result.listCells().size());
map.put("row",Bytes.toString(result.getRow()));for(Cell cell : result.listCells()){//列族String family =Bytes.toString(cell.getFamilyArray(), cell.getFamilyOffset(), cell.getFamilyLength());//列String qualifier =Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength());//值String data =Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());
map.put(family +":"+ qualifier, data);}
list.add(map);}
table.close();}catch(IOException e){
e.printStackTrace();}finally{if(null!= conn){
pool.releaseConnection(conn);}}return list;}/**
* 获取数据(根据 filter)
* @param tableName 表名
* @param filter 过滤器
* @return map
*/publicList<Map<String,String>>getData(String tableName,Filter filter){List<Map<String,String>> list =newArrayList<>();Connection conn =null;try{
conn = pool.getConnection();Table table = conn.getTable(TableName.valueOf(tableName));Scan scan =newScan();// 添加过滤器
scan.setFilter(filter);ResultScanner resultScanner = table.getScanner(scan);for(Result result : resultScanner){HashMap<String,String> map =newHashMap<>(result.listCells().size());
map.put("row",Bytes.toString(result.getRow()));for(Cell cell : result.listCells()){String family =Bytes.toString(cell.getFamilyArray(), cell.getFamilyOffset(), cell.getFamilyLength());String qualifier =Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength());String data =Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());
map.put(family +":"+ qualifier, data);}
list.add(map);}
table.close();}catch(IOException e){
e.printStackTrace();}finally{if(null!= conn){
pool.releaseConnection(conn);}}return list;}/**
* 获取数据(根据 rowKey)
* @param tableName 表名
* @param rowKey rowKey
* @return map
*/publicMap<String,String>getData(String tableName,String rowKey){HashMap<String,String> map =newHashMap<>();Connection conn =null;try{
conn = pool.getConnection();Table table = conn.getTable(TableName.valueOf(tableName));Get get =newGet(Bytes.toBytes(rowKey));Result result = table.get(get);if(result !=null&&!result.isEmpty()){for(Cell cell : result.listCells()){String family =Bytes.toString(cell.getFamilyArray(), cell.getFamilyOffset(), cell.getFamilyLength());String qualifier =Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength());String data =Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());
map.put(family +":"+ qualifier, data);}}
table.close();}catch(IOException e){
e.printStackTrace();}finally{if(null!= conn){
pool.releaseConnection(conn);}}return map;}/**
* 获取数据(根据 rowKey 列族 列)
* @param tableName 表名
* @param rowKey rowKey
* @param columnFamily 列族
* @param columnQualifier 列
* @return map
*/publicStringgetData(String tableName,String rowKey,String columnFamily,String columnQualifier){String data ="";Connection conn =null;try{
conn = pool.getConnection();Table table = conn.getTable(TableName.valueOf(tableName));Get get =newGet(Bytes.toBytes(rowKey));
get.addColumn(Bytes.toBytes(columnFamily),Bytes.toBytes(columnQualifier));Result result = table.get(get);if(result !=null&&!result.isEmpty()){Cell cell = result.listCells().get(0);
data =Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());}
table.close();}catch(IOException e){
e.printStackTrace();}finally{if(null!= conn){
pool.releaseConnection(conn);}}return data;}/**
* 删除数据
*/@GetMapping("/delete")publicvoiddelete(){
log.info("---删除 rowKey --- row1 ");deleteData(tbl_user,"row1");
log.info("---删除 rowKey 列族 --- row2 age ");deleteData(tbl_user,"row2","age");}/**
* 删除数据(根据 rowKey)
* @param tableName 表名
* @param rowKey rowKey
*/publicvoiddeleteData(String tableName,String rowKey){Connection conn =null;try{
conn = pool.getConnection();Table table = conn.getTable(TableName.valueOf(tableName));Delete delete =newDelete(Bytes.toBytes(rowKey));
table.delete(delete);
table.close();}catch(IOException e){
e.printStackTrace();}finally{if(null!= conn){
pool.releaseConnection(conn);}}}/**
* 删除数据(根据 row key,列族)
* @param tableName 表名
* @param rowKey rowKey
* @param columnFamily 列族
*/publicvoiddeleteData(String tableName,String rowKey,String columnFamily){Connection conn =null;try{
conn = pool.getConnection();Table table = conn.getTable(TableName.valueOf(tableName));Delete delete =newDelete(Bytes.toBytes(rowKey));
delete.addFamily(columnFamily.getBytes());
table.delete(delete);
table.close();}catch(IOException e){
e.printStackTrace();}finally{if(null!= conn){
pool.releaseConnection(conn);}}}}
6.启动类
packageorg.example;importorg.springframework.boot.SpringApplication;importorg.springframework.boot.autoconfigure.SpringBootApplication;/**
* @author Administrator
*/@SpringBootApplicationpublicclassHbaseDemo{publicstaticvoidmain(String[] args){SpringApplication.run(HbaseDemo.class,args);}}
7.测试
创建表:http://127.0.0.1:8080/hbase/create
插入:http://127.0.0.1:8080/hbase/insert
查询:http://127.0.0.1:8080/hbase/query
删除:http://127.0.0.1:8080/hbase/delete
删除表:http://127.0.0.1:8080/hbase/drop
查看 UI
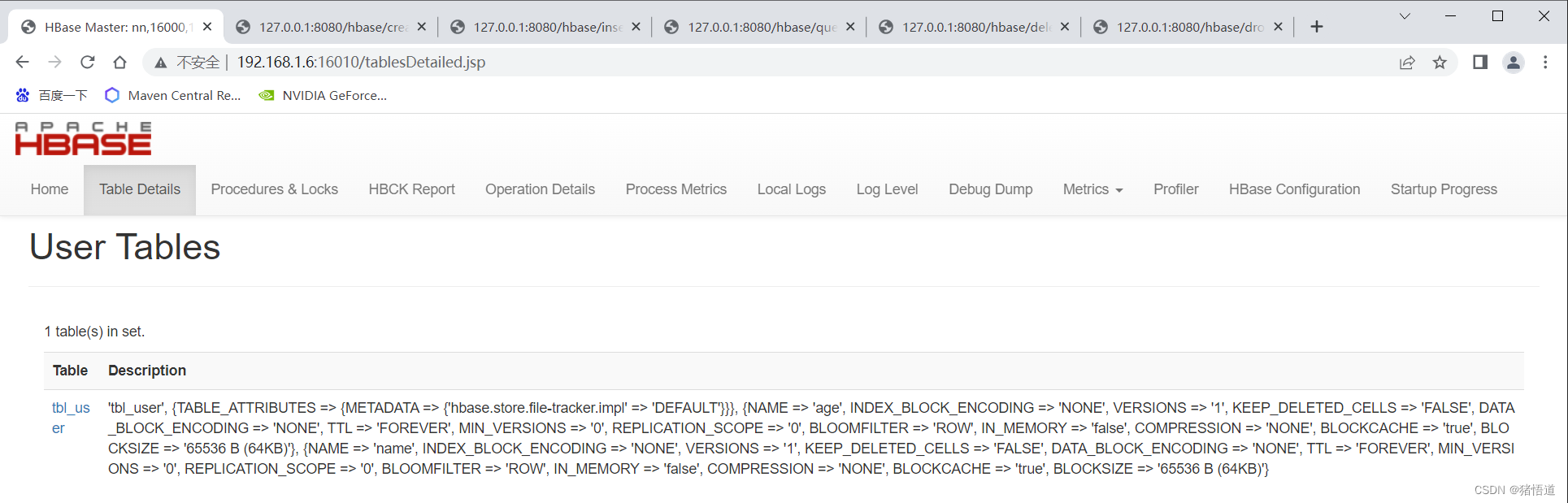
测试输出日志

本文转载自: https://blog.csdn.net/weixin_42176639/article/details/131796472
版权归原作者 猪悟道 所有, 如有侵权,请联系我们删除。
版权归原作者 猪悟道 所有, 如有侵权,请联系我们删除。