
文章目录
黑马头条-day06
Kafka架构图

一、文章上下架需求和实现方案
1.1 需求分析

思考:如果app端文章被投诉,自媒体下架处理后如何同步到APP端?
类似场景:文章点赞,喜欢,不喜欢,点击关注后权重会有变化,如何实时更新?
1.2 技术实现讨论

feign远程调用是http请求,是同步调用,跨服务之间的同步变异步,要使用消息队列技术,不能使用线程池。
1.3 消息中间件对比
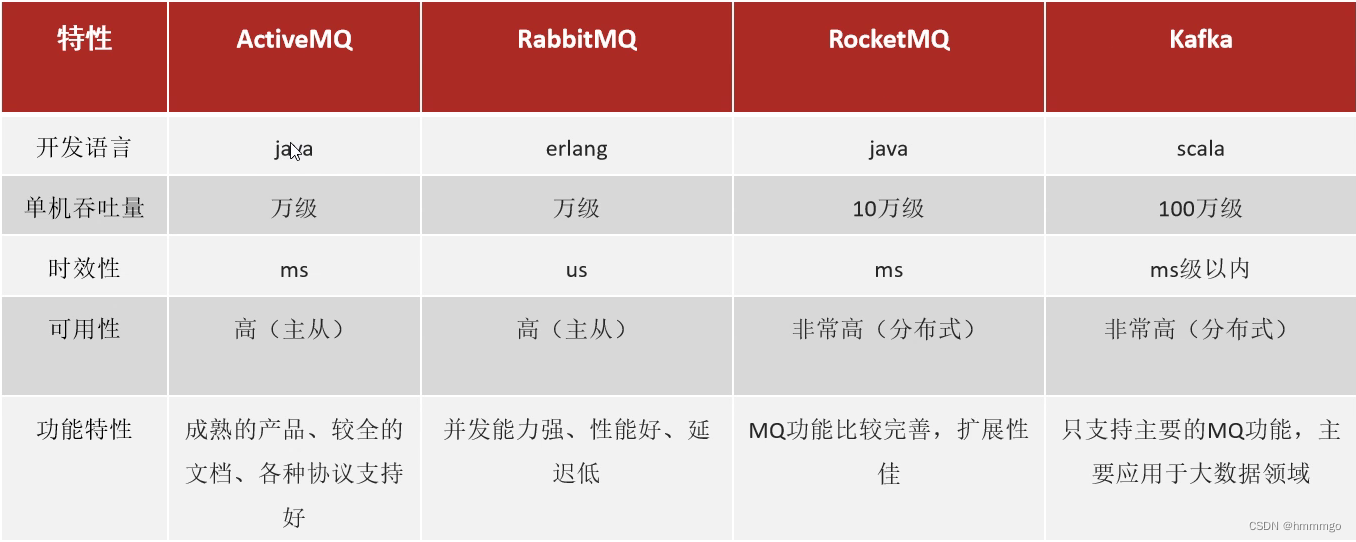
kafka不仅支持发布、订阅功能,还具备流式计算功能。
选择建议
二、Kafka消息中间件介绍
2.1 Kafka环境搭建
Kafka安装和配置
kafka支持集群部署,broker集群的注册管理和Topic的注册管理需要用到注册中心zookeeper,所以安装kafka之前必须先安装zookeeper。虚拟机内已经安装过这两服务,目前是停机状态,执行启动命令即可。
先启动zookeeper
docker starter zookeeper
在启动kafka
docker start kafka
2.2 Kafka快速入门
2.2.1 kafka概念介绍
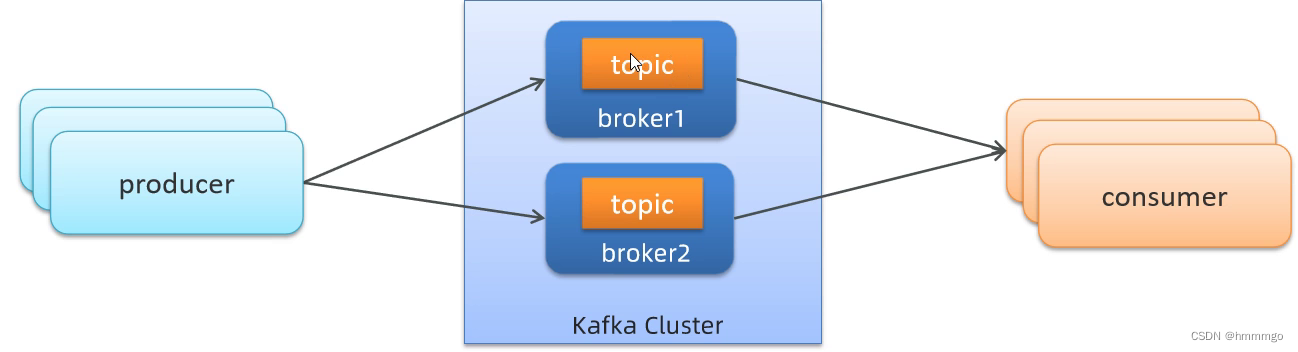
producer: 生产消息的对象称之为主题生产者,生产者可以有多个。
topic: kafka将消息分门别类,每一类的消息称之为一个主题(topic),kafka中每个Topic都会到对应的目录进行记录
broker: 已生产的消息保存在一组服务器中,称之为kafka集群。集群中的每一个服务器都是一个代理(broker)。消费者可以订阅一个或多个主题(Topic),并从Broker拉数据,从而消费这些已发布的消息。当broker接收到producer发送过来的消息时,需要根据消息的主题和分区信息,将该消息写入到该分区当前最后的segment文件中,文件的写入方式是追加写。
consumer: 订阅消息并处理发布的消息的对象称之为主题消费者,消费者也可以有多个。
生产者和消费者,也是kafka的客户端
2.2.2 springboot集成kafka
①导入spring-kafka依赖信息
<!-- kafkfa --><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><exclusions><exclusion><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId></dependency>
②在resources下创建文件application.yml
server:port:9991spring:application:name: kafka-demo
kafka:# kafka的服务端地址bootstrap-servers: 192.168.200.130:9092# 生产者配置producer:# key的String类型序列化器key-serializer: org.apache.kafka.common.serialization.StringSerializer
# value的String类型序列化器value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 消费者consumer:# 消费者群组名称,自定义group-id: ${spring.application.name}-test
# 反序列化器key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
③生产者代码
在controller中生产消息
@RestControllerpublicclassProducerController{@AutowiredprivateKafkaTemplate kafkaTemplate;@GetMapping("/sendKeyValue/{key}/{value}")publicStringsendKeyValue(@PathVariableString key,@PathVariableString value){// 发送消息到固定的主题(testTopic)中// 发的消息可以是一个value的值,也可以是键值对
kafkaTemplate.send("testTopic", key,value);return"ok";}// 如果要发送键值对,可以把键值对封装成json,发送value@GetMapping("/sendKeyValue/{value}")publicStringsendKeyValue(@PathVariableString value){
kafkaTemplate.send("testTopic",value);return"ok";}}
④消费者代码
@ComponentpublicclassConsumerListener{/**
* 消费消息的方法
* @param consumerRecord
*/@KafkaListener(topics ="testTopic")// 接收的都是ConsumerRecord这个对象,这个对象里可以获取到key和value的值publicvoidreceiveMsg(ConsumerRecord<String,String> consumerRecord){//要做非空判断,有两种方式// if(consumerRecord!=null){// System.out.println(consumerRecord.key() + "==>" + consumerRecord.value());// }Optional<ConsumerRecord<String,String>> optional =Optional.ofNullable(consumerRecord);
optional.ifPresent(x->{System.out.println(x.key()+"==>"+ x.value());});}}
2.3 Kafka消费组理解
2.3.1 同一个消费组场景
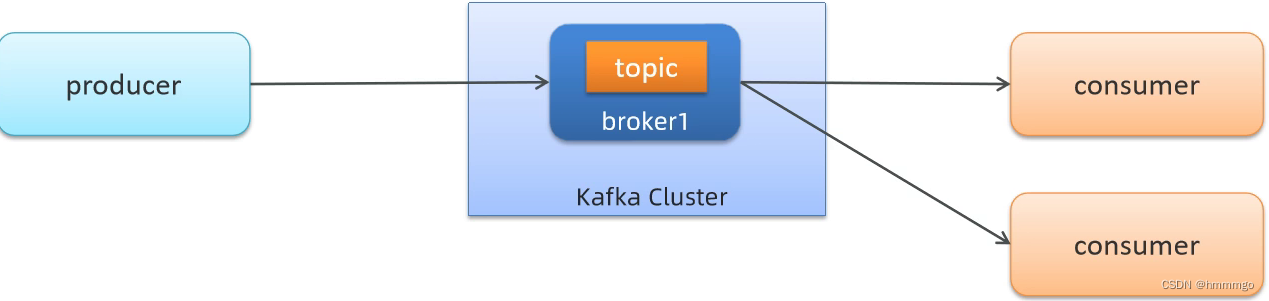
如果消费者在同一个消费组,那么只有一个消费之可以消费数据,并且只有那一个
2.3.2 不同消费组场景
群组名不同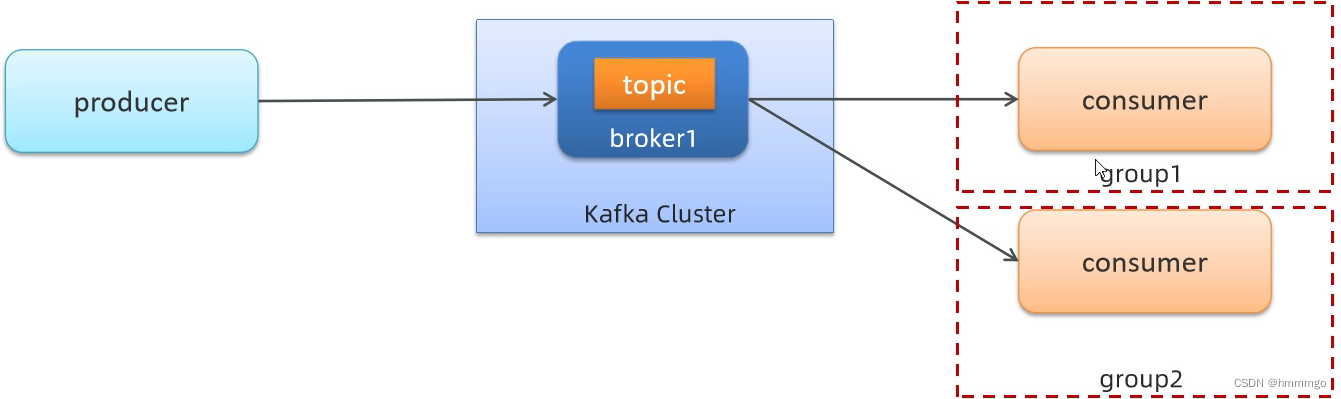
在不同消费者群组,所有消费者都可以消费数据
2.4 Kafka分区和消费相关问题
2.4.1 分区机制(Partition设计)
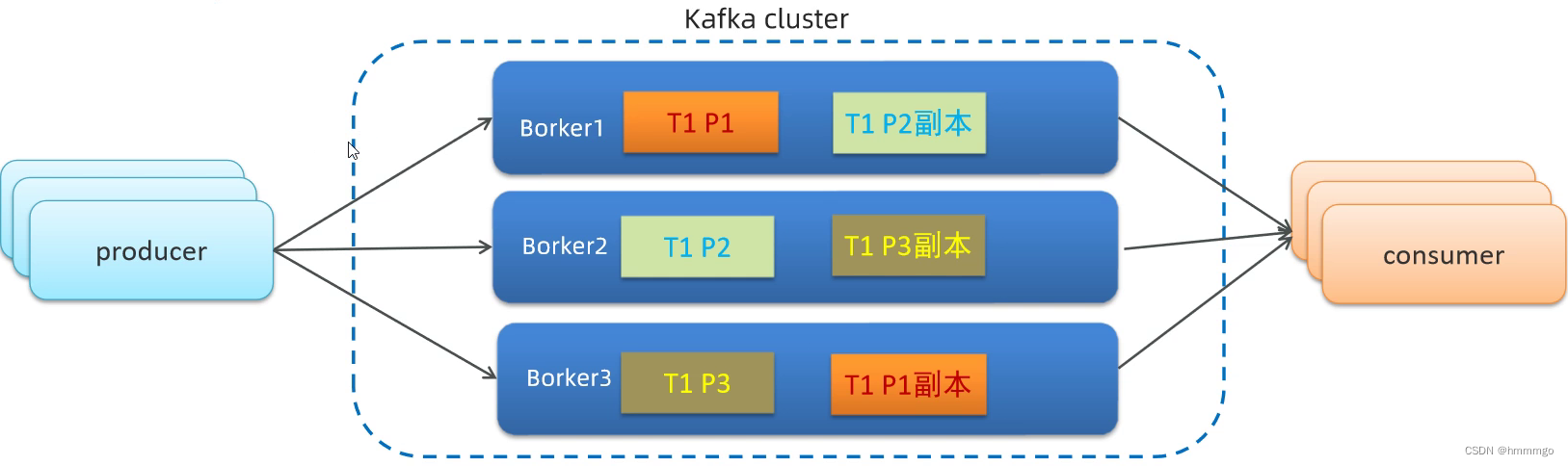
任何主题都会有至少一个分区,一般在集群的时候,每个主题会有多个分区,分区的数量和集群节点的数量保持一致。
分区就是同一个主题对应的不同数据,比如,一个主题有1000条消息,那么把这个主题分成5份,那么一份就有200条消息,那每一份数据就是每一个分区的数据。分开存储,提高其存储能力,存到不同的服务器,最终存储空间就大了。并且,每一个分区,都有一个备份,至少一个备份,保证其数据的高可用。
1、同一个Topic包含不同的Partition(分区)存储在不同机器,一个分区就是一个提交日志。消息以追加的方式写入分区,然后以先进先出的顺序读取。
2、Partition分区的好处是可以并行读和写,保证kafka高吞吐、高性能、高可用
3、每个Partition针对每一个消费组设计了独立的
偏移量
在kafka容器内/opt/kafka_2.12-2.3.1/config/server.properties中通过配置项num.partitions来指定新建Topic的默认Partition数量,默认是1
2.4.2 Kafka分区和消费相关的问题
**不同消费组可以重复消费原因?分区针对消费组具有独立的
偏移量(offset)设计
**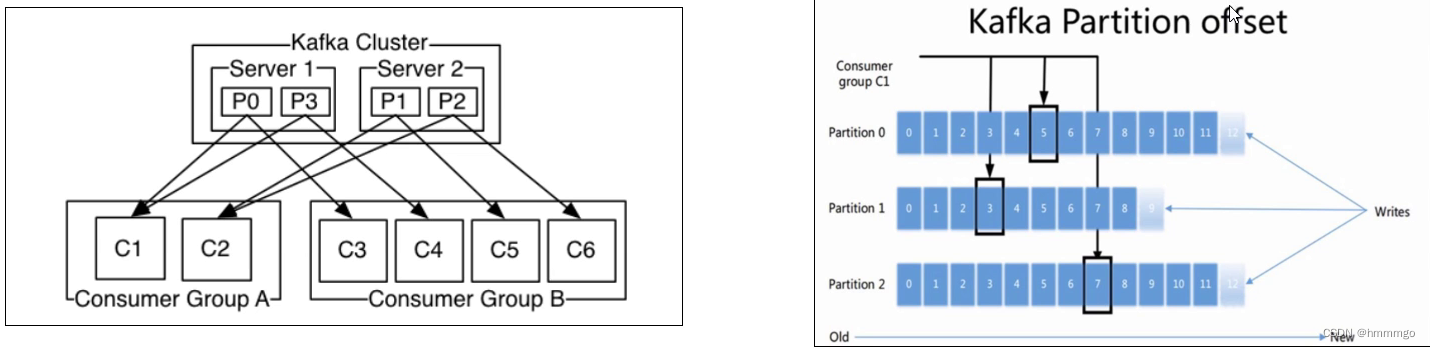
offset
:
偏移量就是消息在日志文件中对应的一个编号,就是该消息的唯一标识。任何发布到partition的消息会被追加到log日志文件尾部(由partition的leader记录,并由partition的follower同步),每条消息在文件中的位置就被称为offset(偏移量),offset是一个long型数字,是按照1自增的,它唯一标记一条消息。消费者通过(offset、partition、topic)跟踪记录。
可以在配置文件server.properties配置log.dirs指定log日志文件目录。
topic_consumer_offsets:
消费者组的位移提交到自带的topic_consumer_offsets里面,当有消费者第一次消费kafka数据时就会自动创建,他的副本数不受集群配置的topic副本数限制,分区数默认50(可以配置),默认压缩策略为compact。当Consumer重启后,自动读取topic_consumer_offsets中位移数据,从而在上次消费截止的地方继续消费。
2.4.3 命令行查看kafka信息
Kafka的消息Log日志文件查看
- 登录到kafka容器
docker exec -it kafka /bin/bash
- vi编辑配置文件
vi /opt/kafka_2.12-2.3.1/config/server.properties,可以看到日志文件目录
- 查看日志目录
ls /kafka/kafka-logs-itcast/
- 生产多条消息,然后查看日志文件
/opt/kafka_2.12-2.3.1/bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files /kafka/kafka-logs-itcast/testTopic-0/00000000000000000000.log --print-data-log
2.4.4 Kafka分区和消息有序性问题
kafka能否保证顺序消费?
单机环境
:一个主题对应一个分区。单个分区内的消息写入有序的,所以针对单个分区的消费是可以保证消费顺序的。
集群环境
:一个主题对应多个分区。例如连续进行如下5个操作,通过kafka生产5条消息,由于kafka是并行写消息并以追加的方式写入到多个不同分区,所以在整个主题范围内无法保证写的顺序,最后消费端数据消费也是无法保证顺序的。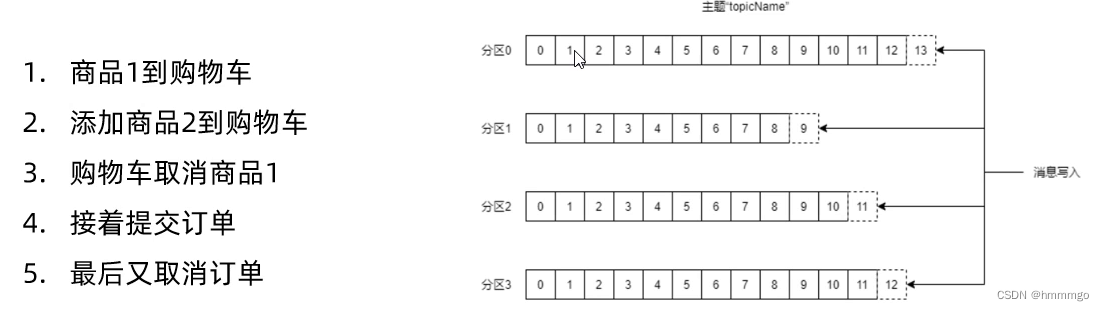
如何解决?
集群环境下,生产者生产消息和消费者消费消息都指向同一个分区。
生产者在发送的时候加一个参数:partition
在单机的情况下只能写0
消费者在注解中加
2.4.5 Kafka分区和顺序消费的问题
分区策略:决定生产者将消息发送到哪个分区的算法


2.4.6 总结
1、kafka分区设计的好处?
高吞吐、高性能、高可用
2、kafka集群环境下默认分区策略
轮询
3、kafka不同消费组可以重复消费原因
kafka分区可以对不同消费组有一套独立消费偏移量
4、kafka如何保证顺序消费?
单机有序,集群无序,生产者和消费者指向同一分区
2.5 Kafka高可用设计
2.5.1 生产端:发送类型、acks和重试机制
①生产端发送消息类型
- 发送并忘记 不关心消息是否正常到达,对返回结果不做任何判断处理,效率高,无法保证消息可靠性。
- 同步发送 使用send()方法发送,他会返回一个Future对象,调用get()方法进行等待kafka响应,就可以知道消息是否发送成功。
- 异步发送 调用send()方法,并指定一个回调函数,服务器在返回响应时调用函数。没有阻塞等待效果,效率更高。
②生产端acks(Acknowledgements)确认应答机制


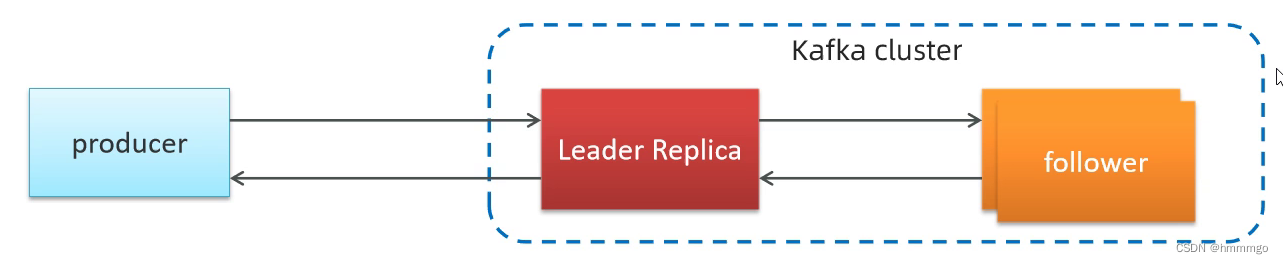
常用的是aks=1
③生产者重试机制
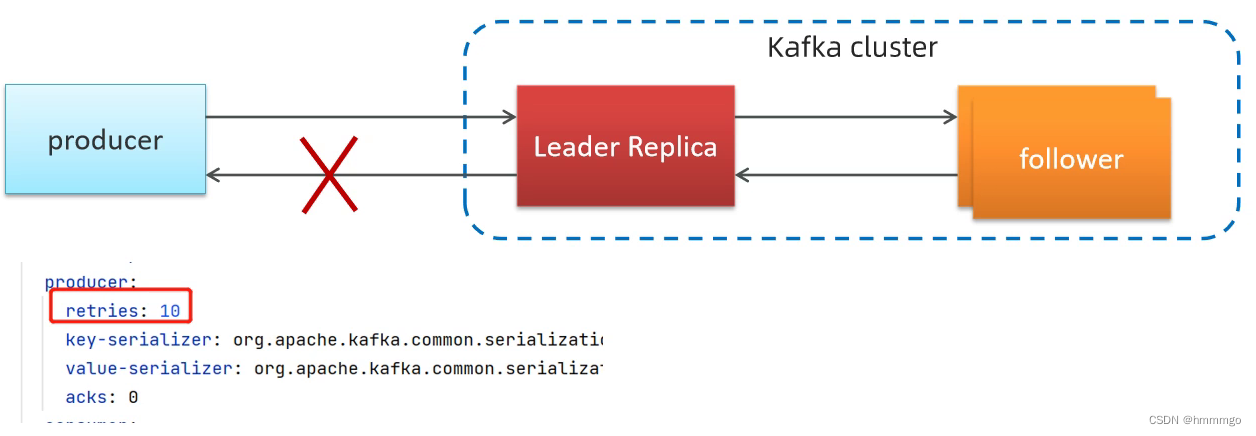
生产者从服务器收到的错误可能是临时性错误(网络中断),在这种情况下,retries参数的值决定了生产者可以重发消息的次数,如果达到这个次数,生产者会放弃重试返回错误,默认情况下,生产者会在每次重试之间等待100ms
问题:
会造成生产重复消息,Leader把数据持久化完成后,要做出响应,在响应的过程中,中断了,生产者会发送重复消息。
2.5.2 服务端:主从备份机制和顺序写
①主从备份机制(Replication
复制
)
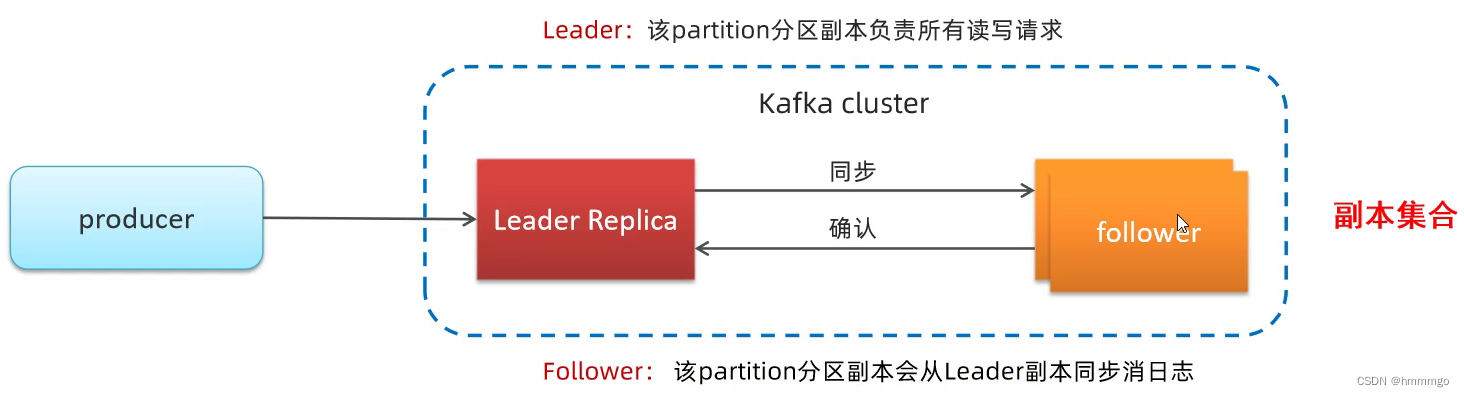
kafka为了提高partition的可靠性而提供了副本的概念(Replica),通过副本机制来实现冗余备份。每个分区可以有多个副本,并且在副本集合中会存在一个leader的副本,所有的读写请求都是有leader副本来进行处理。
kafka定义了两类副本:
- 领导者副本(Leader Replica)
- 追随者副本(Follower Replica)
Leader的读写就是生产消息和消费消息
②备份机制(Replication)-ISR主从同步备份机制
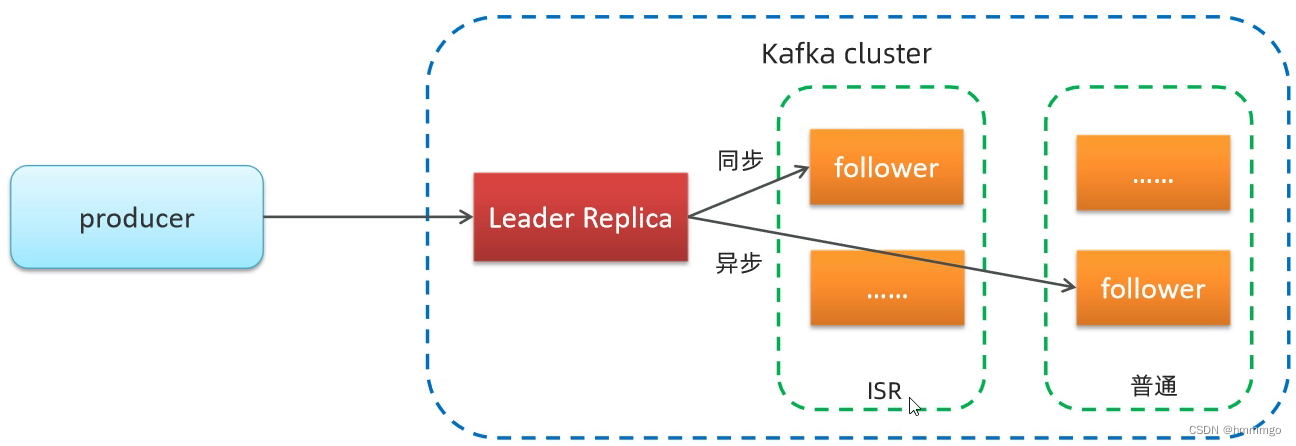
- 我们可以认为,副本集会存在一主多从的关系。一般情况下,同一个分区的多个副本会被均匀分配到集群中的不同broker上,当leader副本所在的broker出现故障后,可以重新选举新的leader副本继续对外提供服务。通过这样的副本机制来提高kafka集群的可用性。
- 所有与leader保持一定程度同步的副本(包括leader)组成ISR(In-Sync Replicas)
- 如果leader失效后,需要选出新的leader,选举的原则如下: - 第一:选举是优先从ISR中选定,因为这个列表中follower的数据是与leader同步的。- 如果ISR列表中的follower都不行了,就只能从其他follower中选取(极端情况),这样也会造成部分数据丢失
③顺序写磁盘(相对于随机写,性能提高百倍以上)
当broker接收到producer发送过来的消息时,需要根据消息的主题和分区信息,将该消息写入到该分区当前最后的segment文件中,文件的写入方式是追加写。
由于是对segment文件追加写,故实现了对磁盘文件的顺序写,避免磁盘随机写时的磁盘寻到的开销,同时由于是追加写,故写入速度与磁盘文件大小无关,具体如图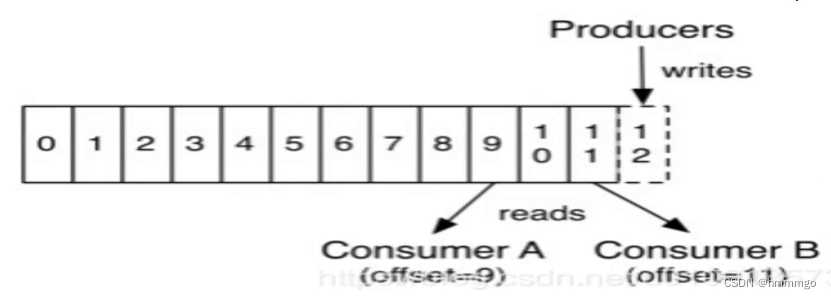
2.5.3 消费端:如何解决重复消息问题
①消费者重复消费产生原因
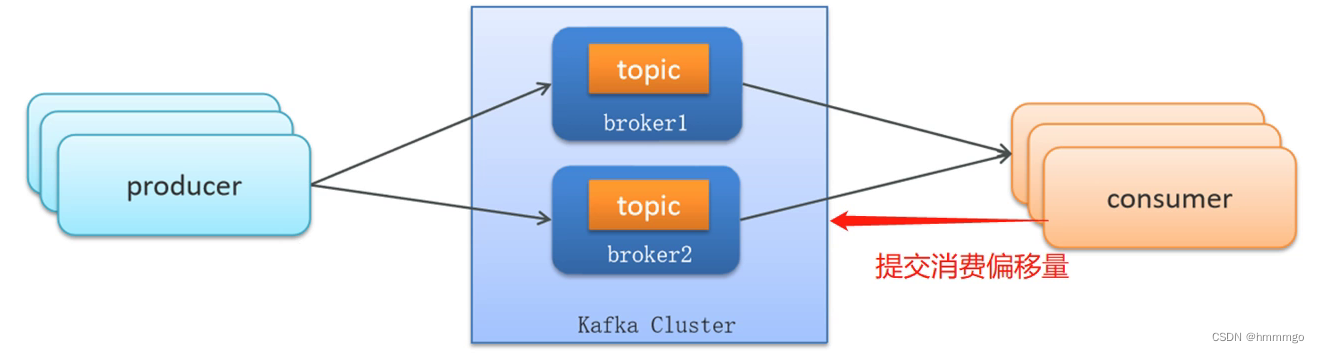
1、生产者如果网络抖动相关原因,可能重复发送消息
2、消费者宕机、重启或者被强行kill进程,导致消费者消费的offset没有提交
3、kafka消费端会每隔5秒自动提交消费偏移量(auto.commit.interval.ms)如果网络问题没来及提交,其他消费者会重复消费消息
4、kafka消费者会每隔10秒向服务端发送心跳(session.timeout.ms)表明还活着,否则服务端认为消费者离组会触发重平衡(重新分配多个分区给多个消费者),重平衡rebalance也会造成消息重复消费(根本原因还是没有提交消费偏移量)
②重平衡Rebalance造成重新消费
kafka不会像其他JMS队列那样需要得到消费者的确认,消费者可以使用kafka来追踪消息在分区的位置(偏移量),消费者会往一个叫做
_consumer_offset
的特殊主题发送消息,消息里包含了每个分区的偏移量。如果消费者发生崩溃或有新的消费者加入群组,就会触发
重平衡
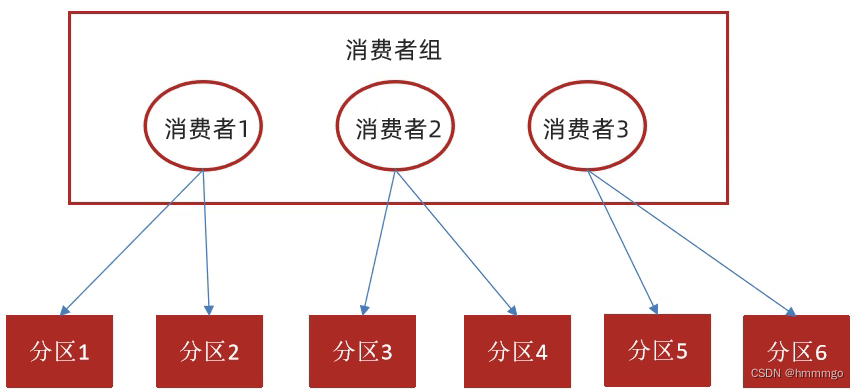
消费者2挂了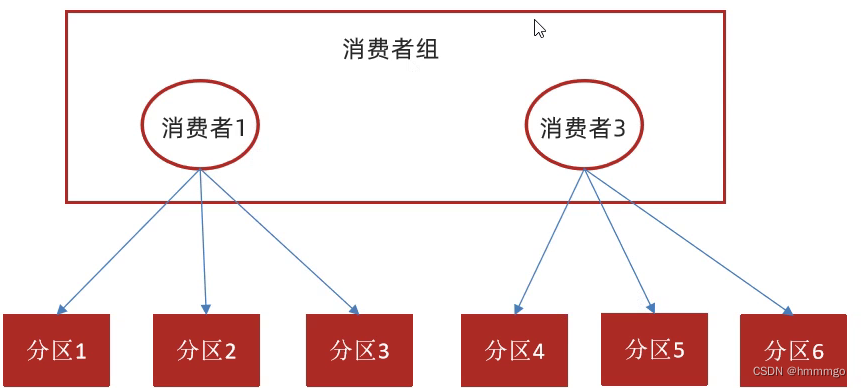
消费者数量或者分区数量发生变化,都会造成重平衡,就可能会造成重复消费。
幂等性: 如果有重复请求,那么处理重复请求的结果,应该跟第一次处理结果相同。
③消费者消息重复如何解决
1、kafka可以手工处理偏移量(不推荐)
当enable.auto.commit被设置为true,提交方式就是让消费者自动提交偏移量,每隔5秒消费者会自动从poll()犯法接收的最大偏移量提交上去
2、从业务角度处理(实际情况不管采用任何消息中间件,重复消费都避免不了)
生产端
发送的消息
添加唯一id(就是锁)
(雪花算法(最好),或者纳秒时间戳)【注意默认不使用messageID,需要显式配置】
消费端
利用去重表判断,会影响性能,一般也不用。
利用
redis去重判断
2.5.4 优化:Kafka吞吐优化设计
1 增加分区数量、2异步发送消息、3消息压缩支持、4批量发送
增加分区数量
可以增加并行写的数量
默认情况下,消息发送时不会被压缩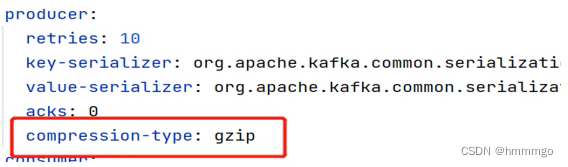

使用压缩可以降低网络传输开销和存储开销,而这往往是向kafka发送消息的瓶颈所在。
批量发送可以提高kafka的吞吐
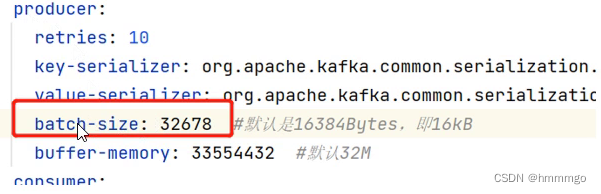

2.6 Kafka消息删除机制

- 对于传统的message queue而言,一般会删除已经被消费的消息,而kafka集群会保留所有的消息,无论其被消费与否。当然,因为磁盘限制,不可能永久保留所有数据
- 两种策略删除旧数据。一是基于时间,而是基于partition文件大小
- 例如可以通过配置$KAFKA_HOME/config/server.properties,让kafka删除一周前的数据,也可以在partition文件超过1GB时删除就数据。
版权归原作者 hmmmgo 所有, 如有侵权,请联系我们删除。