
前言
前短时间,为了验证公司的验证码功能存在安全漏洞,写了一个爬虫程序抓取官网图库,然后通过二值分析,破解验证码进入系统刷单。 其中,整个环节里关键的第一步就是拿到数据 -- Python 爬虫技。
今天,我打算把爬虫经验分享一下,因为不能泄露公司核心信息,所以我随便找了一个第三方网站——**《懂车帝》**做演示。为了展示Selenium效果,网站需满足:需要动态加载(下拉)才能获取完整(或更多)数据的网页,如:淘宝,京东,拼多多的商品也都可以。
通过本篇,你将学会通过Selenium自动化加载HTML的技巧,并利用 BeautifulSoup 解析静态的HTML页面,还有使用 xlwt 插件操作 Excel。
本文仅教学使用,无任何攻击行为或意向。
正文
一、页面分析
1. 打开页面,提取关键信息
首先,打开“某瓣电影一周新片榜”的页面:https://www.dongchedi.com/sales,截图省略了下面列表部分。
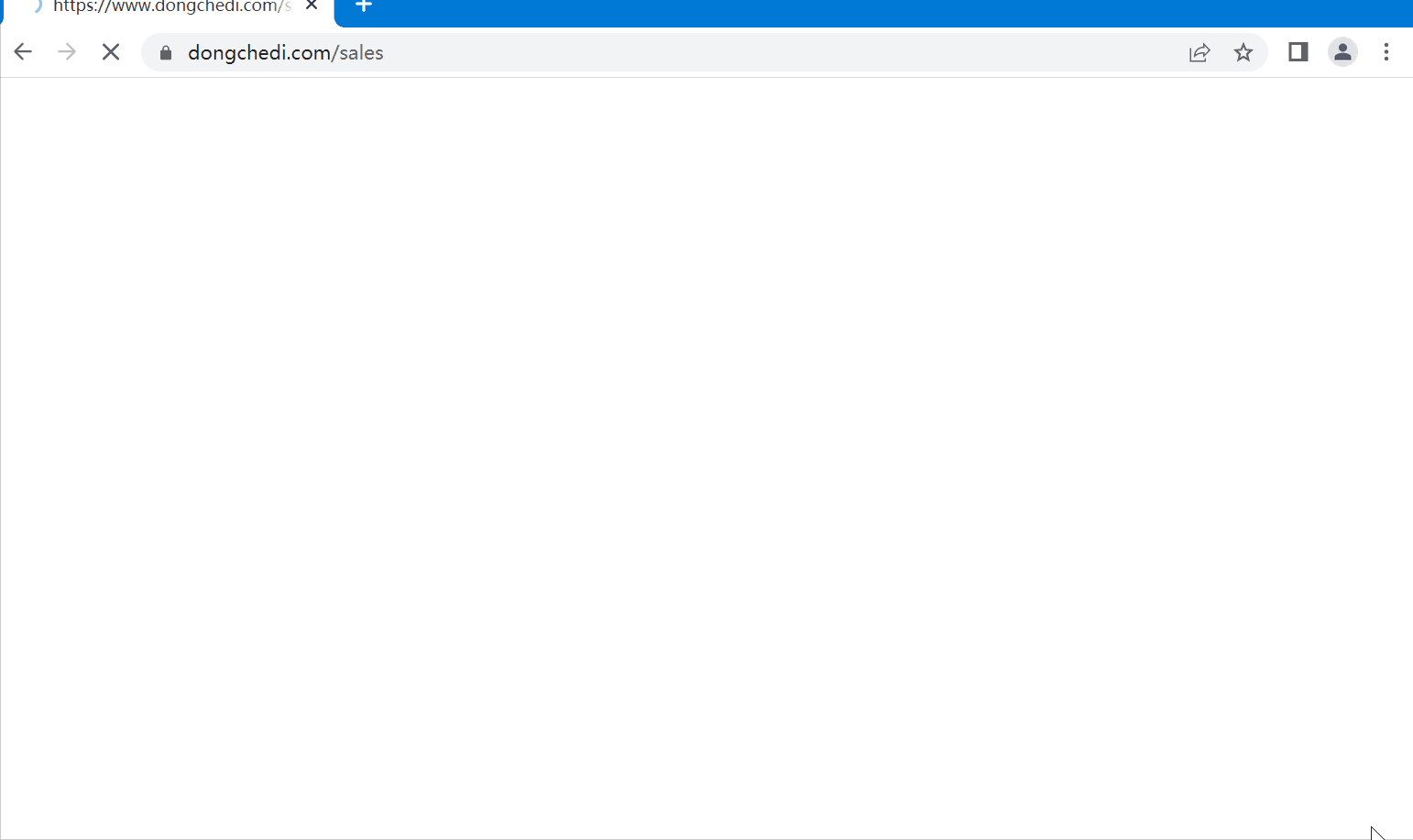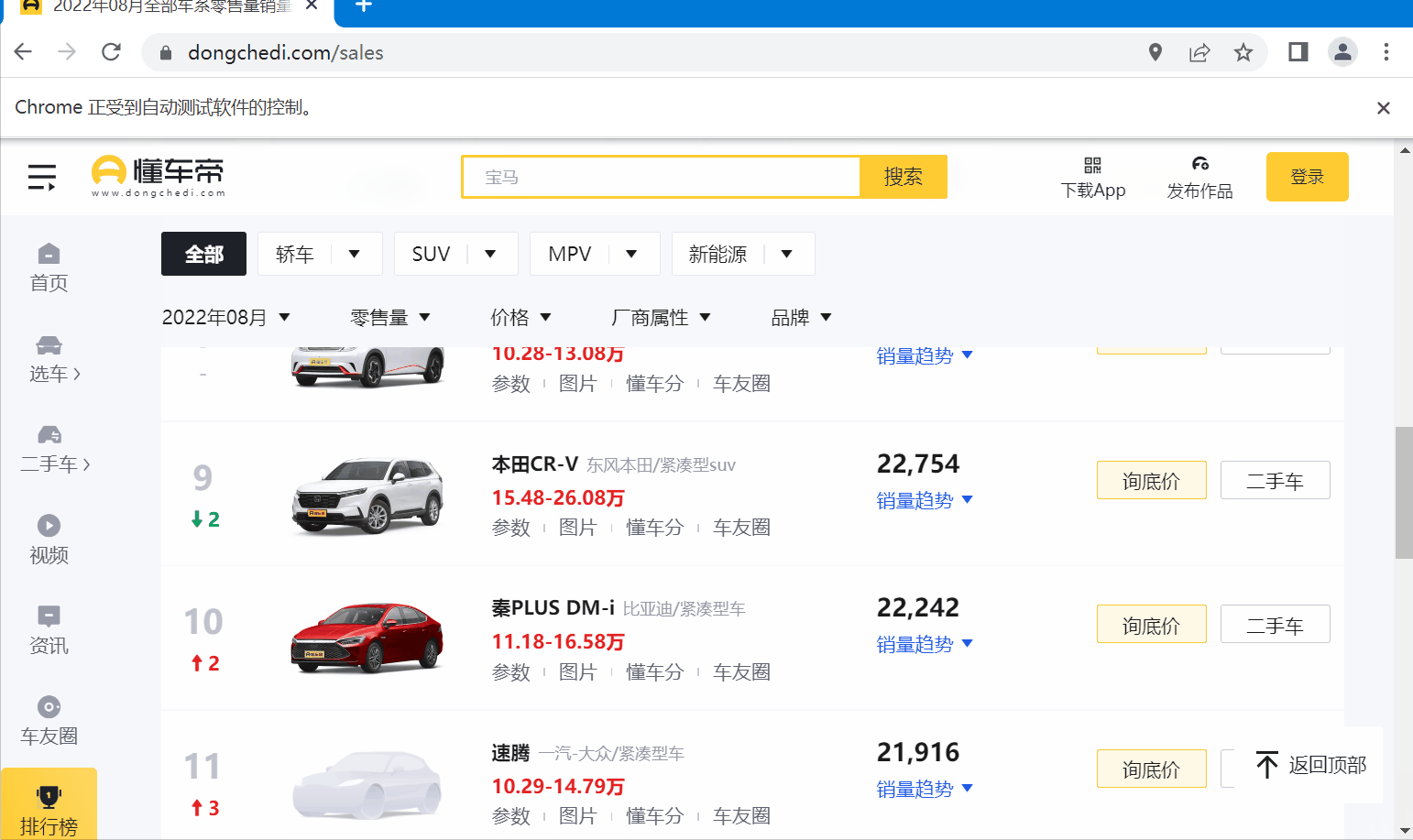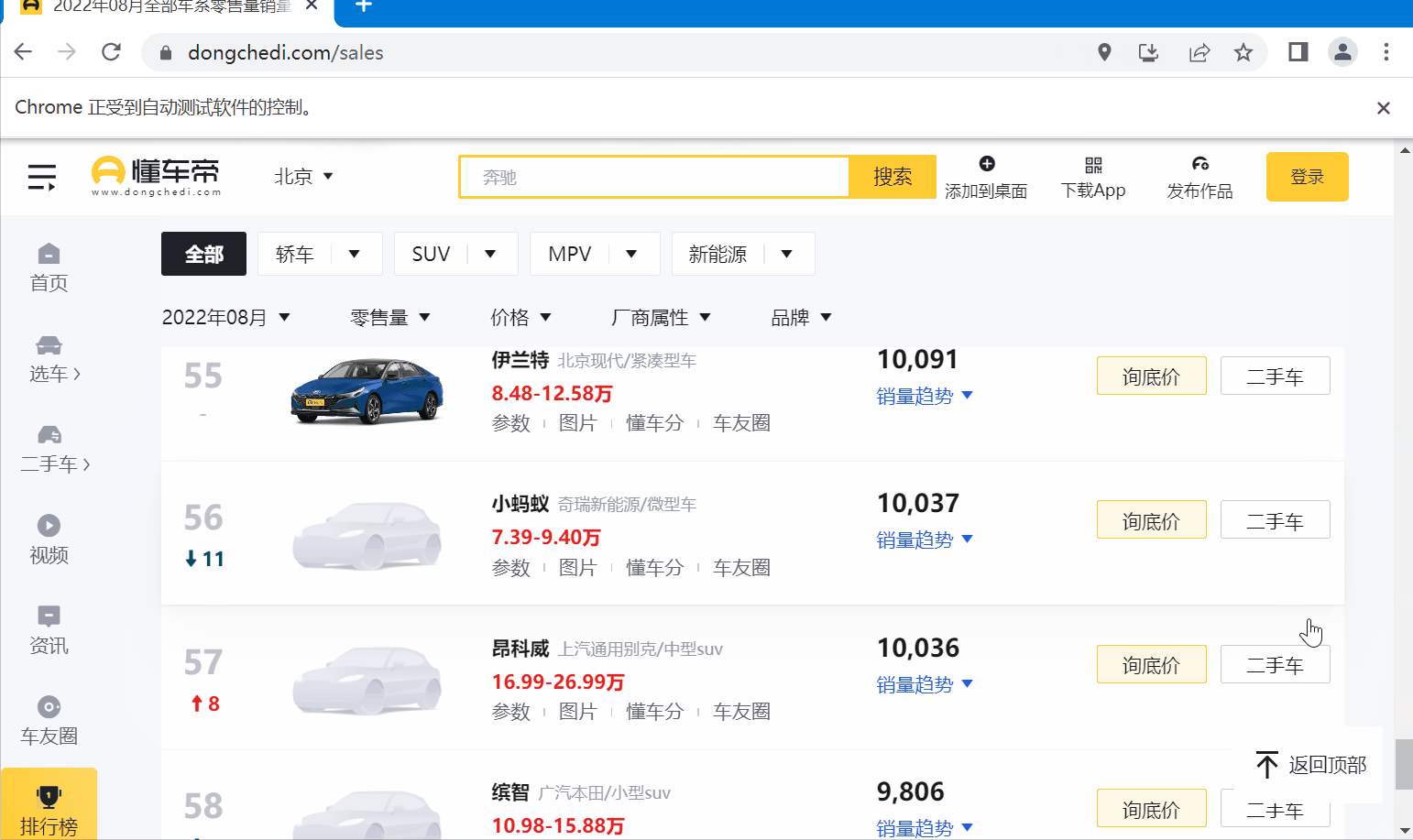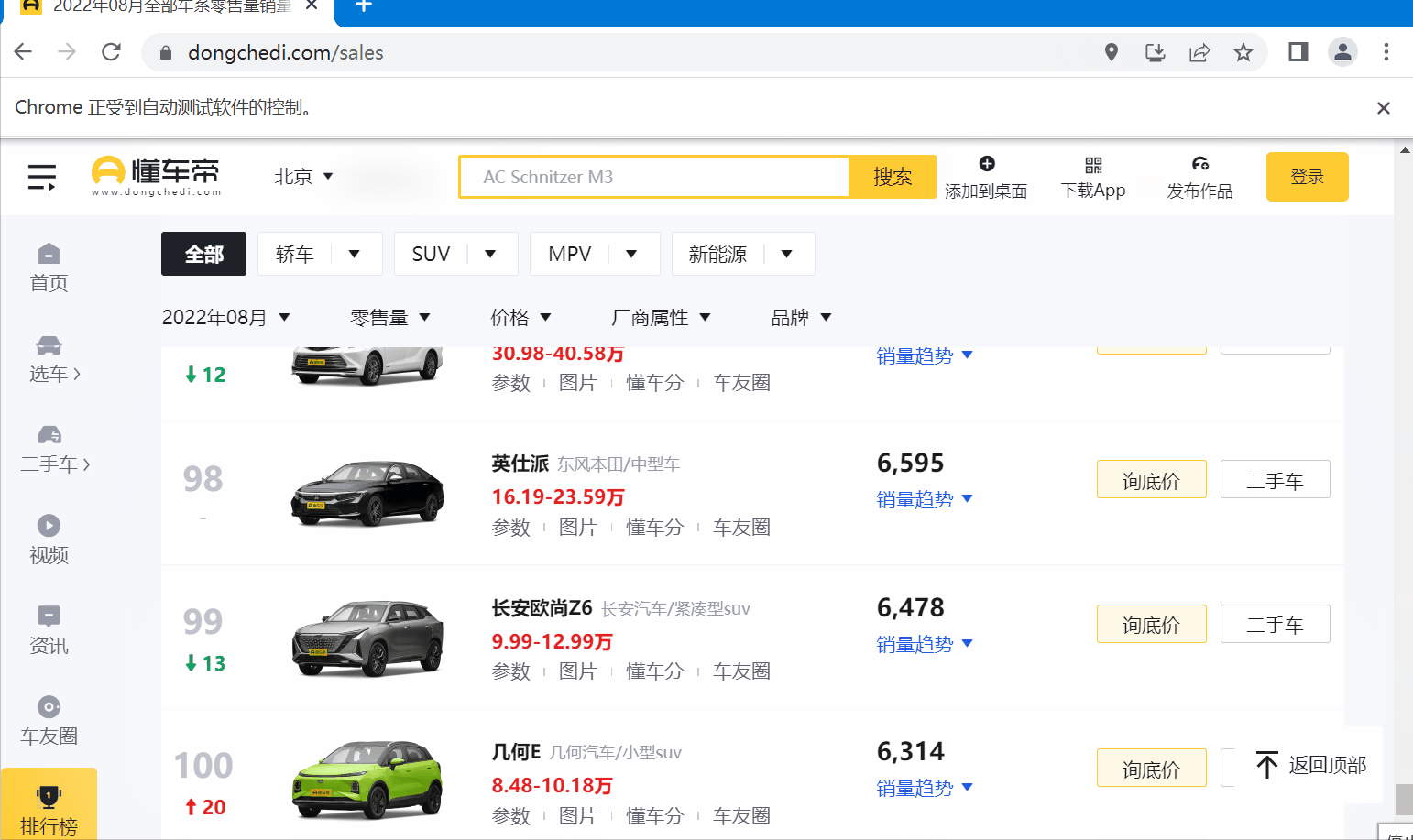
然后,提取榜单里的关键信息,如:当前月份,汽车排名,图片链接,汽车名称,汽车品牌,评论数等,这是我们需要爬取的数据,接下来就需要弄清楚他们在 Html 中的位置。

2. 分析Html页面
Chrome浏览器 - 【F12】检查下 Html 页面结构,找到排行榜数据的具体位置,这对我们后续利用 Selenium 和 BeautifulSoup 解析至关重要。
下面图片里可以看到,月份信息在 “<div class="more_more__z2kQC"></div>” 标签里(篇幅原因,没有展示全),而当月的榜单信息在"<li class="list_item__3gOKl">"的标签里,10条 “<tr></tr> ”标签形成一个List集合。
**注意:**当前页面第一次进来页面只会加载出10条记录,如果想要获取全量的排行榜数据,我们需要用到 Selenium 技术动态加载页面,直到数据全部加载出来为止。

3. 结果展示
以我当前的时间为例——“2022年8月”,一共有“TOP542”条数据。

二、代码讲解
1. 导入关键库
import time # time函数
import xlwt # 进行excel操作
import os.path # os读写
from bs4 import BeautifulSoup # 解析html的
from selenium import webdriver # selenium 驱动
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys # 模仿键盘
from selenium.webdriver.support.wait import WebDriverWait # 导入等待类
from selenium.webdriver.support import expected_conditions as EC # 等待条件
2. Selenium 解析动态Html
因为当前页面没有明显的元素用来判断拉到什么位置就是底部,所以我的规则是:一直循环,直到连续5次 Keys.PAGE_DOWN(下拉),<li> 标签数量不再增加,就认为已经到底了。为了避免程序计算太快,每次下拉还停顿了0.2秒,实际效果不错。
while (flag):
_input.send_keys(Keys.PAGE_DOWN)
driver.implicitly_wait(2)
elem = driver.find_elements(By.CLASS_NAME, "list_item__3gOKl")
len_cur = len(elem)
print(len_now, len_cur)
if (len_now != len_cur):
len_now = len_cur
num = 0
elif (len_now == len_cur and num <= 5):
num = num + 1
time.sleep(0.5)
else:
time.sleep(2)
break
3. Selenium 转 BeautifulSoup
根据小编的开发经验,selenium 很擅长模拟和测试,它动态加载的特性是 BeautifulSoup不 具备的。但是,对于取值操作,简单的还好,复杂点的比如:循环<li>标签这种操作,我还是觉得BeautifulSoup更方便。
在爬虫的世界里,大量有价值的数据都是循环展现的,比如:某排行榜,某商品列表等...所以,Selenium + BeautifulSoup的操作必不可少。
核心代码也非常简单,直接传入 Selenium 驱动 driver,用 page_source() 就可以啦。
# 获取完整渲染的网页源代码
pageSource = driver.page_source
soup = BeautifulSoup(pageSource, 'html.parser')
soup.prettify()
4. 保存数据
# 创建workbook对象
book = xlwt.Workbook(encoding="utf-8",style_compression=0)
# 创建工作表
sheet = book.add_sheet('懂车帝想月销量排行榜', cell_overwrite_ok=True)
col = ("排名", "图片链接", "名称", "品牌", "指导价", "销量")
book.save("销量排行榜.xls")
三、完整代码
细节有待提高,下面的代码大家装好插件,直接拖到本地运行就可以了。
** 如果遇到环境问题,未知异常等,请参照博文:**关于:Python基础,爬虫,常见异常和面试【篇】(专题汇总)
# -*- codeing = utf-8 -*-
import time # time函数
import xlwt # 进行excel操作
import os.path # os读写
from bs4 import BeautifulSoup # 解析html的
from selenium import webdriver # selenium 驱动
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys # 模仿键盘
from selenium.webdriver.support.wait import WebDriverWait # 导入等待类
from selenium.webdriver.support import expected_conditions as EC # 等待条件
# 获取全量数据的 selenium 驱动
def readHtml(baseurl, flag):
print("—————————— Read Html ——————————")
# 打开浏览器
driver = webdriver.Chrome()
driver.get(baseurl)
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.CLASS_NAME, "tw-mt-12")))
# 动态加载排行榜数据
# 我的规则:一直循环,直到连续5次下拉,<li>标签数量不再增加,则认为已经到底了
num, len_now = 0, 0
_input = driver.find_element(By.CLASS_NAME, "body")
while (flag):
_input.send_keys(Keys.PAGE_DOWN)
driver.implicitly_wait(2)
elem = driver.find_elements(By.CLASS_NAME, "list_item__3gOKl")
len_cur = len(elem)
print(len_now, len_cur)
if (len_now != len_cur):
len_now = len_cur
num = 0
elif (len_now == len_cur and num <= 5):
num = num + 1
time.sleep(0.5)
else:
time.sleep(2)
break
return driver
# 将 selenium 驱动转 bs 形式的 html 页面
def getHtml(driver):
print("—————————— Get Html ——————————")
# 获取完整渲染的网页源代码
pageSource = driver.page_source
soup = BeautifulSoup(pageSource, 'html.parser')
soup.prettify()
return soup
# 从 html 页面爬取数据
def getData(soup):
print("—————————— Get Data ——————————")
# 1. 时间
dataTime = soup.find('div', class_="more_more__z2kQC").span.text
# 2. 数据,查找符合要求的字符串
index = 0 # 排行
datalist = [] # 用来存储爬取的网页信息
try:
for item in soup.find_all('li', class_="list_item__3gOKl"):
data = [] # 保存一条数据用
print(item)
# 2.1 生成一条记录
index = index + 1
data.append(index)
data.append(item.find('div', class_='tw-p-12').div.div.img["src"])
dd = item.find('div', class_='tw-py-16 tw-pr-12')
data.append(dd.div.a.text)
data.append(dd.div.span.text)
data.append(dd.p.text)
data.append(item.find('div', class_='tw-py-16 tw-text-center').div.p.text)
# 2.2 存入list
datalist.append(data)
except Exception as e:
print(e)
pass
return dataTime, datalist
# 保存数据到表格
def saveData(datalist, savepath):
print("—————————— save ——————————")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) # 创建workbook对象
sheet = book.add_sheet(dataTime, cell_overwrite_ok=True) # 创建工作表。sheet页名为dataTime
col = ("排名", "图片链接", "名称", "品牌", "指导价", "销量")
for i in range(0, len(col)):
sheet.write(0, i, col[i]) # 列名
for i in range(0, len(datalist)):
# print("第%d条" %(i+1)) # 输出语句,用来测试
data = datalist[i]
for j in range(0, len(col)):
sheet.write(i+1, j, data[j]) # 数据
if os.path.exists(savepath): # 清空路径
os.remove(savepath)
book.save(savepath) # 保存
pass
if __name__ == "__main__":
print("—————————— 开始执行 ——————————")
# 1. 读取url
html = readHtml("https://www.dongchedi.com/sales", True)
# 2. selenium转BeautifulSoup
soup = getHtml(html)
# 3. 处理Html数据
dataTime, dataList = getData(soup)
# 4. 保存数据
saveData(dataList, dataTime + "汽车销量排行总榜.xls")
print("—————————— 爬取完毕 ——————————")
本文转载自: https://blog.csdn.net/weixin_44259720/article/details/127075628
版权归原作者 Java Punk 所有, 如有侵权,请联系我们删除。
版权归原作者 Java Punk 所有, 如有侵权,请联系我们删除。