
这节,我们重点就来说一个事情——进程地址空间。(这次比较短,连个目录都没有哈哈~~)
我们在讲C语言的时候,给大家画过这样的所谓的空间布局图
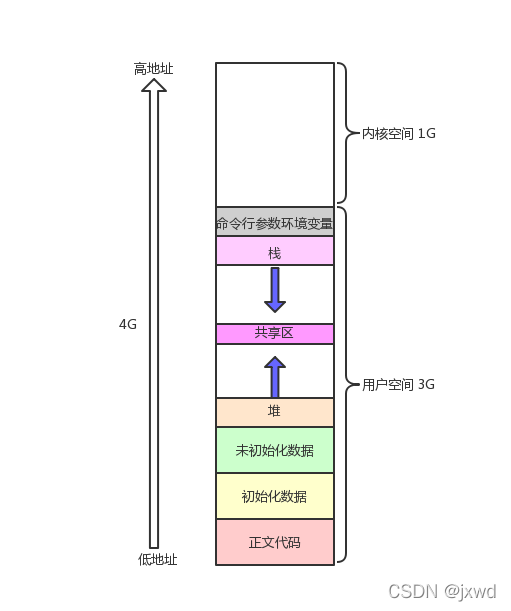
什么栈区内存是有高地址向低地址增长,堆区是由低地址向高地址增长;
由于当时我们需要更好地理解malloc、更好地理解函数的开辟方式, 我们给大家画出了这么个模型。
可是我们并不真正理解它。
今天,我们来详细地探讨一下它。
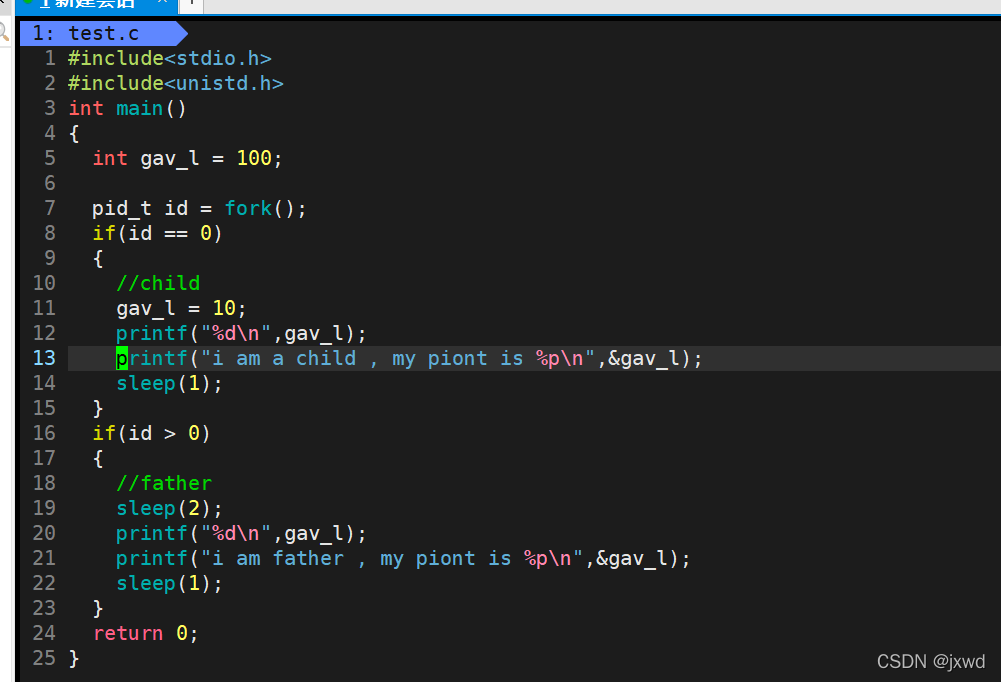
我们先通过一个具体的例子来感受一下:
1 #include<stdio.h>
2 #include<unistd.h>
3 int main()
4 {
5 int gav_l = 100;
6
7 pid_t id = fork();
8 if(id == 0)
9 {
10 //child
11 gav_l = 10;
12 printf("%d\n",gav_l);
13 printf("i am a child , my piont is %p\n",&gav_l);
14 sleep(1);
15 }
16 if(id > 0)
17 {
18 //father
19 sleep(2);
20 printf("%d\n",gav_l);
21 printf("i am father , my piont is %p\n",&gav_l);
22 sleep(1);
23 }
24 return 0;
25 }
这么一段代码,我们先让父进程sleep一下,就是说让子进程先跑。
我们来看运行结果

发现了什么?父进程和子进程的gav_l的值不一样,但是它们俩的地址是一样的!!!
用脚想:如果这里的地址是物理地址,就是说是真正硬件存储器上的地址,那我拿到了一个地址,它对应的值到底是10,还是20?
所以,我们得出了一个结论:这里的地址不是物理地址,而是虚拟地址。
我们在用C/C++语言所看到的地址,全部都是虚拟地址!物理地址,用户一概看不到,由OS统一管理
OS必须负责将 虚拟地址 转化成 物理地址 。
那怎么理解呢?
这就引出了我们今天的重点——进程地址空间

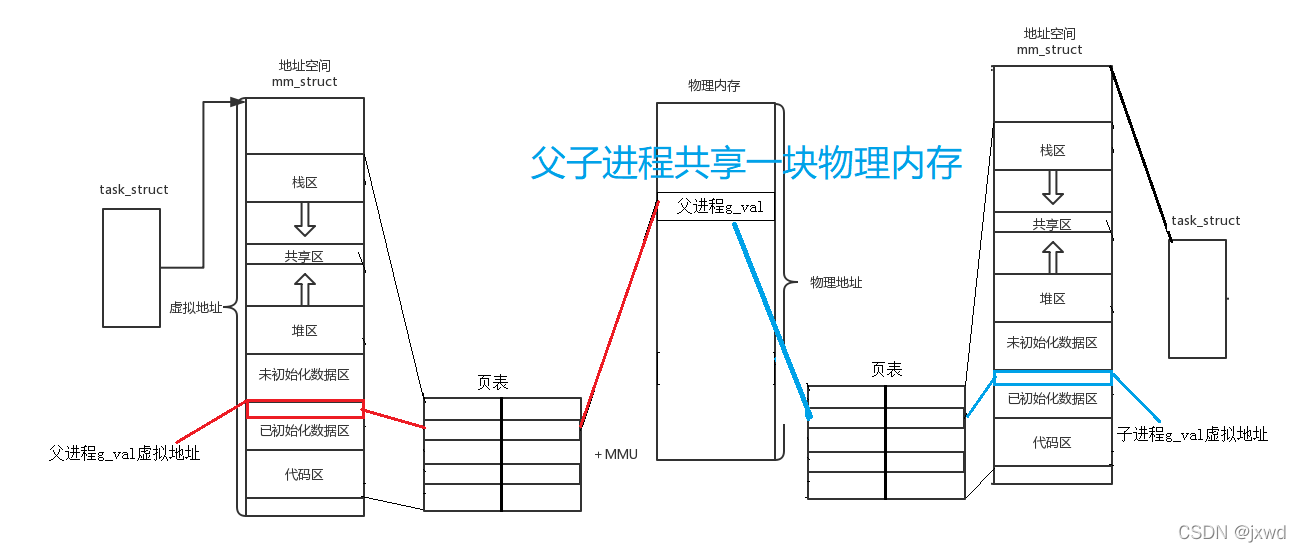
我们结合上面的图来看。
对于一个进程而言,在OS为其创建的时候(即创建task_struct),里面会有一个mm_struct的指针,指向mm_struct这么一个结构体,在这个结构体里面,就有着一块一块区域的划分,比如:
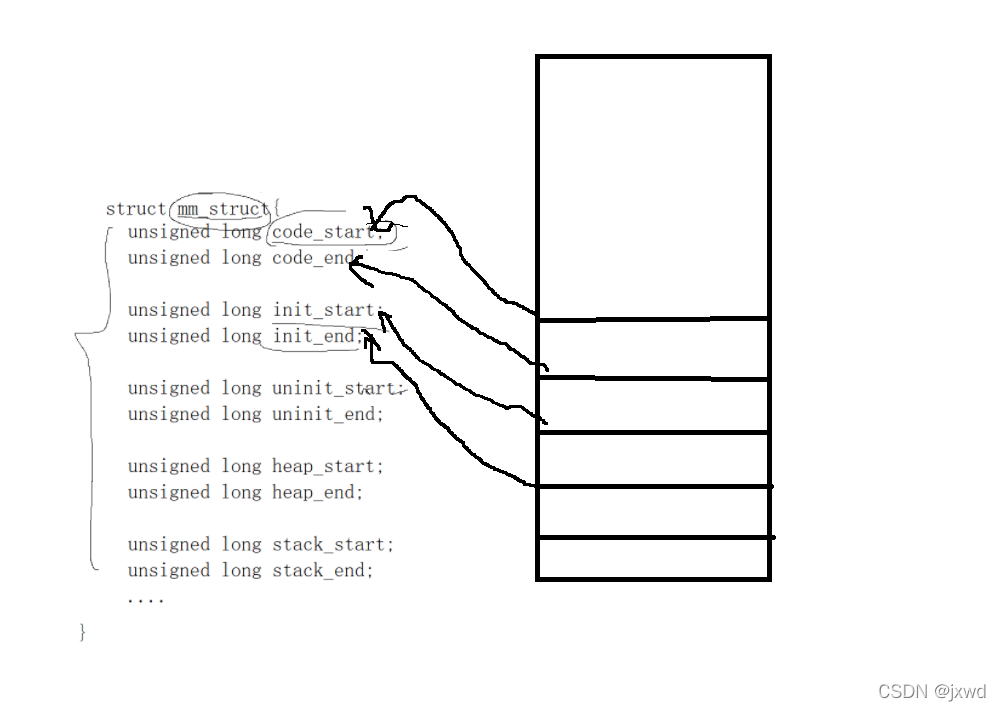
意思就是说,其人为地 创建并规定了 某某空间从哪到哪,从哪到哪。
然后,由OS完成从虚拟内存向物理内存的映射,这项工作通过页表完成:
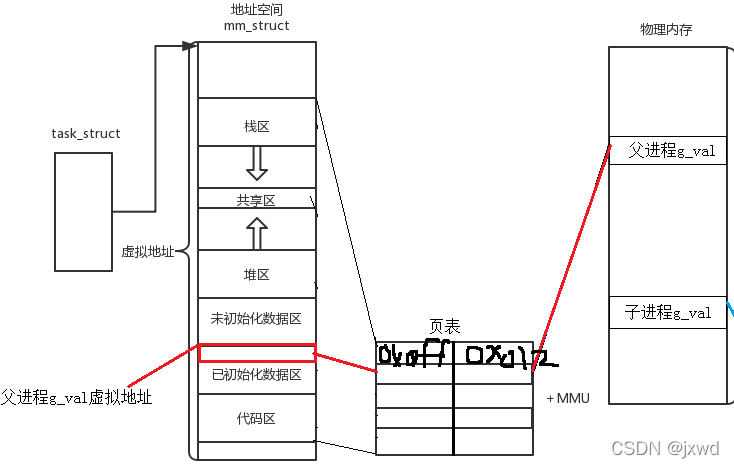
对于页表,举个例子,结合上图:
比如说,在mm_struct里,其是一个地址,那么其通过某种映射关系,映射到物理内中。
然后,页表将物理地址和虚拟地址存储并匹配起来,这样,日后就可以通过虚拟地址找到物理内存中的地址,进而找到其存储的值。
当然,这里只是做一个举例,关于页表,实际上存储的东西远远不止有这些。比如还有像读写信息啦等等。
我们现在就能更好的理解进程了。一个进程,其包含了很多,我们现在可以这样认为:
一个进程是包含了 一堆数据结构以及代码和数据。
在创建新的进程时,
其会依照父进程为模板,在OS为其分配PCB等数据结构的同时,会将父进程的代码和数据拷贝一份到子进程中。
由于代码都只是可读了,而数据是可读可写的,
那么对于父子进程来说,就存在了这样的关系:它们的代码是共享的,而数据是各自私有的。而为了节省内存,在拷贝过后,父子进程的数据实际上也是由同一块物理内存存储的。
就是说,当其未修改的时候,
是像这样的:
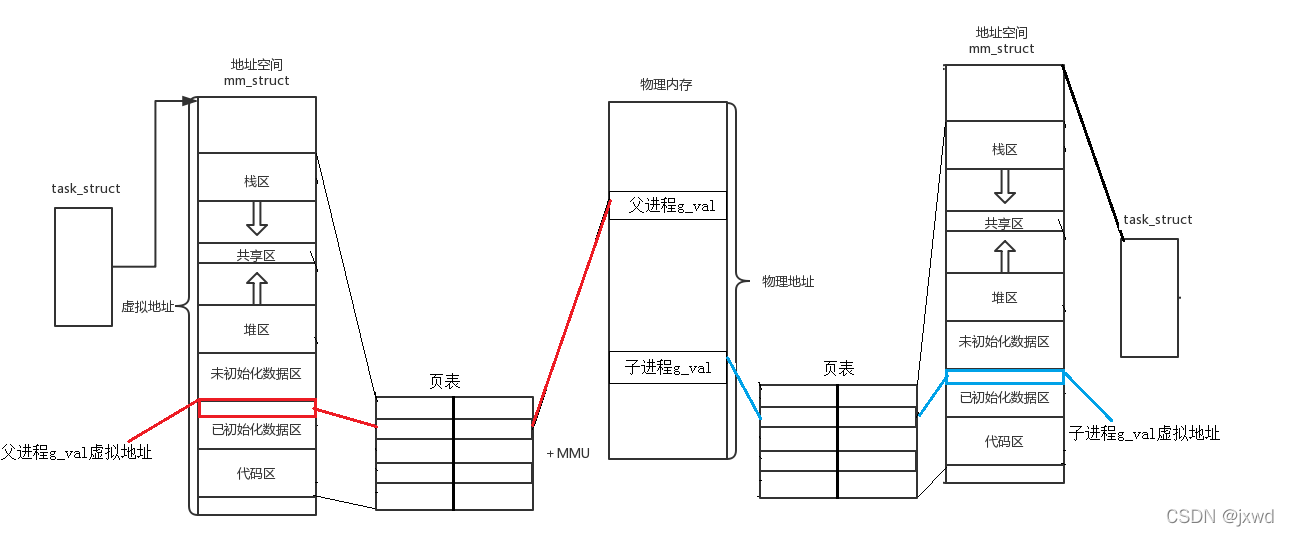
那如果数据被修改了呢?就像我们上面说的代码的那个例子一样?
那我们就需要再来说说写时拷贝。
写时拷贝:****顾名思义,在写的时候进行拷贝。意思就是,在拷贝后,如果对父子进程的数据进行修改,那么OS就会帮我们在物理内存中拷贝一份相同大的数据空间(就基本是你写多少拷贝多少),然后在新的空间中去写入,再将页表中的对应的映射地址修改掉,指向新的地址即可。
就像我们刚刚的那张图这样:
那么,为什么要有这样的存在呢?
第一:可以保护内存。对物理内存的访问,由OS去完成,不让用户去瞎搞,这样一定程度上是对内存进行了保护。
第二:给所有的进程地址空间都提供一致的地址,并且提供可以连续访问的地址。保证进程的独立性。
试想,如果多个进程同时跑,没有虚拟内存,那出现这样的情况怎么办?
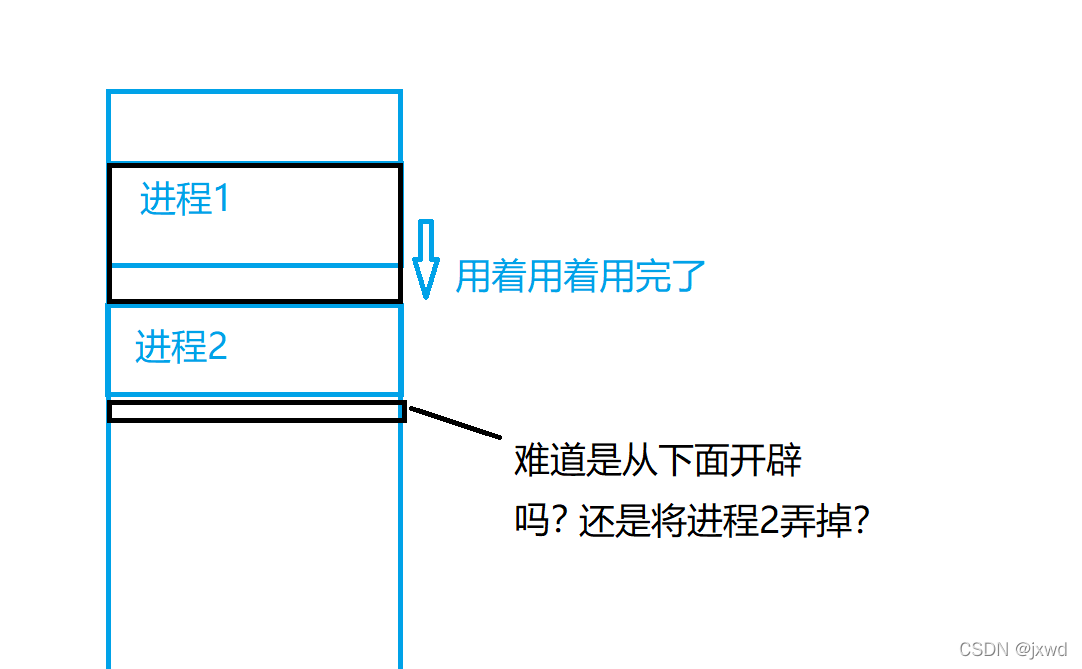
并且这样也会使得用户在用每个进程的时候,从用户的角度来说,由于相同的元素,地址却不一样,会很难受。这样进程的独立性也就无法保证了。
好了,本节内容到此结束,记得加关注呦😙
版权归原作者 jxwd 所有, 如有侵权,请联系我们删除。