
一、伪分布式搭建
1.配置网络
vi /etc/sysconfig/network-scripts/ifcfg-ens33
更改
BOOTPROTO=static
ONBOOT=yes
添加
IPADDR=192.168.116.200
NETMASK=255.255.255.0
GATEWAY=192.168.116.2
DNS1=114.114.114.114
保存 然后:wq退出
输入
service network restart
在ip addr查看是否成功 再ping www.baidu.com ctrl+c结束
2.把包拖入opt里面然后解压
cd /opt
tar -zxf /opt/jdk-8u221-linux-x64.tar.gz -C /usr/local
tar -zxf hadoop-3.2.4.tar.gz -C /usr/local/
3.配置环境变量
vi /etc/profile
export JAVA_HOME=/usr/local/jdk1.8.0_221
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/hadoop-3.2.4
export PATH=$PATH:$HADOOP_HOME/bin
使更改立即生效 source /etc/profile
4.生成密钥
ssh-keygen
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
测试是否免密成功 ssh localhost
退出当前远程登录 logout
5.关闭防火墙
systemctl stop firewalld
开机不启动防火墙
systemctl disable firewalld
6. 配置dfs.sh文件
cd /usr/local/hadoop-3.2.4/etc/hadoop/
vi hadoop-env.sh
在文件开头添加
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
export JAVA_HOME=/usr/local/jdk1.8.0_221
vi core-site.xml
<configuration><property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
vi hdfs-site.xml
<configuration><property>
<name>dfs.replication</name>
<value>1</value>
</property>
7.配置****mapred-site.xml
vi mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property> </configuration>vi yarn-site.xml
<configuration> <property><name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> </confiquration>8.格式化hdfs
hdfs namenode -format
9.如果启动失败
rm -rf /tmp/*
再hdfs namenode -format
10.启动集群
cd $HADOOP_HOME
启动hdfs
sbin/start-dfs.sh
sbin/start-yarn.sh
关闭hdfs
sbin/stop-dfs.sh
sbin/stop-yarn.sh
二、全分布式搭建
1.配置网络 vi /etc/sysconfig/network-scripts/ifcfg-ens33
更改
BOOTPROTO=static
ONBOOT=yes
添加
IPADDR=192.168.116.200
NETMASK=255.255.255.0
GATEWAY=192.168.116.2
DNS1=114.114.114.114
保存 然后:wq退出
输入
service network restart
2.把包拖入opt里面然后解压
cd /opt
tar -zxf /opt/jdk-8u221-linux-x64.tar.gz -C /usr/local
tar -zxf hadoop-3.2.4.tar.gz -C /usr/local/
3.配置环境变量
vi /etc/profile
export JAVA_HOME=/usr/local/jdk1.8.0_221
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/hadoop-3.2.4
export PATH=$PATH:$HADOOP_HOME/bin
使更改立即生效
source /etc/profile
4. 配置dfs.sh文件
cd /usr/local/hadoop-3.2.4/etc/hadoop/
vi hadoop-env.sh
在文件开头添加
HDFS_NAMENODE_USER=root
HDFS_DATANODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
export JAVA_HOME=/usr/local/jdk1.8.0_221
vi core-site.xml
<configuration><property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
vi hdfs-site.xml
<configuration><property>
<name>dfs.replication</name>
<value>1</value>
</property>
5.配置****mapred-site.xml
vi mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property> </configuration>vi yarn-site.xml
<configuration> <property><name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> </confiquration>6.修改hosts映射
**vi /etc/hosts**
添加如下内容(ip和主机名根据自己实际情况而改变)
**192.168.136.200 master****192.168.136.201 slave1****192.168.136.202 slave2**
**7.添加主机名字**
切换到 cd /usr/local/hadoop-3.2.4/etc/hadoop/
vi workers
*添加***master **
**slave1 **
slave2
8.克隆两台虚拟机slave1 slave2
9.修改slave1、slave2主机名
** **hostnamectl set-hostname slave1
bash #重置
** **hostnamectl set-hostname slave2
bash #重置
10.修改两台主机的ip
vi /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR=192.168.136.201/202
NETMASK=255.255.255.0
GATEWAY=192.168.136.2
DNS1=114.114.114.114
然后再service network restart
11.master与slave1、slave2之间互相免密
ssh-keygen
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh-copy-id -i root@slave1 (slave2)
同时在salve1、slave2上生成秘钥,发送给自己,然后再发送给master
ssh-keygen
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh-copy-id -i root@master
输入ssh localhost测试是否对自己免密远程登录
输入logout退出当前远程登录
12.将所有文件发送到****slave1、slave2
scp /etc/profile slave1:/etc/profile (slave2)
**#请到slave1、slave2上输入source /etc/profile**使更改生效
#在master上操作
#jdk
scp -r /usr/local/jdk1.8.0_221 slave1:/usr/local/jdk1.8.0_221 (slave2)
#hadoop
scp -r /usr/local/hadoop-3.2.4/ slave1:/usr/local/hadoop-3.2.4/ (slave2)
**#到slave1、slave2上输入source /etc/profile**使更改生效
13.关闭防火墙
systemctl stop firewalld #关闭防火墙
systemctl disable firewalld #开机不启动防火墙
systemctl status firewalld #查看防火墙状态
14.格式化hdfs
hdfs namenode -format
如果启动失败
rm -rf /tmp/*
再hdfs namenode -format
15.启动集群
cd $HADOOP_HOME
启动hdfs
sbin/start-dfs.sh
sbin/start-yarn.sh
关闭hdfs
sbin/stop-dfs.sh
sbin/stop-yarn.sh
三、spark搭建(伪分布式)
1.首先要启动****Hadoop
cd $HADOOP_HOME
sbin/start-dfs.sh
sbin/tart-yarn.sh
2.把文件拖到opt****里面然后解压
tar -zxf /opt/spark-3.2.4-bin-hadoop3.tar -C /usr/local
3.配置环境变量
vi /etc/profile
export SPARK_HOME=/usr/local/spark-3.2.4-bin-hadoop3
export PATH=$PATH:$SPARK_HOME/bin
4.然后生成文件
source /etc/profile
5.计算pi
cd $SPARK_HOME
*spark-submit *
**--class org.apache.spark.examples.SparkPi **
$SPARK_HOME/examples/jars/spark-examples_2.12-3.3.2.jar 10
6.进入spark****配置文件目录
cd $SPARK_HOME/conf
**#复制spark**配置文件
cp spark-env.sh.template spark-env.sh
vi spark-env.sh
#文末添加以下内容
export JAVA_HOME=/usr/local/jdk1.8.0_221
export HADOOP_HOME=/usr/local/hadoop-3.2.4
export HADOOP_CONF_DIP=${HADOOP_HOME}/etc/Hadoop
7.启动spark
cd $SPARK_HOME
sbin/start-all.sh
8080****启动界面
四、hive搭建
1.下载hive
yum -y install wget
cd /opt
wget https://mirrors.aliyun.com/apache/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
先要启动集群(伪分布式就可以了)
集群运行太慢,伪分布式就够了
2.在master上操作
cd $HADOOP_HOME
sbin/start-dfs.sh #启动hdfs集群
**sbin/start-yarn.sh **#启动yarn集群
3.1derby模式配置
#解压tar -zxf /opt/apache-hive-3.1.2-bin.tar.gz -C /usr/local/
#配置环境变量HIVE_HOME
vi /etc/profile
文末添加如下内容
export HIVE_HOME=/usr/local/apache-hive-3.1.2-bin
export PATH=$PATH:$HIVE_HOME/bin
**#source /etc/profile **使修改生效
直接输入hive启动hive,你会发现报错了。怎么办呢?按照下面步骤继续搞。
#替换hive中落后的文件
cp $HADOOP_HOME/share/hadoop/common/lib/guava-27.0-jre.jar $HIVE_HOME/lib/
rm -f $HIVE_HOME/lib/guava-19.0.jar
4.启动hive-要保证hadoop启动hdfs yarn
切换到**/root **目录
初始化****hive .
cd ~** #切换到root**目录
*rm -fr ***** #删除root下的所有文件*,**免得干扰初始化
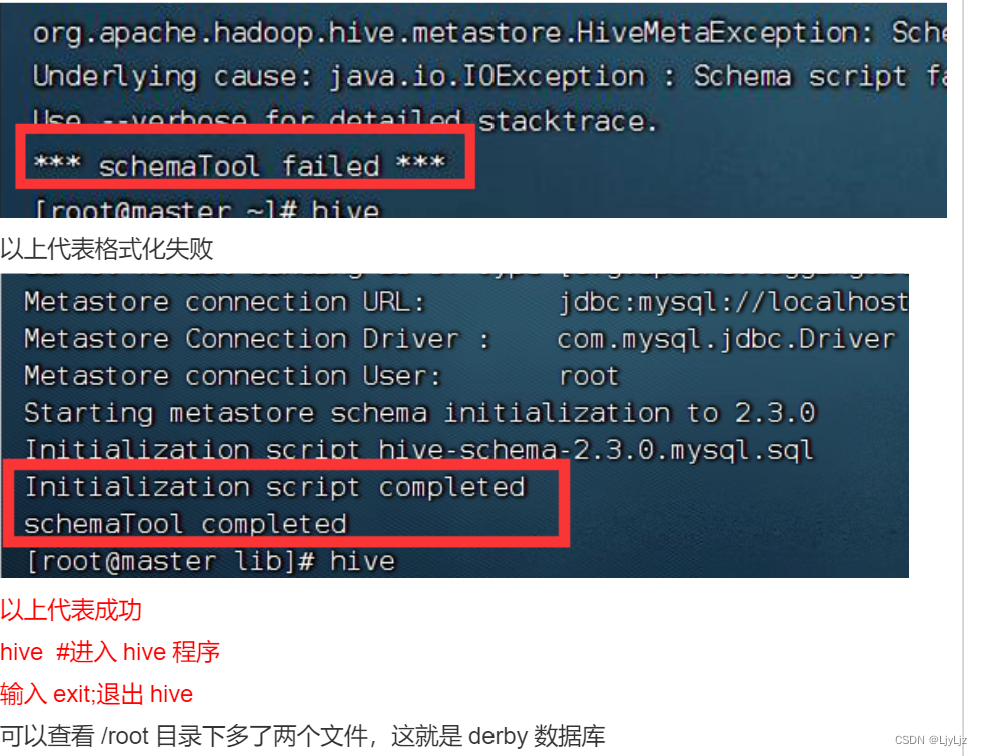
schematool -initSchema -dbType derby
** #初始化derby**数据库
五、mysql搭建
**1.**查看当前mariadb的版本
rpm -qa | grep mariadb
rpm -e mariadb-libs-5.5.68-1.el7.x86_64 --nodeps
2.下载安装包
cd /opt
wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.40-1.el7.x86_64.rpm-bundle.tar
3.解压
tar -xf mysql-5.7.40-1.el7.x86_64.rpm-bundle.tar
4.安装包
rpm -ivh mysql-community-common-5.7.40-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.40-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.40-1.el7.x86_64.rpm
yum install -y net-tools
yum install -y perl
rpm -ivh mysql-community-server-5.7.40-1.el7.x86_64.rpm
5.启动mysql
*systemctl start mysqld如果启动失败,rm -fr Ivar/lib/mysql/ **删除运行痕迹再启动
6.查看临时密码
cat /var/log/mysqld.log | grep password
登录****mysql
mysql -u root -p (输入密码)
7.修改密码
**#**首先需要设置密码的验证强度等级
set global validate_password_policy=LOW;
**#设置为6**位的密码
set global validate_password_length=6;
**#现在可以为mysql**设置简单密码了,只要满足六位的长度即可
ALTER USER 'root'@'localhost' IDENTIFIED BY'123456';
**#开放mysql root**用户外部访问权限,要注意不能把密码设太简单
版权归原作者 LjyLjz 所有, 如有侵权,请联系我们删除。