
文章目录
前言
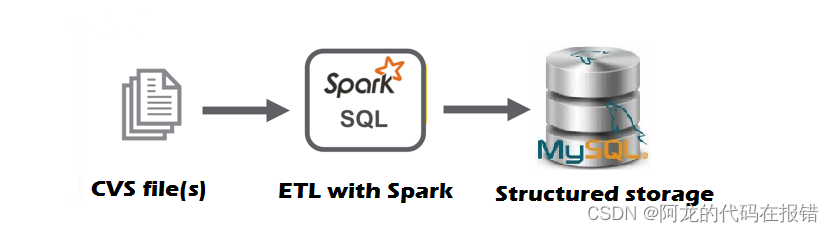
我们用spark对数据进行分析和提取数据后要对得到的数据进行保存接下来的内容是将数据保存到MySQL数据库中
环境的准备是必要的
下载
(本小博主已经为看官大人准备好了下载地址点击下载即可)
下载地址
解压
下载完成后我们对这个压缩包进行解压(当然不解压直接给他拽出来也不犯毛病)
就是下面画红框的(是他是他就是他)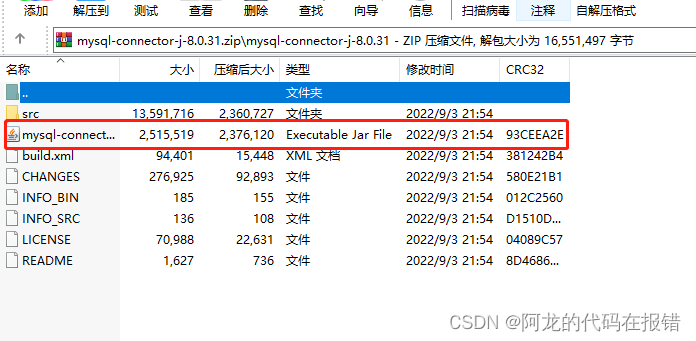
放置文件
给他拽出来之后该给他放到哪里呢?
首先需要放到两个位置:
1、java目录下的
\jre\lib\ext
文件中(至于为什么不要问我,我也不知道他们说的)
2、spark目录下的
jars
文件中(放这个文件夹好像是因为pyspark连接Mysql是通过java实现的)
你要是不知道你的文件目录在哪里的话(那我也没有办法,自己慢慢的找吧,加油!)
当我们的以上的环境都已经就绪的时候,就可以开始让你的手指在键盘上放肆的舞动了,也就是说我们的粮草已将到位了。
代码书写
# 最重要的一步导入库from pyspark.sql import SparkSession
# 初始化spark
spark = SparkSession.builder.appName("Python Spark xinfadi").config("config.option","value").getOrCreate()# 导入我自己爬取的csv文件,当然你们要是没有的话,我是不会给你们的🤭,我很抠哈
ds = spark.read.csv(path='新发地.csv', sep=',', encoding='UTF-8', comment=None, header=True, inferSchema=True)# 这里就是开始很重要的了哦,获取csv文件中我们想要的数据,当然我这个就是一个获取出现次数的,你可以自己随意扩展,但是报错不要找我哦,因为也不会
slave = ds.select(ds.slave).groupby(ds.slave).count().collect()# 这里最最最牛拜了,这是一个转化将列表转化为spark.daraframe的数据,方便保存。
list_aff = spark.createDataFrame(slave, schema=['slave','count'])print(list_aff)# 接下来我们的主角就要登场了,开始配置我们的数据库信息。
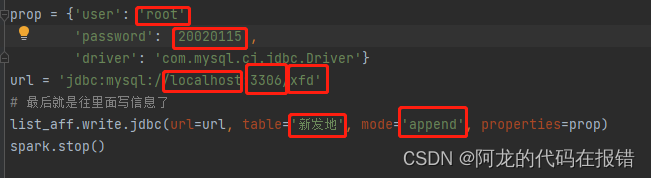
prop ={'user':'root','password':'***********','driver':'com.mysql.cj.jdbc.Driver'}
url ='jdbc:mysql://localhost:3306/xfd'# 最后就是往里面写信息了
list_aff.write.jdbc(url=url, table='新发地', mode='append', properties=prop)
spark.stop()
注意事项
容小的在唠叨两句:看见下面的这张图没,看见没,这个都是重点!!
凡是有红框的都是需要自己根据自己的情况进行更改的你用我的那直接就是一组小报错(最后一个除外哈圈多了,本来想一个一个的给解释解释呢后来犯懒了🤭)
结束语
祝大家代码越敲越顺会的越来越多,报错越来越少,代码一路绿灯~~~///(v)~~~
本文转载自: https://blog.csdn.net/yujinlong2002/article/details/128403101
版权归原作者 阿龙的代码在报错 所有, 如有侵权,请联系我们删除。
版权归原作者 阿龙的代码在报错 所有, 如有侵权,请联系我们删除。