
1. 应用分层
应用分层是一种软件开发设计思想,它将应用程序分成 N 个层次,这 N 个层次分别负责各自的职责,多个层次之间协同提供完整的功能,根据项目的复杂度,可以分成三层,四层或更多层,MVC 就是把整体的程序分成了 Model(模型), View(视图), Controller(控制器)三个层次
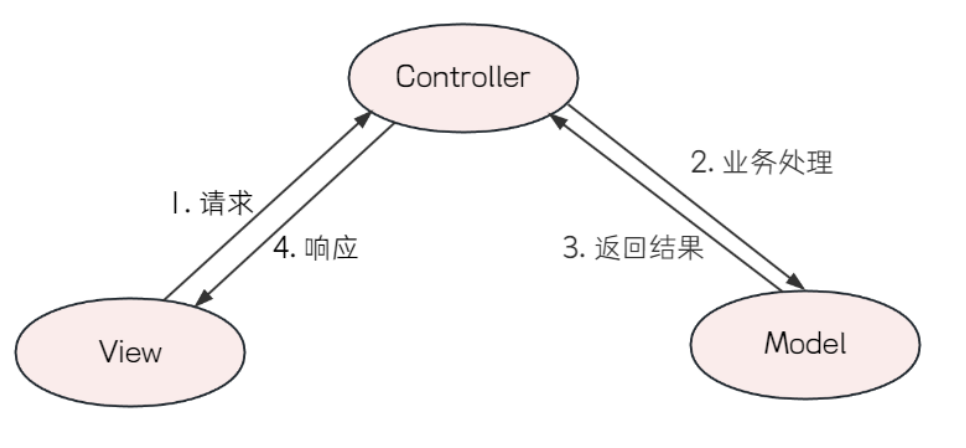
由于后端开发,不需要过多的关注前端,所以又有了一种分层架构:把整体架构分为表现层,业务逻辑层,数据层,又称为“三层架构”
- 表现层:用来展示数据结果和接收用户指令,是最接近用户的一层
- 业务逻辑层:负责处理业务逻辑,包含业务逻辑的具体实现
- 数据层:负责存储和管理与应用程序相关的数据
在 Spring 的实现中可以分为下面三个部分:
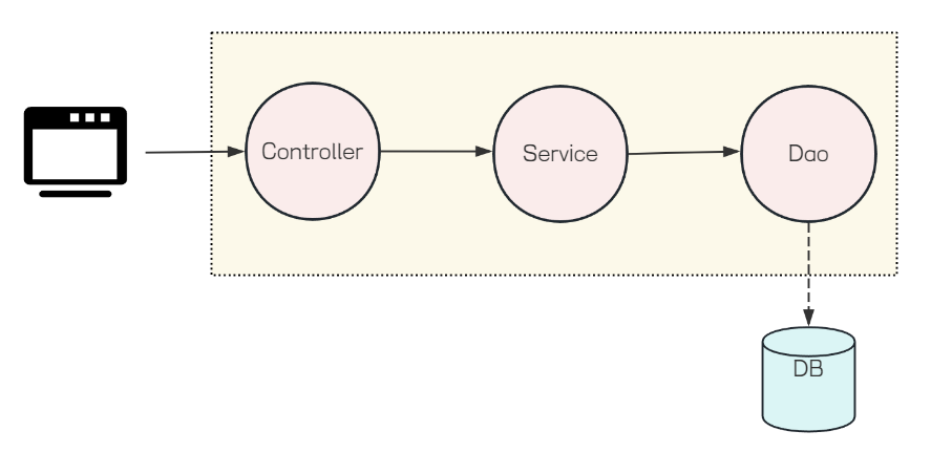
Controller:控制层。接收前端发送的请求,对请求进行处理,并响应数据
Service:业务逻辑层。处理具体的业务逻辑
Dao:数据访问层,也被称为持久层。负责数据访问,操作(增删查改)
2. IoC 的介绍
IoC:也就是控制反转
Spring IoC 是一种设计模式,用于解耦对象之间的依赖关系,在之前创建的项目中对象通常会主动创建和管理自己所依赖的对象,例如,一个
UserService
类可能会在自己的内部使用
new
关键字来创建一个
UserRepository
对象用于数据访问,这样设计看似没有问题,但是可维护性却很低,当有很多类创建了各自的对象时,并且这些对象之间还有依赖关系,例如创建 Car ,Framework,Bottom,Tire 类,从左到右依次存在依赖关系,当其中有一个类的底层代码改变之后,调用链上的代码都需要修改
public class NewCarExample {
public static void main(String[] args) {
Car car = new Car(20);
car.run();
}
//Car类
static class Car {
private Framework framework;
public Car(int size) {
framework = new Framework(size);
System.out.println("Car init....");
}
public void run(){
System.out.println("Car run...");
}
}
//车身类
static class Framework {
private Bottom bottom;
public Framework(int size) {
bottom = new Bottom(size);
System.out.println("Framework init...");
}
}
//底盘类
static class Bottom {
private Tire tire;
public Bottom(int size) {
this.tire = new Tire(size);
System.out.println("Bottom init...");
}
}
//轮胎类
static class Tire {
// 尺⼨
private int size;
public Tire(int size){
this.size = size;
System.out.println("轮胎尺⼨:" + size);
}
}
}
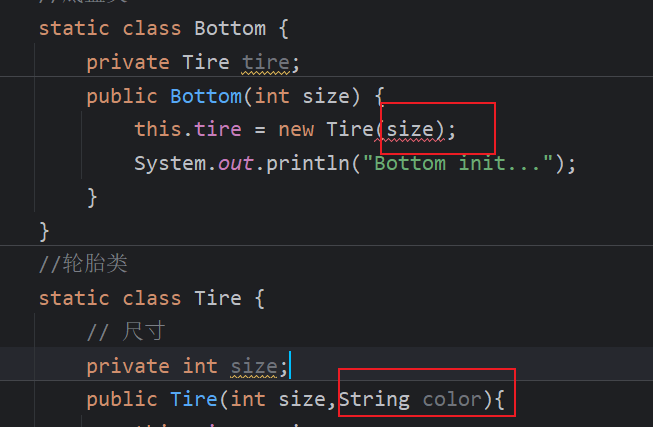
修改轮胎的构造方法之后,底盘也需要修改,当修改底盘之后,上层调用也需要修改
而在 IoC 模式下,对象的创建和管理这些控制权被反转了,不再由对象自身来控制,而是交给外部的容器(IoC 容器)来管理,下面演示一下使用 IoC 的思想来管理对象
public class IocCarExample {
public static void main(String[] args) {
Tire tire = new Tire(20);
Bottom bottom = new Bottom(tire);
Framework framework = new Framework(bottom);
Car car = new Car(framework);
car.run();
}
static class Car {
private Framework framework;
public Car(Framework framework) {
this.framework = framework;
System.out.println("Car init....");
}
public void run() {
System.out.println("Car run...");
}
}
static class Framework {
private Bottom bottom;
public Framework(Bottom bottom) {
this.bottom = bottom;
System.out.println("Framework init...");
}
}
static class Bottom {
private Tire tire;
public Bottom(Tire tire) {
this.tire = tire;
System.out.println("Bottom init...");
}
}
static class Tire {
private int size;
public Tire(int size) {
this.size = size;
System.out.println("轮胎尺⼨:" + size);
}
}
}
通过这样的形式,各个组件的依赖关系就发生了反转,统一对对象进行管理,谁需要这个对象直接传过去一个对象,不需要他自己调用方法进行创建
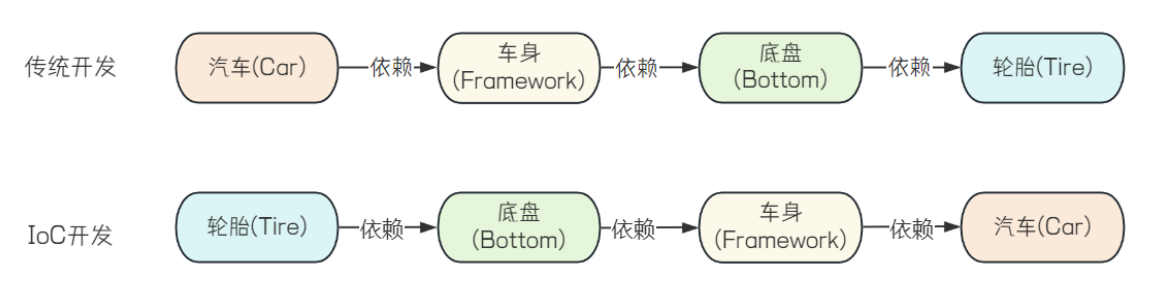
IoC 容器的工作就是把这些对象进行统一管理
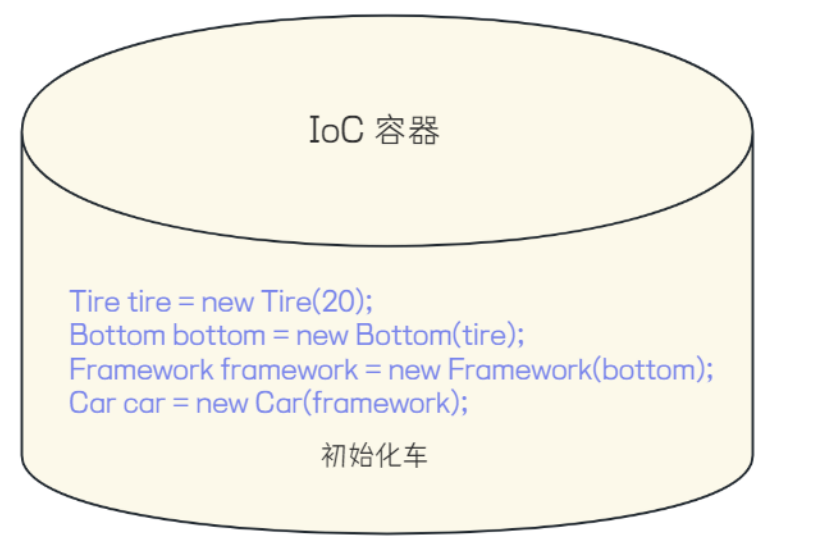
通过这种方式进行资源的统一管理,在创建实例时不需要了解其中的细节,降低了使用资源双方的依赖程度
3. IoC 容器的使用
3.1. bean 的存储
如果想要把一个对象交给 IoC 容器来管理,需要在类上添加一个
@Component
注解,此外还有其它的一些注解可以实现:
- 类注解:
@Controller、@Service、@Repository、@Component、@Configuration. - 方法注解:
@Bean.
@Controller
public class UserController {
public void say(){
System.out.println("UserController");
}
}
@SpringBootApplication
public class SpringIoCApplication {
public static void main(String[] args) {
ApplicationContext context = SpringApplication.run(SpringIoCApplication.class, args);
UserController bean = context.getBean(UserController.class);
bean.say();
}
}
ApplicationContext 可以理解为 Spring 的上下文,这个上下文就是指当前的运行环境和其他功能,也可以看作是一个容器,容器中存储了很多内容,这些内容是当前的运行环境
之后就可以通过拿到的 context 来获取 bean,关于获取 bean 有多种方式:
Object getBean(String var1) throws BeansException;
根据bean名称获取bean
T getBean(String var1, Class var2) throws BeansException;
根据bean名称和类型获取bean
T getBean(Class var1) throws BeansException;
根据类型获取bean
Object getBean(String var1, Object... var2) throws BeansException
按bean名称和构造函数参数动态创建bean,只适⽤于具有原型(prototype)作⽤域的bean
T getBean(Class var1, Object... var2) throws BeansException;
按bean类型和构造函数参数动态创建bean, 只适⽤于具有原型(prototype)作⽤域的 bean
根据类型获取 bean 的话,如果存在多个相同类型的 bean 那么就不能确定具体要获取的是哪个 bean ,同理,如果只是根据名称来获取 bean,如果重名的话也是不能正确获取到 bean 的,所以就有了第三种方式,同时根据类型和名称来获取 bean
上面这三种获取 bean 的方式是比较常用的
关于 IoC 中 bean 的名称转化规则:
如果是 UserController 会被转成 userController,如果是 UController 就还是 UController
UserController bean1 = (UserController) context.getBean("userController");
bean1.say();
由于是根据名称来获取 bean,所以获取到的 bean 不确定是什么类型,会返回一个 Object 类型,需要强转一下
同时指定类型和名称:
UserController bean2 = context.getBean("userController", UserController.class);
bean2.say();
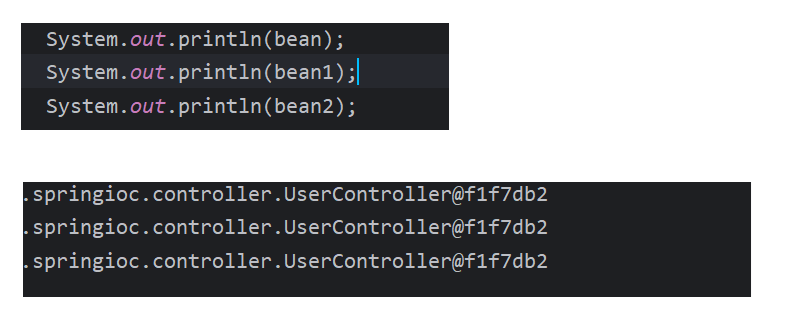
把上面获取的 bean ,打印一下,发现获取的实例的地址是一样的,由此可以知道,通过这种方式获取对象是基于单例模式实现的
接下来演示一下
@Service
注解:
@Service
public class UserService {
public void say(){
System.out.println("UserService");
}
}
UserService service = context.getBean(UserService.class);
service.say();
然后发现和上面一样也是可以运行的,其它的几个类注解也是一样的
那么为什么实现的功能一样,还需要分这么多不同的注解,这个是和之前的应用分层是对应的,通过不同的类注解来了解当前类的用途
@Controller
:控制层,接受请求,对请求进行处理,并进行响应
@Servie
:业务逻辑层,处理具体的业务逻辑
@Repository
:数据访问层, 也称为持久层,负责数据访问操作
@Configuration
:配置层,处理项目中的一些配置信息
3.2. 方法注解
@Bean
上面四个注解都是
@Component
的衍生注解
类注解是添加到某个类上的,但是存在两个问题:
- 如果使用外部包里的类,没办法添加注解
- 同时,由于类注解默认创建的对象是单例对象,如果需要多个对象就需要调整
方法注解
@Bean
就可以解决上述问题
例如,在一个外部包里有一个 UserInfo 类
@Data
@AllArgsConstructor
@NoArgsConstructor
public class UserInfo {
private String name;
private Integer age;
}
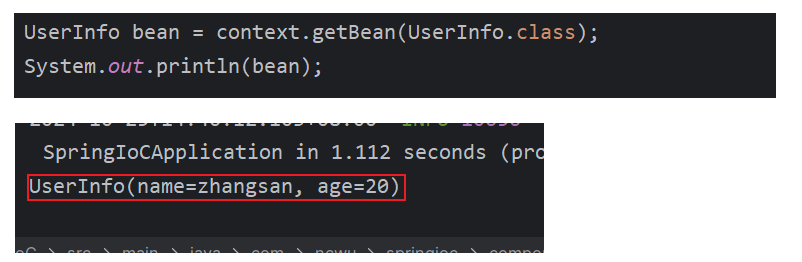
可以通过在获取对象的方法上加上
@Bean
@Component
public class UserInfoComponent {
@Bean
public UserInfo userInfo(){
return new UserInfo("zhangsan",20);
}
}
如果说需要创建对个对象的话:
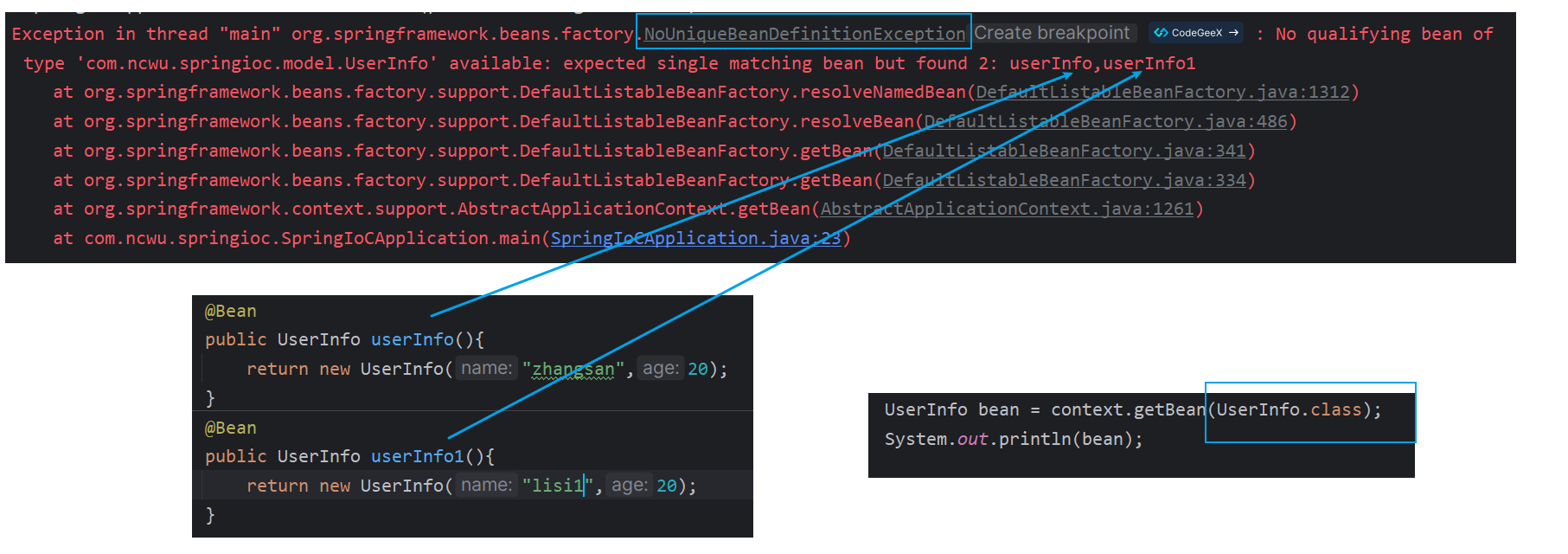
这个问题就是在获取 bean 的时候发现了具有相同类型的 bean,可以直接通过获取 bean 的名称,这里的名称和方法注解下方法名是对应的
UserInfo bean = (UserInfo) context.getBean("userInfo");
System.out.println(bean);
上面的注解,无论是类注解还是方法注解,都可以实现重命名
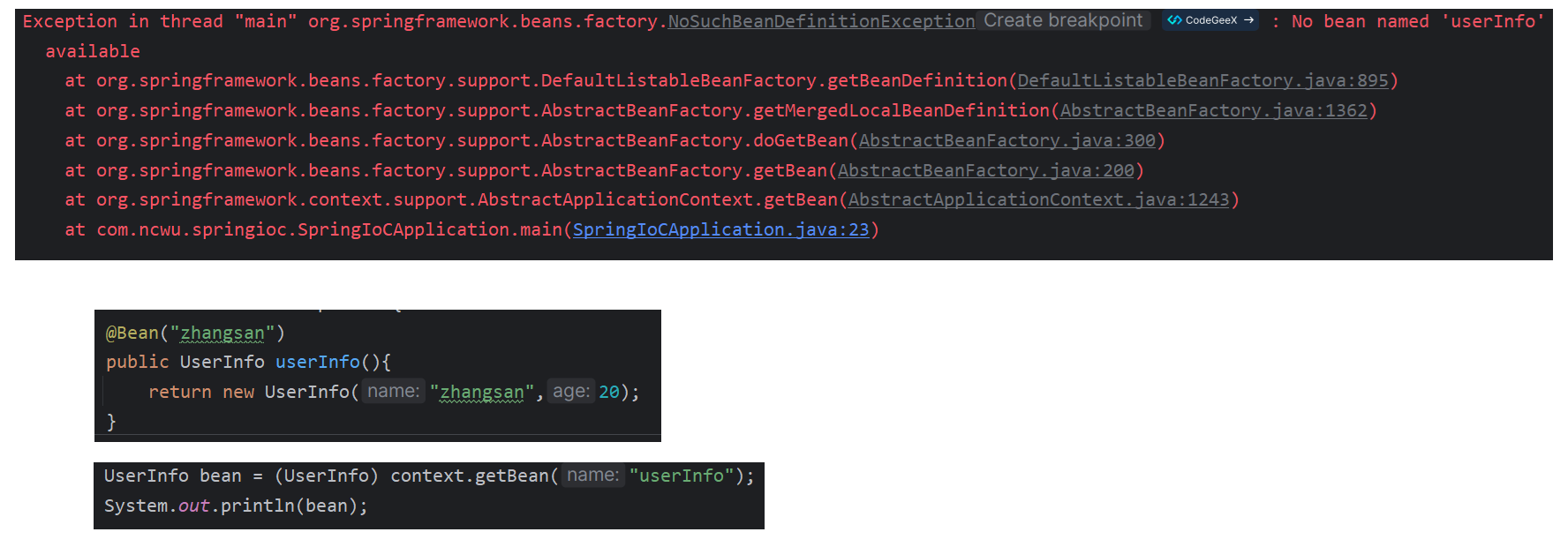
重命名之后就需要使用改之后的名字了
4. 扫描路径
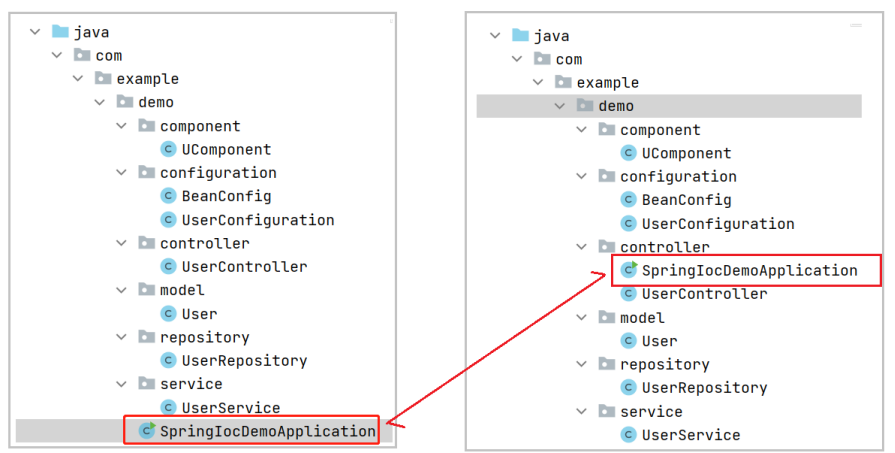

如果说把启动类放到其他目录下再运行就会报错,是因为上面介绍的注解如果想要生效,是需要配置扫描路径的,默认的扫描范围是 Spring Boot 启动类所在的包和它的子包,可以通过
@ComponentScan
来配置扫描路径

在
@ComponentScan
源码中,是支持传入一个数组的,如果想要配置多个扫描路径可以直接传入一个数组
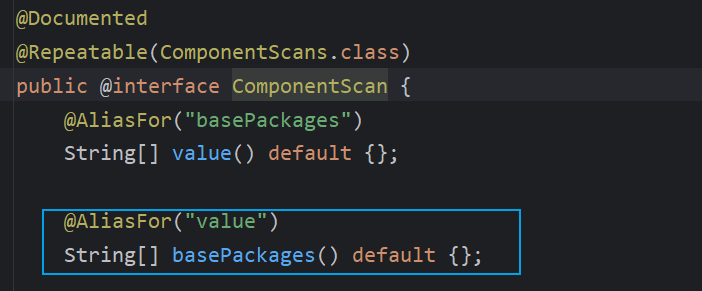
@ComponentScan({"com.example.service","com.example.controller"})
我的主页
版权归原作者 2的n次方_ 所有, 如有侵权,请联系我们删除。