
目录
1. 冯诺伊曼体系结构
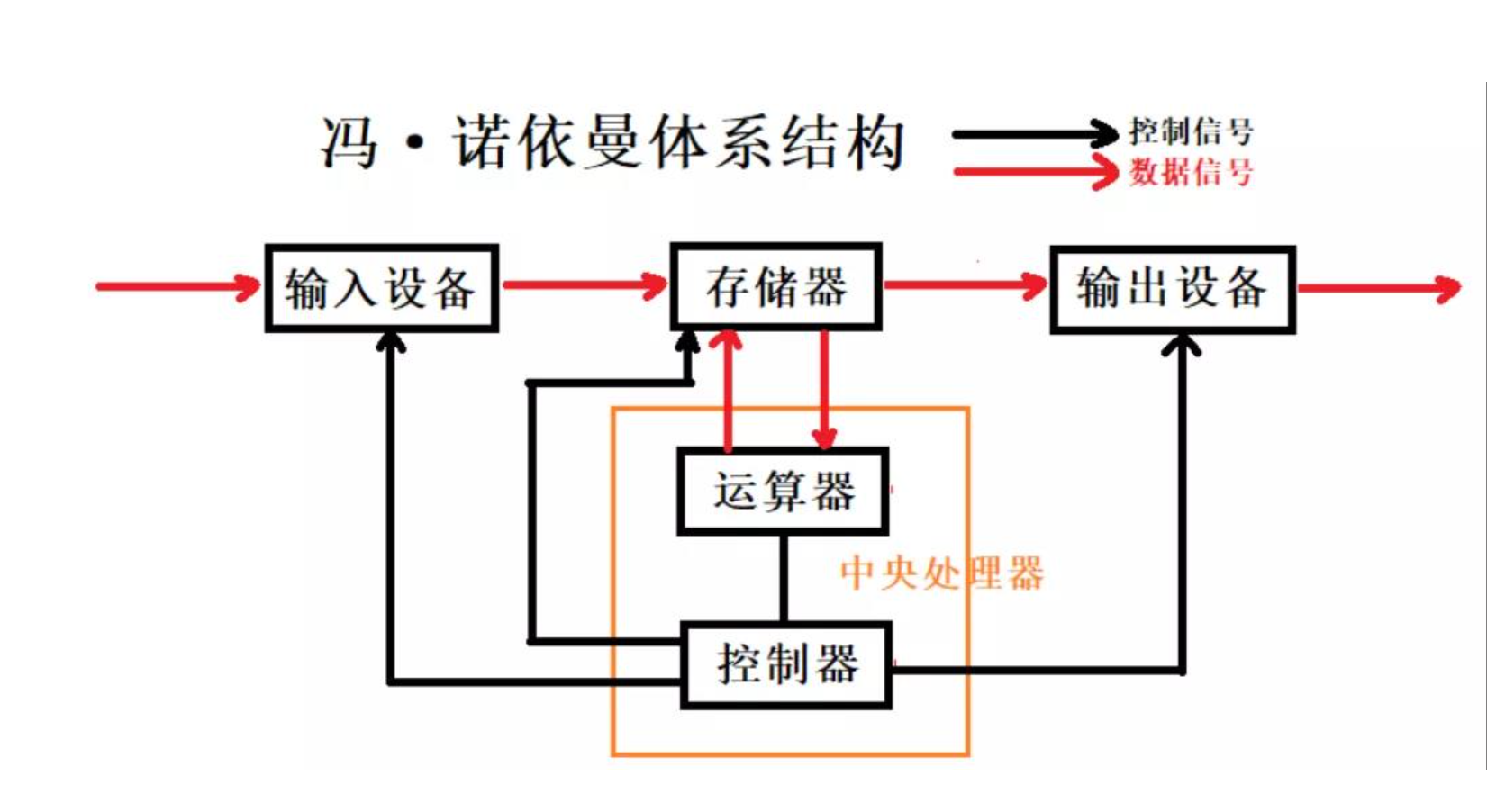
1.1. 概念
- 冯诺伊曼体系结构由五大部分组成,分别为输入设备、输出设备、存储器、运算器和控制器。其内包含的设备既是独立的,又是连接的。运算器和存储器统称为CPU,中央处理器,存储器是内存。
- 设备是独立的: 输入设备:键盘、鼠标、话筒、网卡、磁盘、摄像头等;输出设备:显示器、声卡、显卡、网卡、磁盘、打印机等。
体系结构内的有些设备只能做输入 / 只能做输出 / 既可以做输入,又可以做输出。
- 设备是连接的:通过总线连接,集成在主板上。
连接是手段,目的是进行设备之间数据流动。数据流动的本质是数据会在设备之间进行来回拷贝。数据拷贝的整体效率,是决定着计算机效率的重大指标。
一般会被普遍流行的计算机具有的特性:稳定性和效率都还不错,价格便宜。
1.2. 数据信息流动过程
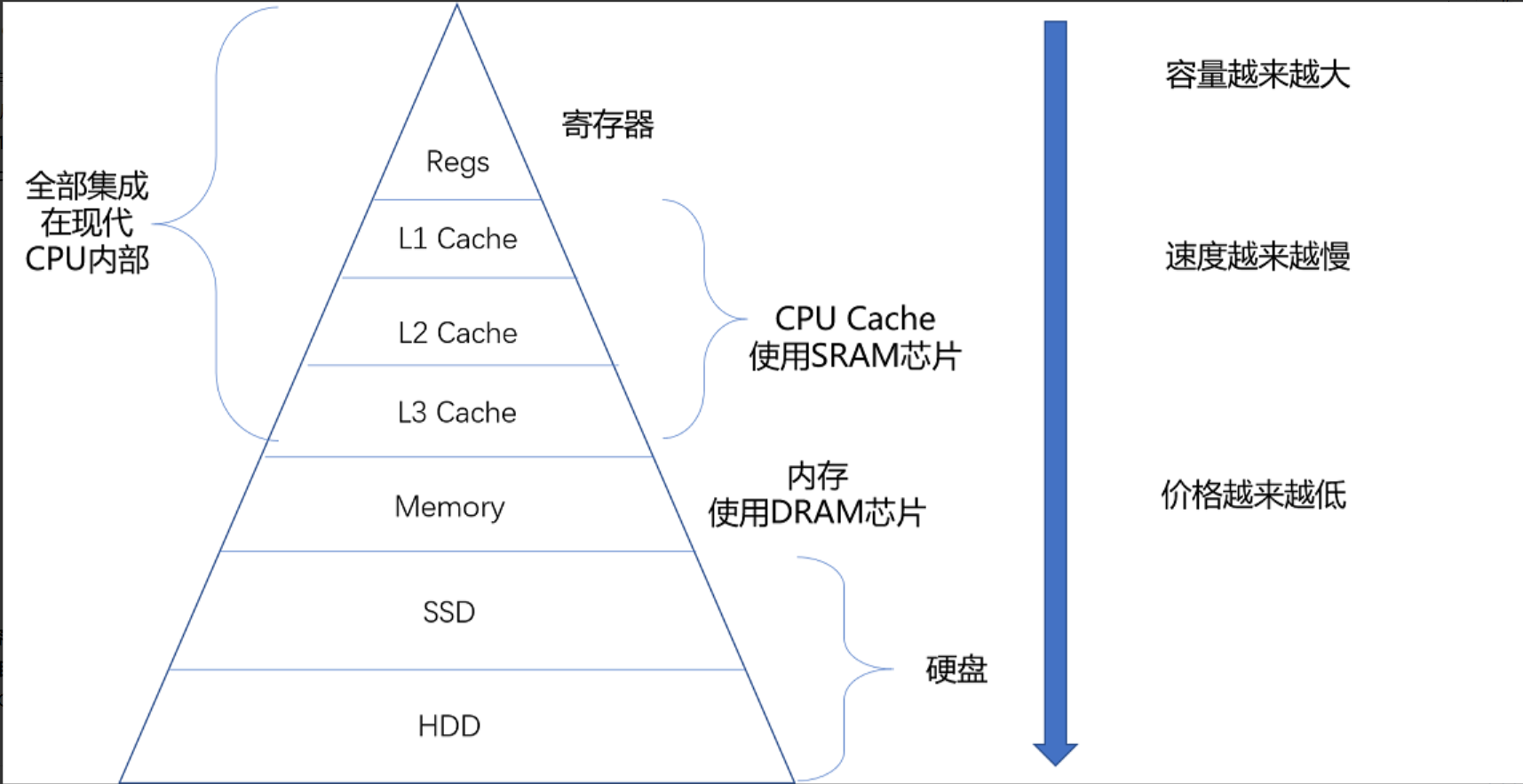
- 计算机的存储金字塔
- 距离CPU越近的存储单元,访问效率越高,单体容量小,造价贵
- 距离CPU越远的存储单元,访问效率越高,单体容量大,造价便宜。
- 为什么体系结构中要存在内存?
如果体系结构中没有内存,根据"木桶原理"(“短板效应”),计算机整体的效率就变成了以外设的访问效率为主。
相较于从外部存储设备中读取数据,从内存中读取数据要快得多,即:内存的访问速度远高于外部存储设备。
体系结构存在内存,计算机整体的效率就变成了以内存的访问效率为主。
内存的引入把效率问题,转化为了软件问题,它可以让我们的计算机效率还不错,且较便宜,我们才能买的起电脑。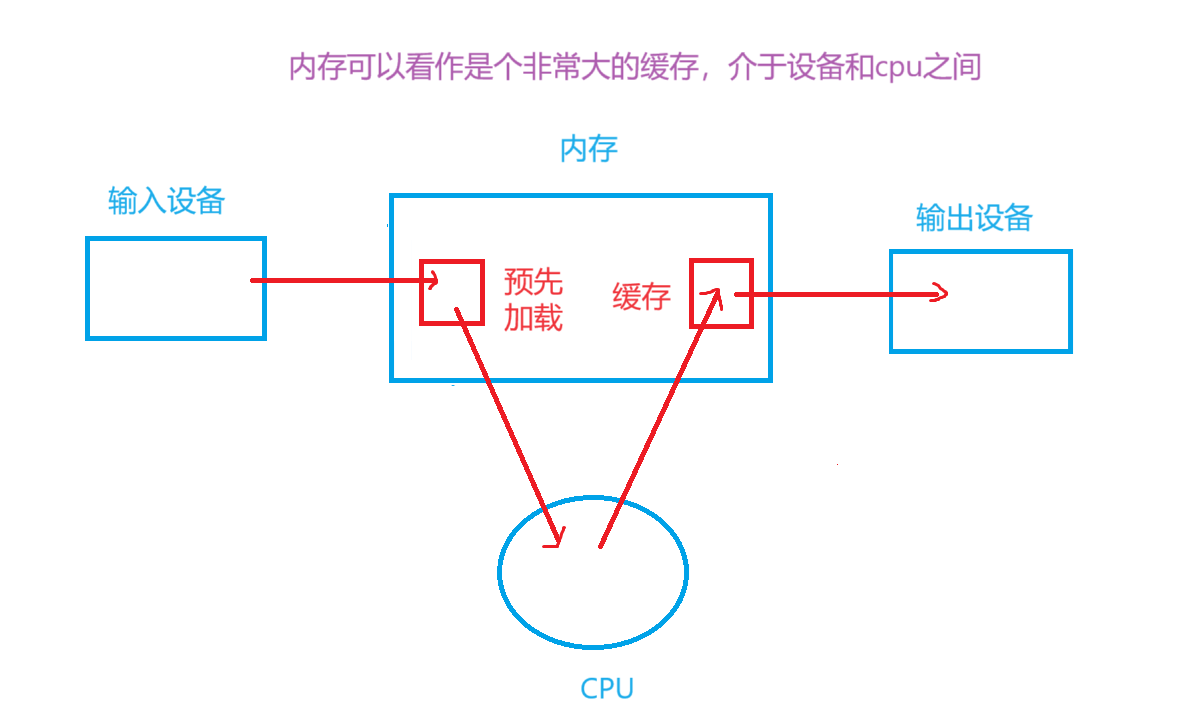 注意:所有设备只能直接和内存打交道 -》 在数据层面上,CPU只能对内存进行读写,不能访问外设(输入、输出设备)、外设也只能将数据写入内存中 或者 从内存中读取数据。
注意:所有设备只能直接和内存打交道 -》 在数据层面上,CPU只能对内存进行读写,不能访问外设(输入、输出设备)、外设也只能将数据写入内存中 或者 从内存中读取数据。
3.数据信息流动的应用场景
a. 程序在运行中,必须将程序加载到内存中。
答 : 因为冯诺依曼体系规定的。程序 ->是个二进制文件 -> 存储在磁盘外设中 -> 只能直接访问内存 -> 最终需要通过CPU来执行 <- 它的指令和数据 <- 程序。
b. 登录上qq开始和某位朋友聊天,数据的流动过程
答:我 : 键盘 -> 内存 -> cpu -> 内存 -> 网卡。网友:网卡 -> 内存 -> cpu -> 内存 -> 显示器。
c. 在qq上发送文件, 数据的流动过程
答:磁盘 -> 内存 -> cpu -> 内存 -> 网卡。
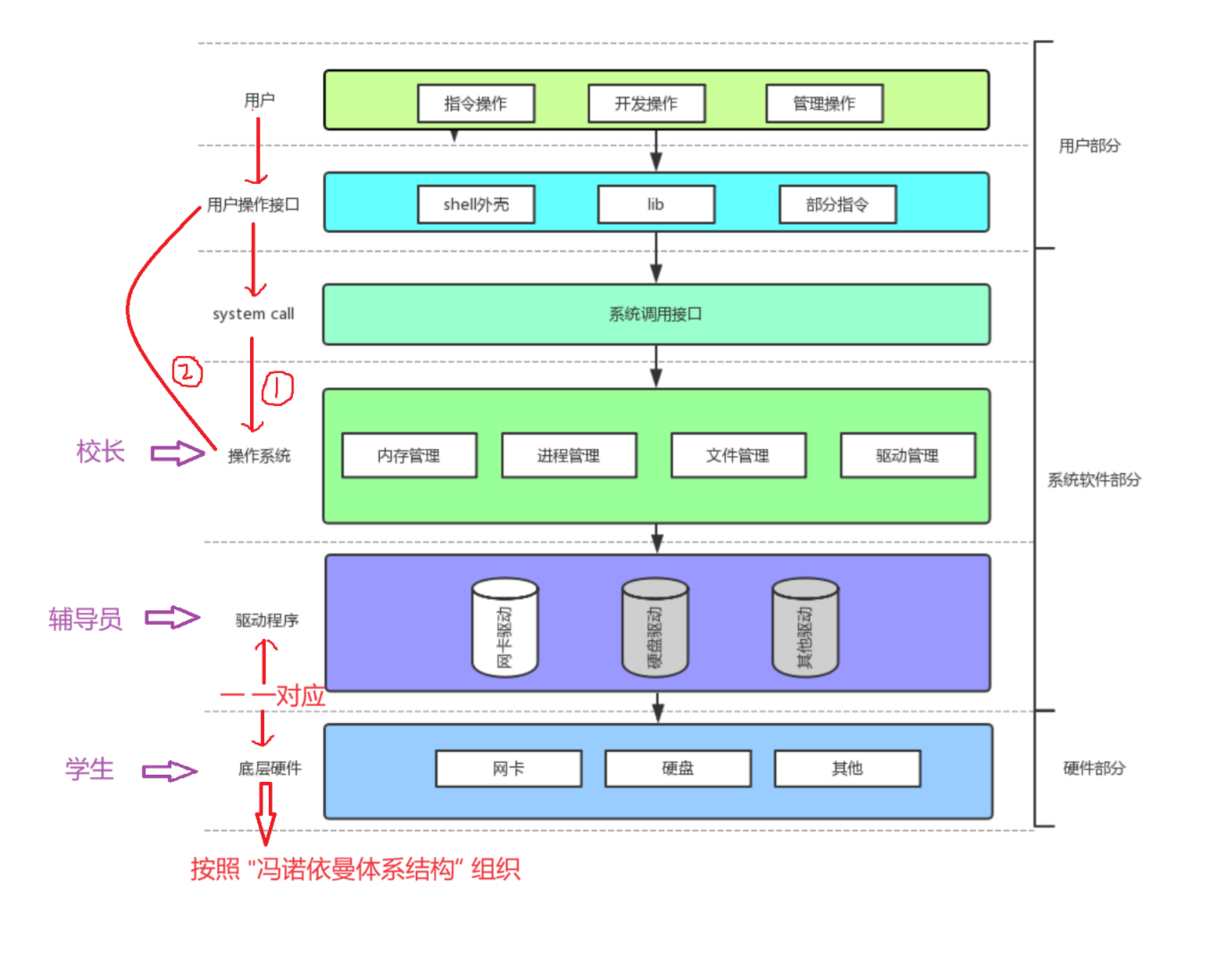
2. 操作系统
2.1. 概念
操作系统概念:操作系统是一个进行软硬件资源管理的软件。它是第一个被加载到计算机的软件。为用户提供数据方面、技术方面的支持。
2.2. 管理
一、例子1:以校园生活为背景,引出计算机中"管理"的概念:
人们在生活和工作中的角色,大致可以被划分以下三类:只做决策的人,等同于管理者,在校园中相当于校长;只做执行的人,等同于被管理者,在校园中相当于学生;既做执行又做决策,在校园中相当于辅导员,保证管理决策落地。
- 管理的本质不是对人做管理,而是对人的属性信息(数据)做管理。
管理者和被管理者无需见面,说明管理一个人的本质不在于见面。eg : 开学到毕业你或许都没和校长见过一面,但你大学四年学业课程,却被他安排的"明明白白"。
- 管理者的核心工作是做决策,根据被管理者的数据来做决策。
管理者和被管理者面都没有见到,那么管理者是如何拿到被管理者的信息的呢? 辅导员 -> 保证管理决策落地。
- 当被管理者非常多时,即:数据量非常大时,管理者如何管理呢?
- 结构体、类用来封装一组类型不同但又相关的若干数据,以及操作这些数据的方法。
因为所有学生在特定场景具有相同的属性信息,如:姓名、年龄、学号、年纪等,所以我们可以定义一个结构体struct student来描述学生的属性信息,创建多个结构体变量,通过将变量放入特定的数据结构(链表)中 ——》 把对学生的管理工作,转为了对链表的增删查改。
eg:找到年龄最小的学生,并把它删除:以学生的年龄作为基值,遍历链表,若查找到了,就在链表中删除这个节点。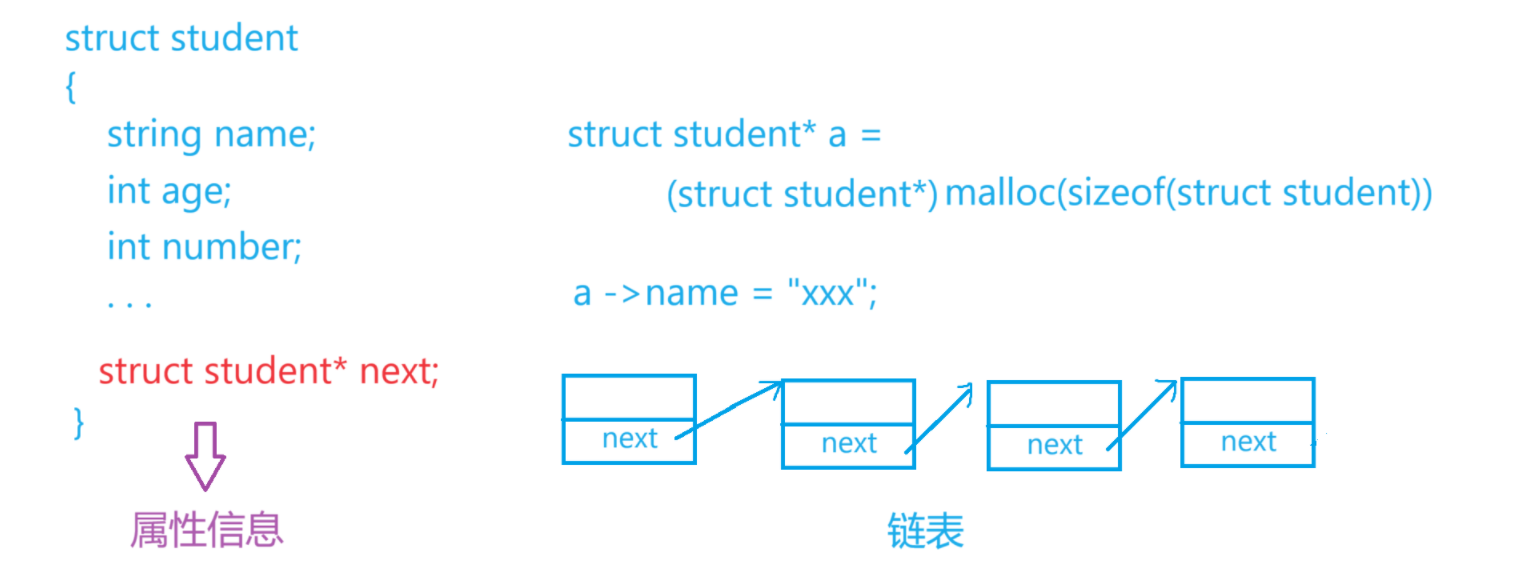 注意:对管理的一个计算机建模的过程 :先描述、再组织。
注意:对管理的一个计算机建模的过程 :先描述、再组织。
- 计算机级别的建模:主要是指将具体问题或现象,转化为计算机能够认识和处理的形式。
二、例子2:面向对象语言
- 描述下历史:先描述的过程:就是面向对象的过程 —— class 、struct ;再组织的过程:数据结构 —— STL,如vector、list、stack、map等。
类中有对象的方法和数据,再把用该类创建的对象放入到容器中。eg:C语言小项目:三子棋、扫雷、通讯录. 定义通讯录,struct Person { string name; int number;} (描述)、struct Contact { int num; struct Person p[1000];} (组织)。
- 预测下未来:以后只要是进行管理,都要做以下两件事:先描述(class、struct)、再组织(STL容器,数据结构) -》将具体问题,进行计算机级别的建模过程,转换为计算机能够认识的问题。
- 数据结构的本质是对数据进行管理。
注意:综上所述:把对数据的管理场景转化为对特定数据结构的增删查改。
2.3. 设计操作系统的目的
- 为什么要有操作系统(为什么要有操作系统的管理)?
答:对下进行软硬件资源管理(手段),对上提供一个良好的运行环境(目的)。
- 为什么要存在系统调用接口?
- a. 安全保护和资源管理。
通过系统调用,操作系统可以确保用户程序不会直接访问或修改内核数据,防止潜在的安全风险。
系统调用接口是用户和内核进行交互的唯一途径,有助于操作系统有效的管理其资源,确保用户程序在受控和安全的环境下访问和使用系统资源。
- b.简化操作。
系统调用为用户程序提供了高级的、易于使用的接口,以访问操作系统提供的各种服务和功能。这使得程序员无需深入了解底层硬件和操作系统的细节,就可以编写出高效且可靠的应用程序。
2.4. 系统调用和库函数概念
一、系统调用
系统调用接口概念:也称为系统调用函数system call,是操作系统提供给用户和内核进行交互的一组接口。因为Linux大部分代码是用C语言写的,system call是用C语言设计出的函数。
eg:当你去银行取钱时,银行会有一个窗口,将你"挡在外面", 你只能通过银行内部人员进行取钱。银行窗口相当于操作系统中系统调用接口。
- 用户不能绕过操作系统直接访问硬件资源,会出现数据损害、资源冲突、系统崩溃等安全隐患。
- 任何人不能直接访问操作系统,必须通过系统调用接口才能访问。例外:在嵌入系统中用户可以直接与内核进行交互。
- 系统调用接口在确保操作系统安全性的情况下,为用户程序提供了对底层硬件访问、系统级别任务的方法。
二、库函数
库函数概念:由编译器或者操作系统预先写好的函数,被存放在"库"中,由用户提供。eg:printf、scanf库函数存放在C标准库中。
- 用户操作接口有库、Shell外壳、部分指令。系统调用接口是系统级别的接口,要求使用者需要对操作系统有一定的了解,然而大多数用户并不了解操作系统 , 所以用户提供了类似于printf和scanf级别的库函数 , 两者都可以让用户完成对硬件资源的使用。
eg:对于不识字的老人家来说,直接使用银行的自助服务系统可能会非常困难,因为他们可能无法理解和操作复杂的界面和流程。在这种情况下,银行会提供一个服务人员来帮助他们完成任务,这个服务人员就相当于用户操作接口。
- printf、scanf的重新理解:printf是向显示器进行打印,scanf是从键盘中读取数据,说明都需要访问硬件设备。因为对硬件设备的访问,必须通过操作系统、而对操作系统的访问,必须通过系统调用接口,所以printf、scanf底层封装了系统调用。
- C标准库具有跨平台性、可移植性。原因之一:C的库函数中调用的system call是由当前操作系统所决定的。eg: Windows下printf函数封装的system call是代码A,,Linux下printf函数封装的system call是代码B,但是C的库函数printf实现时并没有指定是使用代码A还是代码B,具体情况取决于当前操作系统。
- 库函数 vs 系统调用,两者是上下层的关系,库函数在上,由用户(设计者)提供;系统调用在下,由操作系统提供。
3. 进程
3.1. 引言
可执行程序 -> 是二进制文件 -> 存放在磁盘中 -> 外设 -> 需要被加载到内存中。
- 我们可以同时启动多个程序? 可以,但我们一定要将多个可执行程序加载到内存中。
- 操作系统需要管理多个被加载到内存的程序吗? 需要。
- 操作系统如何管理多个被加载到内存的程序呢? 先描述、再组织。
3.2. 概念
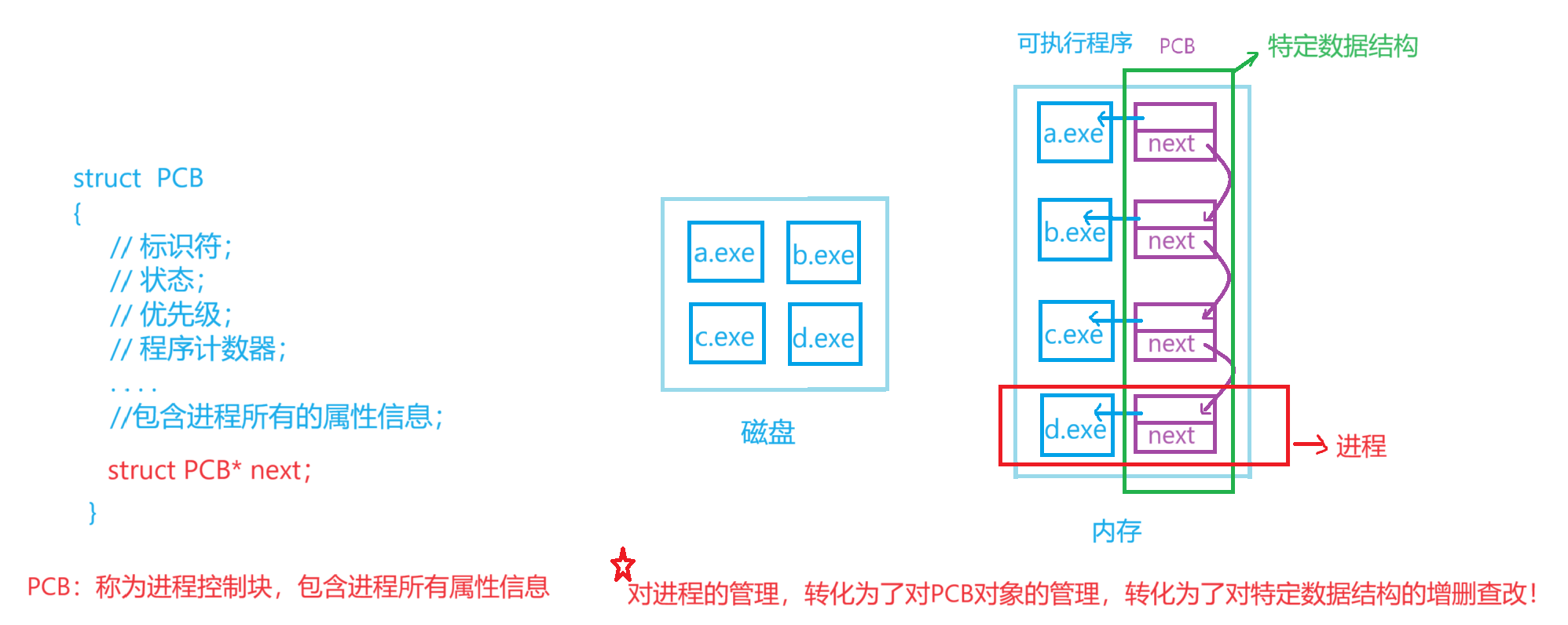
进程 = 内核PCB对象 + 可执行程序 = 内核数据结构 + 可执行程序
- 教材概念:进程是正在运行的程序、被加载到内存的程序、进程可以排队。
- 为什么程序加载到内存,变成进程,我们要给每个进程形成一个PCB对象呢?
- 因为操作系统要对进程进行管理,先描述、再组织,PCB是描述进程所有属性信息。
- 管理的本质:对数据结构的对象进行管理。
对于之前所学习的所有数据结构以及方法,都是对节点的管理工作,而每个节点里面包含数据,都是在模拟操作系统目前的管理工作 ——> 操作系统和数据结构的关联度很大。
注意:未来所有对进程的操作和控制,都只和进程的PCB有关,与进程的可执行程序无关。即:进程的PCB(Node)可以被放入到任何(多个)数据结构中。
eg:CPU的资源是有限的,所以多个进程在运行时需要竞争这些资源,进程的PCB才会被放入到一个队列中准备被CPU调度,这个队列称为"运行队列"。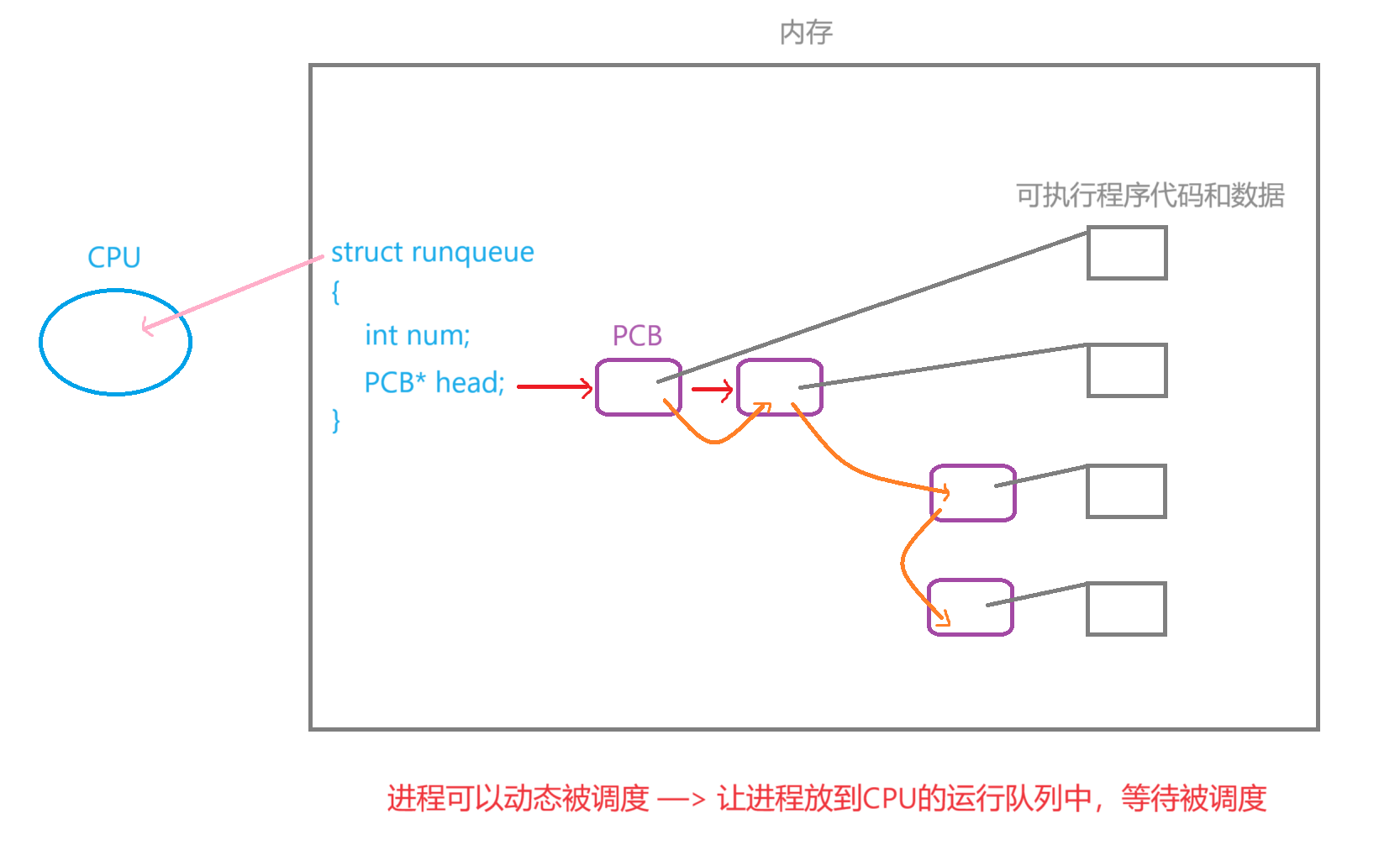
- 💡Tips:几乎所有的独立的指令,都是可执行程序,当它们被运行起来,都要变成进程。
3.3. PCB
- PCB概念:是进程控制块的缩写,它是操作系统为了管理进程所设置的一个数据结构,其中存放着操作系统用于描述进程的所有属性信息,是进程存在的唯一标识。
- PCB是操作系统学科的叫法,Linux下的PCB是task_struct。

- PC指针/eip寄存器:在操作系统中,每个进程都有唯一的程序计数器(PC指针),用于存储当前指令的下一条将要执行的指令的地址。循环、判断、函数跳转的本质是修改PC指针。程序计数器是CPU的一个寄存器,它包含一个地址值,这个地址值指向内存中将要执行的指令序列。
💡Tips:PC指针指向哪个进程的代码,就表示哪个进程正在被CPU调度运行。
3.4. 查看进程
- 在Linux操作系统中,将进程的所有属性信息,以进程的PID为目录名,存放在/proc系统目录下。
ls -l /proc/XXX
- 功能:获取PID为XXX的进程所有信息。
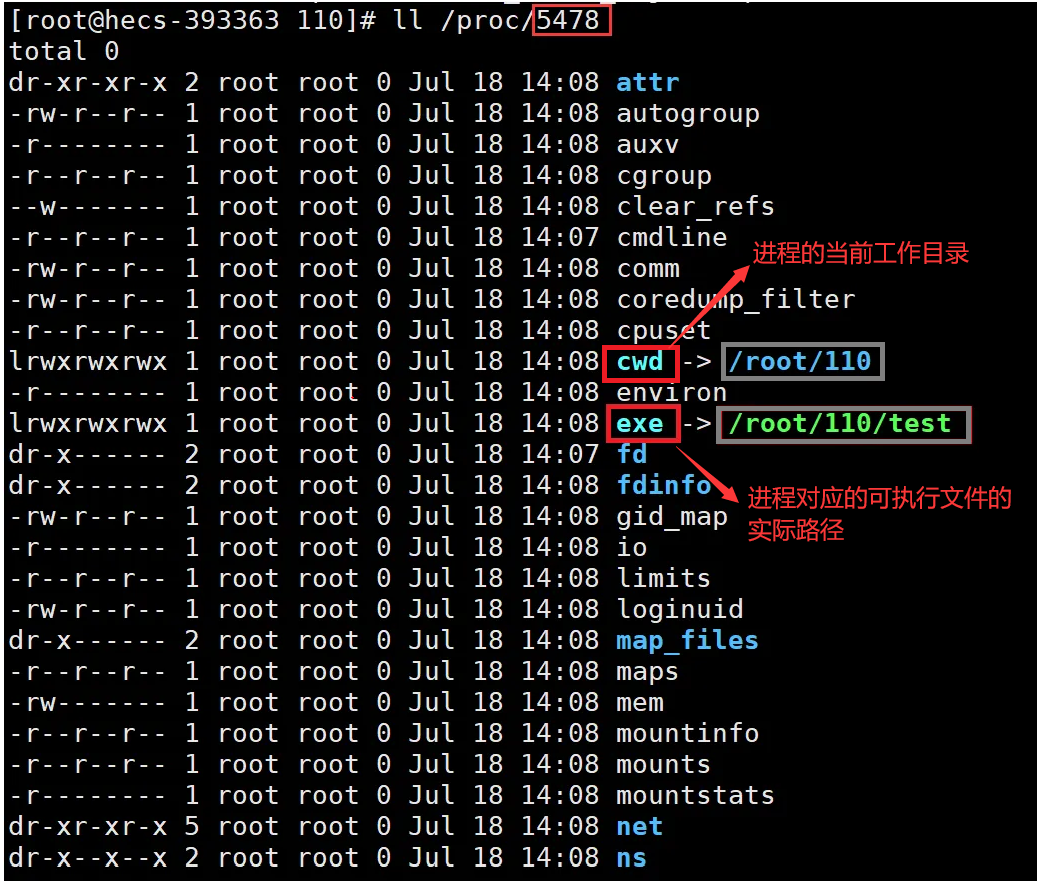
- exe文件:本身不是一个实际存在文件,它是一个符号链接,指向当前正在执行的可执行文件的实际路径。
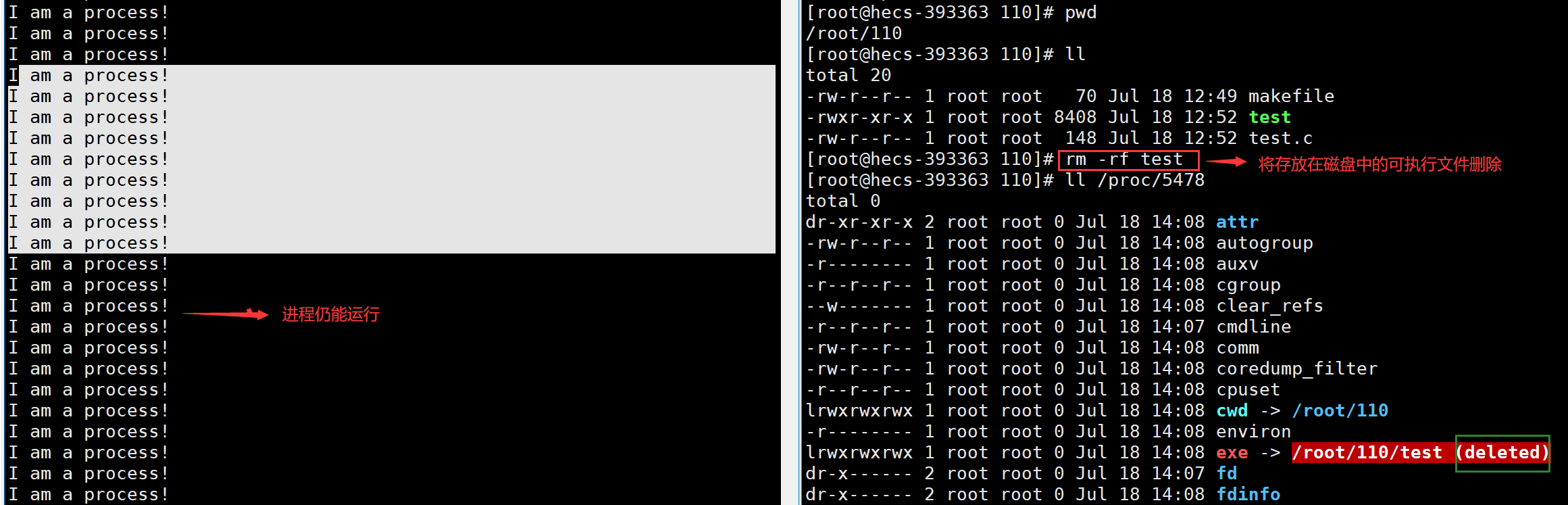
- 问:一个进程一旦启动,我们把它所对应的可执行文件删除了,为什么这个进程仍然可以继续运行呢?
答:一个进程一旦启动,它会在内存中加载其可执行文件的部分或者全部内容,包括代码、数据、资源等。进程开始运行后,它不依赖于磁盘上的可执行文件,而是直接使用内存中的副本,所以删除磁盘上的可执行文件,不会影响进程本次运行,一旦将这个进程退出,这个进程不会再运行了。
💡Tips:运行一个程序,本质是将可执行文件从磁盘拷贝到内存。
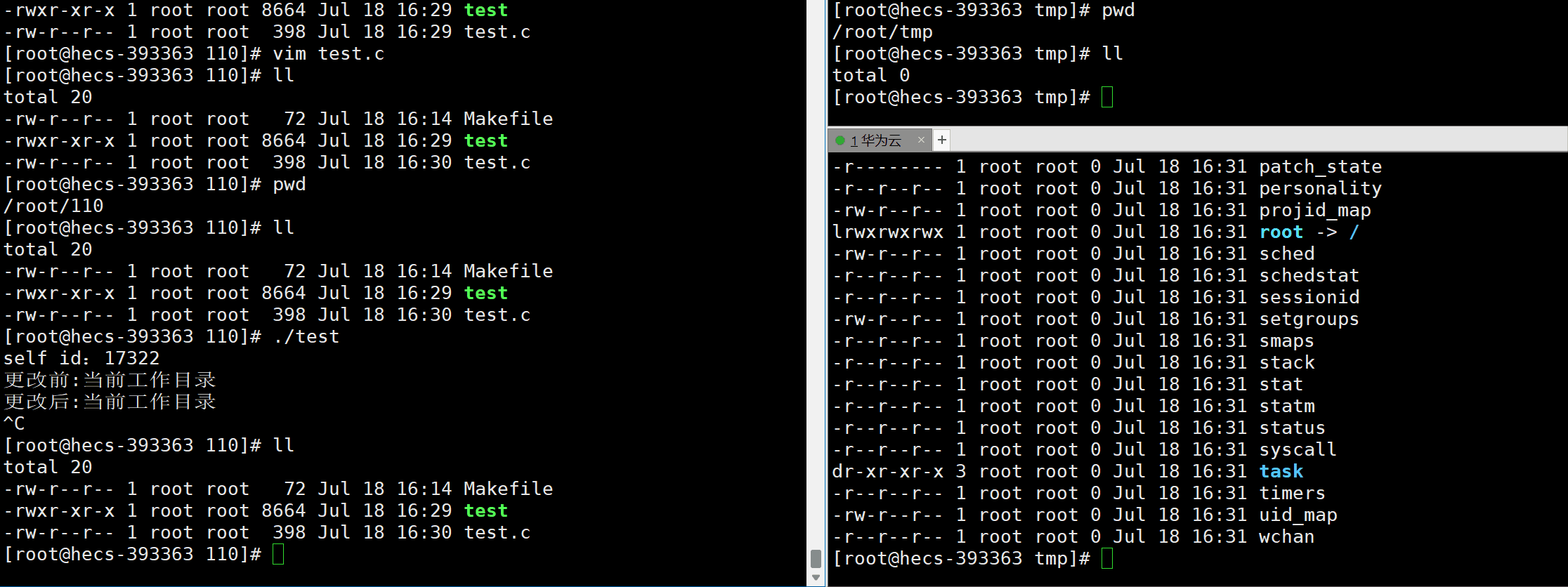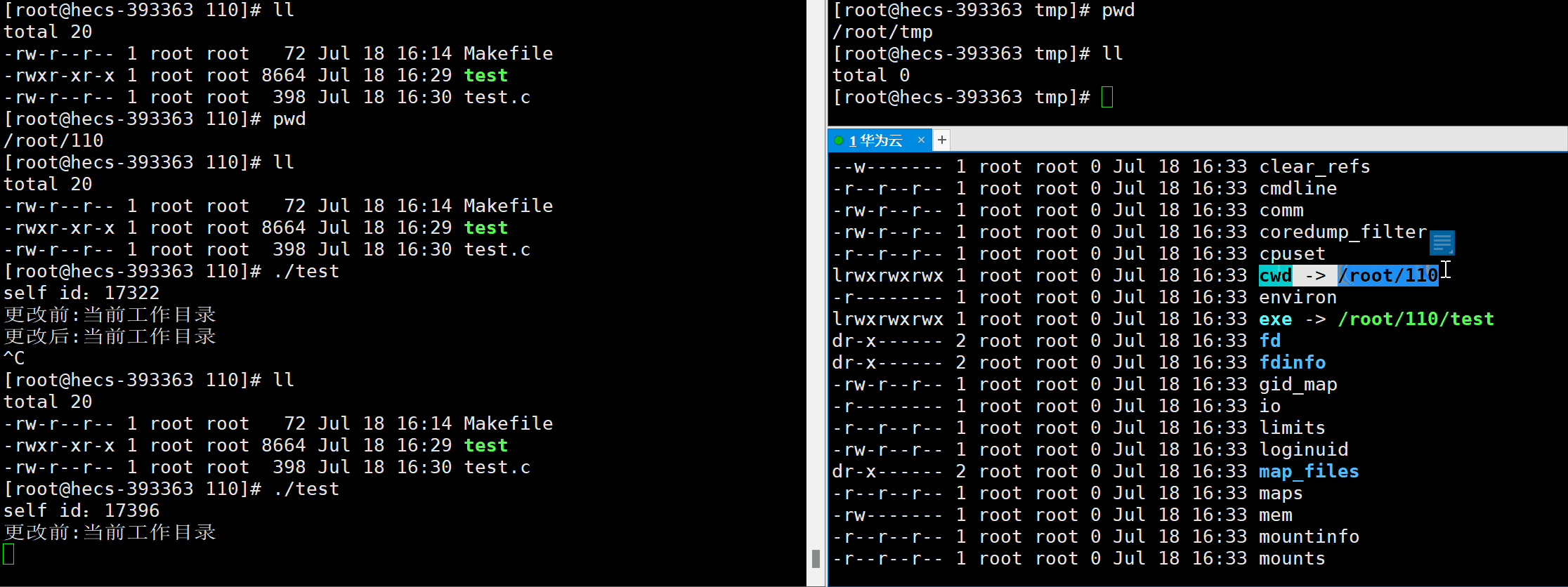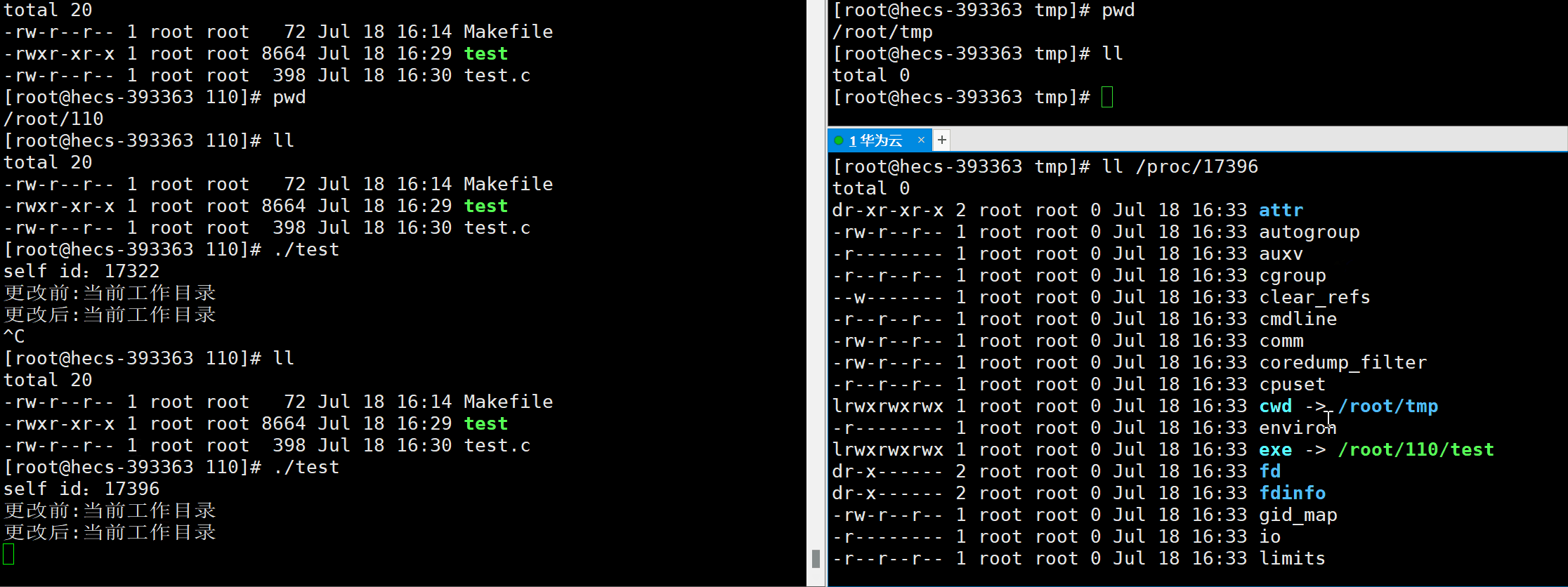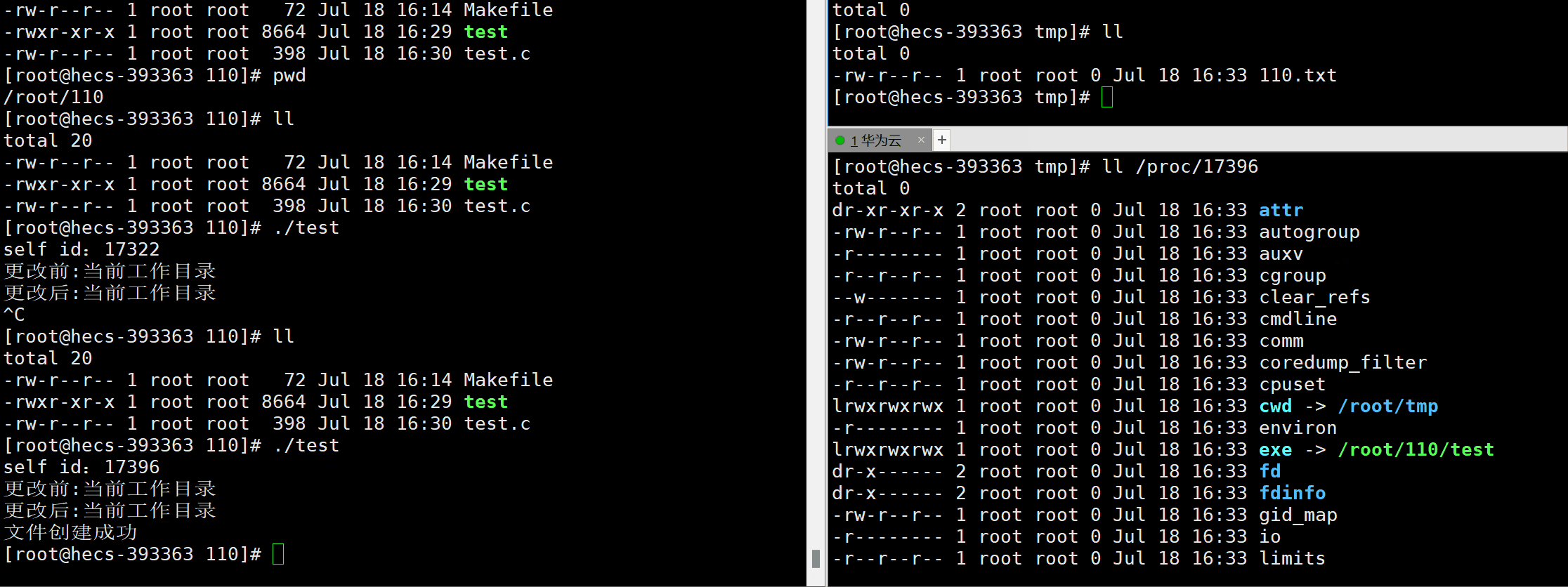
- cwd文件:是一个符号链接,表示当前进程的当前工作目录。
int chdir(const char* path) ;
- 功能:允许程序改变当前进程的当前工作目录cwd,是一个系统调用接口。

#include<stdio.h>#include<unistd.h>#include<sys/types.h>intmain(){printf("self id:%d\n",getpid());printf("更改前:当前工作目录\n");sleep(25);chdir("/root/tmp");printf("更改后:当前工作目录\n");sleep(25);
FILE* fp =fopen("110.txt","w");//此处表示,如果不存在110.txt文件,就会在当前路径(cwd)下,创建此文件if(fp ==NULL)return1;fclose(fp);printf("文件创建成功\n");return0;}
3.5. 进程标识符
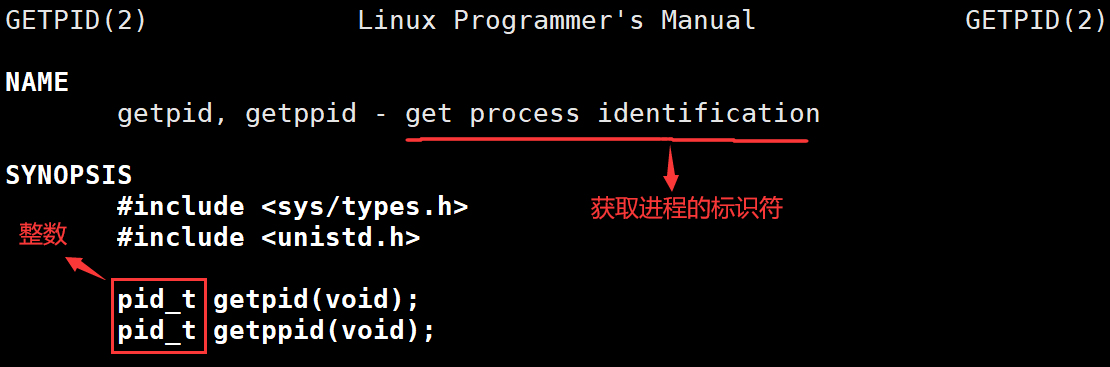
pid_t getpid(void) ;
- 功能:获取进程的标识符(PID)。
pid_t getppid(void) ;
- 功能:获取父进程的标识符(PID)。
ps ajx | head -1 && ps ajx | grep 18835 | grep -v grep
- 功能:获取单个进程。

- 一般在Linux中,普通进程,都有它的父进程。即:每个子进程都是由它的父进程创建出来的。
- 命令行解释器bash,是所有在命令行中启动的进程的父进程。孤儿进程例外。即:在命令行启动的进程都是bash的子进程。
- 多次运行同一个可执行程序,每次启动都会创建新的进程,OS会为每个新进程分配唯一的PID,每次运行的进程之间是独立的,互不影响。
注意:PCB对象以及内部数据,是操作系统内核的一部分,访问PCB内的数据,需要通过系统调用接口来访问。
3.6. 创建进程
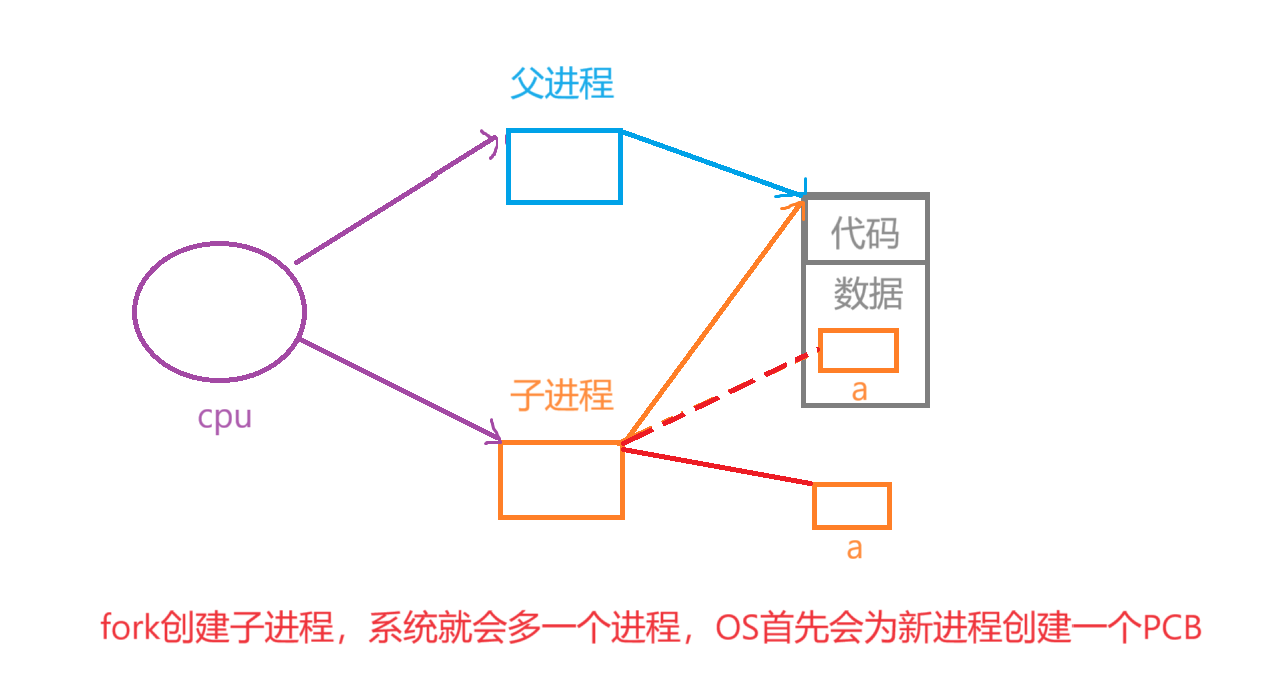
一、fork函数
pid_t fork(void) ;
- 功能:创建一个子进程。

- 概念:fork是个系统调用接口,用于创建一个新的进程,这个新进程被称为子进程,调用fork函数的进程称为父进程。
#include<stdio.h>#include<unistd.h>#include<sys/types.h>intmain(){printf("before fork: I am a process, pid: %d, ppid: %d\n",getpid(),getppid());sleep(1);fork();printf("after fork: I am a process, pid: %d, ppid: %d\n",getpid(),getppid());sleep(1);return0;}
![LY5_[C(CLFWNIH]B9}_CFKH.png](https://img-blog.csdnimg.cn/img_convert/c3f9462bc575be79a68964a698bc7876.png)
a. fork之后,代码共享。
b. 从一个执行分支流,变为了两个执行分支流,从一个父进程,变为了父子两进程,fork之后的代码父子进程同时执行。
- 返回值:如果创建进程成功,将子进程的PID返回给父进程,0返回给子进程。反之创建失败,将-1返回给父进程。
![I919OTSA[N8GO{`U1@UNA]S.png](https://img-blog.csdnimg.cn/img_convert/30914b889aa71f07713b24f9a3f3e798.png)
#include<stdio.h>#include<unistd.h>#include<sys/types.h>intmain(){printf("before fork: I am a process, pid: %d, ppid: %d\n",getpid(),getppid());sleep(4);printf("开始创建进程\n");sleep(1);pid_t id =fork();if(id <0)return1;elseif(id ==0){//子进程while(1){printf("after fork: 我是子进程,pid: %d, ppid: %d, id: %d \n",getpid(),getppid(), id);sleep(2);}}else{//父进程while(1){printf("after fork: 我是父进程,pid: %d, ppid: %d, id: %d \n",getpid(),getppid(), id);sleep(2);}}return0;}

- 特点:子进程被创建,是以父进程为模板。
fork函数创建的子进程会继承父进程的许多属性和数据、它会创建与父进程几乎完全一样的副本,所以fork之后代码共享。
-fork之后的代码是由父进程提供的,为了让父子进程执行不同代码,使用if. . . .else根据fork返回值进行分流。

二、fork函数原理
- 为什么fork函数给父进程返回子进程的PID,给子进程返回0?
- 父进程 :子进程 = 1 :N。父进程通过标识符来确认和控制子进程;父进程具有唯一性,子进程只需调用getppid( )函数,就可获取父进程的PID。
- 为什么fork函数会返回两次?
- 一个函数,已经运行到了最后开始执行return的时候,这个函数的核心逻辑已经执行完成了!
fork函数功能是创建子进程,在fork函数执行return之前,子进程就已经被创建出来了,return是语句、是代码,fork之后,代码共享,所以fork函数会返回两次。
- 为什么fork函数的返回值id,同一个变量id,既大于0,又等于0?
- 在Linux中,可以使用同一个变量名,可以表示不同的内存!
问1:一个进程崩溃,会影响其他进程吗?
答:不会。因为进程(任意)之间具有独立性,互不影响。操作系统在设计的时候,就必须保证这一点。
问2:父子进程对共享的数据做修改,会出现什么现象吗?
答:在没有发生写操作前,父子进程代码和数据是共享的,它们都指向同一份物理内存的只读副本。当其中一个进程(父/子进程)尝试对共享数据做修改时,内核会检测到写操作,然后从另一个进程那拷贝一份到自己这进行修改(为该进程创建数据的私有副本),这一操作称为写时拷贝。
版权归原作者 奶芙c 所有, 如有侵权,请联系我们删除。