
1. 注意事项如下
1.1 分区字段
可以有多个分区字段,一般以时间维度来建立分区,也可以再加其他字段。以业务场景为提前条件,来设定分区的字段。
从业务角度理解,分区字段可理解为业务数据的一部分,作为业务查询的一个条件。
从技术角度理解,分区字段是表外字段,不作为源表数据结构的字段【但也可以源表的业务字段,抽取出来作为分区字段,方便业务数据处理】,这是个人的理解,如果不对请联系本人。
PARTITIONED BY (
`plant_time` string COMMENT '工厂时间')
1.2 分隔符
建立使用 \u0001
hive默认的列分割类型为org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe,这其实就是^A分隔符。hive中默认使用^A(ctrl+A)作为列分割符,如果用户需要指定的话,等同于row format delimited fields terminated by '\001',因为^A八进制编码体现为'\001'。如果使用默认的分隔符,在建表时,可以不指定分割符,什么都不加;也可以按照上面的指定加‘\001’为列分隔符,效果一样。
hive默认使用的行分隔符是'\n'分隔符 ,也可以加一句:LINES TERMINATED BY '\n' 。如果在建表时,加不加效果一样。但是区别是hive可以通过row format delimited fields terminated by '\t'这个语句来指定不同的分隔符。但是hive不能够通过LINES TERMINATED BY '$$'来指定行分隔符,目前Hive的默认行分隔符仅支持‘\n’字符, 否则执行会报错。
如下所示:一些特殊字符
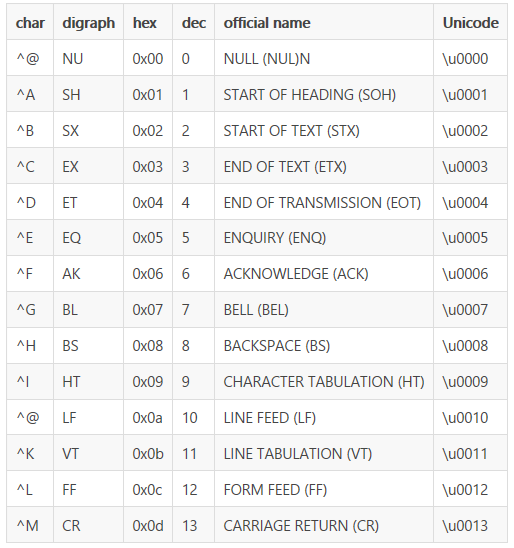
查看隐藏字符的方法:
cat -A filename
vim
使用vim进入编辑文件的命令模式,使用以下命令:
set list #显示隐藏字符
set nolist #取消显示隐藏字符
1.3 存储格式
本人建议使用 ORC 存储格式
Hive支持的存储数据的格式主要有存储形式TEXTFILE行式存储SEQUENCEFILE行式存储ORC列式存储PARQUET列式存储
1.3.1 列式存储和行式存储
行存储的特点: 查询满足条件的一整行数据的时候,行存储只需要找到其中一个值,其余的值都在相邻地方。列存储则需要去每个聚集的字段找到对应的每个列的值,所以此时行存储查询的速度更快。
列存储的特点: 因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的;
ORC和PARQUET是基于列式存储的。
使用如下命令
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\u0001' STORED AS ORC ;
2 建表语句实例
-- dwd.dwd_sap_mm_coois_history definition
CREATE TABLE `dwd.dwd_sap_mm_coois_history`(
`charg` string COMMENT '批次',
`matnr` string COMMENT '物料',
`maktx` string COMMENT '物料描述',
`lgort` string COMMENT '库存地点',
`bwart` string COMMENT '移动类型',
`einheit` string COMMENT '未清数量 (EINHEIT)',
`aufnr` string COMMENT '订单',
`bdter` string COMMENT '需求日期',
`werks` string COMMENT '工厂',
`lmeng` string COMMENT '需求数量',
`zzline` string COMMENT '线别',
`baugr` string COMMENT '追溯需求',
`bdmng` string COMMENT '需求数量 (EINHEIT)',
`enmng` string COMMENT '撤回数量 (EINHEIT)',
`txt04` string COMMENT '系统状态',
`flmng` string COMMENT '短缺 (EINHEIT)',
`ktext` string COMMENT '工作中心说明',
`arbpl` string COMMENT '工作中心',
`udate` string COMMENT '在制天数',
create_by string comment '建立者',
create_time timestamp comment '建立时间',
update_by string comment '最后更新者',
update_time timestamp comment '最后更新时间',
remark string comment '备注'
)
COMMENT '工单领料基本表 '
PARTITIONED BY (
`plant_time` string COMMENT '工厂时间')
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\u0001' STORED AS ORC ;
本文转载自: https://blog.csdn.net/yqj234/article/details/130745201
版权归原作者 yqj234 所有, 如有侵权,请联系我们删除。
版权归原作者 yqj234 所有, 如有侵权,请联系我们删除。