
一.HDFS的简介:
HDFS:大规模数据分布式存储核心
HDFS(Hadoop Distributed File System)是Hadoop项目的一个子项目,也是Hadoop的核心组件之一。它是一个分布式文件系统,设计用于存储大型数据,如TB和PB级别的数据。
HDFS的主要特征包括:
- 文件分块存储:在HDFS中,文件在物理上是分块存储的。块的大小可以通过配置参数(dfs.blocksize)来规定。在Hadoop 2.x版本中,默认块大小是128M,而在老版本中是64M。
- 统一的命名空间和目录树:HDFS文件系统会给客户端提供一个统一的抽象目录树。客户端通过路径来访问文件,形如:hdfs默认文件:https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
- 元数据管理:目录结构及文件分块信息(元数据)的管理由NameNode节点承担。NameNode是HDFS集群的主节点,负责维护整个HDFS文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的DataNode等)。
1.1 Hadoop架构
HDFS(Hadoop Distributed FileSystem),由3个模块组成:分布式存储HDFS,分布式计算MapReduce,资源调度框架Yarn
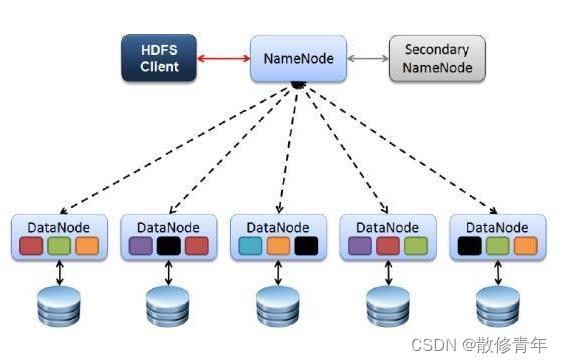
大量的文件可以分散存储在不同的服务器上面
单个文件比较大,单块磁盘放不下,可以切分成很多小的block块,分散存储在不同的服务器上面,各服务器通过网络连接,造成一个整体。
1.2 定义block
HDFS3.x上的文件会按照128M为单位切分成一个个的block,分散存储在集群的不同的数据节点datanode上,需要注意的是,这个操作是HDFS自动完成的。hadoop当中, 文件的 block 块大小默认是 128M(134217728字节)。
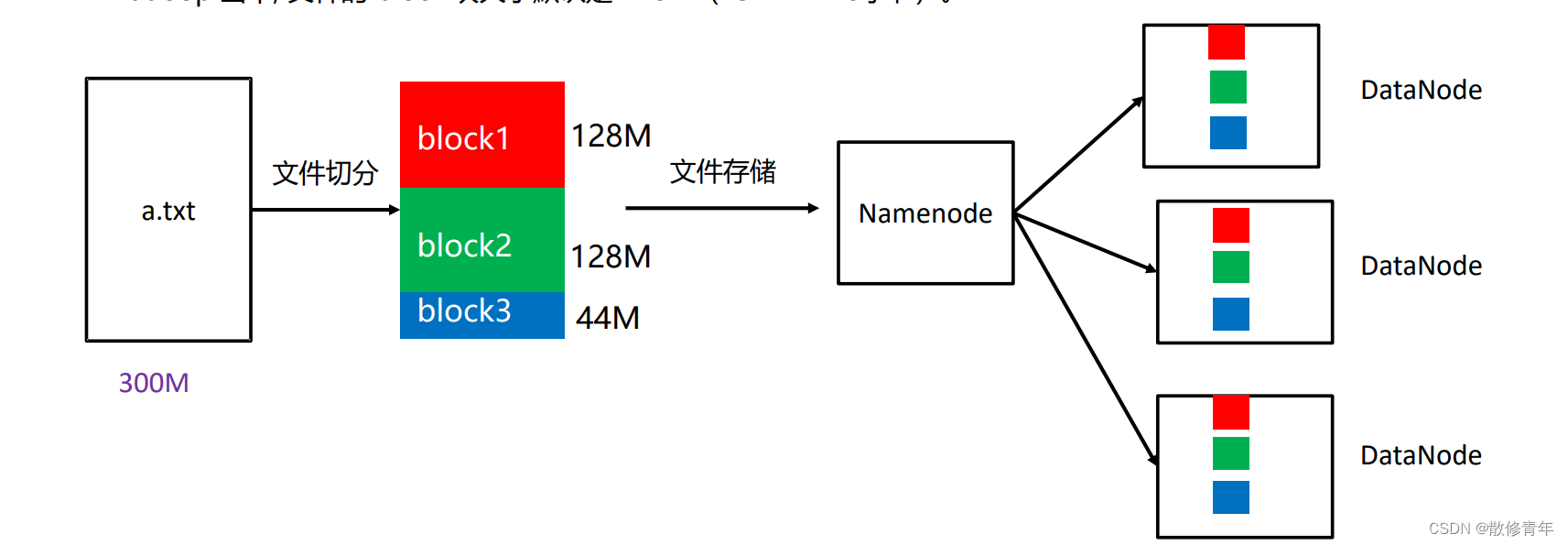
假设我们现在要存储一个300M的文件,这个300M就会被切分成这128M,128M,44M三块,这时我们需要知道,就算它的底层逻辑会按照128M进行划分,可是datanode3一个实际占用44M的块也是不会占据128M的空间的。(具体情况具体分析)
#即使是某一块突然宕机也不会影响整体的运行#
二、HDFS的四大组件
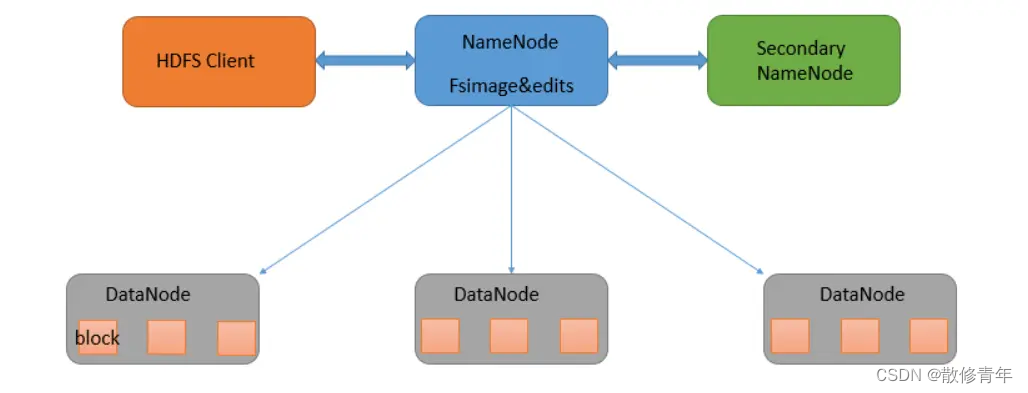
HDFS的四个基本组件:HDFS Client、NameNode、DataNode和Secondary NameNode
2.1Client 的介绍
就是客户端。 文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储 与 NameNode 交互,获取文件的位置信息。 与 DataNode 交互,读取或者写入数据。 Client 提供一些命令来管理 和访问HDFS,比如启动或者关闭HDFS。
2.2 NameNode的介绍
大数据框架都是分布式的,可能每个角色都运行在各个不同的服务器上面,需要进行通信的时候就要需要网络的支持,而在我们客户端需要读一个文件的信息时,必须知道我们这个文件被分成了多少个block,各个block又分别存储在哪个服务器上,这种用于描述文件的信息被称为文件的元数据信息(metaData),而metaData就是存储在NameNode的内存中的
2.3metaData的介绍(记录数据的数据)
#Hive元数据存储用Metastore
Hadoop元数据存储用Namenode
metaData的大小:文件,block,目录占用大概150byte字节的元数据,所以为什么说HDFS适合存储大文件而不适合存储小文件,可想而知存储一个大文件就只有一份150byte的元数据,存储N多个小文件就会伴随存在N份150Byte字节的元数据文件,这就非常地不划算(可以帮助你去按需购买所需要大小的运存)
2.4Secondary NameNode的介绍
** 并非 NameNode 的后备,当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务, 辅助 NameNode,分担其工作量, 在紧急情况下,可辅助恢复 NameNode。**
实习笔记:
1.访问端口
hdfs访问:2.x 50070 3.x 9870
运行日志:19888
yarn:8088
2.注:“-”开头是文件,“d”开头是文件夹
总的来说,HDFS是一个强大而灵活的分布式文件系统,适用于处理大规模数据存储和访问的需求。
版权归原作者 散修青年 所有, 如有侵权,请联系我们删除。