
一**.什么是spark**
1,Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎, 是当今大数据领域最活跃、最热门、最高效的大数据通用计算平台之一。
2,spark的生态圈
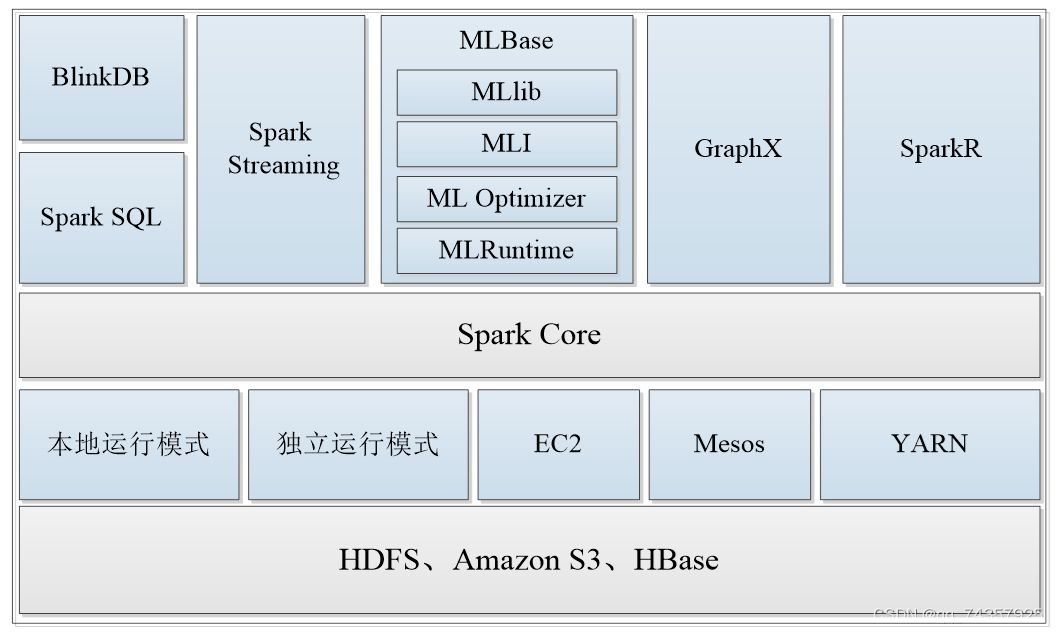
Spark Core
Spark的核心,提供底层框架及核心支持。
BlinkDB
一个用于在海量数据上进行交互式SQL查询的大规模并行查询引擎,允许用户通过权衡数据精度缩短查询响应时间,数据的精度将被控制在允许的误差范围内。
Spark SQL
可以执行SQL查询,支持基本的SQL语法和HiveQL语法,可读取的数据源包括Hive、HDFS、关系数据库(如MySQL)等。
SparkStreaming
可以进行实时数据流式计算。
MLBase
是Spark生态圈的一部分,专注于机器学习领域,学习门槛较低。
3.spark特点
运行速度快:
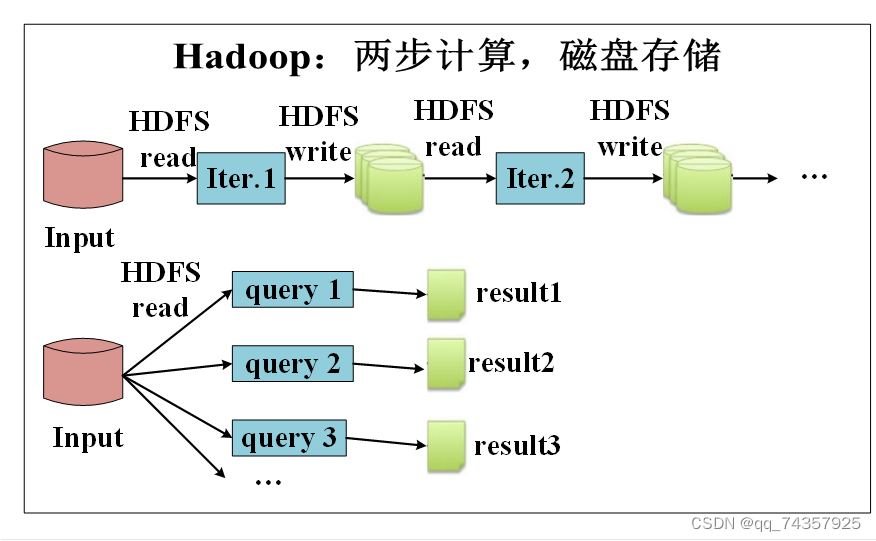
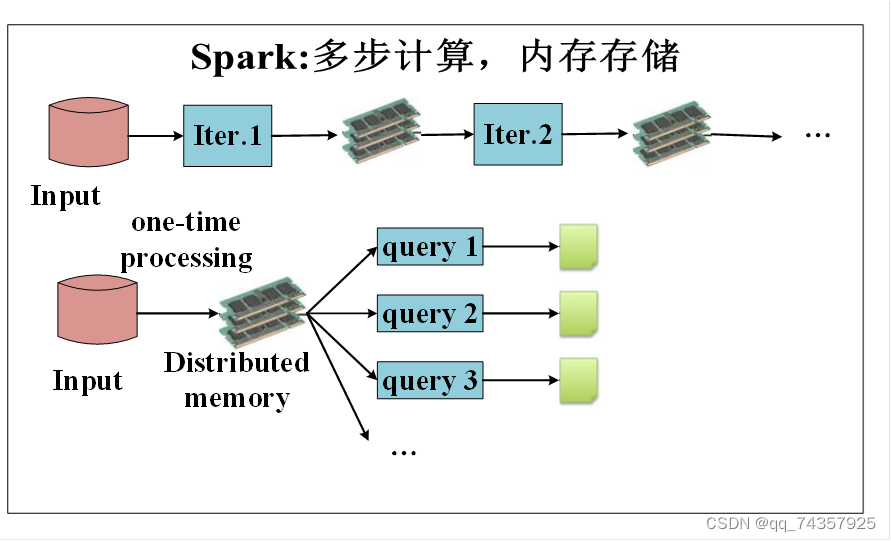
与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上。Spark实现了高效的DAG执行引擎,可以通过基于内存来高效处理数据流。计算的中间结果是存在于内存中。
易用性好:
Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的Shell,可以非常方便地在这些Shell中使用Spark集群来验证解决问题的方法。
通用性强:
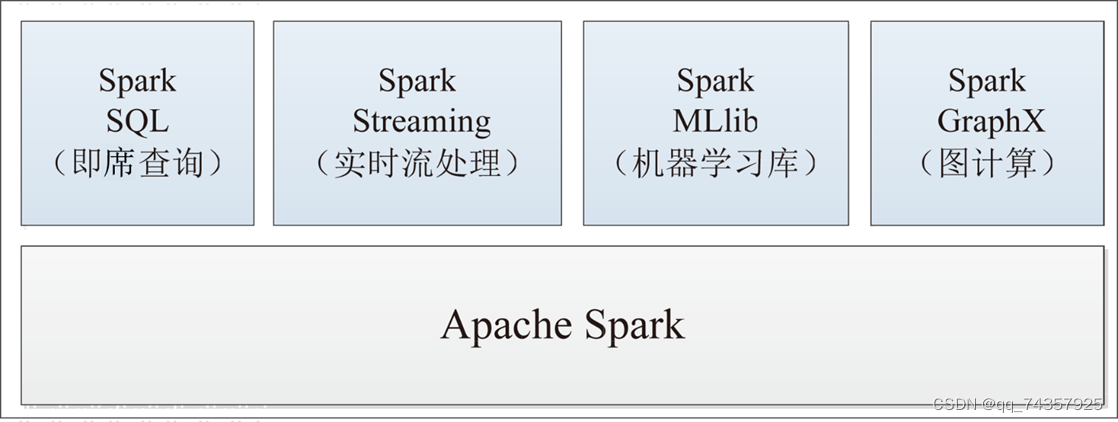
Spark提供了统一的解决方案。Spark可以用于,交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。减少了开发和维护的人力成本和部署平台的物力成本。
高兼容性:
Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。
4,spark架构
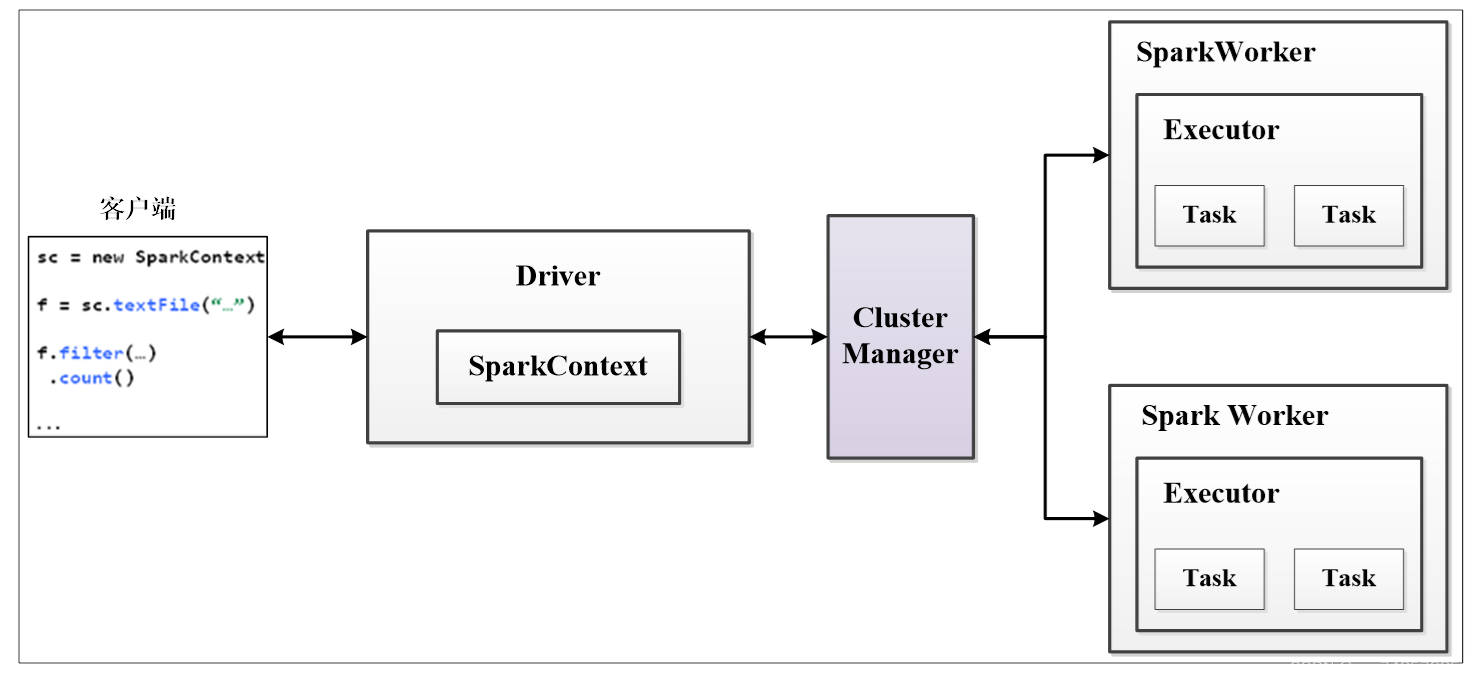
2.组件
客户端
用户提交作业的客户端。
Driver
运行Application的main()函数并创建SparkContext。
SparkContext
整个应用的上下文,控制应用的生命周期。
ClusterManager
资源管理器,即在集群上获取资源的外部服务,目前主要有Standalone(Spark原生的资源管理器)和YARN(Hadoop集群的资源管理器)。
SparkWorker
集群中任何可以运行应用程序的节点,运行一个或多个Executor进程。
Executor
执行器,在Spark Worker上执行任务的组件、用于启动线程池运行任务。每个Application拥有独立的一组Executor。
Task
被发送到某个Executor的具体任务。
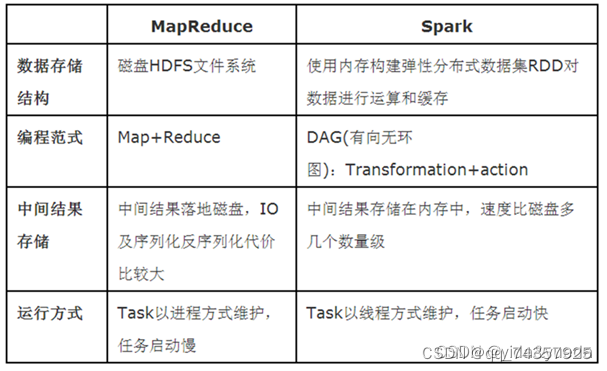
二.spark和mapreduce的对比
①架构
Spark采用的是经典的scheduler/workers模式, 每个Spark应用程序运行的第一步是构建一个可重用的资源池,然后在这个资源池里运行所有的ShuffleMapTask和ReduceTask
MapReduce采用了多进程模型,而Spark采用了多线程模型。
②速度
spark把中间计算结果存放在内存中,减少迭代过程中的数据落地,能够实现数据高效共享,迭代运算效率高;当然也有部分计算基于磁盘,比如Shuffle,但是其大量Transformation操作,比如单纯的map或者filter等操作可以直接基于内存进行pipeline操作。
mapreduce中的计算中间结果是保存在磁盘上的,产生了大量的I/O操作,效率很低。
③容错
spark容错性高,因为支持DAG(有向无环图)图的分布式,也叫spark有血缘机制,在计算过程中如果出现问题造成数据丢失,系统不用重新计算,只需要根据血缘关系找到最近的中间过程数据进行计算,而且基于内存的中间数据存储增加了再次使用的读取的速度,spark引进rdd弹性分布式数据集的概念,它是分布在一组节点中的只读对象集合,如果数据集一部分数据丢失,则可以根据血统来对它们进行重建;另外在RDD计算时可以通过checkpoint来实现容错,checkpoint有两种方式,即checkpiont data 和logging the updates。
④功能
hadoop只提供了map和reduce两种操作,spark提供的操作类型有很多,大致分为转换和行动操作两大类。
另外,Spark提供了Spark RDD、Spark SQL、Spark Streaming、Spark MLlib、Spark GraphX等技术组件,可以一站式地完成大数据领域的离线批处理、交互式查询、流式计算、机器学习、图计算等常见的任务,所以具有超强的通用性。
三**.什么是结构化数据,什么是非结构化数据**
结构化数据:即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据。结构化的数据是指可以使用关系型数据库表示和存储,表现为二维形式的数据。
一般特点是:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。
非结构化数据:非结构化数据是指信息没有一个预先定义好的数据模型或者没有以一个预先定义的方式来组织。非结构化数据一般指大家文字型数据,但是数据中有很多诸如时间,数字等的信息。相对于传统的在数据库中或者标记好的文件,由于他们的非特征性和歧义性,会更难理解。
文本、图片、音频/视频信息等等。
四.spark三种运行模式
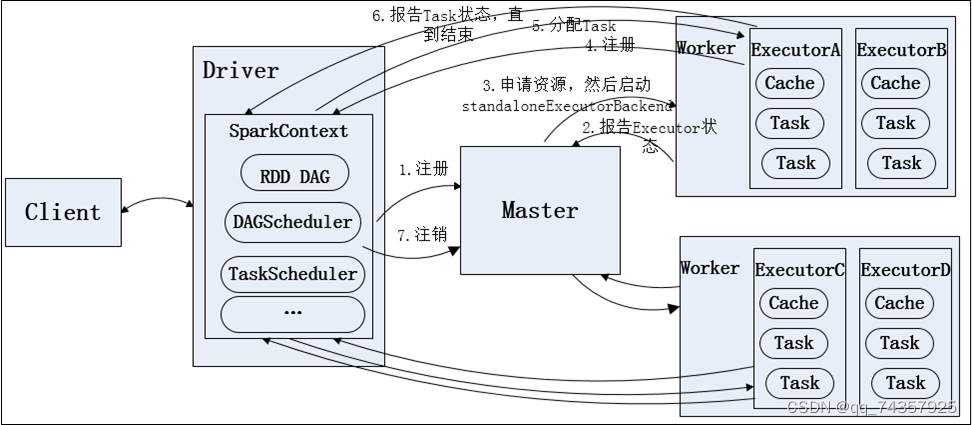
1.standalone模式
与MapReduce1.0框架类似,Spark框架本身也自带了完整的资源调度管理服务,可以独立部署到一个集群中,而不需要依赖其他系统来为其提供资源管理调度服务。在架构的设计上,Spark与MapReduce1.0完全一致,都是由一个Master和若干个Slave构成,并且以槽(slot)作为资源分配单位。不同的是,Spark中的槽不再像MapReduce1.0那样分为Map 槽和Reduce槽,而是只设计了统一的一种槽提供给各种任务来使用。
standalone模式运行流程
2.Spark on Mesos模式
Mesos是一种资源调度管理框架,可以为运行在它上面的Spark提供服务。Spark on Mesos模式中,Spark程序所需要的各种资源,都由Mesos负责调度。由于Mesos和Spark存在一定的血缘关系,因此,Spark这个框架在进行设计开发的时候,就充分考虑到了对Mesos的充分支持,因此,相对而言,Spark运行在Mesos上,要比运行在YARN上更加灵活、自然。目前,Spark官方推荐采用这种模式,所以,许多公司在实际应用中也采用该模式。
3. Spark on YARN模式
1,YARN是一种统一资源管理机制,在其上面可以运行多套计算框架。目前的大数据技术世界,大多数公司除了使用Spark来进行数据计算,由于历史原因或者单方面业务处理的性能考虑而使用着其他的计算框架,比如MapReduce、Storm等计算框架。Spark基于此种情况开发了Spark on YARN的运行模式,由于借助了YARN良好的弹性资源管理机制,不仅部署Application更加方便,而且用户在YARN集群中运行的服务和Application的资源也完全隔离,更具实践应用价值的是YARN可以通过队列的方式,管理同时运行在集群中的多个服务。
yarn-cluster模式运行流程

yarn-client运行流程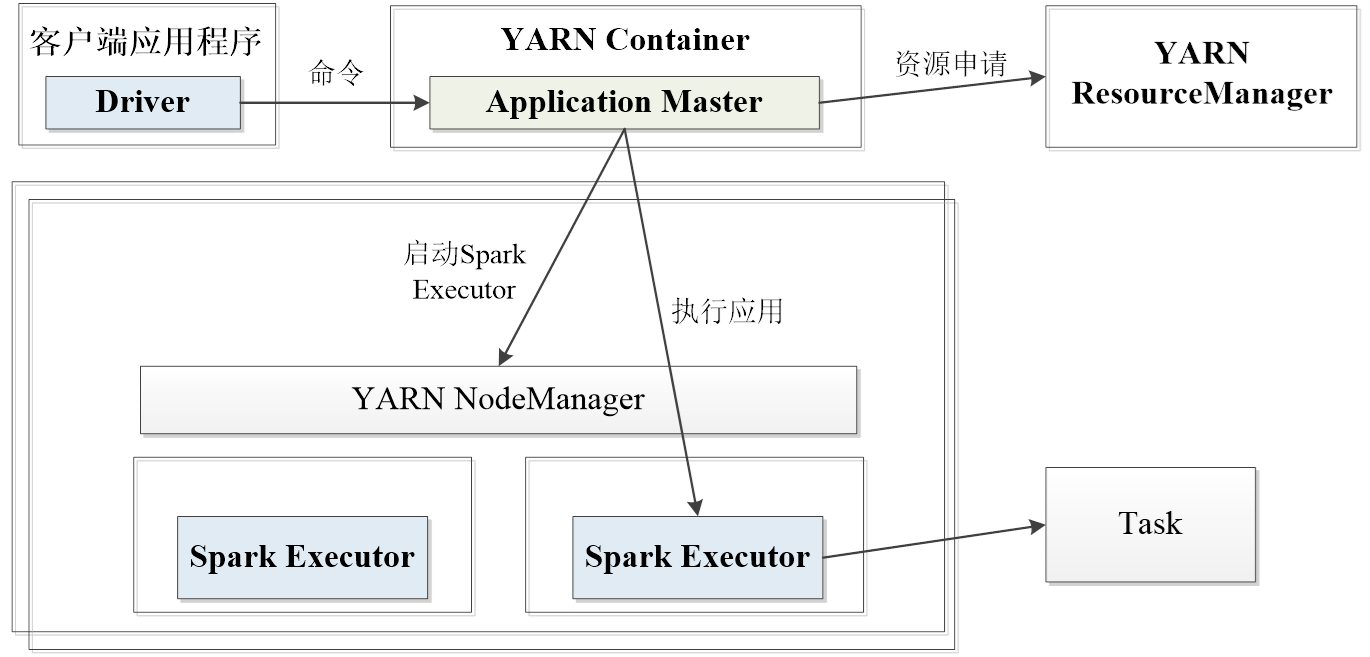
五.Spark****核心原理
1.Stage划分的依据是?
主要是基于Shuffle。Stage划分基于数据依赖关系的,一般分为两类:宽依赖(Shuffle Dependency)与窄依赖(Narrow Dependency)。
宽依赖,父RDD的一个分区会被子RDD的多个分区使用。
窄依赖,父RDD的分区最多只会被子RDD的一个分区使用。
区分宽窄依赖,我们主要从父RDD的Partition流向来看:流向单个RDD就是窄依赖,流向多个RDD就是宽依赖。
Spark Stage划分,就是从最后一个RDD往前推算,遇到窄依赖(NarrowDependency)就将其加入该Stage,当遇到宽依赖(ShuffleDependency)则断开。每个Stage里task的数量由Stage最后一个RDD中的分区数决定。如果Stage要生成Result,则该Stage里的Task都是ResultTask,否则是ShuffleMapTask。
2.怎么定义一个Task
一个供Executor执行的可执行的逻辑单元,Spark目前提供了两类Task,分别为ShuffleMapTask和ResultTask。Job会由一个或者多个Stage,一个Spark Job基于Stage构建成逻辑执行计划和物理执行计划。如: Job A={S1,S2,S3} 由三个Stage构成,那么S1、S2会由ShuffleMapTasks构成,S3作为Job的最后一个Stage由多个ResultTasks构成。Task在Driver侧构建,在Executor侧执行,执行完一个ResultTask会把Task的输出发送给Driver侧的应用程序,执行完一个ShuffleMapTask后基于Task的Partitioner把Task的输出划分多份进行存储。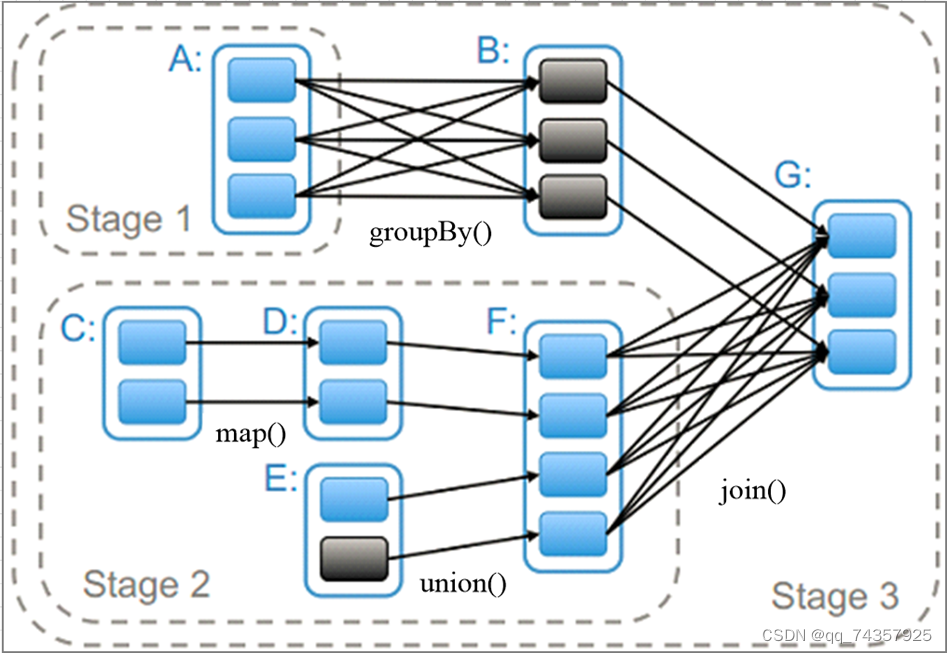
版权归原作者 qq_74357925 所有, 如有侵权,请联系我们删除。