
【大家好,我是爱干饭的猿,本文重点介绍Spark SQL的定义、特点、发展历史、与hive的区别、数据抽象、SparkSession对象。
后续会继续分享其他重要知识点总结,如果喜欢这篇文章,点个赞👍,关注一下吧】
上一篇文章:《【Spark入门】基础入门》
1. SparkSQL
1.1 什么是SparkSQL
SparkSQL 是Spark的一个模块, 用于处理海量结构化数据
限定: 结构化数据处理
1.2 为什么要学习SparkSQL
SparkSQL是非常成熟的 海量结构化数据处理框架
学习SparkSQL主要在2个点:
- SparkSQL本身十分优秀, 支持SQL语言\性能强\可以自动优化\API简单\兼容HIVE等等
- 企业大面积在使用SparkSQL处理业务数据 - 离线开发- 数仓搭建- 科学计算- 数据分析
1.3 SparkSQL特点
1. 融合性
SQL可以无缝集成在代码中,随时用sQL处理数据
2. 统一数据访问
一套标准API可读写不同数据源
3. Hive兼容
可以使用SparkSQL直接计算并生成Hive数据表
4. 标准化连接
支持标准化JDBC\ODBC连接,方便和各种数据库进行数据交互
1.4 SparkSQL发展历史
在许多年前(2012\2013左右)Hive逐步火热起来, 大片抢占分布式SQL计算市场。
Spark作为通用计算框架, 也不可能放弃这一细分领域,于是, Spark官方模仿Hive推出了Shark框架(Spark 0.9版本) Shark框架是几乎100%模仿Hive, 内部的配置项\优化项等都是直接模仿而来。不同的在于将执行引擎由MapReduce更换为了Spark。
因为Shark框架太模仿Hive, Hive是针对MR优化, 很多地方和SparkCore(RDD)水土不服, 最终被放弃,Spark官方下决心开发一个自己的分布式SQL引擎 也就是诞生了现在的SparkSQL。
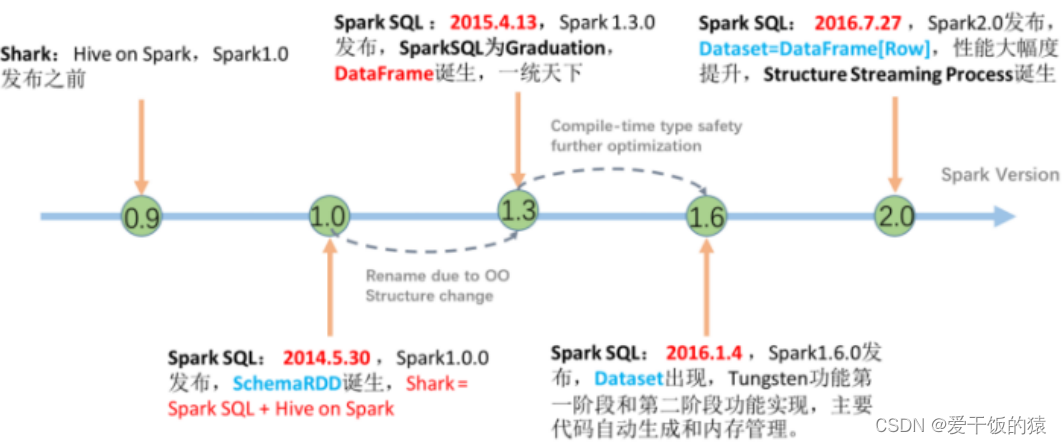
● 2014年 1.0正式发布
● 2015年 1.3 发布DataFrame数据结构, 沿用至今
● 2016年 1.6 发布Dataset数据结构(带泛型的DataFrame), 适用于支持泛型的语言(Java\Scala)
● 2016年 2.0 统一了Dataset 和 DataFrame, 以后只有Dataset了, Python用的DataFrame就是 没有泛型的Dataset
● 2019年 3.0 发布, 性能大幅度提升,SparkSQL变化不大
2. SparkSQL 概述
2.1 SparkSQL和Hive的异同
Hive和Spark均是:“分布式SQL计算引擎”
均是构建大规模结构化数据计算的绝佳利器,同时SparkSQL拥有更好的性能。
目前,企业中使用Hive仍旧居多,但SparkSQL将会在很近的未来替代Hive成为分布式SQL计算市场的顶级
2.2 SparkSQL的数据抽象


2.3 SparkSQL数据抽象的发展
从SparkSQL的发展历史可以看到:
• 14年最早的数据抽象是:SchemaRDD(内部存储二维表数据结构的RDD),SchemaRDD就是魔改的RDD,将RDD支持的存储数据,限定
为二维表数据结构用以支持SQL查询。由于是魔改RDD,只是一个过渡产品,现已废弃。
• 15年发布DataFrame对象,基于Pandas的DataFrame(模仿)独立于RDD进行实现,将数据以二维表结构进行存储并支持分布式运行
• 16年发布DataSet对象,在DataFrame之上添加了泛型的支持,用以更好的支持Java和Scala这两个支持泛型的编程语言
• 16年,Spark2.0版本,将DataFrame和DataSet进行合并。其底层均是DataSet对象,但在Python和R语言到用时,显示为DataFrame对象
。和老的DataFrame对象没有区别
2.4 DataFrame数据抽象
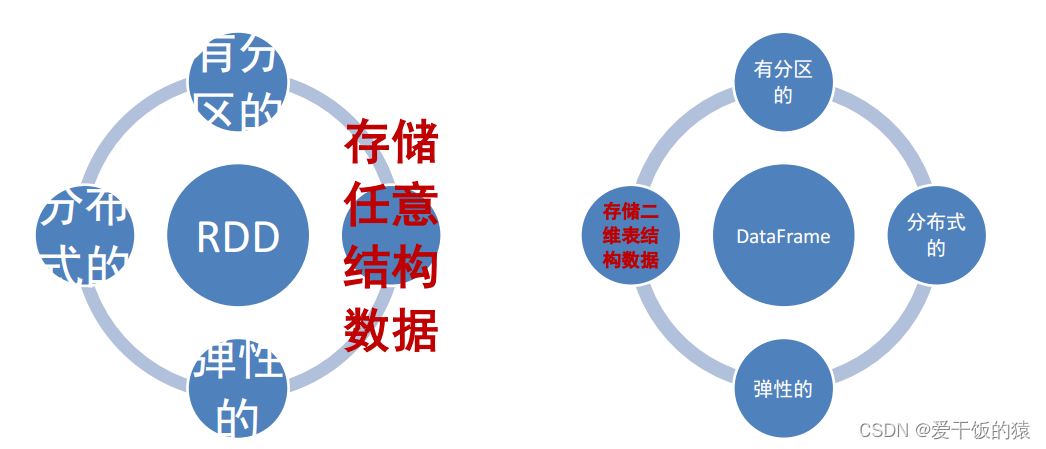
DataFrame和RDD都是:弹性的、分布式的、数据集
只是,DataFrame存储的数据结构“限定”为:二维表结构化数
据,而RDD可以存储的数据则没有任何限制,想处理什么就处理什么
所以DataFram更适合sql处理
2.5 SparkSession对象
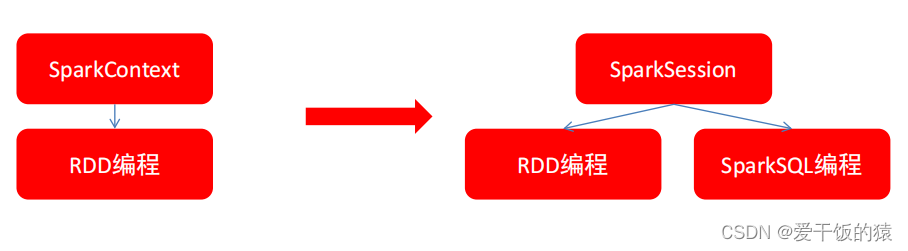
在RDD阶段,程序的执行入口对象是: SparkContext
在Spark 2.0后,推出了SparkSession对象,作为Spark编码的统一入口对象。
SparkSession对象可以:
- 用于SparkSQL编程作为入口对象
- 用于SparkCore编程,可以通过SparkSession对象中获取到SparkContext 所以,我们后续的代码,执行环境入口对象,统一变更为SparkSession对象
代码演示:
# coding:utf8# SparkSession对象的导包,对象是来自于pyspark.sql包中from pyspark.sql import SparkSession
if __name__ =='__main__':# 构建SparkSession执行环境入口对象
spark = SparkSession.builder.\
appName("test").\
master("local[*]").\
getOrCreate()# 通过SparkSession对象获取SparkContext对象
sc = spark.sparkContext
# SparkSOL的HelloWorld
df = spark.read.csv("../xian_rent/rent.csv", sep=',', header=True)# 展示表结构
df.printSchema()# 注册成零时表,可以通过sql使用
df.createTempView("rent_data")# 1. SQL 风格
spark.sql("""
select * from rent_data where price >= 8000 limit 5
""").show()# 2. DSL 风格
df.where("price >= 8000").limit(5).show()
版权归原作者 爱干饭的猿 所有, 如有侵权,请联系我们删除。