
1 man指令(重要)
Linux的命令有很多参数,我们不可能全记住,我们可以通过查看联机手册获取帮助。访问Linux手册页的命令是 :
man 语法: man [选项] 命令
**常用选项 **
-k 根据关键字搜索联机帮助 ;
num 只在第num章节找 ;
-a 将所有章节的都显示出来,比如 man printf 它缺省从第一章开始搜索,知道就停止,用a选项,当按下q退出,他会继续往后面搜索,直到所有章节都搜索完毕。
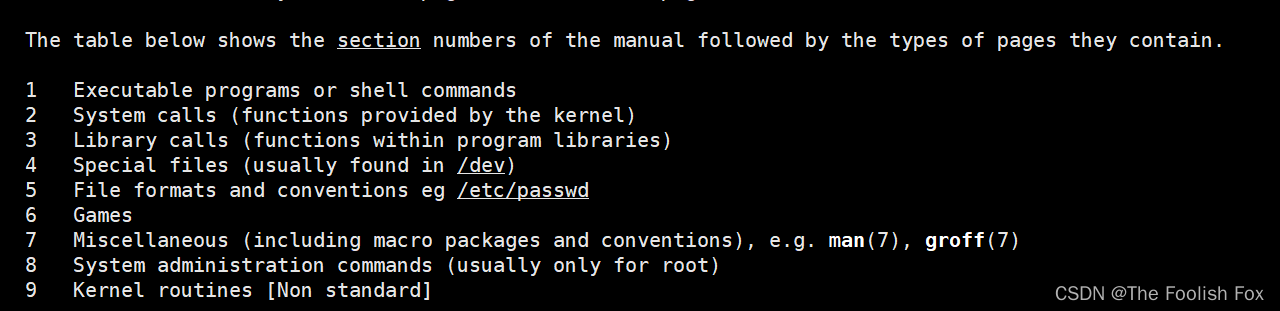
解释一下,mam手册总共分为9章:
1 是普通的命令
2 是系统调用,如open,write之类的(通过这个,至少可以很方便的查到调用这个函数,需要加什么头文件)
3 是库函数,如printf,fread4是特殊文件,也就是/dev下的各种设备文件
4 特别的文件
5 是指文件的格式,比如passwd, 就会说明这个文件中各个字段的含义
6 是给游戏留的,由各个游戏自己定义
7 是附件还有一些变量,比如向environ这种全局变量在这里就有说明
8 是系统管理用的命令,这些命令只能由root使用,如ifconfifig
9 内核例程(非标准)
我们可以试试:
man man
我们可以怎样去查找c语言中printf呢?
man 3 printf
然后就能够跳转到man手册:

退出的话按:q
至于查找其他选项大家下来可以自己试试。
2 more指令
语法:more [选项][文件]
功能:more命令,功能类似 cat
常用选项:
- -n 显示前n行 (这里的n是敲数字,不是敲n)
- q 退出more
这个指令的功能类似与cat都是查看目标文件的内容,不过具体细节效果有所差异,在讲more之前我们再来学习一个指令:echo

正如你看到的那样,echo后面跟一堆字符就能把字符打印到屏幕上,那带不带" "有啥区别吗?
严格说区别不大,但是带上" "能够更方便我们知道后面是字符串。
那我们能用echo将字符串打印到文件里面吗?
答案是当然可以的
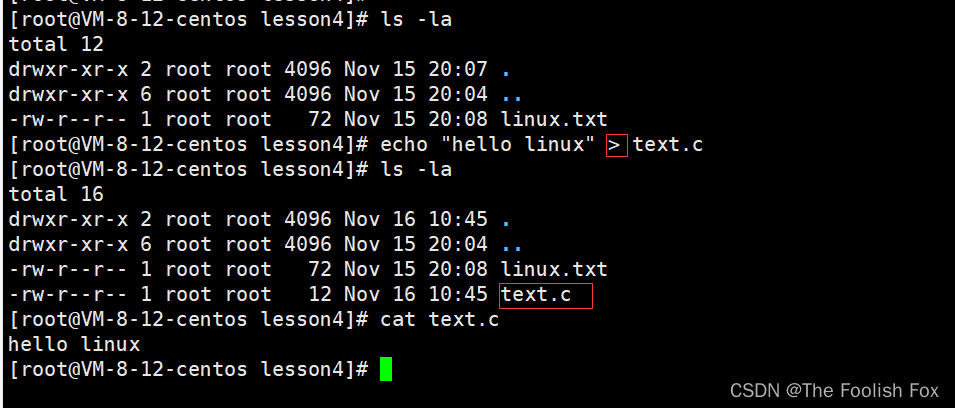
我们可以看到刚开始我们当前目录下是没有text.c这个文件的,可以当我们执行了:
echo "hello linux" > text.c
就会生成一个text.c文件并且把字符写入到文件中,而这个**> ** 我们叫做 输出重定向。
这个概念大家一定要记住很重要,并且输出重定向是覆盖式的写入的,什么意思呢?
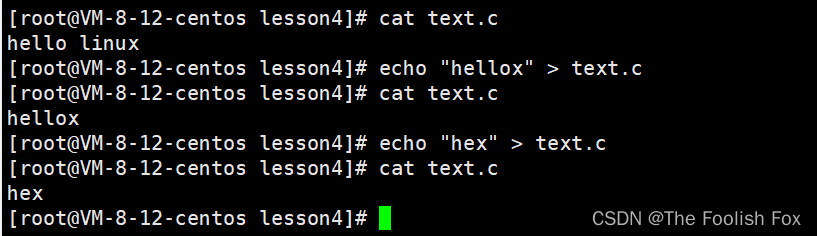
通过上面我们可以知道当我们执行一个新的输出重定向的时候会直接将原来文件内容清空,然后再写入,那有没有什么方法不清空原来数据呢?
答案是有的:当我们执行:
echo "hello linux" >> text.c

这个 >> 就叫做追加重定向,它会保留原来的数据。
有了输出重定向那有没有输入重定向呢?
答案是有的

通过上面我们可以知道上述两种方法都能将文件中内容读取出来,但是方法却是不同的,第一种用的是输入重定向方法,第二种是用的cat指令这种方法,这两种方法的具体差异我们后面的学习会详细讲解,这里就不在多说了。而这个 < 就叫做输入重定向。
现在回归正题,more究竟是怎么使用的呢?
我们创建一个文本内容很长的文件,这里我们使用Shell脚本的命令,我也看不懂,大家目前了解一下就好,后面我们会系统的学系这个的。
cnt=0; while [ $cnt -le 1000 ]; do echo "hello $cnt"; let cnt++; done > mylog.txt
假如我们还是用cat去打开的话:
他会直接跳转到最后几行,前面的内容就被很快的跳过,想要找到就得一行一行的找,很麻烦

那我们就可以使用more:
使用命令:
more mylog.txt
光标会定位到当前屏幕所能容纳的最多内容这里,并且不会继续往下走,再敲回车才会往下走:

每敲一次回车往下走一行,直到走到最后。但是它的缺陷是并不能往回走,就是当你错过了就无法再回去了,更好的处理方法就是我们要讲的下一个命令:less
3 less指令(重要)
- less 工具也是对文件或其它输出进行分页显示的工具,应该说是linux正统查看文件内容的工具,功能极其强大。
- less 的用法比起 more 更加的有弹性。在 more 的时候,我们并没有办法向前面翻, 只能往后面看但若使用了 less 时,就可以使用 [pageup][pagedown] 等按键的功能来往前往后翻看文件,更容易用来查看一个文件的内容!
- 除此之外,在 less 里头可以拥有更多的搜索功能,不止可以向下搜,也可以向上搜
语法: less [参数] 文件
功能:
less与more类似,但使用less可以随意浏览文件,而more仅能向前移动,却不能向后移动,而且less在查看之前 不会加载整个文件。
选项:
- -i 忽略搜索时的大小写
- -N 显示每行的行号
- /字符串:向下搜索“字符串”的功能
- ?字符串:向上搜索“字符串”的功能
- n:重复前一个搜索(与 / 或 ? 有关)
- N:反向重复前一个搜索(与 / 或 ? 有关)
- q:quit
具体用法:
less -N mylog.txt
我们可以通过上下翻阅来查找我们想要查询的内容,还可以通过/字符串 和?字符串 来更方便的查找,其他功能你们也可以下去试试,这里就不在多说了,less的功能总的来说比more强大了不少。
4 head指令和tail指令
这两个指令都比较简单,顾名思义,它是用来显示开头或结尾某个数量的文字区块,head 用来显示档案的 开头至标准输出中,而 tail 想当然就是看档案的结尾。
语法: head [参数]... [文件]...
功能:
head 用来显示档案的开头至标准输出中,默认head命令打印其相应文件的开头10行。
选项:
-n<行数> 显示的行数
tail 命令从指定点开始将文件写到标准输出.使用tail命令的-f选项可以方便的查阅正在改变的日志文件,tail -f fifilename会把fifilename里最尾部的内容显示在屏幕上,并且不但刷新,使你看到最新的文件内容.
语法: tail[必要参数][选择参数][文件]
功能:用于显示指定文件末尾内容,不指定文件时,作为输入信息进行处理。常用查看日志文件。
选项:
- -f 循环读取
- -n<行数> 显示行数

这个很简单,大家都很容易理解,那么现在问题来了,如何显示文件中第295行到300行的内容呢?
有人会说,这还不简单吗?将该文件的前300行输出重定向到一个临时文件tmp.txt中,再用tail指令取最后5行内容不就行了吗
这种方法是可取的,我们可以来试试:

这样我们就创建好了临时文件,我们可以通过临时文件来得到我们想要的数据

那如果我们再加一个限制条件,不准使用临时文件来保存呢?
这个时候就可以用管道(|)来处理了
命令:
cat mylog.txt | head -300 | tail -5
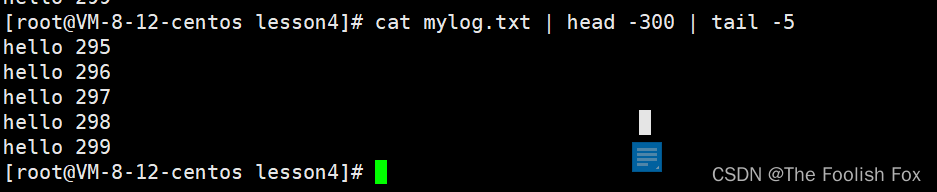
我们发现用管道来处理的确方便了不少,而管道也正如它的名字一样,就是作为一种中介条件将不同命令组合起来用,我们甚至还可以这样用:

最后的这个wc又是什么鬼呢?
wc通俗来讲其实是用来统计行数的,我们可以来看看:

使用这个命令可以统计出文件有多少行,而在上面我们最后用了管道来统计出295行到300行之间的行数,不难看出使用多个管道命令最终执行会落实到最后一个命令上去。
5 时间相关的指令
date****显示
date 指定格式显示时间: date +%Y:%m:%d
date 用法:date [OPTION]... [+FORMAT]
**1.**在显示方面,使用者可以设定欲显示的格式,格式设定为一个加号后接数个标记,其中常用的标记列表如下:
%H : 小时(00..23)
%M : 分钟(00..59)
%S : 秒(00..61)
%X : 相当于 %H:%M:%S
%d : 日 (01..31)
%m : 月份 (01..12)
%Y : 完整年份 (0000..9999)
%F : 相当于 %Y-%m-%d
我们可以来试试:

这里面+和%是不能够省略的,其他地方的字符可以自己替换:

**2.**在设定时间方面
- date -s //设置当前时间,只有root权限才能设置,其他只能查看。
- date -s 20080523 //设置成20080523,这样会把具体时间设置成空00:00:00
- date -s 01:01:01 //设置具体时间,不会对日期做更改
- date -s “01:01:01 2008-05-23″ //这样可以设置全部时间
- date -s “01:01:01 20080523″ //这样可以设置全部时间
- date -s “2008-05-23 01:01:01″ //这样可以设置全部时间
- date -s “20080523 01:01:01″ //这样可以设置全部时间
**3.**时间戳
时间->时间戳:date +%s
时间戳->时间:date -d@1508749502
Unix时间戳(英文为Unix epoch, Unix time, POSIX time 或 Unix timestamp)是从1970年1月1日(UTC/GMT的午夜)开始所经过的秒数,不考虑闰秒

我们可以将时间戳转化成具体的时间
6 Cal指令
cal命令可以用来显示公历(阳历)日历。公历是现在国际通用的历法,又称格列历,通称阳历。“阳历”又名“太阳历”,系以地球绕行太阳一周为一年,为西方各国所通用,故又名“西历”。
命令格式:cal [参数][月份][年份]
功能: 用于查看日历等时间信息,如只有一个参数,则表示年份(1-9999),如有两个参数,则表示月份和年份
常用选项:
- -3 显示系统前一个月,当前月,下一个月的月历
- -j 显示在当年中的第几天(一年日期按天算,从1月1号算起,默认显示当前月在一年中的天数)
- -y 显示当前年份的日历

7 find指令:(灰常重要) -name
- Linux下find命令在目录结构中搜索文件,并执行指定的操作。
- Linux下find命令提供了相当多的查找条件,功能很强大。由于find具有强大的功能,所以它的选项也很多,其中大部分选项都值得我们花时间来了解一下。
- 即使系统中含有网络文件系统( NFS),find命令在该文件系统中同样有效,只你具有相应的权限。
- 在运行一个非常消耗资源的find命令时,很多人都倾向于把它放在后台执行,因为遍历一个大的文件系统可能会花费很长的时间(这里是指30G字节以上的文件系统)

这个指令的意思是将家目录中所有名字为text.c的路径都显示出来,这里我们只有一个,所以只显示了一个,我们不妨再lesson2的目录下再创建个text.c,来观察是否会显示:

很明显我们观察到了我们想要的结果,至于find命令的其他选项,大家下来后可以自己试试。
8 grep指令
grep的参考文档
语法: grep [选项] 搜寻字符串 文件
**功能: **在文件中搜索字符串,将找到的行打印出来
**常用选项: **
-i :忽略大小写的不同,所以大小写视为相同
-n :顺便输出行号
-v :反向选择,亦即显示出没有 '搜寻字符串' 内容的那一行

通过这个命令我们能比较直观的找到我们想要找到的文件数据,有点儿类似Windows中搜索功能,该命令能够再任意文件中查找我们想要的数据并且把它打印出来,我们还可以通过管道来打印:
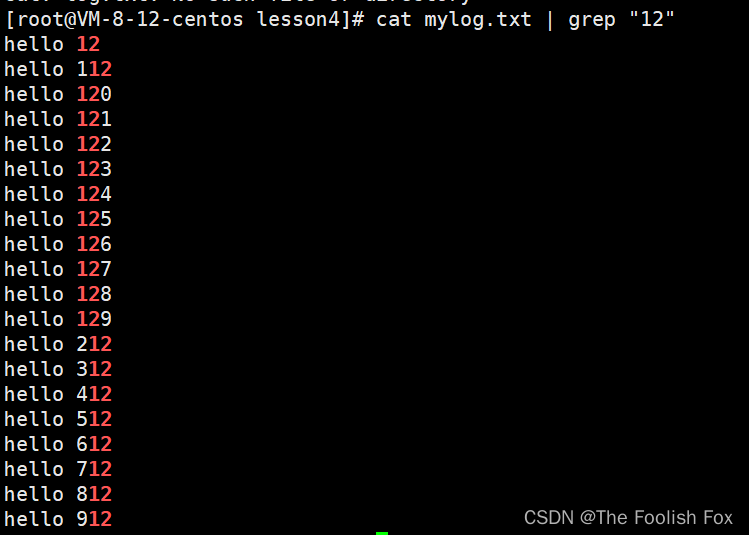
讲到这儿,我再补充一个小知识点:Linux下一切皆文件,无论是键盘还是屏幕,甚至是指令,再Linux中都被当做文件来处理,这个在后面我们还会有深刻的认识。
9 zip/unzip指令
语法:zip 压缩文件.zip 目录或文件
功能:将目录或文件压缩成zip格式
这个命令很简单,我们可以直接上手试试:

我们最后发现为lesson4中啥也没有呢?
原因就处在我们压缩的时候:压缩的时候有多级目录的话要加上 -r 选项递归处理,否则就会出错。
我们将前面的删掉然后重新压缩:

这下可以明显看见成功了。
10 其他常见命令
1 sort:(文本行排序)
首先我们打开linux.txt文件,向里面写入数据:
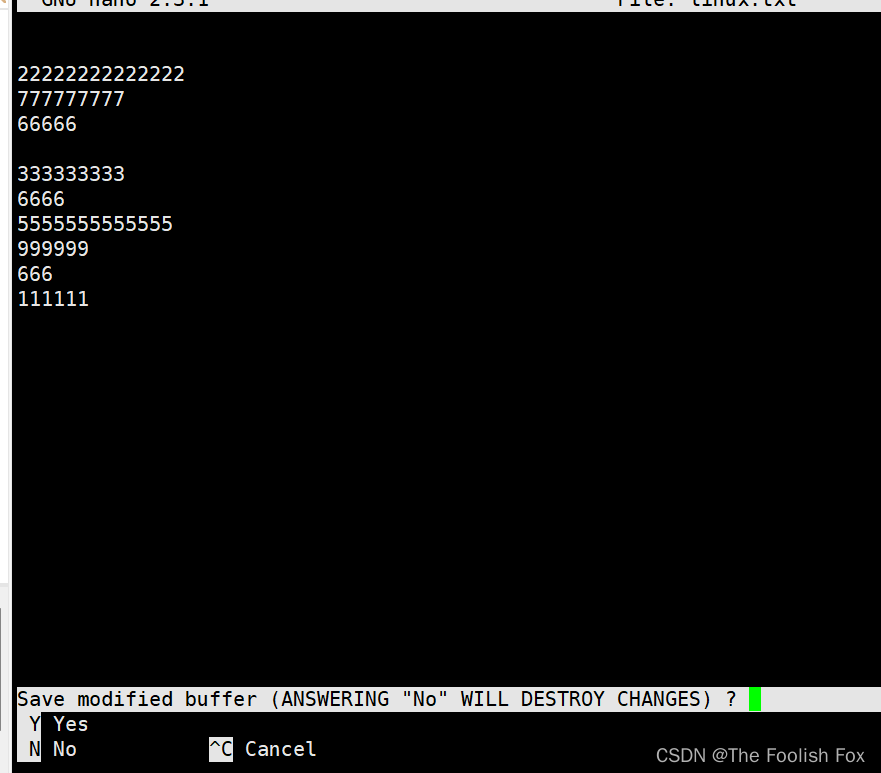
保存退出后使用命令:
sort linux.txt

我们看到该文本已经按照ascll大小排列出来了。
2 uniq:(相邻内容去重)
我们重新打开nano修改一下里面数据,然后进行排序去重:
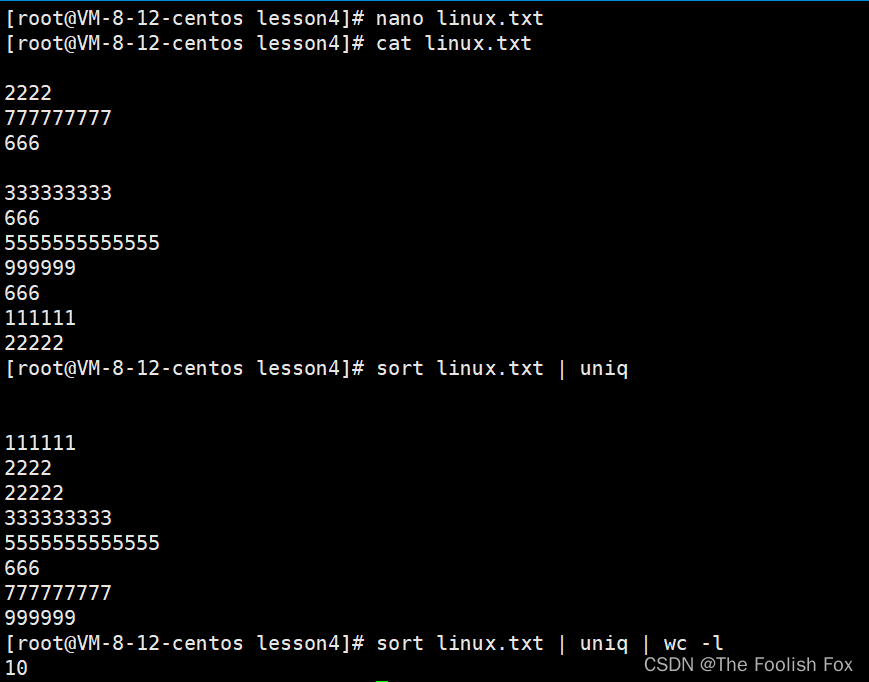
最终我们可以发现文本内容重复的已经被删去,剩下的按照ascll大小进行排列,最后文本内容剩下了10行。
注意:无论是去重还是排序,文本实际的内容是不会改变的,就是说改变的只是我们在屏幕上看见的数据,文本的数据没有发生一点儿改变。

文本内容还是以前未排序未去重的样子。
3 which:(查看指令路径)

4 whereis:(搜索包含关键字的文档)

5 top:(任务管理器)

这个类似于Windows中任务管理器。退出的话按q。
6 alias:(起别名)

注意=不能省略,' '可以换成" ",但是不能不写。
总结:
本次我们介绍的命令有:
manmoreecholessheadtailwcdatecalfindgrepzip/unzipsortuniqwhichwhereistopalias
与此同时我们还了解了输出重定向,追加重定向,输入重定向,管道等等知识,看起来很乱很杂,但是我们要好好的把这些命令融会贯通,才能为后面的学习做准备。由于整理的有点儿仓促,有错误是不可避免的,希望大佬们能指正本文的错误,非常感谢。
基本指令这里还有一部分没有讲完,剩下内容将在下一次补充,我们下期再见啦!

版权归原作者 Fox! 所有, 如有侵权,请联系我们删除。