
【源码解读】|SparkContext源码解读
导读

**可以关注下公众号:857Hub,专注数据开发、数据架构之路,热衷于分享技术干货。 **
本文针对于Spark2.4系列分析
/**
* Main entry point for Spark functionality. A SparkContext represents the connection to a Spark
* cluster, and can be used to create RDDs, accumulators and broadcast variables on that cluster.
* Spark功能的主要入口点。 SparkContext表示与Spark集群的连接,可用于在该集群上创建RDD,累加器和广播变量。
*
* Only one SparkContext may be active per JVM. You must `stop()` the active SparkContext before
* creating a new one. This limitation may eventually be removed; see SPARK-2243 for more details.
* 每个JVM只能激活一个SparkContext。在创建新的SparkContext之前,您必须“停止()”活动的SparkContext。
* 此限制可能最终会消除;有关更多详细信息,请参见SPARK-2243
*
* @param config a Spark Config object describing the application configuration. Any settings in
* this config overrides the default configs as well as system properties.
* 传入参数config是一个描述应用程序配置的Spark Config对象。此配置中的任何设置都会覆盖默认配置以及系统属性
*/
须知
一、 CallSite创建
什么叫CallSite? CallSite有什么用?
/** CallSite represents a place in user code. It can have a short and a long form. */
CallSite表示用户代码中的一个位置。它可以有短的和长的形式。(最短栈、最长栈)
private[spark] case class CallSite(shortForm: String, longForm: String)
源码中通过getCallSite() 方法配置返回CallSite
参数示意:
参数英文名参数含义lastSparkMethod方法存入firstUserFile类名存入firstUserLine行号存入
源码如下:
def getCallSite(skipClass:String=>Boolean= sparkInternalExclusionFunction): CallSite ={// Keep crawling up the stack trace until we find the first function not inside of the spark// package. We track the last (shallowest) contiguous Spark method. This might be an RDD// transformation, a SparkContext function (such as parallelize), or anything else that leads// to instantiation of an RDD. We also track the first (deepest) user method, file, and line.var lastSparkMethod ="<unknown>"var firstUserFile ="<unknown>"var firstUserLine =0var insideSpark =trueval callStack =new ArrayBuffer[String]():+"<unknown>"
Thread.currentThread.getStackTrace().foreach { ste: StackTraceElement =>// When running under some profilers, the current stack trace might contain some bogus// frames. This is intended to ensure that we don't crash in these situations by// ignoring any frames that we can't examine.if(ste !=null&& ste.getMethodName !=null&&!ste.getMethodName.contains("getStackTrace")){if(insideSpark){if(skipClass(ste.getClassName)){
lastSparkMethod =if(ste.getMethodName =="<init>"){// Spark method is a constructor; get its class name
ste.getClassName.substring(ste.getClassName.lastIndexOf('.')+1)}else{
ste.getMethodName
}
callStack(0)= ste.toString // Put last Spark method on top of the stack trace.}else{if(ste.getFileName !=null){
firstUserFile = ste.getFileName
if(ste.getLineNumber >=0){
firstUserLine = ste.getLineNumber
}}
callStack += ste.toString
insideSpark =false}}else{
callStack += ste.toString
}}}val callStackDepth = System.getProperty("spark.callstack.depth","20").toInt
val shortForm =if(firstUserFile =="HiveSessionImpl.java"){// To be more user friendly, show a nicer string for queries submitted from the JDBC// server."Spark JDBC Server Query"}else{s"$lastSparkMethod at $firstUserFile:$firstUserLine"}val longForm = callStack.take(callStackDepth).mkString("\n")
CallSite(shortForm, longForm)}
客户端结果:
举例:WordCount例子中,获得数据如下
最短栈:SparkContext at MyWorkCount.scala:7
最长栈:org.apache.spark.SparkContext.<init>(SparkContext.scala:76)
com.spark.MyWorkCount$.main(MyWorkCount.scala:7)
com.spark.MyWorkCount.main(MyWorkCount.scala)
二、ActiveContext取舍
// If true, log warnings instead of throwing exceptions when multiple SparkContexts are active// 如果为true,则在多个SparkContext处于活动状态时记录警告而不是引发异常 默认falseprivateval allowMultipleContexts:Boolean=
config.getBoolean("spark.driver.allowMultipleContexts",false)// In order to prevent multiple SparkContexts from being active at the same time, mark this// context as having started construction.// NOTE: this must be placed at the beginning of the SparkContext constructor.// 为了防止同时激活多个SparkContext,将此上下文标记为active。以防止多个SparkContext实例同时成为active级别的。
SparkContext.markPartiallyConstructed(this, allowMultipleContexts)val startTime = System.currentTimeMillis()private[spark]val stopped: AtomicBoolean =new AtomicBoolean(false)//断言存活的SparkCntextprivate[spark]def assertNotStopped():Unit={if(stopped.get()){val activeContext = SparkContext.activeContext.get()val activeCreationSite =if(activeContext ==null){"(No active SparkContext.)"}else{
activeContext.creationSite.longForm
}thrownew IllegalStateException(s"""Cannot call methods on a stopped SparkContext.
|This stopped SparkContext was created at:
|
|${creationSite.longForm}
|
|The currently active SparkContext was created at:
|
|$activeCreationSite
""".stripMargin)}}
正式篇
一、读取SparkConf、日志压缩配置
Spark配置类,配置已键值对形式存储,封装了一个ConcurrentHashMap类实例settings用于存储Spark的配置信息。
//copy一份配置文件
_conf = config.clone()//必要信息检查,验证提交配置项参数、提交方式
_conf.validateSettings()//检查部署模式spark.master配置if(!_conf.contains("spark.master")){thrownew SparkException("A master URL must be set in your configuration")}//检查spark.app.name配置if(!_conf.contains("spark.app.name")){thrownew SparkException("An application name must be set in your configuration")}// log out spark.app.name in the Spark driver logs 打印应用程序名称
logInfo(s"Submitted application: $appName")// System property spark.yarn.app.id must be set if user code ran by AM on a YARN cluster// 如果用户代码由AM在YARN群集上运行,则必须设置系统属性spark.yarn.app.idif(master =="yarn"&& deployMode =="cluster"&&!_conf.contains("spark.yarn.app.id")){thrownew SparkException("Detected yarn cluster mode, but isn't running on a cluster. "+"Deployment to YARN is not supported directly by SparkContext. Please use spark-submit.")}// 检查日志配置if(_conf.getBoolean("spark.logConf",false)){
logInfo("Spark configuration:\n"+ _conf.toDebugString)}// Set Spark driver host and port system properties. This explicitly sets the configuration// instead of relying on the default value of the config constant.// 设置Spark驱动程序主机和端口系统属性。这将显式设置配置而不依赖于config常量的默认值
_conf.set(DRIVER_HOST_ADDRESS, _conf.get(DRIVER_HOST_ADDRESS))
_conf.setIfMissing("spark.driver.port","0")
_conf.set("spark.executor.id", SparkContext.DRIVER_IDENTIFIER)//获取用户传入jar包//在YARN模式下,它将返回一个空列表,因为YARN 具有自己的分发jar的机制。
_jars = Utils.getUserJars(_conf)//获取用户传入的文件
_files = _conf.getOption("spark.files").map(_.split(",")).map(_.filter(_.nonEmpty)).toSeq.flatten
//事件日志目录
_eventLogDir =if(isEventLogEnabled){val unresolvedDir = conf.get("spark.eventLog.dir", EventLoggingListener.DEFAULT_LOG_DIR).stripSuffix("/")
Some(Utils.resolveURI(unresolvedDir))}else{
None
}//事件日志压缩 默认flase不压缩
_eventLogCodec ={val compress = _conf.getBoolean("spark.eventLog.compress",false)if(compress && isEventLogEnabled){
Some(CompressionCodec.getCodecName(_conf)).map(CompressionCodec.getShortName)}else{
None
}}
二、初始化LiveListenerBus
SparkContext 中的事件总线,可以接收各种使用方的事件,并且异步传递Spark事件监听与SparkListeners监听器的注册。
//创建生命周期监听总线
_listenerBus =new LiveListenerBus(_conf)// Initialize the app status store and listener before SparkEnv is created so that it gets// all events.// 在创建SparkEnv之前 初始化 应用程序状态存储 和 侦听器,以便获取所有事件
_statusStore = AppStatusStore.createLiveStore(conf)
listenerBus.addToStatusQueue(_statusStore.listener.get)
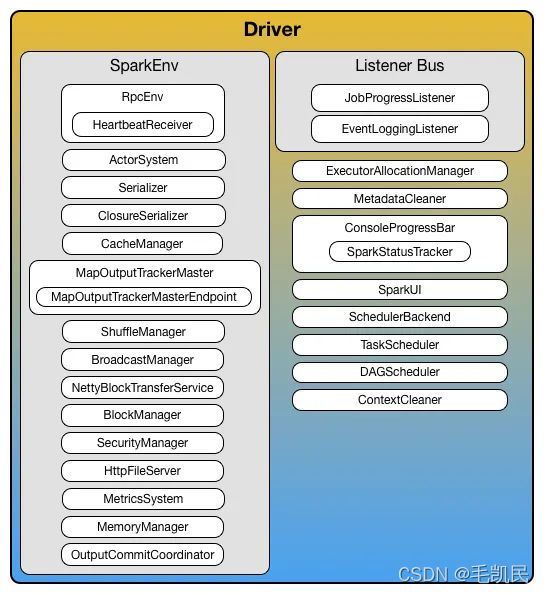
三、创建SparkENV对象(DriverENV)
SparkContext中非常重要的类,它维护着Spark的执行环境,所有的线程都可以通过SparkContext访问到同一个SparkEnv对象。包含一些rpc创建……etc.
LiveListenerBus 生命周期监听总线
// Create the Spark execution environment (cache, map output tracker, etc)// 创建SparkEev 执行环境(cache, map输出追踪器, 等等)
_env = createSparkEnv(_conf, isLocal, listenerBus)
SparkEnv.set(_env)// If running the REPL, register the repl's output dir with the file server.//REPL-> “读取-求值-输出”循环(英语:Read-Eval-Print Loop,简称REPL)指的是一个简单的,交互式的编程环境// 如果运行REPL,请向文件服务器注册repl的输出目录。
_conf.getOption("spark.repl.class.outputDir").foreach { path =>val replUri = _env.rpcEnv.fileServer.addDirectory("/classes",new File(path))
_conf.set("spark.repl.class.uri", replUri)}--------------------------------------------------------------------------private[spark]def createSparkEnv(
conf: SparkConf,
isLocal:Boolean,
listenerBus: LiveListenerBus): SparkEnv ={
SparkEnv.createDriverEnv(conf, isLocal, listenerBus, SparkContext.numDriverCores(master, conf))}
四、初始化SparkStatusTracker
低级别的状态报告API,只能提供非常脆弱的一致性机制,对Job(作业)、Stage(阶段)的状态进行监控。
//用于监视job和stage的进度//注意SparkStatusTracker中API提供非常弱的一致性语义,在Active阶段中有可能返回'None'
_statusTracker =new SparkStatusTracker(this, _statusStore)
五、初始化ConsoleProgressBar
进度条 [stage1]====================>
//说白了就是console print的那个线。。。。。。
_progressBar =if(_conf.get(UI_SHOW_CONSOLE_PROGRESS)&&!log.isInfoEnabled){
Some(new ConsoleProgressBar(this))}else{
None
}--------------------------------------------------------------------privatedef show(now:Long, stages: Seq[StageData]){val width = TerminalWidth / stages.size
val bar = stages.map { s =>val total = s.numTasks
val header =s"[Stage ${s.stageId}:"val tailer =s"(${s.numCompleteTasks} + ${s.numActiveTasks}) / $total]"val w = width - header.length - tailer.length
val bar =if(w >0){val percent = w * s.numCompleteTasks / total
(0 until w).map { i =>if(i < percent)"="elseif(i == percent)">"else" "}.mkString("")}else{""}
header + bar + tailer
}.mkString("")// only refresh if it's changed OR after 1 minute (or the ssh connection will be closed// after idle some time)if(bar != lastProgressBar || now - lastUpdateTime >60*1000L){
System.err.print(CR + bar)
lastUpdateTime = now
}
lastProgressBar = bar
}
六、创建&初始化 Spark UI
Spark监控的web平台,提供了整个生命周期的监控包括任务、环境。
//是否允许UI开启
_ui =if(conf.getBoolean("spark.ui.enabled",true)){
Some(SparkUI.create(Some(this), _statusStore, _conf, _env.securityManager, appName,"",
startTime))}else{// For tests, do not enable the UI
None
}// Bind the UI before starting the task scheduler to communicate// the bound port to the cluster manager properly// 在启动任务计划程序以将绑定的端口正确通信到集群管理器之前,先绑定UI
_ui.foreach(_.bind())//默认生成hadoop配置
_hadoopConfiguration = SparkHadoopUtil.get.newConfiguration(_conf)// Add each JAR given through the constructor// jar和file添加if(jars !=null){
jars.foreach(addJar)}if(files !=null){
files.foreach(addFile)}
七、ExecutorMemory配置
// executor内存 根据以下属性逐级查找 如果都没有的话最后使用1024MB
_executorMemory = _conf.getOption("spark.executor.memory").orElse(Option(System.getenv("SPARK_EXECUTOR_MEMORY"))).orElse(Option(System.getenv("SPARK_MEM")).map(warnSparkMem)).map(Utils.memoryStringToMb).getOrElse(1024)// Convert java options to env vars as a work around// since we can't set env vars directly in sbt.for{(envKey, propKey)<- Seq(("SPARK_TESTING","spark.testing"))
value <- Option(System.getenv(envKey)).orElse(Option(System.getProperty(propKey)))}{
executorEnvs(envKey)= value
}
Option(System.getenv("SPARK_PREPEND_CLASSES")).foreach { v =>
executorEnvs("SPARK_PREPEND_CLASSES")= v
}// The Mesos scheduler backend relies on this environment variable to set executor memory.// Mesos调度程序后端依赖于此环境变量来设置执行程序内存。// TODO: Set this only in the Mesos scheduler.
executorEnvs("SPARK_EXECUTOR_MEMORY")= executorMemory +"m"
executorEnvs ++= _conf.getExecutorEnv
executorEnvs("SPARK_USER")= sparkUser
八、注册HeartbeatReceiver
心跳接收器,所有 Executor 都会向HeartbeatReceiver 发送心跳,当其接收到 Executor 的心跳信息后,首先更新 Executor 的最后可见时间,然后将此信息交给 TaskScheduler 进一步处理。
// We need to register "HeartbeatReceiver" before "createTaskScheduler" because Executor will// retrieve "HeartbeatReceiver" in the constructor. (SPARK-6640)// 我们需要在“ createTaskScheduler”之前注册“ HeartbeatReceiver”,// 因为执行器将在构造函数中检索“ HeartbeatReceiver”。 (SPARK-6640)
_heartbeatReceiver = env.rpcEnv.setupEndpoint(
HeartbeatReceiver.ENDPOINT_NAME,new HeartbeatReceiver(this))
九、创建TaskScheduler
Spark任务调度器,负责任务的提交,并且请求集群管理器对任务调度。由于它调度的Task是有DagScheduler创建,所以DagScheduler是它的前置调度器。
val(sched, ts)= SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
十、创建&启动DAGScheduler
一个基于Stage的调度器, 负责创建 Job,将 DAG 中的 RDD 划分到不同的 Stage,并将Stage作为Tasksets提交给底层调度器TaskScheduler执行。
//创建DAGScheduler 传入当前SparkContext对象,然后又去取出taskScheduler// def this(sc: SparkContext) = this(sc, sc.taskScheduler)
_dagScheduler =new DAGScheduler(this)//绑定心跳执行器
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler's constructor// 在taskScheduler在DAGScheduler的构造函数中设置DAGScheduler引用之后,初始化TaskScheduler
_taskScheduler.start()
_applicationId = _taskScheduler.applicationId()
_applicationAttemptId = taskScheduler.applicationAttemptId()
_conf.set("spark.app.id", _applicationId)if(_conf.getBoolean("spark.ui.reverseProxy",false)){
System.setProperty("spark.ui.proxyBase","/proxy/"+ _applicationId)}
_ui.foreach(_.setAppId(_applicationId))// 啪啪啪一丢设置后 UI和任务关联
十一、初始化BlockManager
在DAGShceduler中有一个BlockManagerMaster对象,该对象的工作就是负责管理全局所有BlockManager的元数据,当集群中有BlockManager注册完成的时候,其会向BlockManagerMaster发送自己元数据信息;BlockManagerMaster会为BlockManager创建一个属于这个BlockManager的BlockManagerInfo,用于存放BlockManager的信息。
_env.blockManager.initialize(_applicationId)
十二、初始化MericsSystem
Spark webui 监控指标。包括Shuffle read/wirte gc…etc。spark运行时监控。
// The metrics system for Driver need to be set spark.app.id to app ID.// So it should start after we get app ID from the task scheduler and set spark.app.id.// 需要将驱动程序的指标系统设置为spark.app.id到应用程序ID。// 因此,它应该在我们从任务计划程序获取应用程序ID并设置spark.app.id之后开始。//启动指标监控系统 gc时间,shuffler read/write...etc.
_env.metricsSystem.start()// Attach the driver metrics servlet handler to the web ui after the metrics system is started.// 启动指标系统后,将驱动程序指标servlet处理程序附加到Web ui。
_env.metricsSystem.getServletHandlers.foreach(handler => ui.foreach(_.attachHandler(handler)))
十三、创建EventLoggingListener
事件监听器将各种事件进行json转换
//创建事件日志监听 添加到总线列队中去(总线列队后面会详细讲~~~)
_eventLogger =if(isEventLogEnabled){val logger =new EventLoggingListener(_applicationId, _applicationAttemptId, _eventLogDir.get,
_conf, _hadoopConfiguration)
logger.start()
listenerBus.addToEventLogQueue(logger)
Some(logger)}else{
None
}
十四、创建&启动资源划分管理器
根据配置判断是否开启动态资源管理器
// Optionally scale number of executors dynamically based on workload. Exposed for testing.// 可以根据工作负载动态伸缩执行器的数量spark.dynamicAllocation.enabledval dynamicAllocationEnabled = Utils.isDynamicAllocationEnabled(_conf)
_executorAllocationManager =if(dynamicAllocationEnabled){
schedulerBackend match{case b: ExecutorAllocationClient =>
Some(new ExecutorAllocationManager(
schedulerBackend.asInstanceOf[ExecutorAllocationClient], listenerBus, _conf,
_env.blockManager.master))case _ =>
None
}}else{
None
}
_executorAllocationManager.foreach(_.start())
十五、创建ContextCleaner
上下文清理器,为RDD、shuffle、broadcast状态的异步清理器,清理超出应用范围的RDD、ShuffleDependency、Broadcast对象。
//根据spark.cleaner.referenceTracking 默认是true 创建ContextCleaner
_cleaner =if(_conf.getBoolean("spark.cleaner.referenceTracking",true)){
Some(new ContextCleaner(this))}else{
None
}
_cleaner.foreach(_.start())
十六、ExtraListeners配置
setupAndStartListenerBus()
十七、环境更新
postEnvironmentUpdate()---------------------------------------------------------------//环境更新,这个就是在UI Environment界面显示的数据privatedef postEnvironmentUpdate(){if(taskScheduler !=null){val schedulingMode = getSchedulingMode.toString
val addedJarPaths = addedJars.keys.toSeq
val addedFilePaths = addedFiles.keys.toSeq
val environmentDetails = SparkEnv.environmentDetails(conf, schedulingMode, addedJarPaths,
addedFilePaths)val environmentUpdate = SparkListenerEnvironmentUpdate(environmentDetails)
listenerBus.post(environmentUpdate)}}
十八、投递程序启动事件
postApplicationStart()--------------------------------------------------------------//主要关注post方法,发送事件。同样关注start() stop()privatedef postApplicationStart(){// Note: this code assumes that the task scheduler has been initialized and has contacted// the cluster manager to get an application ID (in case the cluster manager provides one).
listenerBus.post(SparkListenerApplicationStart(appName, Some(applicationId),
startTime, sparkUser, applicationAttemptId, schedulerBackend.getDriverLogUrls))}
十九、最后绑定注册
//关注postStartHook
_taskScheduler.postStartHook()
_env.metricsSystem.registerSource(_dagScheduler.metricsSource)
_env.metricsSystem.registerSource(new BlockManagerSource(_env.blockManager))
_executorAllocationManager.foreach { e =>
_env.metricsSystem.registerSource(e.executorAllocationManagerSource)
二十、结束清理
// Make sure the context is stopped if the user forgets about it. This avoids leaving// unfinished event logs around after the JVM exits cleanly. It doesn't help if the JVM// is killed, though.// 如果用户忘记上下文,请确保上下文已停止。这样可以避免在JVM干净退出之后// 保留未完成的事件日志。但是,如果杀死了JVM 则无济于事
logDebug("Adding shutdown hook")
_shutdownHookRef = ShutdownHookManager.addShutdownHook(
ShutdownHookManager.SPARK_CONTEXT_SHUTDOWN_PRIORITY){()=>
logInfo("Invoking stop() from shutdown hook")try{
stop()}catch{case e: Throwable =>
logWarning("Ignoring Exception while stopping SparkContext from shutdown hook", e)}}}catch{case NonFatal(e)=>
logError("Error initializing SparkContext.", e)try{
stop()}catch{case NonFatal(inner)=>
logError("Error stopping SparkContext after init error.", inner)}finally{throw e
}}
总结
- Spark 中的组件很多,涉及网络通信、分布式、消息、存储、计算、缓存、测量、清理、文件服务、Web UI 的方方面面。
- Spark中大量采用事件监听方式,实现driver端的组件之间的通信。
欢迎关注公众号: 857Hub
版权归原作者 毛凯民 所有, 如有侵权,请联系我们删除。