
冯诺依曼体系
🥖冯·诺依曼结构也称普林斯顿结构,是一种将程序指令存储器和数据存储器合并在一起的存储器结构。
🥖其主要内容点明了计算机制造的三个基本原则,即采用二进制逻辑、程序存储执行以及计算机由五个部分组成(运算器、控制器、存储器、输入设备、输出设备)。
🥖而现如今的计算机,如笔记本、服务器,大部分都遵守冯诺依曼体系。
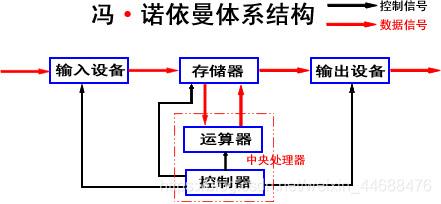
我们认识的计算机都是由这样一个个硬件组成的:
- 运算器和控制器:中央处理器(CPU) 。
- 存储器:内存。
- 输入设备:键盘, 鼠标,扫描仪,网卡等。
- 输出设备:显示器,打印机等。
注意
- 这里的存储器指的是内存而不是磁盘。
- 不考虑缓存情况,这里的CPU能且只能对内存进行读写,不能访问外设(输入或输出设备)。(CPU只与内存打交道)
- 外设(输入或输出设备)要输入或者输出数据,也只能写入内存或者从内存中读取。 (在数据层面上,外设只与内存打交道)
🥖因此,当外部由输入设备传入数据时会先将数据传到内存之中,之后 **CPU **对内存中的数据进行处理之后再将输出的数据加载到内存之中,最后由输出设备进行输出。
为什么CPU不直接访问输入或输出设备?
🥖由于外设的速度较慢,而 CPU 读取数据并处理数据的速度是很快的,若 CPU 直接访问外设,就像拿一个有短板的木桶去打水,那无论其他木板有多长最终打的水的高度都不会超过那块短板,所以总体的速度将会以外设为主,将导致 **CPU **性能的浪费。
跨主机间数据的传递
🥖那我们在网络中与他人交互时,数据流是怎样流动的。就拿QQ/微信举例吧,当信息从聊天框发送出去之后,便被加载到了内存之中,经过计算之后通过显示屏输出呈现给我们,并通过网卡将数据传给朋友,朋友的网卡接收了网络上的数据,并将其加载到了内存之中,经CPU计算后在显示屏上输出,如此便完成了信息的传递。

操作系统
🥖操作系统包括了:内核(进程管理,内存管理,文件管理,驱动管理)和 其他程序(例如函数库, shell程序等等)
🥖本质上是一款对软硬件进行资源管理的软件。
管理
🥖在学校里,校长是管理者,而我们学生是被管理者,校长只负责决策并不需要尽到执行的义务,假如校长安排你转一个专业或者换一个宿舍,他并不需要见到你,而是对你的数据进行修改便可,之后的辅导员便会协助你调整。即管理者和被管理者是不需要直接沟通的。
🥖并且辅导员将协助校长拿到学生的信息,校长并不需要与学生直接接触,而是管理学生的数据就能够实现对学生的管理。
因此,管理的本质便是对被管理者的数据做管理。
🥖那么校长是如何对学生进行管理的?首先需要先对学生这个个体进行描述,如学号、姓名、专业、班级等信息,之后再以数据结构的方式将所有的学生连接在一起集中管理。如此对全校学生的管理就转变成了对数据结构的管理了。如此方法就称作“先描述,后组织 。”
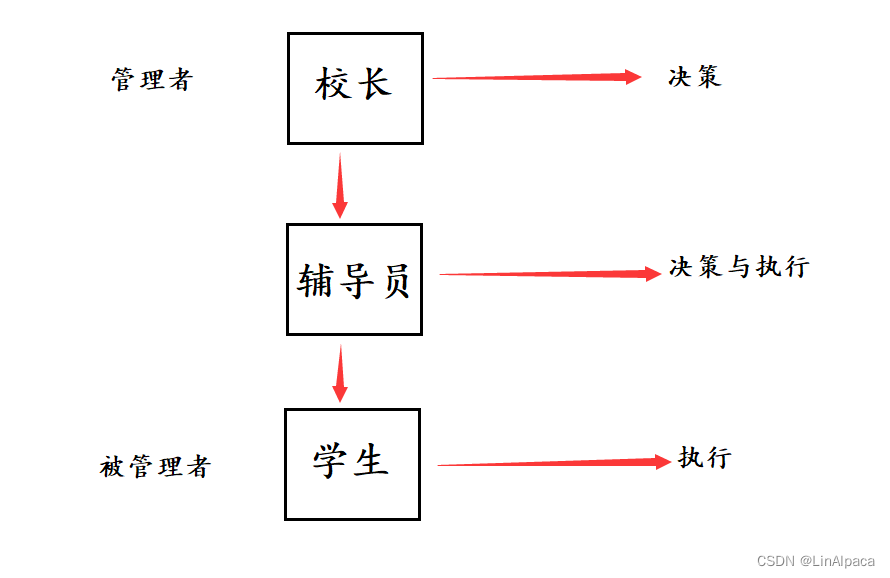
🥖将这个过程放到操作系统之中也同样适用,操作系统就是校长,硬件驱动就是辅导员、而学生就是被管理的软硬件。即硬件驱动与硬件交互之后拿到了相关的数据转交给操作系统,而操作系统做完决策之后再将新的命令传递驱动进行执行。并通过“先描述,再组织”的方式,以数据结构的形式对硬件进行管理。
🥖由此操作系统对下管理好软硬件资源,对上给用户提供良好(安全、稳定、高效、功能丰富等) 的执行环境。
🥖更重要的一点是:操作系统是不相信任何人的,正如我们是银行的用户,经常去银行存钱,但银行就信任我们吗?为了避免用户中有人恶意破坏,而对操作系统造成伤害, 所以操作系统并不是暴露自己的全部功能而是以系统调用来访问操作系统。由于系统调用的使用成本可能较高,之后在此基础上便有人进行二次的软件开发而产生了图形化界面和 shell 及工具集。
系统调用与库函数
🥖在开发角度,操作系统对外会表现为一个整体,但是会暴露自己的部分接口,供上层开发使用,这部分由操作系统提供的接口,叫做系统调用。
系统调用在使用上,功能比较基础,对用户的要求相对也比较高,所以,有心的开发者可以对部分系统调用进行适度封装,从而形成库,有了库,就很有利于更上层用户或者开发者进行二次开发。
进程
🥖基本概念:**程序的一个执行实例 ,正在执行的程序 **。在内核观点中便是担当分配系统资源(CPU时间,内存)的实体。
🥖所以以前的任何启动并运行程序的行为,都是由系统将程序转化为进程后,再来完成特定的任务。
我们打开任务管理器便会发现这些正在运行的可执行文件都是一个个进程。

描述进程
🥖进程信息被放在一个叫做进程控制块的数据结构中,是进程属性的集合。通常称之为PCB(process control block),而** Linux **操作系统下的 **PCB **是: task_struct。是 **Linux **内核的一种数据结构,它会被装载到 **RAM **(内存)里并且包含着进程的信息。
task_ struct内容分类
- 标示符: 描述本进程的唯一标示符,用来区别其他进程。
- 状态: 任务状态,退出代码,退出信号等。
- 优先级: 相对于其他进程的优先级。
- 程序计数器: 程序中即将被执行的下一条指令的地址。
- 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
- 上下文数据: 进程执行时处理器的寄存器中的数据[休学例子,要加图CPU,寄存器]。
- I/ O状态信息: 包括显示的I/O请求,分配给进程的I/ O设备和被进程使用的文件列表。
- 记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
- 其他信息
🥖从上面我们知道,操作系统在管理对象时进行的都是 **“先描述,再组织” **的方式,而 **PCB **正是用于描述进程的,且最终对进程的管理转化为对一个个 **PCB **连接而成的链表的管理。正如一个学生只有被登记在学校的档案里才能称其为这个学校的学生,而不是在这个学校里的人就叫作这个学校的学生。由此只有一个可执行文件被加载到内存之中,描述出其属性并能够对其做管理。这样才算完成对进程的建模。
由此可得进程 = 内核关于进程的相关数据结构 + 当前进程的代码和数据。

进程的查看和终止
🥖为了进程可以持续地进行,于是我们写一个无限循环的代码,作为样本进行观察。

🥖我们将这个代码运行后,再打开一个新的会话窗口, 之后输入指令便可查询该进程的信息。
ps axj | head -1 && ps axj | grep 进程名
- ps axj :显示所有进程。
- | :管道,将所有进程的这个信息转移到下一个命令。
- head -1 :显示第一行。
- grep : 进程名 :筛选以进程名为关键字进行筛选。
- && :可以像C语言里面那样理解,即要执行左边的命令又要执行右边的命令。
🥖当这串命令执行之后,你会发现出现了两个进程。 这是由于,当我们查找进程时使用的命令也会在操作系统的处理下变成一个进程,同时也包含了进程名的关键字,所以在输出的时候才出现了两个进程。但第一个才是我们程序运行所产生的进程。

🥖这里不得不介绍一下 PID 和 PPID 了,每个进程运行之时都会有属于自己的一个 **PID **,就相当于这个进程的身份证号码,若一个进程来源于另一个进程就用父子进程来称呼彼此,而 **PPID **则是这个进程的父进程的 **PID **。
🥖第二种方法则是直接在系统文件夹之下查找,我们事先得到进程的 **PID **之后,在 **proc **文件夹下找到目标进程的目录,便可以看到该进程的具体属性。
ll /proc/进程的PID
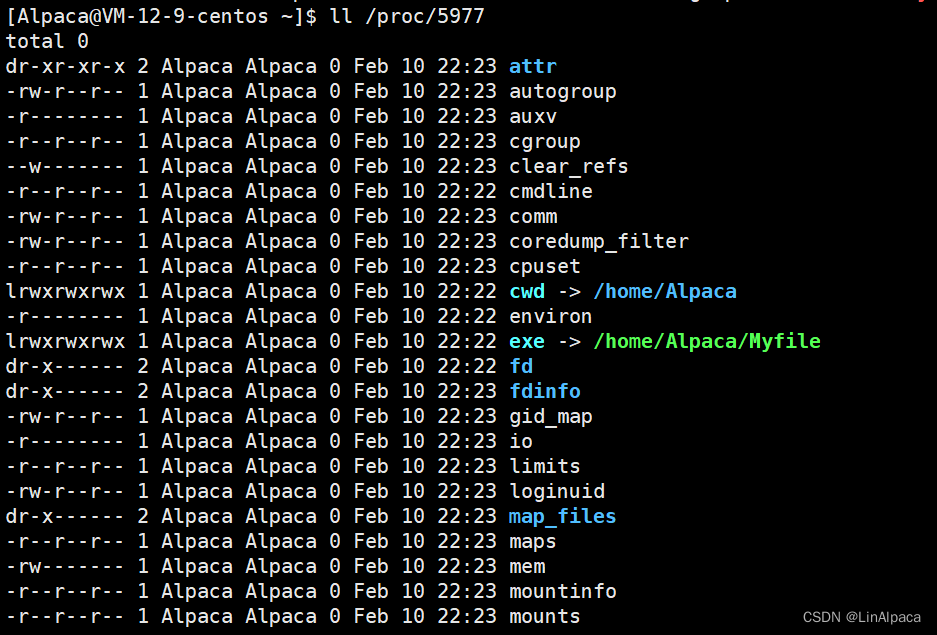
🥖值得注意的是:
进程信息必须在进程运行之时查看,由于进程结束之后系统便会删除其相关数据,由此在进程停止运行时是无法查询到该进程的数据的。

** 杀死进程**
🥖有两种方法,第一种是 CTRL+c ,这个方法也适用于平时不小心按到一些输入框,导致无论按什么键都无法退出该状态,这个时候就可以尝试按下 CTRL+c 便会强制结束进程。

🥖第二种是 kill -9 PID,在另一个会话中输入该命令,指定目标进程杀死,便可终止该进程的进行。

🥖同时我们还可以通过系统调用来获取进程的 **PID **跟 **PPID **,只需要将代码修改一下,包上头文件 **<sys/types.h> **,之后使用 **getpid () **就可以得到当前进程的 **PID **,同理获取 **PPID 则是getppid() **。

🥖之后我们反复地运行和结束程序,我们可以看到程序的 **PID **是一直在改变的,而其 **PPID **始终没有发生改变。当我们顺着这个 **PPID **找回去时,我们发现这个进程的名字叫做 **bash **。
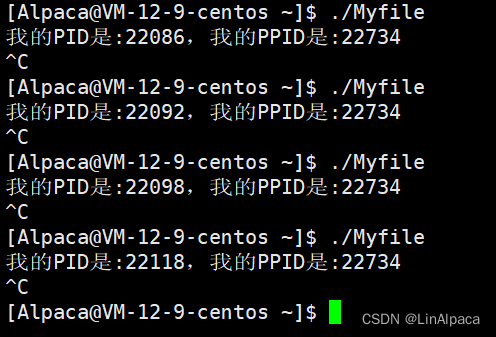
bash
🥖 **Bash **是一个命令处理器,通常运行于文本窗口中,并能执行用户直接输入的命令,作为一个中间人协助我们与操作系统对话。本质上其实也是一个进程。那我们现在便知道我们运行的这个进程便是由 **bash **创建出来的子进程,那我们能否也能够自己创建一个子进程出来呢?答案是当然可以。

通过系统调用创建子进程
🥖先了解一下 **fork **函数,根据文本 **fork **函数会为我们创建一个子进程,之后返回一个 **pid_t **类型的值,不需要传参数,子进程时其返回值是 **0 **,返而返回给父进程子进程的 **PID **,返回 **-1 **则代表创建失败。
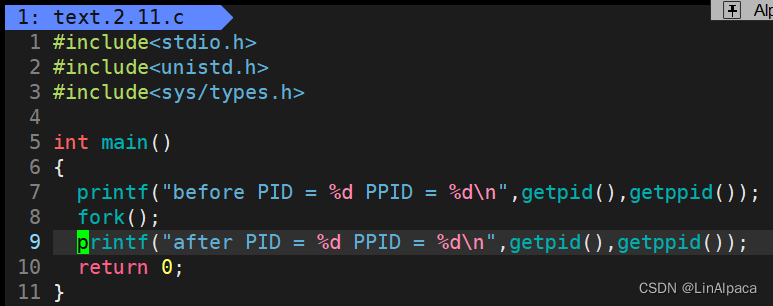
🥖像这样修改代码之后,可以观察到最后的打印出现两次,说明此时为两个进程,而 **PID **与 **PPID **恰好说明二者是父子进程的关系。
🥖运行出来的结果恰好印证了手册中对 **fork() **的描写,当前进程在遇到 **fork() **时会分成两个执行流,并走完接下来的代码。


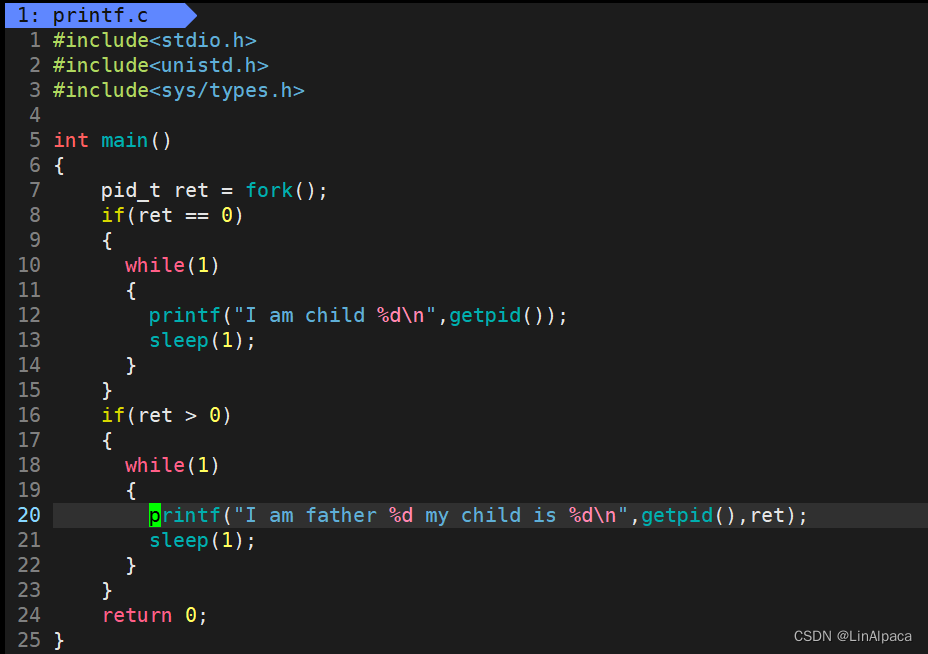
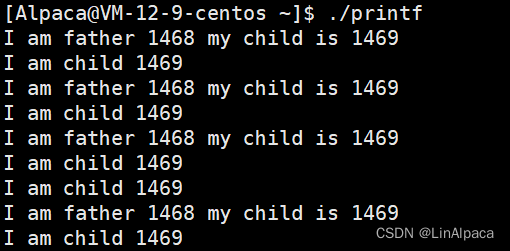
🥖为了让父子进程执行不同的代码块,我们可以用 if else 将父子进程分开从而进行不同的工作。
🥖返回值为 0 时则说明此时的进程为子进程,父进程时的返回值则是子进程的PID于是根据返回值的不同,我们便可以将子进程与父进程区分开来。
fork的辨析
fork做了什么?
🥖自然是创建一个新的进程,我们都知道,进程 = 内核关于进程的相关数据结构 + 当前进程的代码和数据。若要创建一个新的进程,自然还需要为其创建一个 **pcb **来描述这个进程,由于其来源于父进程,实际上也就是由父进程的 **pcb 拷贝了一份过来,之后二者都指向了同一份代码和数据。即二者在 fork() **之后的代码共享。
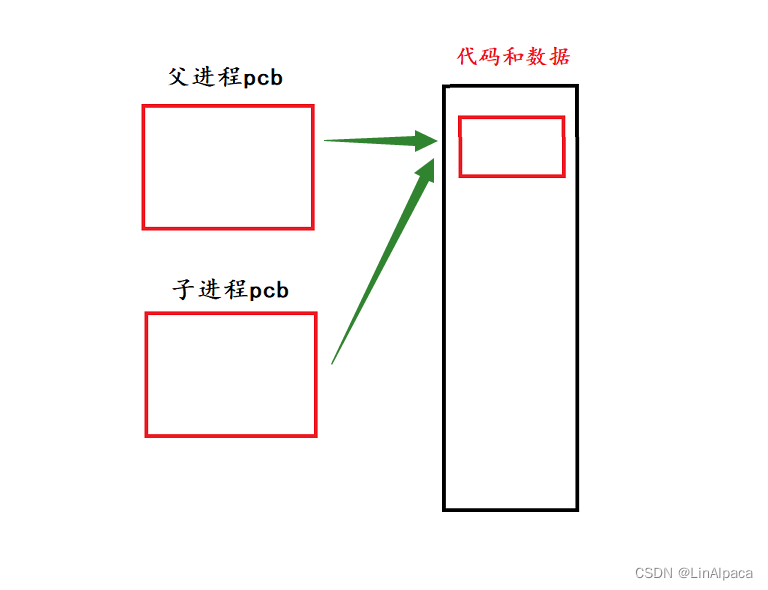
如何看待代码和数据
🥖进程在运行的时候是具有独立性的,如上面产生了一对父子进程,在运行之时停止其中一个,另外一个进程并不会收到影响。
🥖其中还分为了两部分:
🥖代码:代码是只读的,在进程运行之时是不会收到影响的。
🥖数据:当有一个执行流尝试修改数据的时候,OS会自动触发写时拷贝,新开辟空间供其修改数据。
如何理解两个返回值
🥖当 fork() 要对值进行返回的时候,其实在函数的内部创建子进程的工作已经完成,此时已经有了两个进程,两个进程继续执行下面的语句,执行完 **fork() **之后自然都会有返回值,这样在我们看来就好像有两个返回值,实则我们在接收返回值时便已触发了写时拷贝,看似相同的 **ret **实则储存在不同的空间。
🥖好了,这次操作系统与进程的概念就到这里结束了,关注博主一起学习,共同进步!! !
版权归原作者 LinAlpaca 所有, 如有侵权,请联系我们删除。