
数据清洗
数据清洗是指对数据进行重新审查和校验的过程中,发现并纠正数据文件中可识别的错误,按照一定的规则把错误或冲突的数据洗掉,包括检查数据一致性,处理无效值和缺失值等。
清洗要求
编写Scala代码,使用Spark将ods库中相应表数据全量抽取到Hive的dwd库中对应表中。表中有涉及到timestamp类型的,均要求按照yyyy-MM-dd HH:mm:ss,不记录毫秒数,若原数据中只有年月日,则在时分秒的位置添加00:00:00,添加之后使其符合yyyy-MM-dd HH:mm:ss。(若dwd库中部分表没有数据,正常抽取即可)
抽取ods库中user_info表中昨天的分区数据,并结合dim_user_info最新分区现有的数据, 根据id合并数据到dwd库中dim_user_info的分区表(合并是指对dwd层数据进行插入或修改,需修改的数据以id为合并字段, 根据operate_time排序取最新的一条),分区字段为etl_date且值与ods库的相对应表该值相等,同时若operate_time为空,则用create_time填充, 并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”。若该条记录第一次进入数仓dwd层则dwd_insert_time、dwd_modify_time均存当前操作时间,并进行数据类型转换。若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变,dwd_modify_time存当前操作时间,其余列存最新的值。 使用hive cli执行show partitions dwd.dim_user_info命令。
清洗准备
按要求全量抽取到dwd库中
编写sparkAPI 进行数据处理
Logger.getLogger("org").setLevel(Level.OFF)
System.setProperty("HADOOP_USER_NAME","root")
val sparkconf=new SparkConf()
.setAppName("qingxi")
.setMaster("local[*]")
val sparkSession=SparkSession.builder()
.config(sparkconf)
.config("hive.metastore.uris","thrift://bigdata1:9083")
.config("dfs.client.use.datanode.hostname","true")
.config("spark.sql.parquet.writeLegacyFormat","true")
.enableHiveSupport()
.getOrCreate()
根据题目要求,使用Spark将ods库中相应表数据全量抽取到Hive的dwd库中对应表中
清洗代码
sparkSession.read.table("ods.user_info")
.withColumn("dwd_insert_user",lit("user1"))
.withColumn("dwd_insert_time",to_timestamp(from_unixtime(unix_timestamp(),"yyyy-MM-dd HH:mm:ss")))
.withColumn("dwd_modify_user",lit("user1"))
.withColumn("dwd_modify_time",to_timestamp(from_unixtime(unix_timestamp(),"yyyy-MM-dd HH:mm:ss")))
.withColumn("birthday",to_timestamp(from_unixtime(unix_timestamp(col("birthday"),"yyyy-MM-dd HH:mm:ss"))))
.write
.mode(SaveMode.Overwrite)
.partitionBy("etl_date")
.saveAsTable("dwd.dim_user_info")
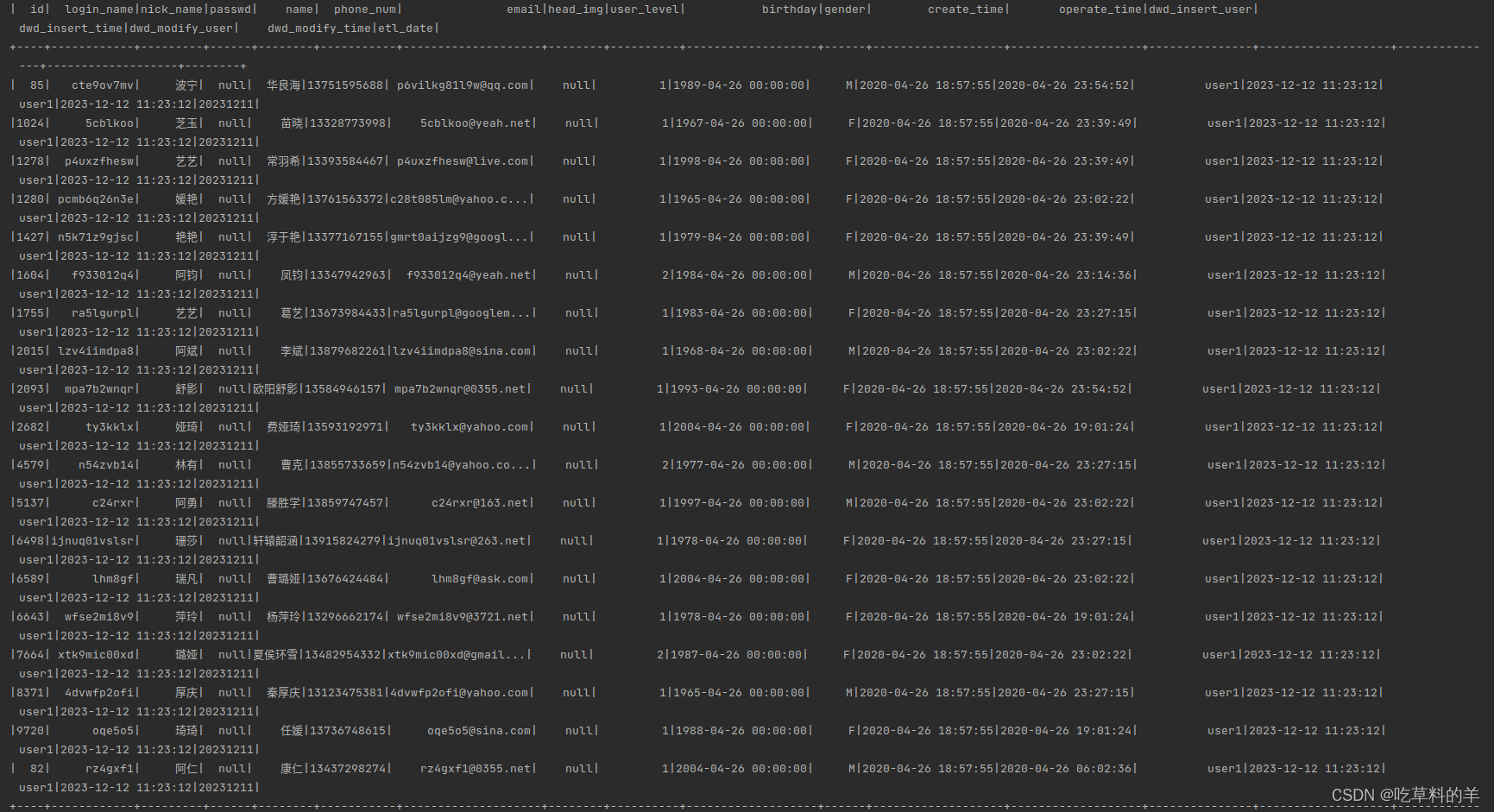
查看抽取内容
sparkSession.sql("select * from dwd.dim_user_info").show()
增量清洗
清洗ods 库中user_info 表数据
清洗代码
val ods_user_info=sparkSession.table("ods.user_info")
.withColumn("dwd_insert_user",lit("user1"))
.withColumn("dwd_insert_time",to_timestamp(from_unixtime(unix_timestamp(),"yyyy-MM-dd HH:mm:ss")))
.withColumn("dwd_modify_user",lit("user1"))
.withColumn("dwd_modify_time",to_timestamp(from_unixtime(unix_timestamp(),"yyyy-MM-dd HH:mm:ss")))
.withColumn("birthday",to_timestamp(from_unixtime(unix_timestamp(col("birthday"),"yyyy-MM-dd HH:mm:ss"))))
.withColumn("operate_time",when(col("operate_time").isNull,col("create_time")).otherwise(col("operate_time")))
.withColumn("etl_date",lit("20231211"))
将dwd库中dim_user_info表给到变量dwd_user_info
val dwd_user_info = sparkSession.table("dwd.dim_user_info")
将两个表内容合并
val union_table=ods_user_info.select(dwd_user_info.columns.map(col):_*).union(dwd_user_info)
.withColumn("sortId",row_number().over(Window.partitionBy("id").orderBy(desc("operate_time"))))
.withColumn("dwd_insert_time",lead("dwd_insert_time",1).over(Window.partitionBy("id").orderBy(desc("dwd_modify_time"))))
.withColumn("dwd_insert_time",when(col("dwd_insert_time").isNull,col("dwd_modify_time")).otherwise(col("dwd_insert_time")))
左连接去重,把旧数据删掉
val new_data=union_table.filter(col("sortId")===1).as("new_data")
val old_data=union_table.filter(col("sortId")===2).as("old_data")
new_data.join(old_data,new_data("id")===old_data("id"),"left")
.select("new_data.*")
.drop("sortId")
.write
.mode(SaveMode.Overwrite)
.saveAsTable("dwd.zhang_dim_user_info")
完整代码
package qingxi.zengliang
import org.apache.hadoop.hive.ql.parse.WindowingSpec.WindowSpec
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.{SaveMode, SparkSession}
import org.apache.spark.sql.functions.{col, desc, format_string, from_unixtime, lead, lit, row_number, to_timestamp, unix_timestamp, when}
/**
* 抽取ods库中user_info表中昨天的分区数据,并结合dim_user_info最新分区现有的数据,
* 根据id合并数据到dwd库中dim_user_info的分区表(合并是指对dwd层数据进行插入或修改,需修改的数据以id为合并字段,
* 根据operate_time排序取最新的一条),分区字段为etl_date且值与ods库的相对应表该值相等,同时若operate_time为空,则用create_time填充,
* 并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”。
* 若该条记录第一次进入数仓dwd层则dwd_insert_time、dwd_modify_time均存当前操作时间,
* 并进行数据类型转换。若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变,dwd_modify_time存当前操作时间,其余列存最新的值。
* 使用hive cli执行show partitions dwd.dim_user_info命令,
*/
object Test01 {
def main(args: Array[String]): Unit = {
//sparkAPI 编写
Logger.getLogger("org").setLevel(Level.OFF)
System.setProperty("HADOOP_USER_NAME","root")
val sparkconf=new SparkConf()
.setAppName("qingxi")
.setMaster("local[*]")
val sparkSession=SparkSession.builder()
.config(sparkconf)
.config("hive.metastore.uris","thrift://bigdata1:9083")
.config("dfs.client.use.datanode.hostname","true")
.config("spark.sql.parquet.writeLegacyFormat","true")
.enableHiveSupport()
.getOrCreate()
//清洗dwd.dim_user_info
// sparkSession.read.table("ods.user_info")
// .withColumn("dwd_insert_user",lit("user1"))
// .withColumn("dwd_insert_time",to_timestamp(from_unixtime(unix_timestamp(),"yyyy-MM-dd HH:mm:ss")))
// .withColumn("dwd_modify_user",lit("user1"))
// .withColumn("dwd_modify_time",to_timestamp(from_unixtime(unix_timestamp(),"yyyy-MM-dd HH:mm:ss")))
// .withColumn("birthday",to_timestamp(from_unixtime(unix_timestamp(col("birthday"),"yyyy-MM-dd HH:mm:ss"))))//若原数据中只有年月日,则在时分秒的位置添加00:00:00
// .write
// .mode(SaveMode.Overwrite)
// .partitionBy("etl_date")
// .saveAsTable("dwd.dim_user_info")
// sparkSession.sql("select * from dwd.dim_user_info").show()
//ods_user_info 这个变量放着清洗过得ods中的数据
val ods_user_info=sparkSession.table("ods.user_info")
.withColumn("dwd_insert_user",lit("user1"))
.withColumn("dwd_insert_time",to_timestamp(from_unixtime(unix_timestamp(),"yyyy-MM-dd HH:mm:ss")))
.withColumn("dwd_modify_user",lit("user1"))
.withColumn("dwd_modify_time",to_timestamp(from_unixtime(unix_timestamp(),"yyyy-MM-dd HH:mm:ss")))
.withColumn("birthday",to_timestamp(from_unixtime(unix_timestamp(col("birthday"),"yyyy-MM-dd HH:mm:ss"))))
.withColumn("operate_time",when(col("operate_time").isNull,col("create_time")).otherwise(col("operate_time")))
.withColumn("etl_date",lit("20231211"))
//dwd_user_info 这个变量存放dwd.dim_user_info过去清洗的数据
val dwd_user_info = sparkSession.table("dwd.dim_user_info")
//合并两表数据根据id分区,添加sortID字段区分新旧表,并实现dwd_insert_time时间不变
val union_table=ods_user_info.select(dwd_user_info.columns.map(col):_*).union(dwd_user_info)
.withColumn("sortId",row_number().over(Window.partitionBy("id").orderBy(desc("operate_time"))))
.withColumn("dwd_insert_time",lead("dwd_insert_time",1).over(Window.partitionBy("id").orderBy(desc("dwd_modify_time"))))
.withColumn("dwd_insert_time",when(col("dwd_insert_time").isNull,col("dwd_modify_time")).otherwise(col("dwd_insert_time")))
val new_data=union_table.filter(col("sortId")===1).as("new_data")
val old_data=union_table.filter(col("sortId")===2).as("old_data")
new_data.join(old_data,new_data("id")===old_data("id"),"left")
.select("new_data.*")
.drop("sortId")
.write
.mode(SaveMode.Overwrite)
.saveAsTable("dwd.zhang_dim_user_info")
println("表结果")
sparkSession.sql("select * from dwd.zhang_dim_user_info").show()
sparkSession.stop()
}
}
实现效果
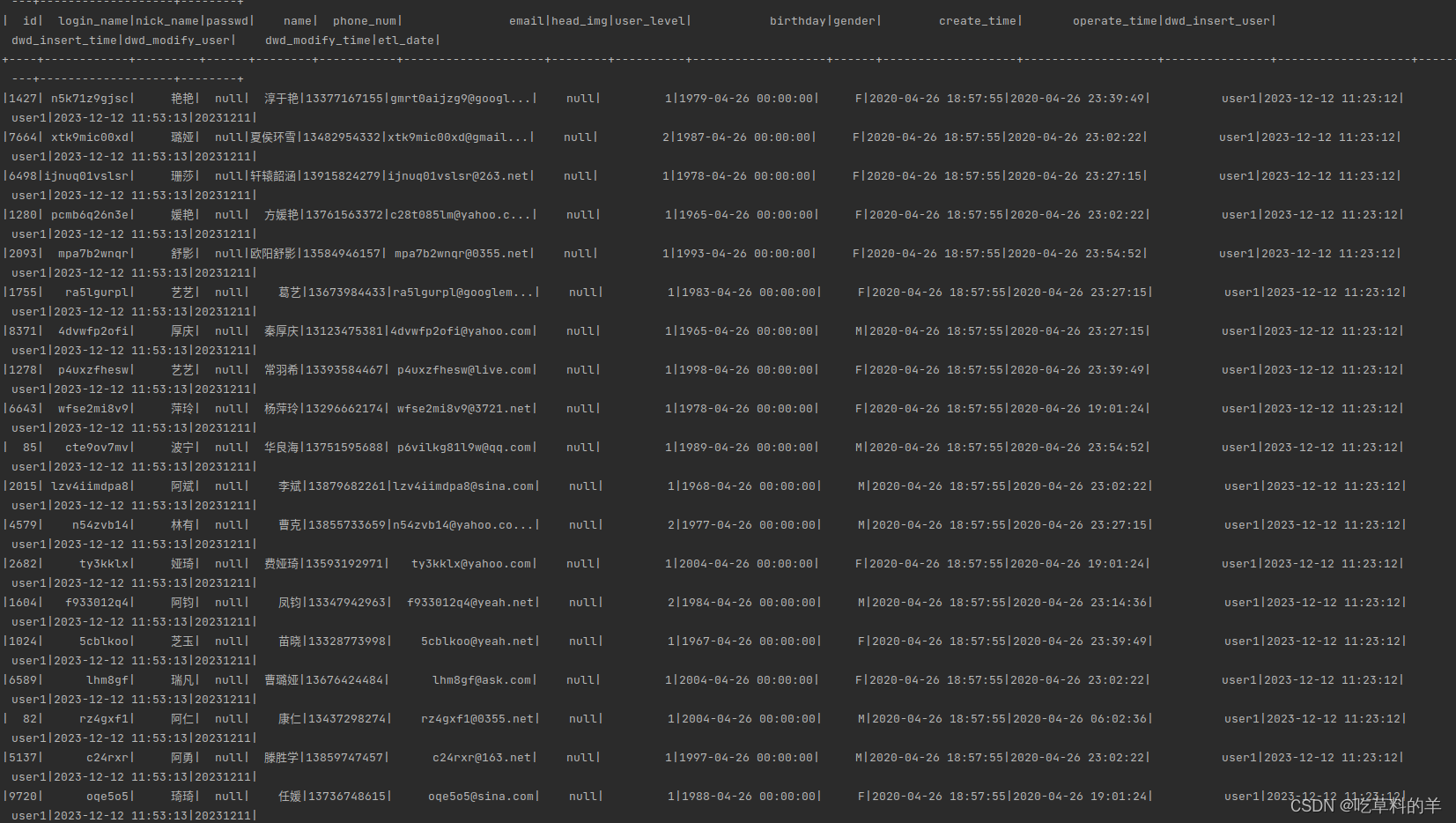
清洗完成
版权归原作者 吃草料的羊 所有, 如有侵权,请联系我们删除。