
Hadoop简介
狭义来说,hadoop是Apache基金会开发的分布式系统基础架构,用来解决海量数据的存储和海量数据的分析计算问题。广义上来说,Hadoop 通常是指一个更广泛的概念 —— Hadoop 生态圈。
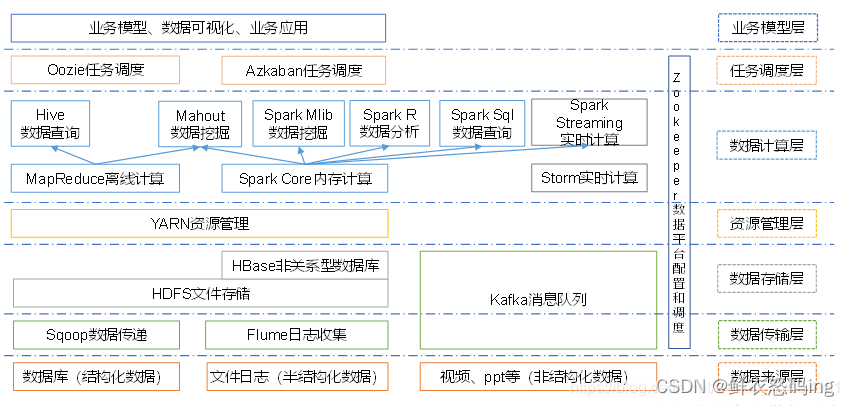
Hadoop 三大发行版本
Apache、Cloudera、Hortonworks
Apache 版本最原始(最基础)的版本,对于入门学习最好。
Cloudera在大型互联网企业中用的较多。其主要产品有CDH、Cloudera Manager,Cloudera Support
Hadoop优势
高可靠性: Hadoop 底层维护多个数据副本,所以即使 Hadoop 某个计算元素或存储出现故障,也不会导致数据的丢失。
**高扩展性: **在集群间分配任务数据,可方便的扩展数以千计的节点。
高效性: 在 MapReduce 的思想下,Hadoop 是并行工作的,以加快任务处理速度。
高容错性: 能够自动将失败的任务重新分配。
低成本:Hadoop不要求机器的配置达到极高的标准,大部分普通商用服务器即可满足要求,通过提供多个副本和容错机制提高集群的可靠性
Hadoop基本组成
常用Shell命令
hdfs dfs -ls <path>:列出指定 HDFS 路径下的文件和目录
hdfs dfs -mkdir <path>:在 HDFS 中创建新目录
hdfs dfs -put <localsrc> <dst>:将本地文件(或目录)复制到 HDFS
hdfs dfs -get <src> <localdst>:将 HDFS 上的文件(或目录)复制到本地
hdfs dfs -mv <src> <dst>:移动 HDFS 中的文件目录或重命名文件目录
hdfs dfs -cp <src> <dst>:复制 HDFS 中的文件或目录
hdfs dfs -rm <path>:删除 HDFS 中的文件
hdfs dfs -cat <path>:在控制台显示 HDFS 文件的内容
hdfs dfs -du <path>:显示 HDFS 文件或目录的大小
hdfs dfs -df <path>:显示 HDFS 的可用空间
hdfs fsck path [-files [-blocks [-location]]]
-files列出路径内的文件状态
-files -blocks输出文件块报告(几个块,几个副本)
-files -blocks -locations 输出每个block的详情
HDFS分布存储
HDFS是一个分布式文件系统,具有高容错、高吞吐 量等特性,分布在多个集群节点上的文件系统。有NN、DN、SNN三种角色。
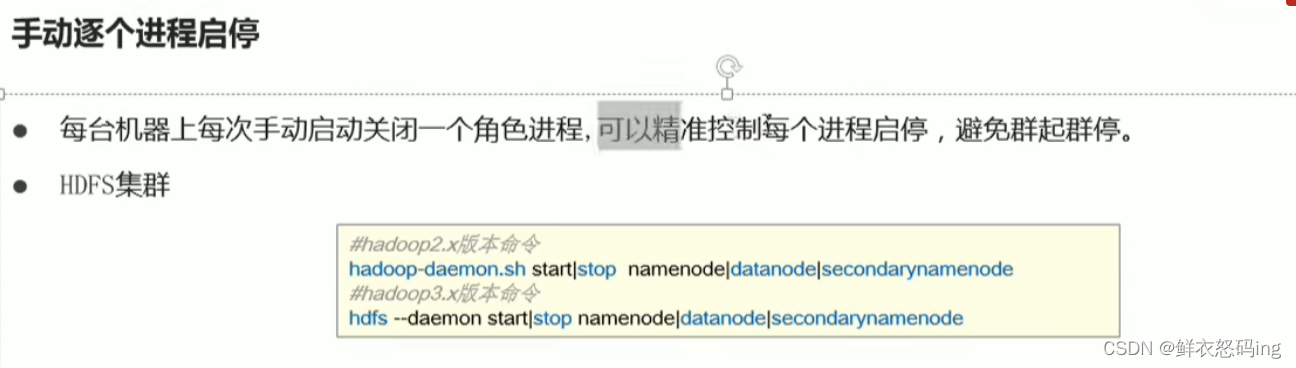
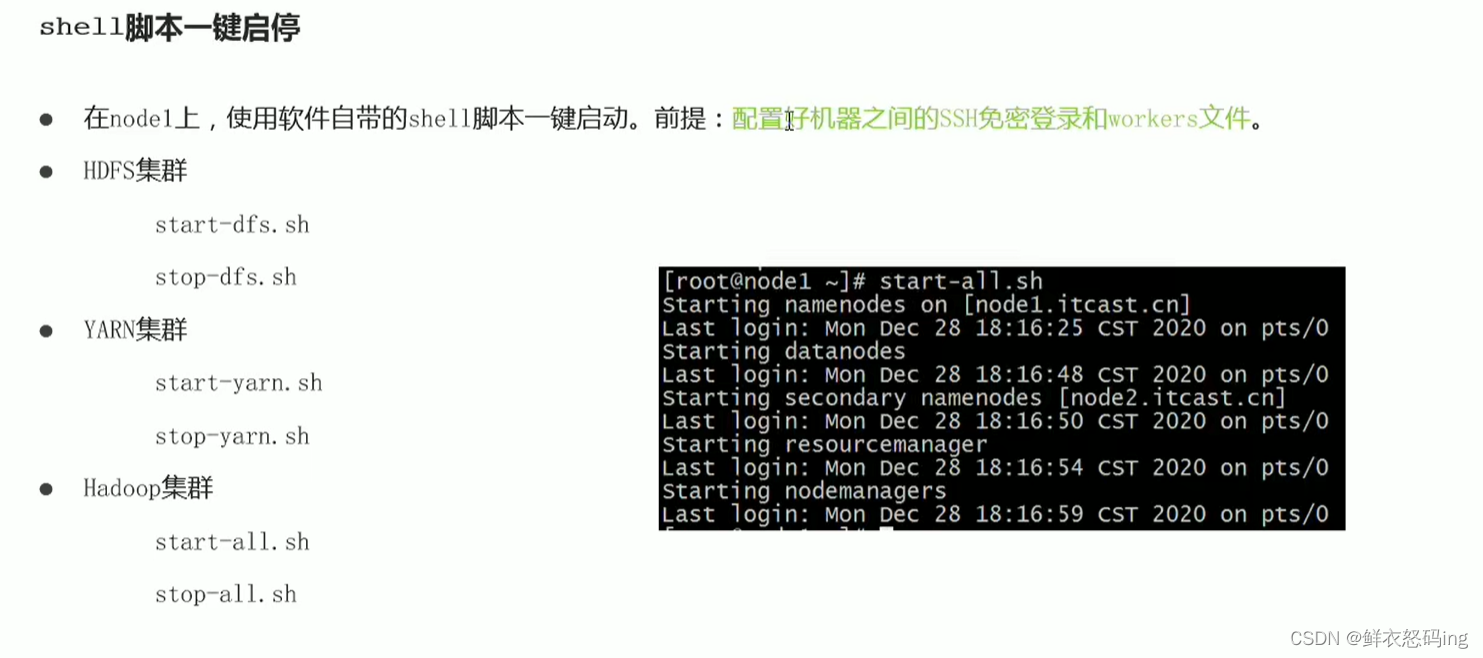
HDFS启停
NameNode(NN)
HDFS的主角色,负责管理每个文件的块所在的 DataNode、整个HDFS文件系统、存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限)等。
DataNode(DN)
HDFS从角色,负责处理客户端的读写请求,存储删除文件块,以及块数据校验和。
SecondaryNameNode(SNN)
NN的辅助角色,帮NN打杂,监控 HDFS 状态的辅助后台程序,每隔一段时间获取 HDFS 元数据的快照。
可通过9870端口(默认9870)访问web界面,查看集群各节点状态及信息
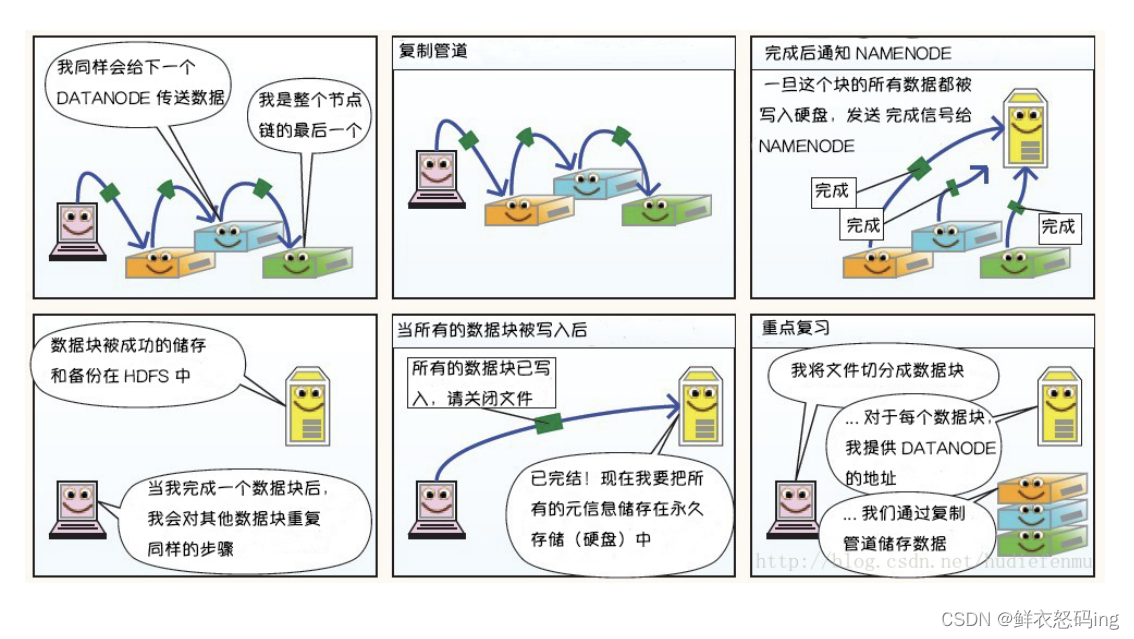
文件写入流程
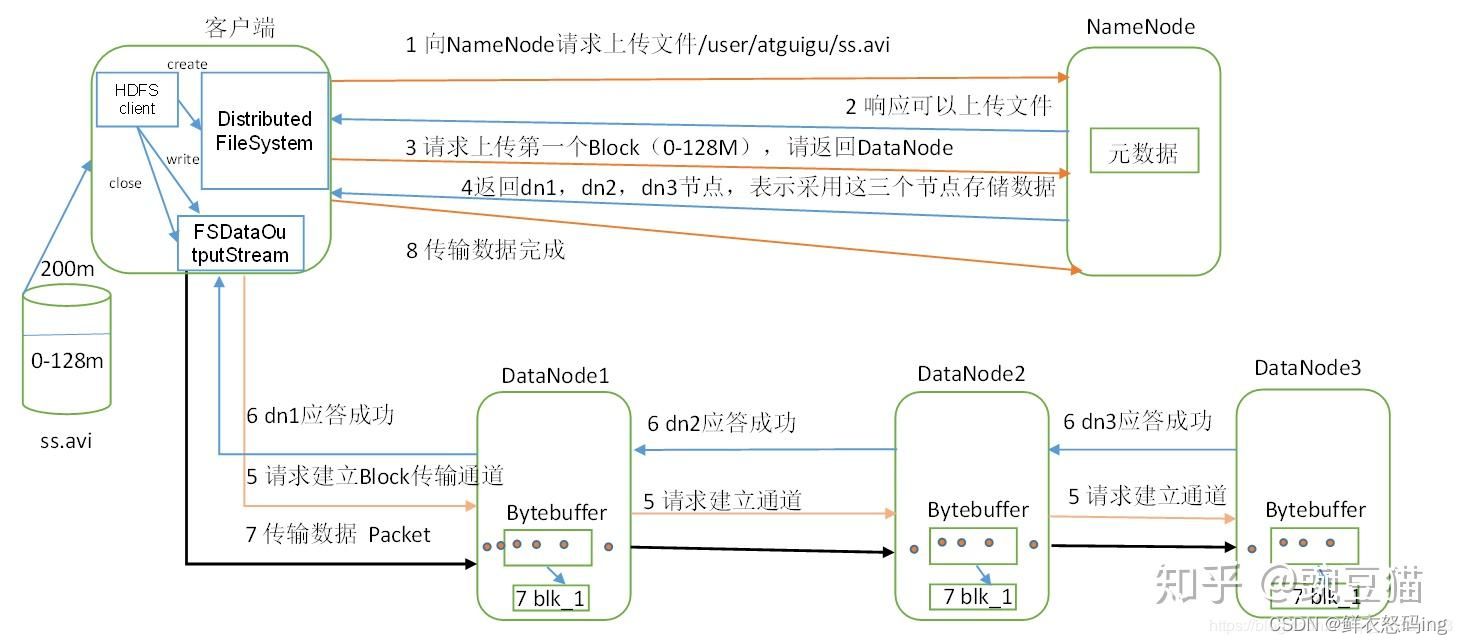
发送的写入请求通过后,客户端会根据NN返回的信息自动把数据分块,向网络距离最近的DN写入数据。同时,DN会完成备份操作,把备份传到其他的DN,然后由其他的DN再次做备份传播,直到满足设置的备份数量 。当数据写入完成后,客户端会通知NN,由NN完成元数据记录。
HDFS架构的稳定性
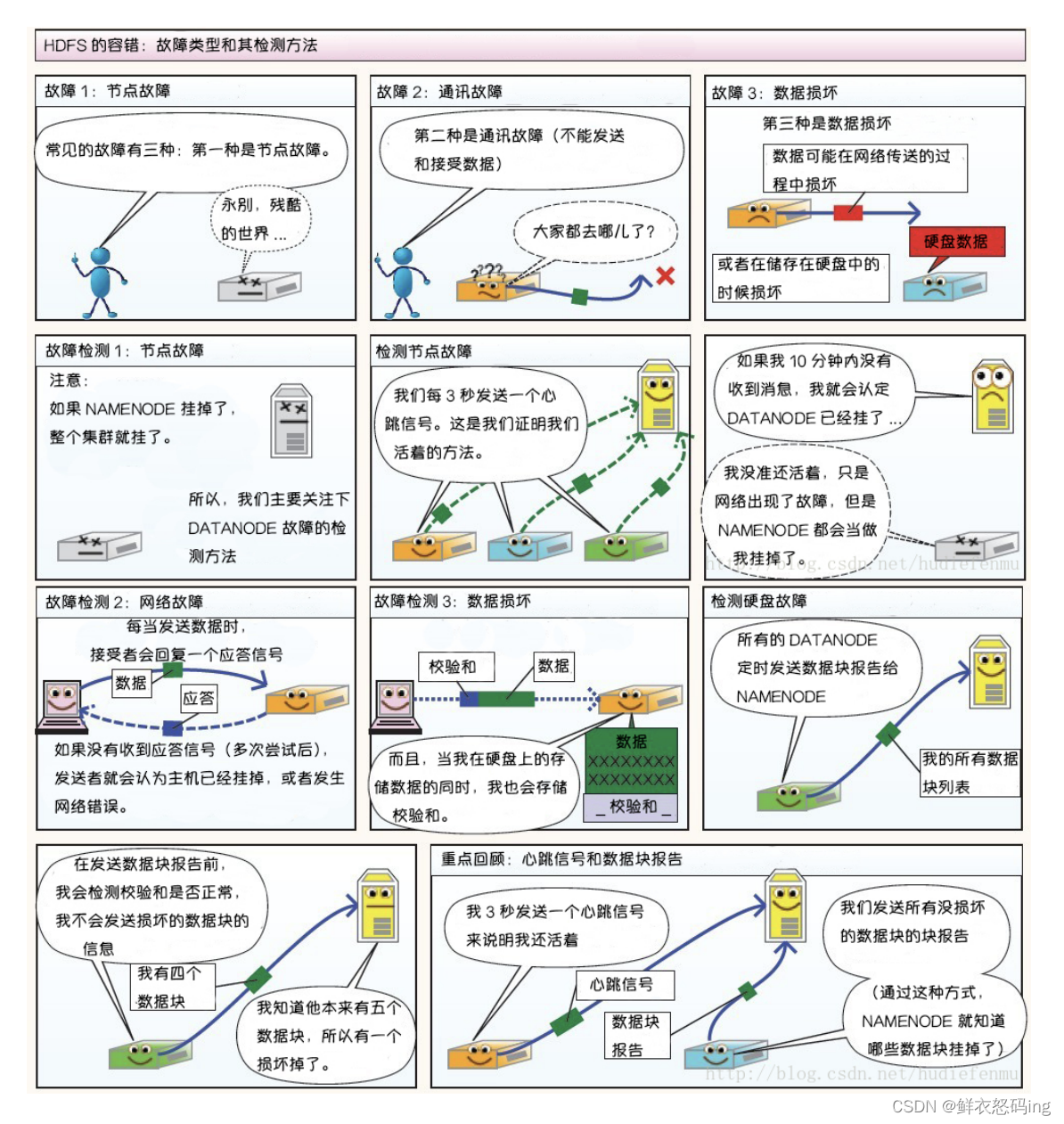
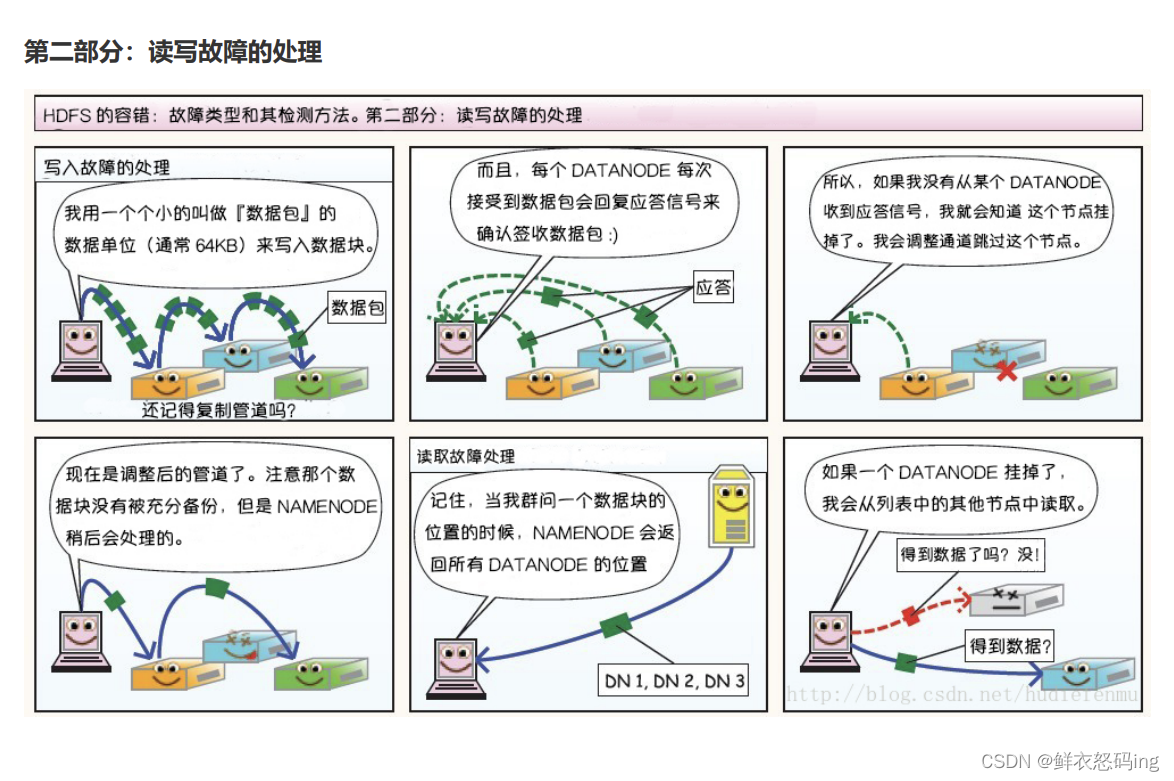
1. 心跳机制和重新复制
每个 DataNode 定期向 NameNode 发送心跳消息,如果超过指定时间没有收到心跳消息,则将 DataNode 标记为死亡。NameNode 不会将任何新的 IO 请求转发给标记为死亡的 DataNode,也不会 再使用这些 DataNode 上的数据。 由于数据不再可用,可能会导致某些块的复制因子小于其指定值, NameNode 会跟踪这些块,并在必要的时候进行重新复制。
2. 数据的完整性
由于存储设备故障等原因,存储在 DataNode 上的数据块也会发生损坏。为了避免读取到已经损坏的数 据而导致错误,HDFS 提供了数据完整性校验机制来保证数据的完整性,具体操作如下: 当客户端创建 HDFS 文件时,它会计算文件的每个块的 校验和 ,并将 校验和 存储在同一 HDFS 命名空 间下的单独的隐藏文件中。当客户端检索文件内容时,它会验证从每个 DataNode 接收的数据是否与存 储在关联校验和文件中的 校验和 匹配。如果匹配失败,则证明数据已经损坏,此时客户端会选择从其 他 DataNode 获取该块的其他可用副本。
3.元数据的磁盘故障
FsImage 和 EditLog 是 HDFS 的核心数据,这些数据的意外丢失可能会导致整个 HDFS 服务不可 用。为了避免这个问题,可以配置 NameNode 使其支持 FsImage 和 EditLog 多副本同步,这样 FsImage 或 EditLog 的任何改变都会引起每个副本 FsImage 和 EditLog 的同步更新。
4.支持快照
快照支持在特定时刻存储数据副本,在数据意外损坏时,可以通过回滚操作恢复到健康的数据状态。
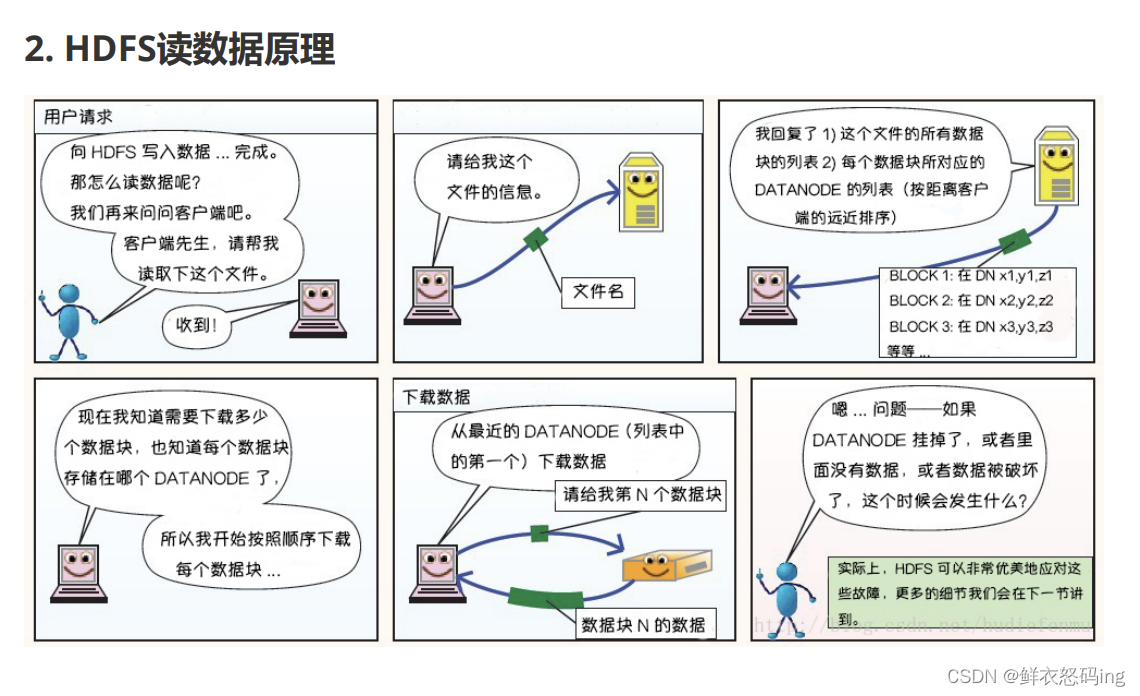
文件读取流程
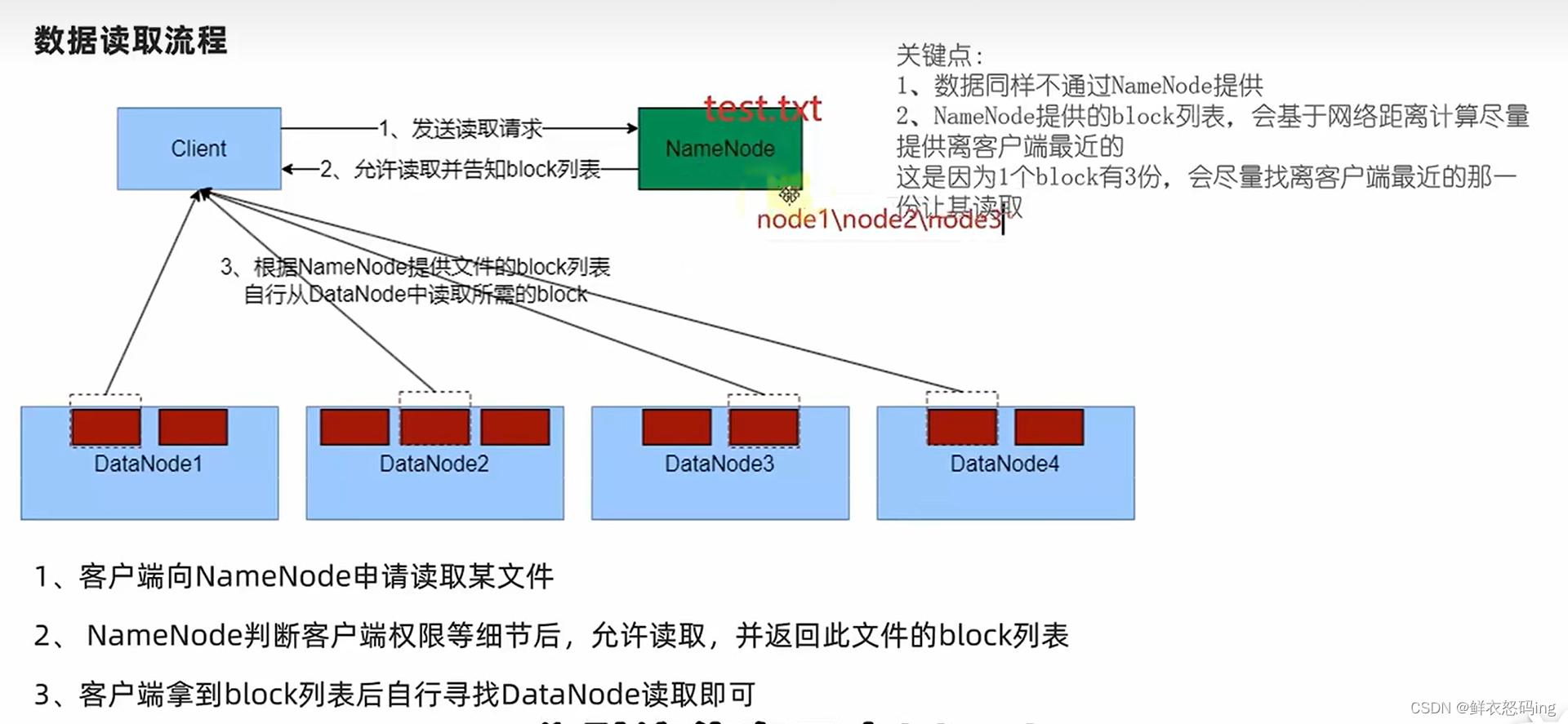
存储方式
Block块和多副本
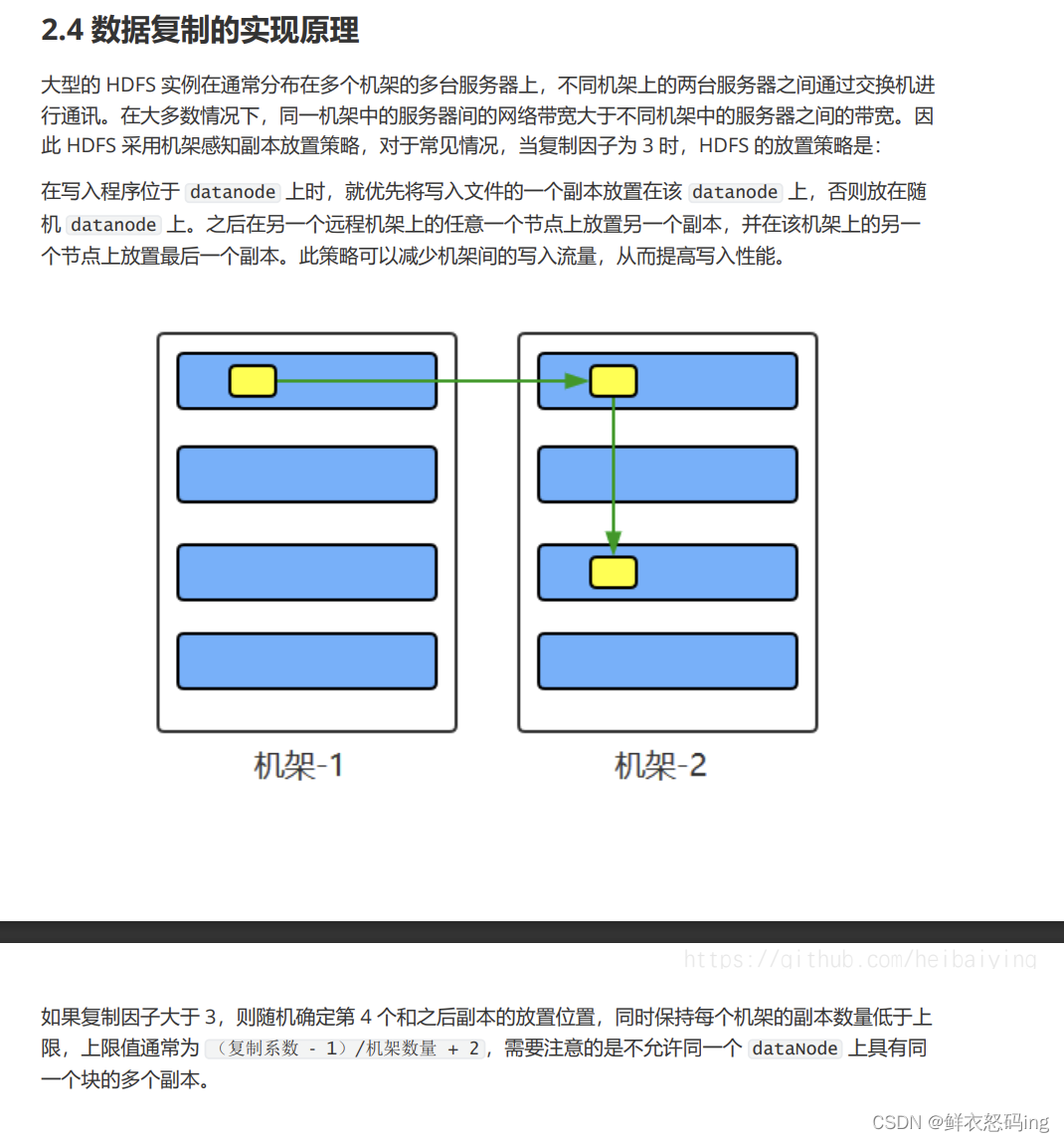
由于文件大小不一,不利于统一管理,hdfs设定了统一的存储单位Block块,Block块是hdfs最小存储单位,通常每个128MB(可修改dfs.blocksize)。hdfs会按照Block块大小把文件切分成多份存储在多个datanode上也就是多个服务器上,同时为了保证整个文件的完成性(防止Block块丢失或损坏),hdfs会对每个Block块做多个备份存储在其他节点上,备份的数量默认是3,可以在hdfs-site.xml中配置数量,修改后要重新分发该文件,保证每个服务器的配置文件相同!
<property></property><name>dfs.replication</name> <value>3</value>
同时还可以临时决定上传文件的副本数量:
hdfs fs -D dfs.replication=5 -put test.tst /data/test
还可以修改已存在的hdfs文件的副本数量:
hdfs fs -setrep [-R] 5 path
path是指定文件路径,-R表示对子目录也生效
edits和fsimage文件
hdfs中文件被划分成一堆堆block块,为了方便整理记录文件和block的关系,namenode基于一批edits文件和一个fsimage文件完成整个文件系统的维护管理。
edits文件是一个流水账文件,记录了hdfs的每一次操作以及该次操作影响的文件及其对应的block。为了保证edits文件检索性能,会有多个edits文件,每一个edits文件存储到达一定数量会开启新的edits,保证不出现超大的edits文件。最终所有edits文件会合并为一个fsimage文件,这个fsimage文件就记录了最终状态的文件操作信息。如果已经有了fsimage,就会把全部的edits和已存在的fsimage进行新的合并,生成新的fsimage。


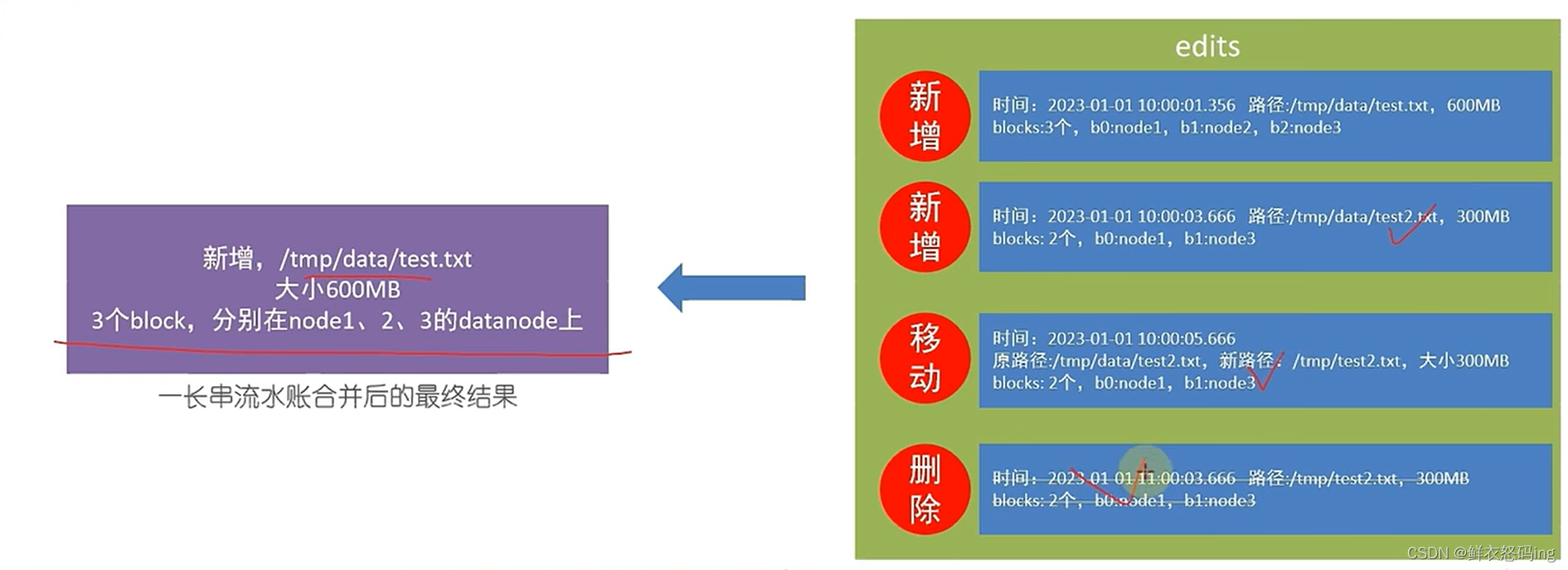
元数据合并及控制参数
注意!元数据(eidts和fsimage)的合并不是由NN完成的,而是SNN,NN只是基于元数据对整个文件系统进行维护管理,负责元数据记录和权限审批,NN是管理者,不是员工。
SNN会通过http从NN拉取edits和fsimage然后合并元数据并提供给NN使用

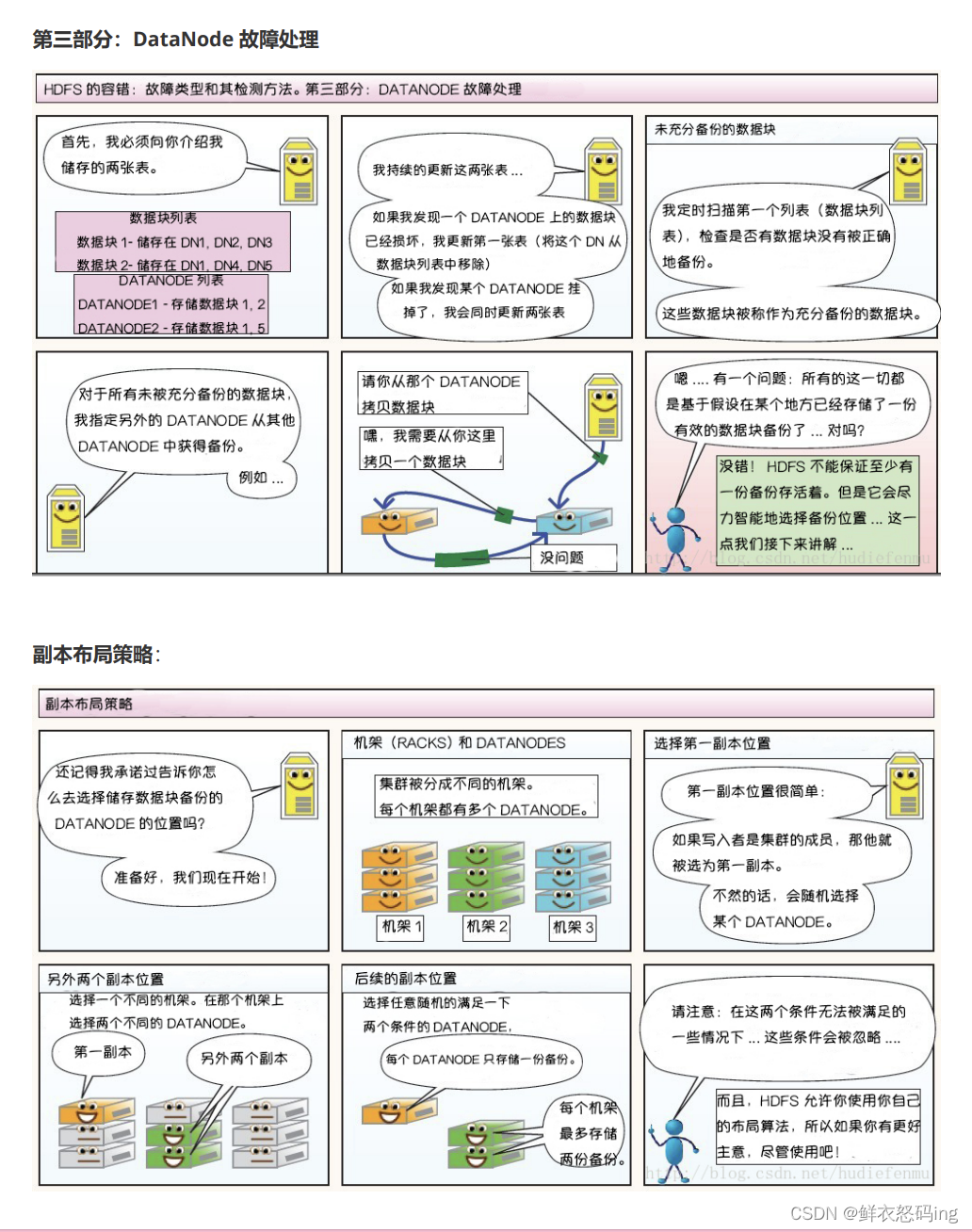
HDFS漫画

3.HDFS故障类型和检测方法
Mapreduce分布式并行计算框架
MapReduce是基于Yarn运行的,没有Yarn就无法运行MapReduce,MapReduce有RM、NM、AM三种角色。
MR不适合实时计算,不适合流式计算,不适合有向图计算。
可通过8042端口(默认8042)访问web界面,查看MR任务的执行信息
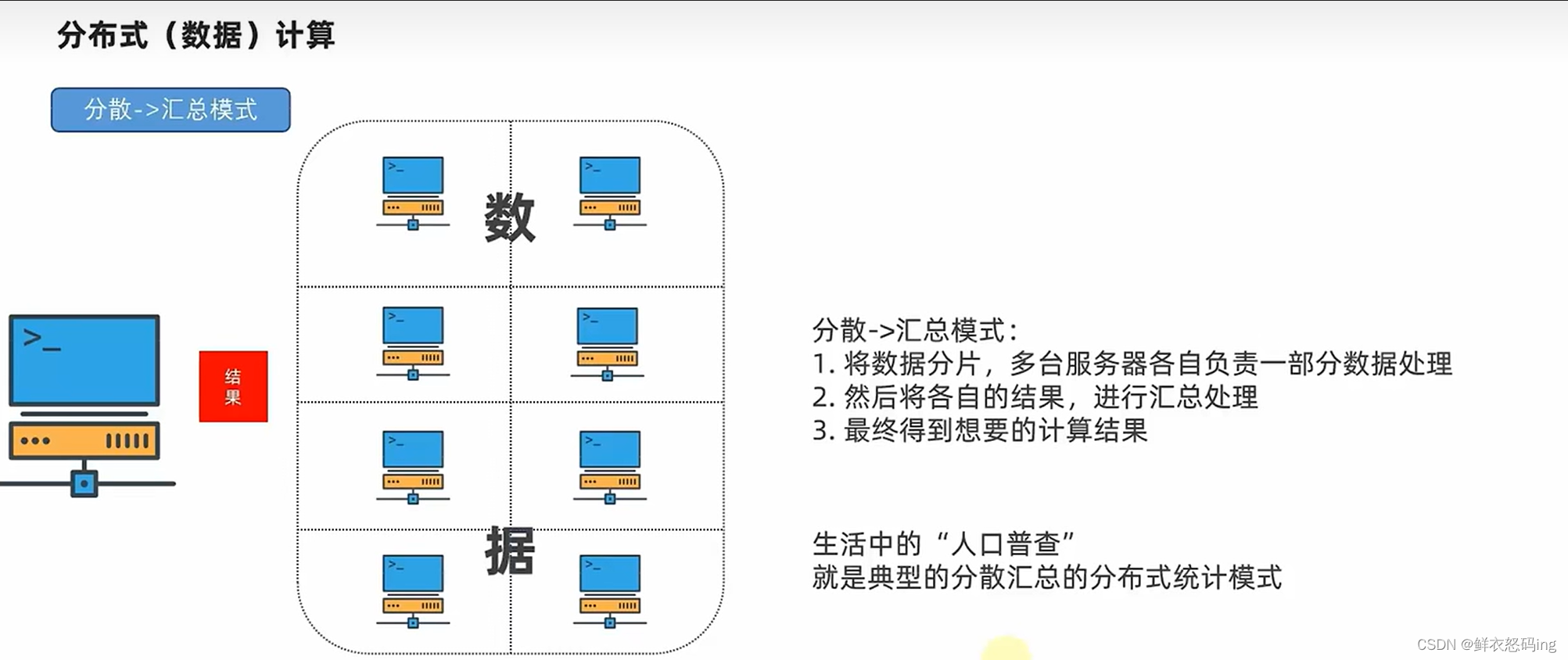
计算模式
MapReduce属于分散汇总。spark、flink属于中心调度
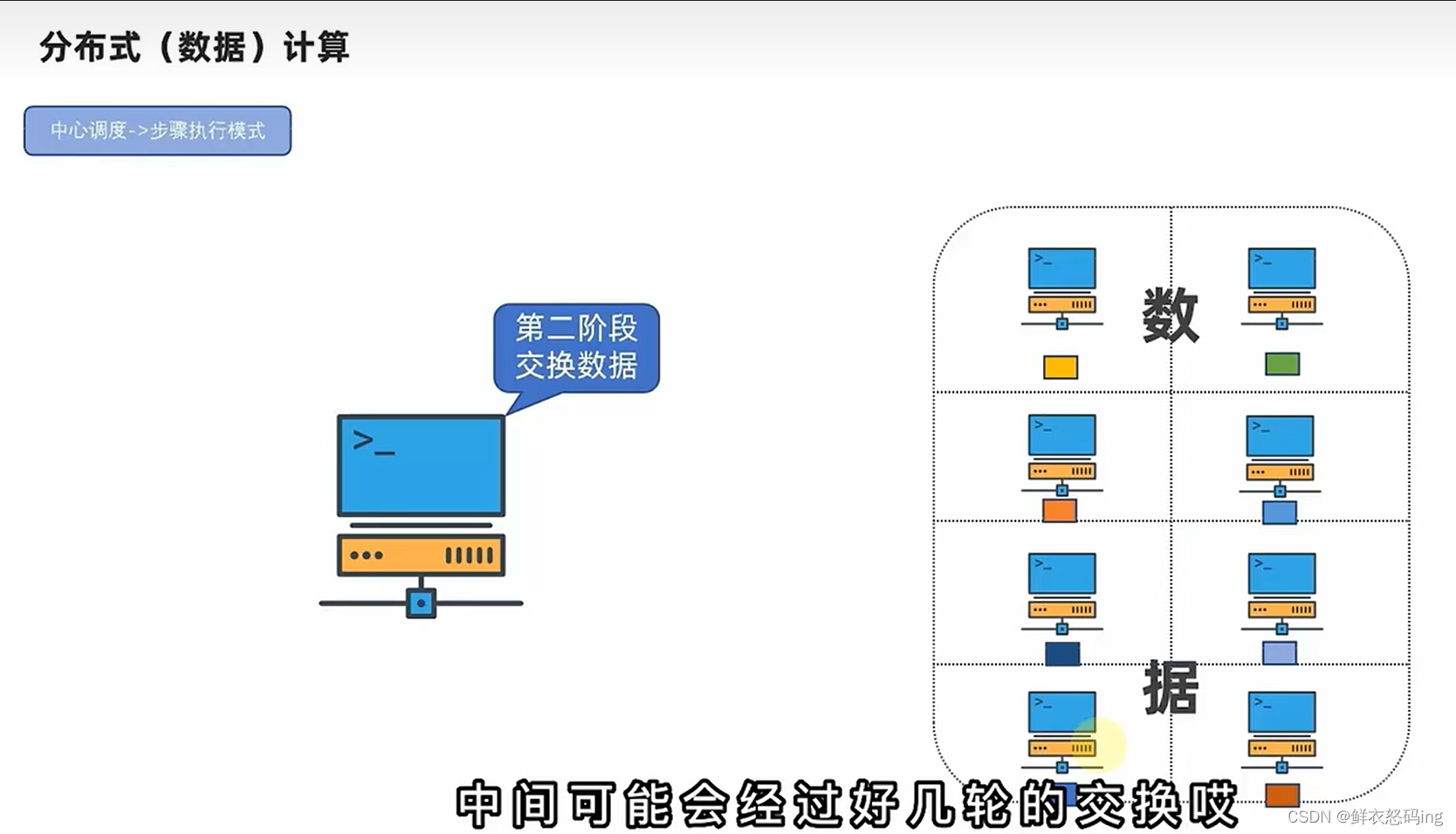
Map和Reduce
Map接口提供“分散”功能,Reduce提供“汇总聚合”功能,用户可以通过Java、python等编程调用mapreduce接口完成开发,不过现在已经有了Hive on MR(稍微过时),sparkSQL等客户端。不懂编程仅用SQL就能完成开发,使用更方便,逐渐成为主流。
MR执行原理
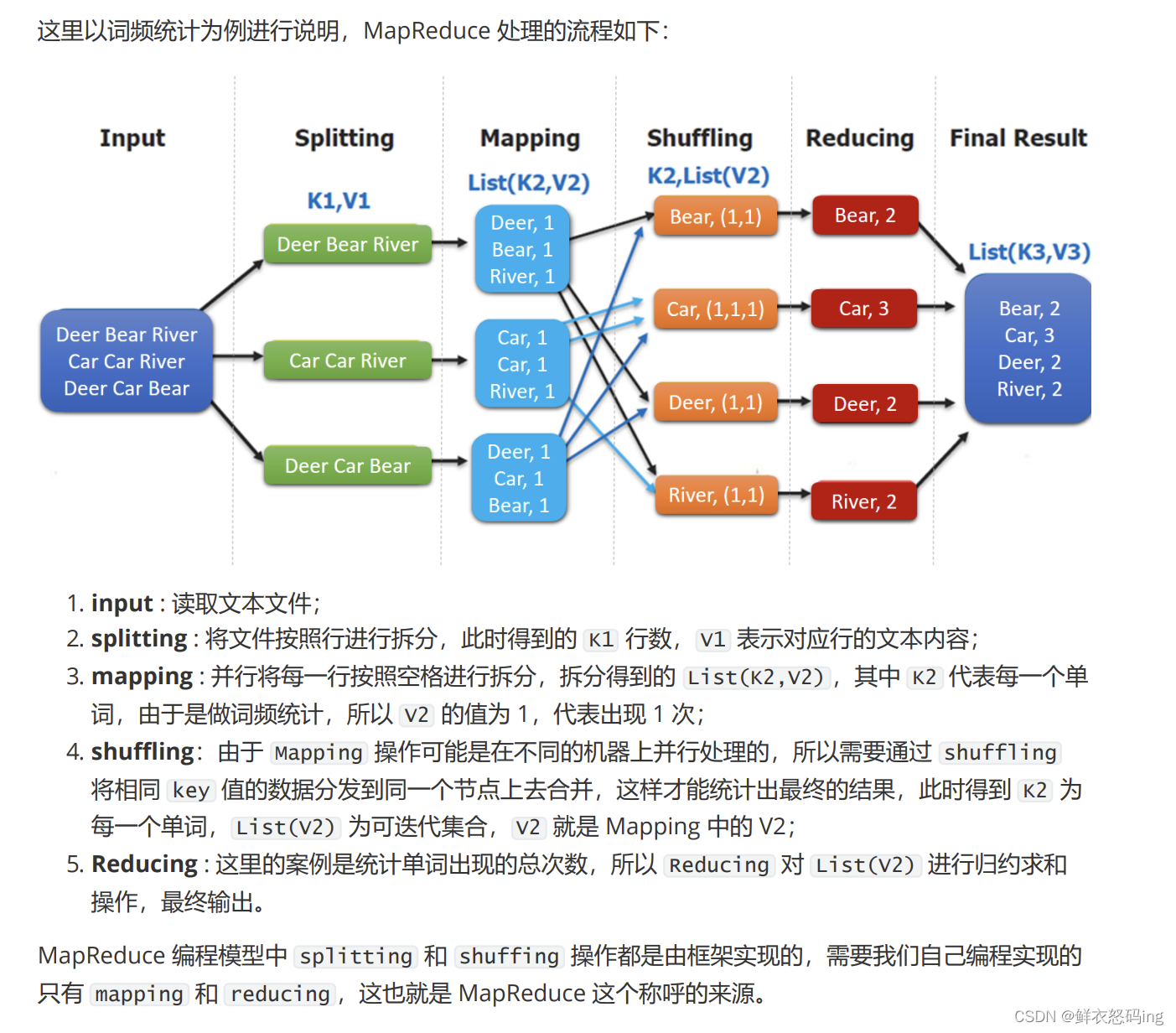
Yarn作业调度、资源管理
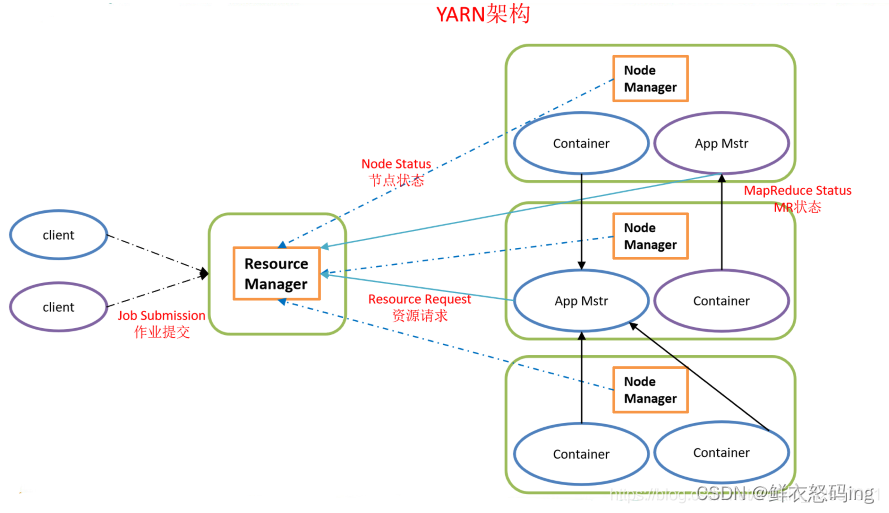
Yarn管控整个集群的资源调度,MR程序运行时,是在Yarn的监督下运行的,MR程序会把计算任务分成若干个map和reduce,然后向Yarn申请资源并运行任务。Yarn有四种角色:ResourceManager(RM)、NodeManager(NM)、ProxyServer(PS)、JobHistoryServer(JHS)
Yarn启停

ResourceManager
集群资源总管家,整个集群资源调度者,负责协调调度各个程序所需资源。
NodeManager
单机资源管家,单个服务器的资源调度者,负责协调调度单个服务器的资源供程序使用。同时负责该节点内所有容器的生命周期的管 理,监视资源和跟踪节点健康。具体如下:
启动时向 ResourceManager 注册并定时发送心跳消息,等待 ResourceManager 的指令;
维护 Container 的生命周期,监控 Container 的资源使用情况;
管理任务运行时的相关依赖,根据 ApplicationMaster 的需要,在启动 Container 之前将需 要的程序及其依赖拷贝到本地。
ApplicationMaster
在用户提交一个应用程序时,YARN 会启动一个轻量级的进程 ApplicationMaster 。 ApplicationMaster 负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器内资 源的使用情况,同时还负责任务的监控与容错。具体如下:
根据应用的运行状态来决定动态计算资源需求;
向 ResourceManager 申请资源,监控申请的资源的使用情况;
跟踪任务状态和进度,报告资源的使用情况和应用的进度信息;
负责任务的容错。
运行时可通过服务器的8088端口(默认8088)访问web界面
JobHistoryServer
记录历史运行程序的信息及产生的日志,把每个程序的运行日志统一收集到hdfs,可通过19888端口访问web界面
Container
Container 是 Yarn 中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等。
Hadoop一键启停
版权归原作者 怒码ing 所有, 如有侵权,请联系我们删除。