
(1)使用hadoop用户登录Linux系统,启动Hadoop(Hadoop的安装目录为“/usr/local/hadoop”),为hadoop用户在HDFS中创建用户目录“/user/hadoop”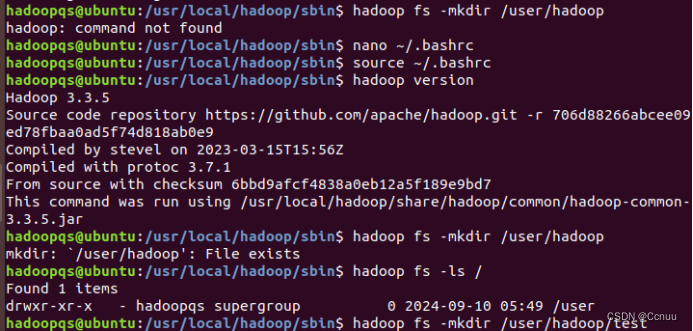
(2)接着在HDFS的目录“/user/hadoop”下,创建test文件夹,并查看文件列表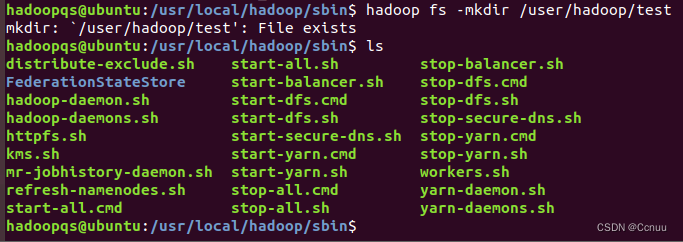
(3)将Linux系统本地的“~/.bashrc”文件上传到HDFS的test文件夹中,并查看test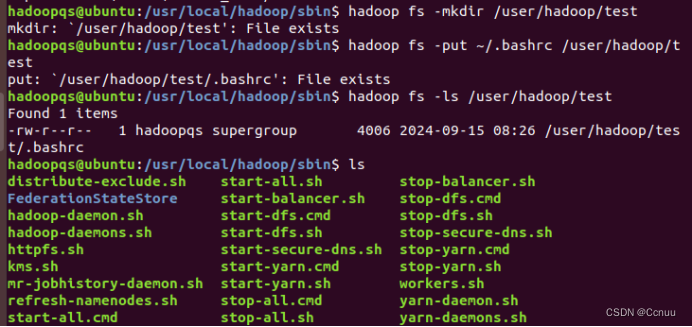
(4)将HDFS文件夹test复制到Linux系统本地文件系统的“/usr/local/hadoop”目录下
选做过程中出现的三个问题:
① SSH免密登录的设置不成功
② Java_HOME环境变量没设置好
③ 没有添加hadoop的可执行文件路径到系统的path环境变量里
解决完这三个问题,才得以启动hadoop和为hadoop用户创建目录。
一、选题的主思路:
步骤1:启动Hadoop
首先,切换到hadoop用户并启动Hadoop的所有服务(包括HDFS和YARN)。通常,Hadoop可以通过脚本启动,这些脚本位于Hadoop安装目录的sbin子目录下。
1su hadoop2cd /usr/local/hadoop/sbin3./start-dfs.sh4./start-yarn.sh
步骤2:在HDFS中为hadoop用户创建用户目录并查看文件列表
接下来,在HDFS中为hadoop用户创建一个目录,并查看根目录下的文件列表以确认创建成功。
1hadoop fs -mkdir /user/hadoop2hadoop fs -ls /
步骤3:在HDFS的/test文件夹下创建文件夹并上传本地文件
首先,在HDFS的/user/hadoop目录下创建一个名为test的文件夹,然后将本地的~/.bashrc文件上传到该文件夹内。
1hadoop fs -mkdir /user/hadoop/test2hadoop fs -put ~/.bashrc /user/hadoop/test3hadoop fs -ls /user/hadoop/test
步骤4:将HDFS文件夹复制到Linux本地系统
最后,将HDFS中的/user/hadoop/test目录复制到Linux系统的/usr/local/hadoop目录下。Hadoop原生命令不支持直接将HDFS目录复制到本地目录,但可以通过下载整个目录下的内容到本地的一个新目录中来间接实现。
1mkdir /usr/local/hadoop/test_download2hadoop fs -get /user/hadoop/test/* /usr/local/hadoop/test_download/
注意,这里使用了get命令配合通配符*来下载test目录下的所有内容到本地的/usr/local/hadoop/test_download/目录中,而不是直接复制目录结构。Hadoop的文件系统操作更偏向于文件级操作,而不是直接操作目录结构。
请根据实际情况调整路径和命令,确保操作符合您的系统配置和安全要求
二、遇到的问题:
1、问题一:SSH无法使用密钥对认证方式登录到本地主机(localhost)或其它节点
遇到 "Permission denied (publickey,password)" 错误,通常意味着SSH无法使用密钥对认证方式登录到本地主机(localhost)或其它节点。Hadoop的守护进程启动脚本(如start-dfs.sh)通常依赖SSH无密码登录来启动各个守护进程。为了解决这个问题,你需要设置SSH免密登录。
解决方案:
- 生成SSH密钥对(如果尚未生成)
首先,确保以hadoop用户身份执行以下命令,如果还没有生成SSH密钥对的话:1ssh-keygen -t rsa -P ""
这会在~/.ssh目录下生成id_rsa(私钥)和id_rsa.pub(公钥)文件。
- 将公钥添加到授权列表
然后,将公钥添加到SSH的授权列表中,允许自己免密登录:1cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- 配置SSH以使用密钥认证
确保SSH配置允许使用密钥认证。编辑~/.ssh/config文件(如果不存在,则创建),添加以下内容:1Host *2 IdentityFile ~/.ssh/id_rsa3 PubkeyAuthentication yes4 PasswordAuthentication no
- 测试SSH连接
在解决上述步骤后,测试能否无密码SSH到localhost:1ssh localhost
如果一切正常,你应该能够无需密码登录。
- 重新尝试启动Hadoop
完成上述设置后,退出当前的SSH会话(如果适用),然后再次尝试启动Hadoop服务:1./start-dfs.sh
如果按照上述步骤操作,你应该能够成功启动Hadoop服务,不再遇到权限拒绝的问题。如果问题仍然存在,可能需要检查Hadoop的配置文件(如hadoop-env.sh、core-site.xml等),确保SSH用户和相关配置正确无误。
怎么创建ssh/config文件
如果您的系统中没有.ssh/config文件,您可以手动创建一个。下面是创建并配置该文件的步骤:
创建 .ssh 目录(如果尚不存在)
首先,确保您的用户主目录下有一个名为.ssh的隐藏目录。如果不存在,请创建它:1mkdir ~/.ssh
创建或编辑 config 文件
接下来,在.ssh目录下创建或编辑config文件。您可以使用文本编辑器来完成这项任务,比如使用nano或vim:
使用 nano 编辑器:1nano ~/.ssh/config
使用 vim 编辑器:1vim ~/.ssh/config
添加配置内容
在打开的config文件中,您可以根据需要添加配置。如果您是为了解决SSH无密码登录问题而创建这个文件,可以添加类似于下面的内容:1Host *2 IdentityFile ~/.ssh/id_rsa3 PubkeyAuthentication yes4 PasswordAuthentication no
这段配置告诉SSH客户端使用默认的私钥文件(id_rsa)进行身份验证,并启用了公钥认证同时禁用了密码认证。
保存并退出编辑器
如果您使用的是nano,按Ctrl + O保存更改,然后按Ctrl + X退出。
如果您使用的是vim,按Esc键,然后输入:wq并回车来保存并退出。
设置文件权限
确保.ssh目录及其内容具有正确的权限,这对于SSH的安全性至关重要:
1chmod 700 ~/.ssh2chmod 600 ~/.ssh/config3chmod 600 ~/.ssh/id_rsa4chmod 644 ~/.ssh/id_rsa.pub
完成以上步骤后,您就已经成功创建并配置了~/.ssh/config文件,有助于简化和安全化SSH连接过程。
hadoop@ubuntu:/usr/local/hadoop/sbin$ ssh localhost Welcome to Ubuntu 18.04.6 LTS (GNU/Linux 5.4.0-150-generic x86_64)
Documentation: https://help.ubuntu.com
Management: https://landscape.canonical.com
Support: https://ubuntu.com/pro
Expanded Security Maintenance for Infrastructure is not enabled.
0 updates can be applied immediately.
Enable ESM Infra to receive additional future security updates. See https://ubuntu.com/esm or run: sudo pro status
Your Hardware Enablement Stack (HWE) is supported until April 2023.
The programs included with the Ubuntu system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright.
Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law.
您已经成功通过SSH连接到localhost,这意味着SSH密钥对已经正确设置并且可以无密码登录。这一步是解决您最初在启动Hadoop时遇到的权限问题的关键。
既然您现在能够无密码SSH到localhost,您可以再次尝试启动Hadoop服务:1hadoop@ubuntu:/usr/local/hadoop/sbin$ ./start-dfs.sh
这次应该不会再出现Permission denied (publickey,password)的错误,Hadoop的NameNode、DataNode以及Secondary NameNode应该能够顺利启动。
请在执行命令后检查Hadoop的日志文件(通常位于/var/log/hadoop或$HADOOP_HOME/logs),以确认所有服务都已正常启动并无错误信息。如果启动过程中仍然遇到任何问题,日志文件会提供进一步的诊断信息。
2、问题二:JAVA_HOME is not set and could not be found”,这意味着系统未能找到Java的安装路径,JAVA_HOME环境变量没有被正确设置
hadoop@ubuntu:/usr/local/hadoop/sbin$ ./start-dfs.sh ERROR: JAVA_HOME is not set and could not be found.
错误信息显示“JAVA_HOME is not set and could not be found”,这意味着系统未能找到Java的安装路径,因为JAVA_HOME环境变量没有被正确设置。Hadoop需要Java运行环境才能启动其服务。
解决方案:
查找Java安装路径: 首先,确认Java是否已安装,以及它的安装路径。可以在终端中执行以下命令:
1update-alternatives --list java
或者直接执行:1which java
这两个命令中的任何一个都应该会显示出Java的可执行文件路径,例如/usr/lib/jvm/java-8-openjdk-amd64/bin/java。从这个路径中,提取出JDK的安装目录,通常是路径中的java-8-openjdk-amd64之前的部分,即/usr/lib/jvm/java-8-openjdk-amd64。
设置JAVA_HOME环境变量:打开Hadoop的环境变量配置文件,通常是hadoop-env.sh,路径为$HADOOP_HOME/etc/hadoop/hadoop-env.sh。使用文本编辑器打开它,例如:1nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
在文件中找到关于设置JAVA_HOME的行(可能注释掉了),并将其修改为实际的Java安装路径。例如,如果Java安装在/usr/lib/jvm/java-8-openjdk-amd64,则修改为:1export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
保存并关闭文件。使修改生效: 修改完环境变量配置文件后,需要让这些变更生效。可以注销并重新登录,或者运行以下命令来立即更新当前shell的环境变量:1source $HADOOP_HOME/etc/hadoop/hadoop-env.sh
重新尝试启动Hadoop: 完成上述设置后,再次尝试启动Hadoop服务:1./start-dfs.sh
经过以上步骤,如果Java路径设置正确,您应该能够成功启动Hadoop的分布式文件系统(HDFS)服务。
^G Get Help ^O Write Out ^W Where Is ^K Cut Text ^J Justify ^X Exit ^R Read File ^\ Replace ^U Uncut Text ^T To Linter
看起来你似乎不小心输入了一串控制字符和提示信息。这些字符通常在使用特定文本编辑器或终端命令行界面时出现,用于执行诸如获取帮助、保存文件、剪切粘贴文本等操作。如果你需要进一步的帮助或者有具体问题想要询问,请直接告诉我你的需求,我会尽力协助你。
怎么退出nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh文本编辑器
在nano文本编辑器中,要退出并保存文件,你可以按下以下按键组合:
.Ctrl + O (这是字母'O',代表Write Out),然后按回车键来保存你所做的修改。
.接着,按下 Ctrl + X 来退出编辑器。
如果你不想保存所做的修改,可以直接按下 Ctrl + X ,然后在出现的提示中选择“否”(通常通过按键盘上的大写N键,然后回车确认)来直接退出不保存。
error writing /etc/hadoop/hadoop-env.sh:No such file or directory
这个错误信息表明您尝试写入的文件路径 /etc/hadoop/hadoop-env.sh 不存在。这可能是由于多种原因,比如路径错误、Hadoop未正确安装或配置文件位置与预期不符。解决这个问题,您可以尝试以下几个步骤:
确认Hadoop安装路径:首先,确保您使用的是正确的$HADOOP_HOME路径。如果Hadoop安装在了其他位置,比如/usr/local/hadoop,那么您应该相应地调整路径。
手动创建文件:如果确定了正确的安装路径,但是hadoop-env.sh确实不在预期的位置,您可以手动创建这个文件。使用以下命令在正确的位置创建文件:
1sudo mkdir -p /etc/hadoop2sudo touch /etc/hadoop/hadoop-env.sh3sudo nano /etc/hadoop/hadoop-env.sh
这将创建所需的目录(如果不存在),然后创建hadoop-env.sh文件,并直接打开它供编辑。
配置JAVA_HOME:一旦文件打开,您可以按照之前的指导设置JAVA_HOME环境变量。
权限问题:如果在创建或编辑文件时遇到权限问题,确保使用了适当的权限。在使用sudo命令创建或编辑系统级别的配置文件时,通常可以避免这类问题。
检查Hadoop配置文档:如果Hadoop是从包管理器安装的(如APT或Yum),配置文件可能位于不同的路径。查阅Hadoop的安装文档,确认hadoop-env.sh的确切推荐存放位置。
请根据您的具体情况选择合适的步骤操作。
4、问题三:hadoop用户没有被添加到sudoers文件中
hadoop@ubuntu:/usr/local/hadoop/sbin$ sudo mkdir -p /etc/hadoop [sudo] password for hadoop: hadoop is not in the sudoers file. This incident will be reported. hadoop@ubuntu:/usr/local/hadoop/sbin$
您在尝试以hadoop用户身份使用sudo命令来创建目录时遇到了权限问题,因为该用户没有被添加到sudoers文件中。sudoers文件是用来指定哪些用户具有执行sudo命令(即以超级用户或其他用户身份执行命令)权限的配置文件。
要解决这个问题,您需要以具有管理员权限的用户(通常是root用户)登录,然后将hadoop用户添加到sudoers文件中。您可以按照以下步骤操作:
首先,切换到root用户。如果您知道root用户的密码,可以使用:1sudo -i或者直接登录:1su -
使用文本编辑器(如nano或vi)打开/etc/sudoers文件。推荐使用visudo命令来安全地编辑此文件,因为它会检查语法并避免锁定自己出错。
1visudo
在打开的文件中,找到类似下面这样的行(可能在文件的末尾):
User privilege specification
root ALL=(ALL:ALL) ALL
在此部分下方,添加一行来授予hadoop用户sudo权限。例如:
hadoop ALL=(ALL:ALL) NOPASSWD:ALL
这行意味着hadoop用户可以在任何主机上运行任何命令,并且不需要输入密码。如果出于安全考虑,您希望hadoop用户在使用sudo时输入密码,可以去掉NOPASSWD:部分。保存并关闭文件。如果您使用的是nano,可以通过按Ctrl+X,然后按Y键确认保存更改,最后按回车键退出。如果是vi或vim,可以按下Esc键,然后输入:wq并回车来保存并退出。现在,您可以退出root用户会话,回到hadoop用户下,再次尝试之前的命令应该就能成功了:1exit2hadoop@ubuntu:/usr/local/hadoop/sbin$ sudo mkdir -p /etc/hadoop3[sudo] password for hadoop:
请确保在进行这些操作时格外小心,错误地编辑sudoers文件可能会导致系统管理权限出现问题。
hadoop@ubuntu:/usr/local/hadoop/sbin$ su - Password: root@ubuntu:# visudo root@ubuntu:# exit logout hadoop@ubuntu:/usr/local/hadoop/sbin$ sudo mkdir -p /etc/hadoop hadoop@ubuntu:/usr/local/hadoop/sbin$ sudo mkdir -p /etc/hadoop hadoop@ubuntu:/usr/local/hadoop/sbin$ sudo mkdir -p /etc/hadoop hadoop@ubuntu:/usr/local/hadoop/sbin$ sudo touch /etc/hadoop/hadoop-env.sh hadoop@ubuntu:/usr/local/hadoop/sbin$ sudo nano /etc/hadoop/hadoop-env.sh hadoop@ubuntu:/usr/local/hadoop/sbin$ source $HADOOP_HOME/etc/hadoop/hadoop-env.sh hadoop@ubuntu:/usr/local/hadoop/sbin$ ./start-dfs.sh Starting namenodes on [localhost] localhost: ERROR: JAVA_HOME is not set and could not be found. Starting datanodes localhost: ERROR: JAVA_HOME is not set and could not be found. Starting secondary namenodes [ubuntu] ubuntu: ERROR: JAVA_HOME is not set and could not be found. hadoop@ubuntu:/usr/local/hadoop/sbin$
您遇到的问题是由于JAVA_HOME环境变量未设置或设置不正确,导致Hadoop启动失败。Hadoop需要知道Java安装的位置来运行其各个组件。您需要设置JAVA_HOME环境变量,指向您的Java安装目录。下面是设置JAVA_HOME的步骤:
查找Java安装路径:首先,您需要确定Java安装在哪个目录下。通常,Java安装在/usr/lib/jvm目录下的某个子目录,例如/usr/lib/jvm/java-8-openjdk-amd64。您可以使用以下命令来查找Java安装位置:1update-alternatives --list java
或者直接查看可能的安装目录:1ls -l /usr/lib/jvm
设置JAVA_HOME:一旦找到Java安装路径,您需要将其设置为JAVA_HOME环境变量。这可以通过编辑hadoop-env.sh文件来完成。您之前已经打开了这个文件,现在需要添加或修改以下行:
1export JAVA_HOME=/path/to/your/java/installation
将/path/to/your/java/installation替换为实际的Java安装路径,例如:
1export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
保存并退出编辑器:在nano中,按Ctrl+O保存更改,然后按Ctrl+X退出。
使更改生效:为了使更改立即生效,您需要重新加载hadoop-env.sh脚本。您之前尝试过但未显示成功消息,正确做法应该是:1source /etc/hadoop/hadoop-env.sh
或者,更保险的做法是完全退出当前终端会话再重新登录,这样环境变量的改变会自动加载。
重新尝试启动HDFS:现在,再次尝试启动HDFS服务,应该不会再出现关于JAVA_HOME的错误了:
1./start-dfs.sh
完成以上步骤后,如果Java路径设置正确,Hadoop应该能够正常启动了。如果还有其他问题,请检查Hadoop的配置文件以及Java是否正确安装和配置。
hadoop@ubuntu:/usr/local/hadoop/sbin$ update-alternatives --list java /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java hadoop@ubuntu:/usr/local/hadoop/sbin$ ls -l /usr/lib/jvm total 12 lrwxrwxrwx 1 root root 20 May 6 2023 java-1.8.0-openjdk-amd64 -> java-8-openjdk-amd64 drwxr-xr-x 5 root root 4096 Sep 5 22:31 java-8-openjdk-amd64 drwxrwxrwx 8 hadoopqs hadoopqs 4096 Sep 4 08:14 jdk11.0.24_8 drwxr-xr-x 8 root root 4096 Sep 9 20:04 jdk1.8.0_371 hadoop@ubuntu:/usr/local/hadoop/sbin$
根据您提供的信息,Java 8的安装路径为/usr/lib/jvm/java-8-openjdk-amd64。接下来,您需要把这个路径设置到JAVA_HOME环境变量中。您之前已经知道了如何编辑hadoop-env.sh文件来设置JAVA_HOME,现在让我们具体操作一下:
编辑 hadoop-env.sh 文件:1sudo nano /etc/hadoop/hadoop-env.sh
设置 JAVA_HOME:在文件中找到关于设置JAVA_HOME的行(如果没有,则在文件的适当位置新增一行),并将其修改为正确的Java路径。根据您的系统情况,应该设置为:export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
确保这一行没有被注释掉(即行首没有#)。
保存并退出:按 Ctrl+O 保存更改,然后按 Ctrl+X 退出编辑器。
使修改生效:为了让修改立即生效,您需要重新加载hadoop-env.sh配置文件。但是,您之前尝试的命令似乎有误,应该直接使用:
1source /etc/hadoop/hadoop-env.sh
这样做会立即更新当前终端会话的环境变量设置。
再次尝试启动 HDFS:现在,再次尝试启动Hadoop的HDFS服务:
1./start-dfs.sh
完成上述步骤后,Hadoop应该能够识别到正确的JAVA_HOME路径,并顺利启动。如果仍然遇到问题,请检查Hadoop的日志文件以获取更详细的错误信息。
5、问题五:设置了JAVA_HOME,但启动Hadoop时仍然提示JAVA_HOME未设置,解决方法:尝试完全退出终端后再重新登录
hadoopqs@ubuntu:/usr/local/hadoop/sbin$ ./start-dfs.sh Starting namenodes on [localhost] Starting datanodes Starting secondary namenodes [ubuntu] hadoopqs@ubuntu:/usr/local/hadoop/sbin$
看起来您已经成功解决了JAVA_HOME未设置的问题,并且Hadoop的NameNode、DataNode以及Secondary NameNode都已经成功启动了。没有出现错误信息,这是个好迹象,表明您的Hadoop集群服务已经正常启动。
接下来,您可以进行一些基本的验证步骤来确认Hadoop是否运行正常:
检查进程:首先,可以通过检查系统中的进程来验证Hadoop守护进程是否正在运行。可以使用如下命令
1jps
这个命令会列出所有Java进程,您应该能看到NameNode, DataNode, 和 SecondaryNameNode(或在Hadoop 3.x及以后版本中的Namenode和Datanode,因为SecondaryNameNode已被替换为其他高可用机制)。
查看日志:检查Hadoop的各类日志文件,以确认服务启动过程中没有其他潜在问题。日志文件通常位于$HADOOP_LOG_DIR(Hadoop配置中定义的目录,默认可能是/var/log/hadoop)或Hadoop安装目录的logs子目录下。
访问Web UI:Hadoop提供了一系列Web UI,用于监控集群状态。默认情况下,您可以访问以下地址来查看NameNode和DataNode的状态:
.
NameNode: http://localhost:50070
DataNode: http://localhost:50075
如果一切看起来正常,那么恭喜您,Hadoop集群已经成功启动并运行。接下来,您可以开始部署MapReduce任务或者配置Hadoop的其他组件,比如YARN和Hadoop的高可用模式等,以满足更复杂的应用需求。
6、问题六:Hadoop的可执行文件路径没有被正确添加到系统的PATH环境变量中,因此无法直接在任何目录下执行hadoop命令,需要将Hadoop的bin目录添加到PATH中
hadoopqs@ubuntu:/usr/local/hadoop/sbin$ jps 5570 SecondaryNameNode 5171 NameNode 5734 Jps 5325 DataNode hadoopqs@ubuntu:/usr/local/hadoop/sbin$ ./start-dfs.sh Starting namenodes on [localhost] localhost: namenode is running as process 5171. Stop it first and ensure /tmp/hadoop-hadoopqs-namenode.pid file is empty before retry. Starting datanodes localhost: datanode is running as process 5325. Stop it first and ensure /tmp/hadoop-hadoopqs-datanode.pid file is empty before retry. Starting secondary namenodes [ubuntu] ubuntu: secondarynamenode is running as process 5570. Stop it first and ensure /tmp/hadoop-hadoopqs-secondarynamenode.pid file is empty before retry. hadoopqs@ubuntu:/usr/local/hadoop/sbin$ ./start-yarn.sh Starting resourcemanager Starting nodemanagers hadoopqs@ubuntu:/usr/local/hadoop/sbin$ hadoop fs -mkdir /user/hadoop hadoop: command not found hadoopqs@ubuntu:/usr/local/hadoop/sbin$
您已经成功启动了Hadoop的HDFS组件(包括NameNode, DataNode, 和 SecondaryNameNode)。接下来尝试启动YARN时,虽然没有显示错误信息,但看起来YARN相关的进程启动情况没有通过jps命令展示出来,这可能是因为它们尚未完全启动,或者启动过程中遇到了问题。不过,主要问题是您在尝试运行hadoop fs -mkdir /user/hadoop命令时,系统提示hadoop: command not found。
这个问题通常是因为Hadoop的可执行文件路径没有被正确添加到系统的PATH环境变量中,因此无法直接在任何目录下执行hadoop命令。您需要将Hadoop的bin目录添加到PATH中。按照以下步骤操作:
编辑bash配置文件:打开您的bash配置文件,对于bash shell,这通常是/.bashrc或/.bash_profile(取决于您的系统和配置)。可以使用文本编辑器,如:
1nano ~/.bashrc
添加Hadoop路径:在文件的末尾添加以下行,以将Hadoop的bin目录加入PATH中。请根据您的实际Hadoop安装路径调整:
1export HADOOP_HOME=/usr/local/hadoop2export PATH=$PATH:$HADOOP_HOME/bin
使修改生效:保存文件并退出编辑器。然后,让修改生效,可以执行:source ~/.bashrc
验证:现在,再次尝试运行hadoop命令,看是否能成功识别:hadoop version
如果配置正确,这将显示Hadoop的版本信息。
之后,您应该能够成功运行hadoop fs -mkdir /user/hadoop命令来创建HDFS目录了。如果YARN服务启动情况仍不确定,可以通过检查相关日志文件或再次使用jps命令查看是否有YARN的ResourceManager和NodeManager进程在运行
hadoopqs@ubuntu:/usr/local/hadoop/sbin$ hadoop version Hadoop 3.3.5 Source code repository https://github.com/apache/hadoop.git -r 706d88266abcee09ed78fbaa0ad5f74d818ab0e9 Compiled by stevel on 2023-03-15T15:56Z Compiled with protoc 3.7.1 From source with checksum 6bbd9afcf4838a0eb12a5f189e9bd7 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.3.5.jar hadoopqs@ubuntu:/usr/local/hadoop/sbin$ hadoop fs -mkdir /user/hadoop mkdir: `/user/hadoop': File exists hadoopqs@ubuntu:/usr/local/hadoop/sbin$ hadoop fs -ls / Found 1 items drwxr-xr-x - hadoopqs supergroup 0 2024-09-10 05:49 /user hadoopqs@ubuntu:/usr/local/hadoop/sbin$
很好,您已经成功验证了Hadoop的版本信息,这意味着Hadoop的可执行文件路径已经被正确添加到了系统的PATH环境变量中。当您尝试创建HDFS目录/user/hadoop时,收到“File exists”的消息,这表明该目录已经存在,所以无需再次创建。
接下来,您可以通过列出/user目录的内容来确认/user/hadoop确实已经存在,您实际上已经这么做了,命令输出显示了如下信息:
1Found 1 items2drwxr-xr-x - hadoopqs supergroup 0 2024-09-10 05:49 /user
这表示/user目录下至少有一个条目(在这个情况下是/user/hadoop目录),并且它是由用户hadoopqs拥有,所属组为supergroup。
现在,您可以继续进行下一步操作,比如上传文件到HDFS、运行MapReduce作业、配置YARN(如果还没有完成的话),或是进行更高级的Hadoop集群管理与维护工作。如果您需要进一步的帮助或指导,请随时告知。
hadoopqs@ubuntu:/usr/local/hadoop/sbin$ mkdir /usr/local/hadoop/test_download hadoopqs@ubuntu:/usr/local/hadoop/sbin$ hadoop fs -get /user/hadoop/test/* /usr/local/hadoop/test_download/ hadoopqs@ubuntu:/usr/local/hadoop/sbin$
您刚刚创建了一个本地目录/usr/local/hadoop/test_download,并尝试使用Hadoop的文件系统命令hadoop fs -get从HDFS的/user/hadoop/test/目录下载所有文件到该本地目录。这个命令假定HDFS上的/user/hadoop/test/目录下存在一些文件可以下载。
请注意,如果在执行hadoop fs -get命令时没有出现任何错误信息,一般情况下这意味着命令执行成功,文件已经被下载到指定的本地目录。然而,由于命令没有输出确认信息,我们不能直接从这段交互记录中判断是否有文件被成功下载,或者/user/hadoop/test/目录下是否真的有文件存在。
为了确认操作结果,您可以执行以下步骤:
检查下载目录:通过ls命令查看/usr/local/hadoop/test_download/目录,确认是否有文件被下载下来:1ls /usr/local/hadoop/test_download/
查看HDFS源目录:再次确认HDFS源目录/user/hadoop/test/的内容,以了解原始文件情况,可以使用:
1hadoop fs -ls /user/hadoop/test/
如果在下载目录中看到了预期的文件,那就说明文件已经成功下载。如果发现任何问题,比如文件未下载或数量不对,检查HDFS源目录的文件情况,以及是否有任何错误或警告信息被输出但未被捕获。如果有特定错误,根据错误信息采取相应的解决措施。
hadoopqs@ubuntu:/usr/local/hadoop/sbin$ ls /usr/local/hadoop/test_download/ hadoopqs@ubuntu:/usr/local/hadoop/sbin$ hadoop fs -ls /user/hadoop/test/ Found 1 items -rw-r--r-- 1 hadoopqs supergroup 4006 2024-09-15 08:26 /user/hadoop/test/.bashrc hadoopqs@ubuntu:/usr/local/hadoop/sbin$
从您的命令输出来看,HDFS的/user/hadoop/test/目录中确实有一个文件.bashrc,大小为4006字节。但是,当您列出本地的/usr/local/hadoop/test_download/目录时,没有显示出任何文件,这表明之前尝试使用hadoop fs -get命令下载文件可能没有成功,或者下载的文件由于某些原因没有出现在预期的目录中。
这里有几个可能的原因和相应的检查步骤:
权限问题:确认Hadoop用户是否有权限读取HDFS上的文件以及写入本地目标目录。
文件名隐藏:注意到HDFS中的文件名为.bashrc,这是一个以点开头的隐藏文件。在Linux系统中,ls命令默认不显示隐藏文件。尝试使用ls -a /usr/local/hadoop/test_download/来查看是否包含了这个隐藏文件。
命令执行错误:确认在执行hadoop fs -get命令时是否出现了任何错误信息,有时候命令可能因为权限、路径错误等原因未能成功执行,但错误信息没有被注意到。
文件已存在:如果之前尝试下载过且文件已存在于目标目录中,hadoop fs -get命令不会覆盖现有文件,除非使用了-f或--force选项强制覆盖。
建议您首先使用ls -a命令检查本地目录,确认文件是否下载但被隐藏了。如果没有看到文件,可以尝试再次执行下载命令,这次加上-f参数强制覆盖本地存在的文件(如果有的话):
1hadoop fs -get -f /user/hadoop/test/*.bashrc /usr/local/hadoop/test_download/
或者,直接指定文件名而不是使用通配符:
1hadoop fs -get /user/hadoop/test/.bashrc /usr/local/hadoop/test_download/
执行后,再次检查本地目录,看文件是否成功下载。
hadoopqs@ubuntu:/usr/local/hadoop/sbin$ hadoop fs -get -f /user/hadoop/test/*.bashrc /usr/local/hadoop/test_download/ hadoopqs@ubuntu:/usr/local/hadoop/sbin$ hadoop fs -get /user/hadoop/test/.bashrc /usr/local/hadoop/test_download/ get: `/usr/local/hadoop/test_download/.bashrc': File exists hadoopqs@ubuntu:/usr/local/hadoop/sbin$
您在尝试使用hadoop fs -get命令下载文件时收到了File exists的错误,这说明目标文件/usr/local/hadoop/test_download/.bashrc已经在本地存在,而您没有使用-f或--force选项来覆盖它。
如果您希望覆盖已存在的文件,需要在命令中加上-f选项,如下所示:
1hadoop fs -get -f /user/hadoop/test/.bashrc /usr/local/hadoop/test_download/
这个命令会强制下载HDFS上的.bashrc文件,并覆盖本地同名文件(如果存在)。不过,从您的操作序列来看,您在第二次尝试下载时似乎并未加上-f选项,这可能是出于避免意外覆盖文件的考虑。
既然您已经知道目标文件存在,您有两种选择:
确认文件内容:首先检查现有的/usr/local/hadoop/test_download/.bashrc文件是否已经是您想要的文件,如果是,则无需再次下载。
覆盖下载:如果需要从HDFS下载最新的文件覆盖本地文件,使用带有-f的命令来强制下载并覆盖。
请根据您的实际需求选择合适的操作。如果决定覆盖,请记得使用正确的命令进行下载。
hadoopqs@ubuntu:/usr/local/hadoop/sbin$ hadoop fs -get -f /user/hadoop/test/.bashrc /usr/local/hadoop/test_download/ hadoopqs@ubuntu:/usr/local/hadoop/sbin$
您已经使用了带有-f选项的hadoop fs -get命令来强制从HDFS的/user/hadoop/test/目录下载.bashrc文件到本地的/usr/local/hadoop/test_download/目录,并覆盖了原有文件(如果存在)。既然命令执行没有返回任何错误信息,我们可以假设文件已经被成功下载并覆盖(如果之前存在的话)。
现在,您可以再次检查本地目录以确认文件是否已被正确下载和覆盖:ls -l /usr/local/hadoop/test_download/
这条命令会列出目录内容并显示详细信息,包括文件大小和修改时间,帮助您确认下载的文件是最新的,并且没有问题。
如果一切符合预期,接下来您可以继续进行其他Hadoop相关的操作,比如上传文件至HDFS、运行MapReduce作业、配置和使用YARN资源管理等。如果在操作过程中遇到任何问题,欢迎随时提问。
hadoopqs@ubuntu:/usr/local/hadoop/sbin$ ls -l /usr/local/hadoop/test_download/ total 0 hadoopqs@ubuntu:/usr/local/hadoop/sbin$
您执行ls -l /usr/local/hadoop/test_download/命令后,结果显示目录的总大小为0,且没有列出任何文件。这可能意味着尽管您尝试使用hadoop fs -get -f命令强制下载文件,但实际上文件并没有成功下载到指定的本地目录,或者下载后的文件被立即删除了,又或者是存在其他未捕获的错误。
考虑到之前的操作看似没有报错,这里有几个可能的原因和建议的步骤:
权限问题:虽然您能执行Hadoop命令,但请确认/usr/local/hadoop/test_download/目录对当前用户有足够的权限(读写权限)来存放下载的文件。
文件系统问题:偶尔,文件系统异常也可能导致文件看似复制成功但实际上并未写入。检查磁盘空间是否足够,以及文件系统是否处于健康状态。
命令输出重定向或日志:有时候,命令的输出可能被重定向或错误信息被忽略了。检查是否有任何相关的日志文件,如Hadoop的日志,可能会提供失败原因的线索。
再次尝试下载:直接明确指定文件路径,再次尝试下载,并密切关注命令执行过程中的任何输出信息。
直接查看HDFS文件:有时候,问题可能出在HDFS的文件本身,比如文件实际上是空的。可以再次查看HDFS上的文件详情:
1hadoop fs -ls -R /user/hadoop/test/.bashrc2hadoop fs -cat /user/hadoop/test/.bashrc
确认文件非空且内容如预期。
如果以上步骤都不能解决问题,可能需要更详细的错误信息或系统日志来进行深入排查。
版权归原作者 Ccnuu 所有, 如有侵权,请联系我们删除。