
使用场景: 表值聚合函数即 UDTAF,这个函数⽬前只能在 Table API 中使⽤,不能在 SQL API 中使⽤。
函数功能:
在 SQL 表达式中,如果想对数据先分组再进⾏聚合取值:
select max(xxx) from source_table group by key1, key2
上⾯ SQL 的 max 语义产出只有⼀条最终结果,如果想取聚合结果最⼤的 n 条数据,并且 n 条数据,每⼀条都要输出⼀次结果数据,上⾯的 SQL 就没有办法实现了。
所以 UDTAF 为了处理这种场景,可以⾃定义 怎么取 , 取多少条 最终的聚合结果,UDTAF 和 UDAF 是类似的。
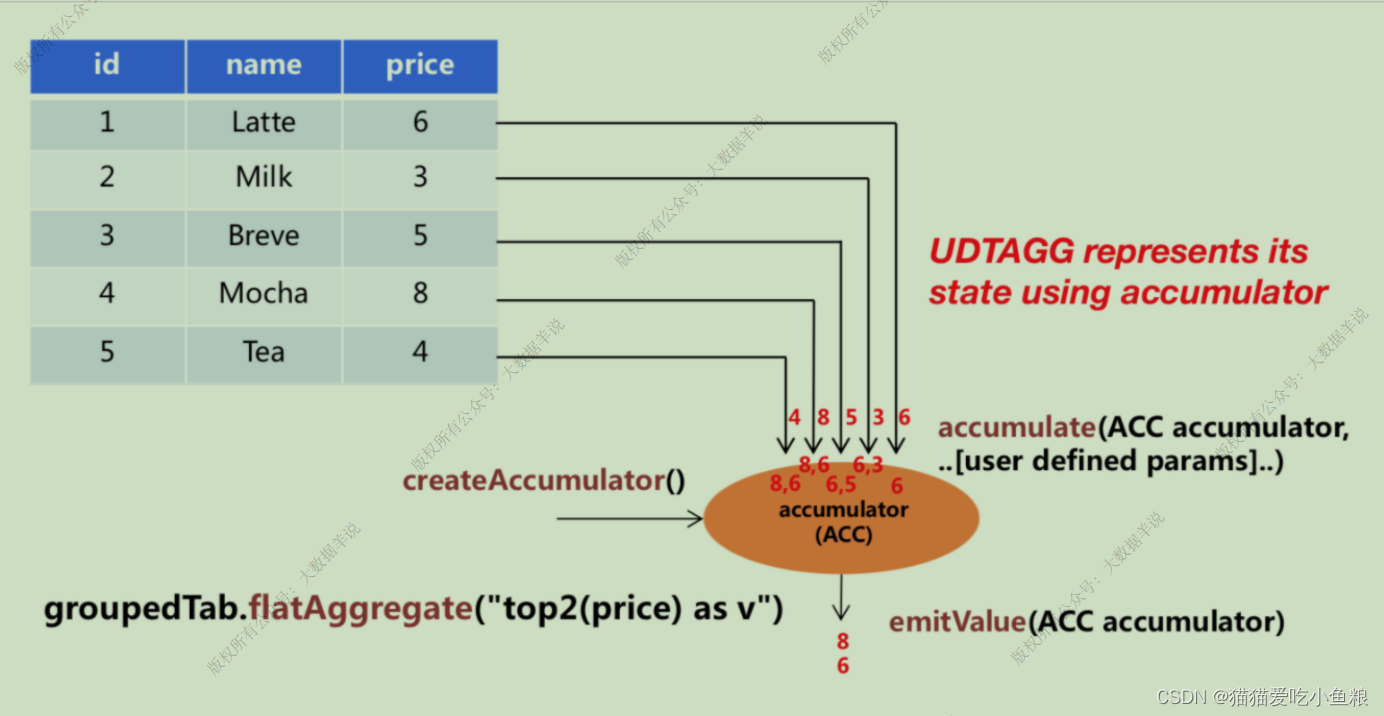
案例场景: 有⼀个饮料表有 3 列,分别是 id、name 和 price,⼀共有 5 ⾏,需要找到价格最⾼的两个饮料,类似于 top2,表值聚合函数,需要遍历所有 5 ⾏数据,输出结果为 2 ⾏数据的⼀个表。
开发流程:
实现 TableAggregateFunction 接⼝,其中所有的⽅法必须是 public 的、⾮ static 的
必须实现以下⽅法:
Acc聚合中间结果 createAccumulator() : 为当前 Key 初始化⼀个空的 accumulator,存储了聚合的中间结果,⽐如在执⾏ max() 时会存储每⼀条中间结果的 max 值;
accumulate(Acc accumulator, Input输⼊参数) : 每⼀⾏数据,都会调⽤ accumulate() ⽅法更新 accumulator,⽅法对每⼀条输⼊数据执⾏,⽐如执⾏ max() 时,遍历每⼀条数据执⾏;这个⽅法必须声明为 public 和⾮ static 的,accumulate ⽅法可以重载,每个⽅法的参数类型可以不同,⽀持变⻓参数。
emitValue(Acc accumulator, Collector collector) 或者 emitUpdateWithRetract(Acc accumulator, RetractableCollector collector) :
当所有的数据处理完之后,调⽤ emit ⽅法来计算和输出最终结果,可以⾃定义输出多少条以及怎样输出结果。
对于 emitValue 以及 emitUpdateWithRetract 区别,以 TopN 举例,emitValue 每次都会发送所有的最⼤的 n 个值,⽽这在流式任务中会有性能问题,为提升性能,可以实现 emitUpdateWithRetract ⽅法,这个⽅法在 retract 模式下会增量输出结果,⽐如只在有数据更新时,做到撤回⽼数据,再发送新数据,⽽不需要每次都发出全量的最新数据。
如果同时定义了 emitUpdateWithRetract、emitValue ⽅法,那 emitUpdateWithRetract 会优先于 emitValue ⽅法被使⽤,因为引擎会认为 emitUpdateWithRetract 会更加⾼效,它的输出是增量的。
某些场景下必须实现:
- retract(Acc accumulator, Input输⼊参数) : 回撤流的场景必须实现,在计算回撤数据时调⽤,如果没有实现则会直接报错。
- merge(Acc accumulator, Iterable it) : 在批式聚合以及流式聚合中的 Session、Hop 窗⼝聚合场景必须实现,这个⽅法对优化也有帮助,例如,打开了两阶段聚合优化,需要 AggregateFunction 实现 merge ⽅法,从⽽在第⼀阶段先进⾏数据聚合。
- resetAccumulator() : 在批式聚合中是必须实现的。
关于⼊参、出参数据类型:
默认情况下,⽤户的 Input输⼊参数( accumulate(Acc accumulator, Input输⼊参数) 的⼊参 Input输⼊参数 )、accumulator( Acc聚 合中间结果 createAccumulator() 的返回结果)、 Output输出参数 数据类型( emitValue(Acc acc,Collector<Output输出参数> out) 的 Output输出参数 )会被 Flink 反射获取,但对于accumulator 和 Output输出参数类型来说,Flink SQL 的类型推导在遇到复杂类型的时候可能会推导出错误的结果(注意: Input输⼊参数 因为是上游算⼦传⼊的,所以类型信息是确认的,不会出现推导错误的情况),⽐如那些⾮基本类型 POJO 的复杂类型,所以跟 ScalarFunction 和 TableFunction ⼀样, AggregateFunction 提供了TableAggregateFunction#getResultType() 和 TableAggregateFunction#getAccumulatorType() 来分别指定最终返回值类型和accumulator 的类型,两个函数的返回值类型都是 TypeInformation。
- getResultType() : 即 emitValue(Acc acc, Collector<Output输出参数> out) 的输出结果数据类型;
- getAccumulatorType() : 即 Acc聚合中间结果 createAccumulator() 的返回结果数据类型;
案例场景: Top2
定义⼀个 TableAggregateFunction 来计算给定列的最⼤的 2 个值
在 TableEnvironment 中注册函数
在 Table API 查询中使⽤函数(当前只在 Table API 中⽀持 TableAggregateFunction)
实现思路:
计算最⼤的 2 个值,accumulator 需要保存当前的最⼤的 2 个值,定义了类 Top2Accum 作为 accumulator,Flink 的 checkpoint 机制会⾃动保存 accumulator,在失败时进⾏恢复,来保证精确⼀次的语义。
Top2 表值聚合函数(TableAggregateFunction)的 accumulate() ⽅法有两个输⼊,第⼀个是 Top2Accum accumulator,另⼀个是⽤户定义的输⼊:输⼊的值 v,尽管 merge() ⽅法在⼤多数聚合类型中不是必须的,但在样例中提供了它的实现。并且定义了 getResultType() 和 getAccumulatorType() ⽅法。
代码案例:
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.TableAggregateFunction;
import org.apache.flink.util.Collector;
/**
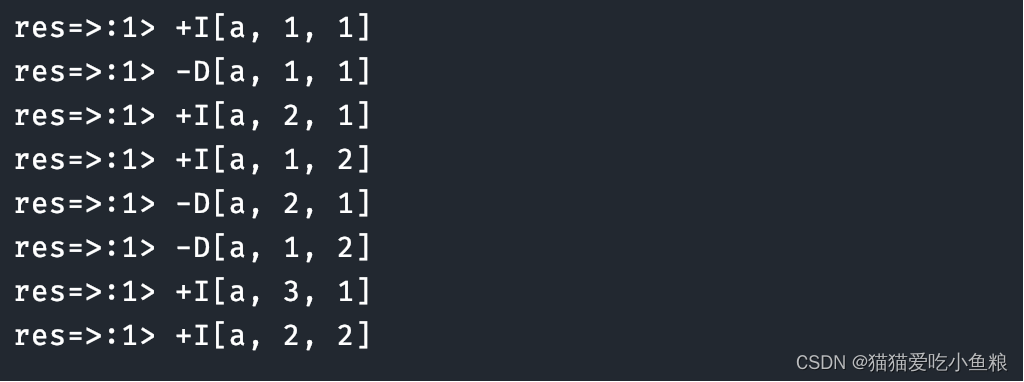
* 输入数据:
* a,1
* a,2
* a,3
*
* 输出结果:
* res=>:1> +I[a, 1, 1]
* res=>:1> -D[a, 1, 1]
* res=>:1> +I[a, 2, 1]
* res=>:1> +I[a, 1, 2]
* res=>:1> -D[a, 2, 1]
* res=>:1> -D[a, 1, 2]
* res=>:1> +I[a, 3, 1]
* res=>:1> +I[a, 2, 2]
*/
public class TableAggregateFunctionTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings);
DataStreamSource<String> source = env.socketTextStream("localhost", 8888);
SingleOutputStreamOperator<Tuple2<String,Integer>> tpStream = source.map(new MapFunction<String, Tuple2<String,Integer>>() {
@Override
public Tuple2<String,Integer> map(String input) throws Exception {
return new Tuple2<>(input.split(",")[0],Integer.parseInt(input.split(",")[1]));
}
});
tEnv.registerFunction("top2", new Top2());
Table table = tEnv.fromDataStream(tpStream, "key,value");
tEnv.createTemporaryView("SourceTable", table);
// 使⽤函数
Table res = tEnv.from("SourceTable")
.groupBy("key")
.flatAggregate("top2(value) as (v, rank)")
.select("key, v, rank");
tEnv.toChangelogStream(res).print("res=>");
env.execute();
}
/**
* Accumulator for Top2.
*/
public static class Top2Accum {
public Integer first;
public Integer second;
}
public static class Top2 extends TableAggregateFunction<Tuple2<Integer, Integer>, Top2Accum> {
@Override
public Top2Accum createAccumulator() {
Top2Accum acc = new Top2Accum();
acc.first = Integer.MIN_VALUE;
acc.second = Integer.MIN_VALUE;
return acc;
}
public void accumulate(Top2Accum acc, Integer v) {
if (v > acc.first) {
acc.second = acc.first;
acc.first = v;
} else if (v > acc.second) {
acc.second = v;
}
}
public void merge(Top2Accum acc, java.lang.Iterable<Top2Accum> iterable) {
for (Top2Accum otherAcc : iterable) {
accumulate(acc, otherAcc.first);
accumulate(acc, otherAcc.second);
}
}
public void emitValue(Top2Accum acc, Collector<Tuple2<Integer, Integer>> out) {
// emit the value and rank
if (acc.first != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.first, 1));
}
if (acc.second != Integer.MIN_VALUE) {
out.collect(Tuple2.of(acc.second, 2));
}
}
}
}
测试结果:
版权归原作者 猫猫爱吃小鱼粮 所有, 如有侵权,请联系我们删除。