
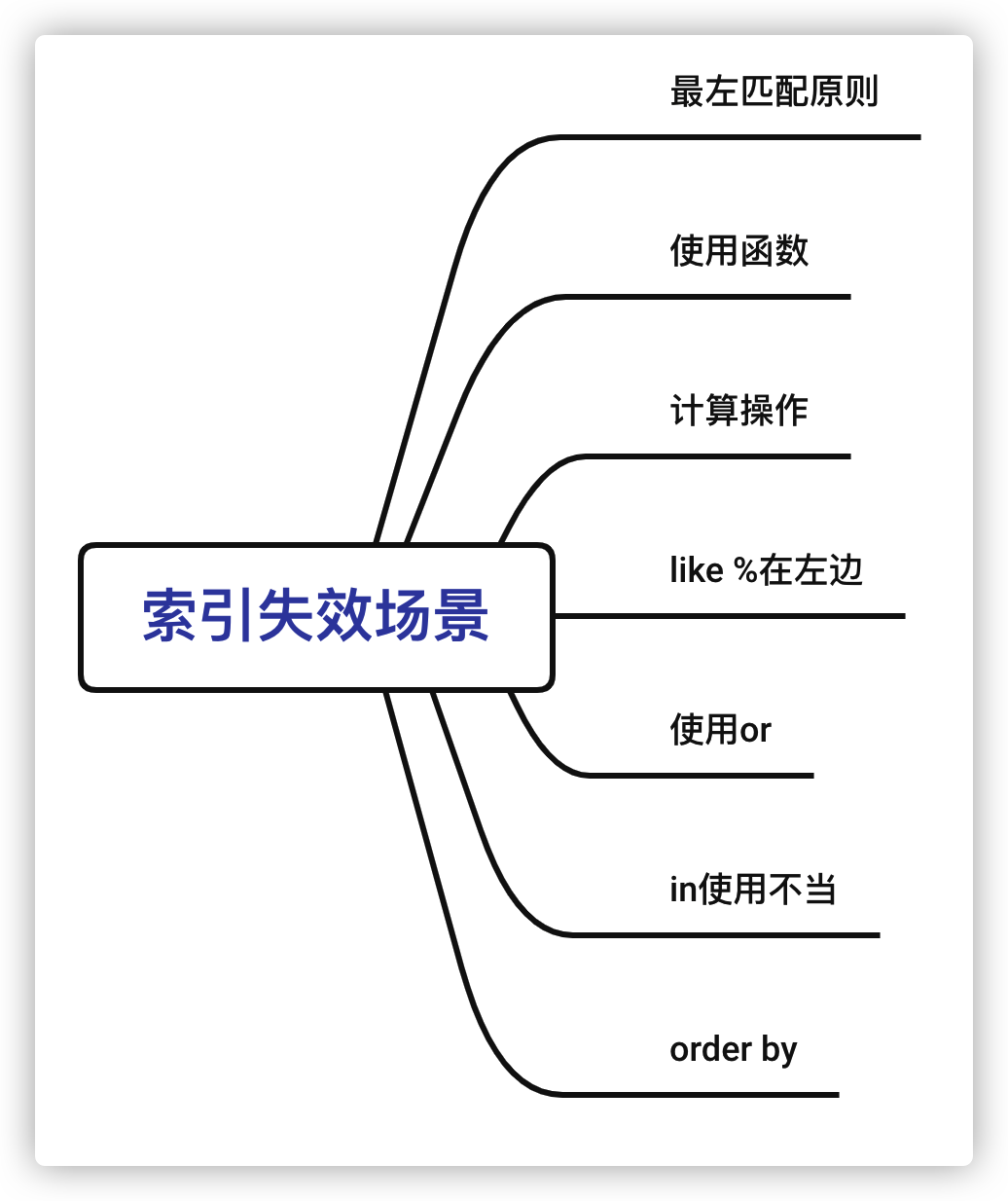
索引失效的7个原因
实际工作以及面试中,应该经常会遇到SQL相关的问题,而这些问题中,索引失效的场景又是一个常客。下面总结一下索引失效的场景,一共7种,索引失效的原因逃不过这7个。
概述
主要内容如下:
先创建一张表用于测试,表中创建了三个索引(MySQL版本8.0.26)
- 主键索引 id
- 普通索引 age
- 联合索引 name,code,address
SET NAMES utf8mb4;SET FOREIGN_KEY_CHECKS =0;-- ------------------------------ Table structure for user-- ----------------------------DROPTABLEIFEXISTS`user`;CREATETABLE`user`(`id`int(11)NOTNULLAUTO_INCREMENT,`name`varchar(20)CHARACTERSET utf8 COLLATE utf8_general_ci NOTNULL,`code`int(100)NULLDEFAULTNULL,`address`varchar(100)CHARACTERSET utf8 COLLATE utf8_general_ci NULLDEFAULTNULL,`age`int(11)NULLDEFAULTNULL,`create_time`datetime(0)NOTNULLONUPDATECURRENT_TIMESTAMP(0),PRIMARYKEY(`id`)USINGBTREE,INDEX`普通索引`(`age`)USINGBTREE,INDEX`联合索引`(`name`,`code`,`address`)USINGBTREE)ENGINE=InnoDBAUTO_INCREMENT=5CHARACTERSET= utf8 COLLATE= utf8_general_ci ROW_FORMAT = Dynamic;-- ------------------------------ Records of user-- ----------------------------INSERTINTO`user`VALUES(1,'海绵宝宝',1001,'上海',23,'2022-11-02 20:44:14');INSERTINTO`user`VALUES(2,'章鱼哥',1002,'北京',22,'2022-11-02 20:44:16');INSERTINTO`user`VALUES(3,'派大星',1003,'苏州',23,'2022-11-02 20:44:19');INSERTINTO`user`VALUES(4,'蟹老板',1004,'南通',24,'2022-11-02 20:44:25');
1. 最左匹配原则
最左匹配原则就是指在联合索引中,如果你的 SQL 语句中用到了联合索引中的最左边的索引,那么这条 SQL 语句就可以利用这个联合索引去进行匹配,并且最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
首先思考下下面这些SQL会不会走到索引:
1、select create_time fromuserwhere name ="派大星"-- 会走索引吗?2、select create_time fromuserwhere code =1-- 会走索引吗?3、select create_time fromuserwhere address ="上海"-- 会走索引吗?4、select create_time fromuserwhere address ="上海"and code =1-- 会走索引吗?5、select create_time fromuserwhere address ="上海"and name ="派大星"-- 会走索引吗?6、select create_time fromuserwhere name ="派大星"and address ="上海"-- 会走索引吗?7、select create_time fromuserwhere code =1and name ="派大星"and address ="上海"-- 会走索引吗?8、select create_time fromuserwhere name ="派大星"and code =1and address ="上海"-- 会走索引吗?
答案是有1、5、6、7和8会走索引。
执行SQL1,分析执行计划:
explainselect create_time fromuserwhere name ="派大星"

可以看到,其使用了联合索引,只扫描了1行。
执行SQL2,分析执行计划:
explainselect create_time fromuserwhere code =1

没有使用索引,进行了全表扫描,rows=4。
SQL3-4可以自行验证,都没有走到索引。
执行SQL5,分析执行计划:
explainselect create_time fromuserwhere address ="上海"and name ="派大星"

使用了联合索引。
执行SQL6,分析执行计划:
explainselect create_time fromuserwhere name ="派大星"and address ="上海"

使用了联合索引。
执行SQL7,分析执行计划:
explainselect create_time fromuserwhere code =1and name ="派大星"and address ="上海"

使用了联合索引。
执行SQL8,分析执行计划:
explainselect create_time fromuserwhere name ="派大星"and code =1and address ="上海"

使用了联合索引。
SQL8能够使用到联合索引的原因,是他的查询条件的顺序,和联合索引的字段顺序是一致的,所以满足最左匹配原则。
可能会有疑惑,5和6不是没有满足最左匹配原则嘛,为什么还会使用到联合索引?
这是个好问题,因为MySQL会使用优化器对SQL进行优化,自动改写为最优查询语句,也就能够使用到联合索引。
但对于SQL5和6,虽然能使用联合索引,但是只走name字段索引,不会走address字段。
那什么又叫”同时遇到范围查询(>、<、between、like)就会停止匹配“呢?
看下面一个例子,改造下SQL7:
explainselect create_time fromuserwhere code >1and name ="派大星"and address ="上海"
把code=1改为code>1,执行:

虽然也使用了联合索引,但是她的type是range。而改造前的type如下图是ref:

那么type位range和ref的区别是什么呢?

可以理解为:range是范围查找,ref是索引查找。
根据官方描述,扫描方式从快到慢依次是:

也就是说,**遇到范围查询(>、<、between、like)**后,后面的字段就不会进行索引匹配了,也就是需要走范围扫描了。
最左匹配规则的原理
我们要知其然也要知其所以然,不能不求甚解。最左匹配的原来是什么呢?其实和MySQL存储引擎使用的存储数据结构有关。
我们都知道,MySQL的默认存储引擎是InnoDB,InnoDB的存储结构使用的是B+树,索引也是一棵B+树。
联合索引是非聚集索引。(聚集索引和聚集索引的区别可以参考这篇文章)
联合索引的B+树节点中存储的是键值。由于构建一棵B+树只能根据一个值来确定索引关系,所以数据库依赖联合索引最左的字段来构建。(看晕了吧,哈哈哈哈,谁看了不晕!!)看下面的图,比较直观,假如创建一个(a,b,c)的联合索引,那么它的索引树是这样的:
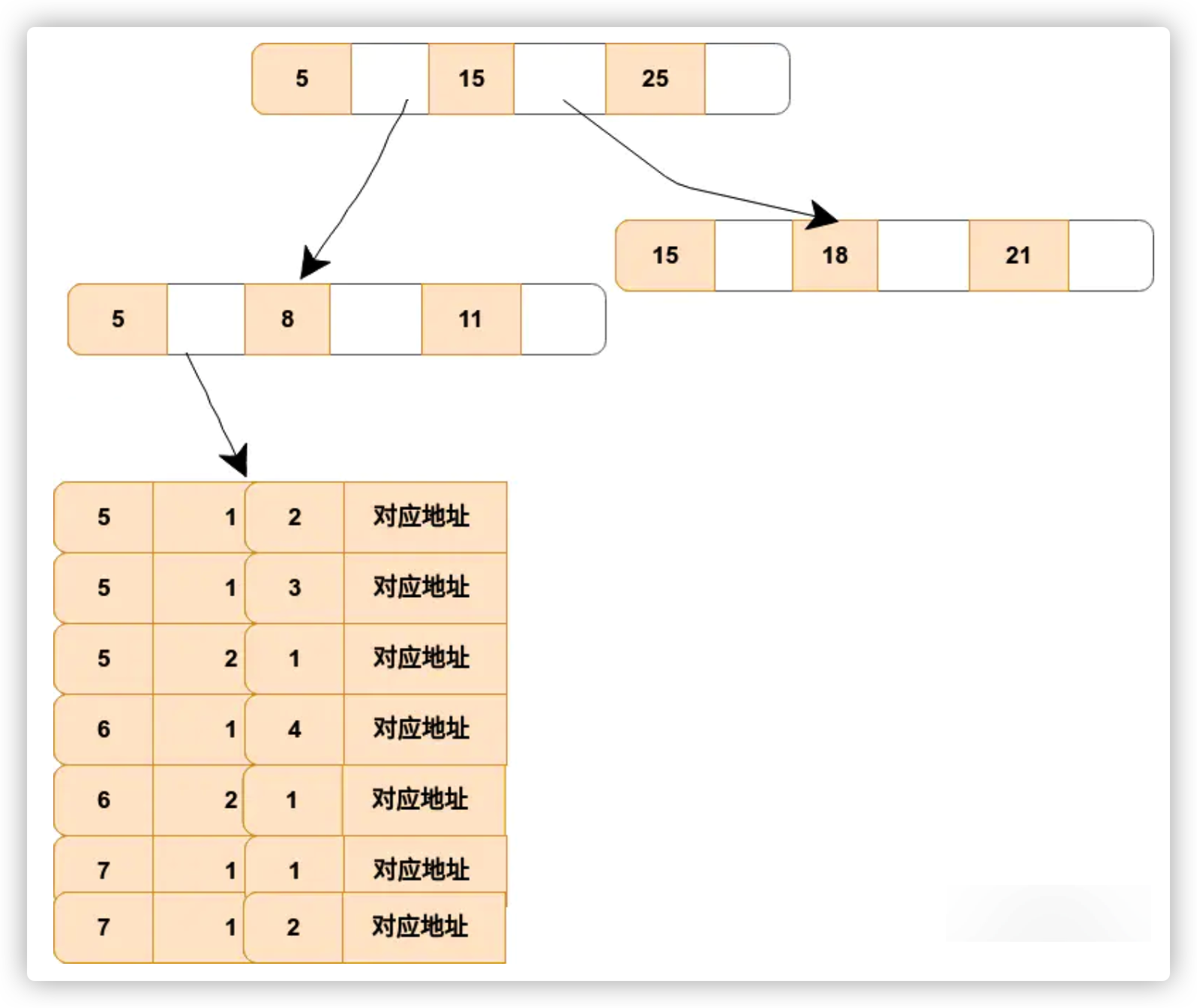
其中的非叶子节点存储的是第一个关键字的索引 a,而叶子节点存储的是三个关键字(a,b,c)的数据,如[5,1,2]代表a,b,c三个字段的数据。
可以看出来他的特点:
- a是有序的:5,5,5,6,6,7,7
- b,c无序
- 当a等值时,b有序。如a=5,b为1,1,2
- 当a,b等值时,c有序。如a=5,b=1,c为2,3
也就是说,后一个字段,需要前字段的支持才能形成有序。
最左匹配小结:
如果创建 b,c,d 联合索引面
- 如果 我where 后面的条件是
c = 1 and d = 1为什么不能走索引呢 如果没有b的话 你查询的值相当于*11我们都知道*是所有的意思也就是我能匹配到所有的数据 - 如果 我 where 后面是
b = 1 and d =1为什么会走索引呢?你等于查询的数据是1*1我可以通过前面 1 进行索引匹配 所以就可以走索引 - 最左缀匹配原则的最重要的就是 第一个字段
下面看下一个失效场景。
2. 使用函数
在select后面使用函数可以使用索引:
explainselectsum(id)fromuserwhere code =1001

但是在where语句后面使用函数,是不能使用索引的:
explainselect create_time fromuserwhere length(name)=3

因为索引保存的是索引字段的原始值,而不是经过函数计算后的值,自然就没办法走索引了。
3. 计算操作
和使用函数一样,导致索引失效是因为改变了索引原来的值 在树中找不到对应的数据只能全表扫描。
explainselect create_time fromuserwhere code-1=3

因为索引保存的是索引字段的原始值,而不是 code - 1 表达式计算后的值,所以无法走索引,只能通过把索引字段的取值都取出来,然后依次进行表达式的计算来进行条件判断,因此采用的就是全表扫描的方式。
小结:影响到索引列的值,索引就会失效
4. Like %
Like 通配符有什么:
- %:表示任意字符出现任意的次数(类似正则表达式总的.)
- _:表示匹配单个字符
like就是只是MySQL后面的搜索模式利用通配符。
需要注意:
使用 like 但是没有使用通配符,效果和使用 = 一样,如:
SELECT*FROM products WHERE products.prod_name like'1000';
使用%通配符造成索引失效的场景主要是**%在左边**:
explainselect create_time fromuserwhere name like'%派大星'

失效的原因是模糊查询范围比较大,没有使用索引的必要了。
%在右边是不会失效的:
explainselect create_time fromuserwhere name like'派大星%'

小结:%在左边失效,%在右边不失效
5. 使用Or导致索引失效
在 WHERE 子句中,如果在 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列,那么索引会失效。
explainselect create_time fromuserwhere code =1001or name ='派大星'

优化方式就是在Or的时候两边都加上索引。
6. in使用不当
In 不是一定会造成全表扫描的 IN肯定会走索引,但是当IN的取值范围较大时会导致索引失效,走全表扫描。
in 在结果集 大于30%的时候索引失效
not in 和 In的失效场景相同
不失效的场景:
explainselect create_time fromuserwhere age in(22)

失效的场景:
explainselect create_time fromuserwhere age in(21,22,23,24)

7. order By
失效场景:
explainselect create_time fromuserorderby age

MySQL执行有两种方案:
- 走索引 + 回表
- 不走索引 直接全表扫描
MySQL任务直接全表扫描更快,所以就没有走索引。
8. 总结
索引失效的具体场景有7种:
- 未遵循最左匹配原则
- 使用函数
- 计算操作
- like %在左边
- 使用or
- in 使用不当
- order by
9. 补充 SELECT *
select * 和走不走索引无关,但会影响效率。
使用sekect * 存在的问题:
- 增加查询分析器解析成本。
- 增减字段容易与 resultMap 配置不一致。
- 无用字段增加网络 消耗,尤其是 text 类型的字段。
为什么会音响改那个效率,这就涉及到聚集索引和非聚集索引了。我们创建的联合索引是非聚集索引,非聚集索引的B+树的叶子节点只存储了某些列,那么需要select * 的话,只查联合索引的B+树是不够的,需要经过回表查询聚集索引,从而查出所有的数据。
因为经历了回表,自然效率就低了很多。
关于聚集索引和非聚集索引,可以看这篇文章。
参考
https://mp.weixin.qq.com/s/R91WyEIXVh2_tvczVHOq9A
版权归原作者 迷思特王 所有, 如有侵权,请联系我们删除。