
1、服务器之间数据文件传递
1)服务器之间传递数据,依赖ssh协议
2)http协议是web网站之间的通讯协议,用户可已通过http网址访问到对应网站数据
3)ssh协议是服务器之间,或windos和服务器之间传递的数据的协议。支持shell指令的传输
4)在linux中默认自带ssh客户端,可以使用ssh指令进行服务器连接
ssh 用户@ip地址或域名


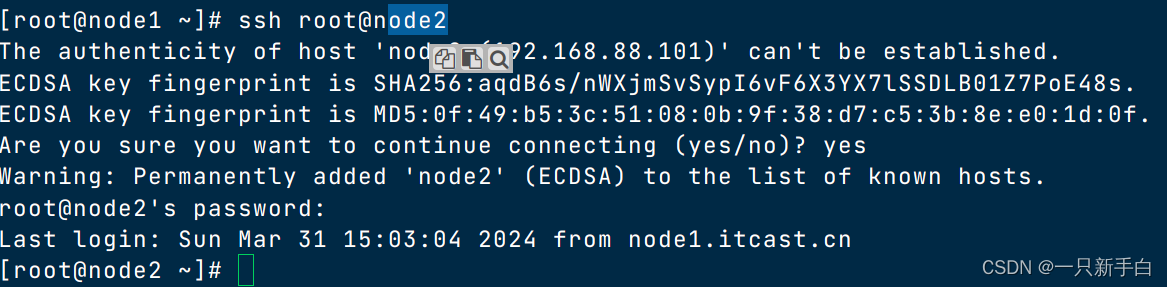

ssh免密登录
每次登录不需要再输入密码
分别在node1、node2、node3上执行如下命令
1)生成密钥
ssh-keygen
2)分别拷贝密钥
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
3)基于ssh协议进行服务器之间的文件或者目录的传输
使用指令scp
scp -r 本机文件或目录路径 目标服务器名:目标服务器路径

2、解压和压缩
tar xvf 压缩包文件
x 代表解压
v 显示解压详情
f 代表解压文件
1)压缩
tar cvf 压缩包名.tar.gz 文件或者目录
3、数据导论[了解]
日常生活中不断产生各类数据,通过对各类数据的分析,得到用户的行为习惯,发现用户的数据价值
4、大数据诞生[了解]
随着用户数据增多传统数据处理方式无法满足海量数据处理的需求,此时引入分布式技术
将海量数据进行分布式的存储,计算,资源调度
可以统一管理多台服务器进行存储和计算,把多台服务器当成一个整体
使用hadoop实现分布式存储,计算和资源调度
5、大数据概述[了解]
大数据主要解决海量数据的存储和计算
海量数据
excel KB MB 1MB=1024KB
mysql GB TB 1GB =1024 MB 1TB =1024GB
大数据 PB,EB(海量数据) 1PB=1024TB
KB < MB < GB < TB < PB < EB < ZB < YB
6、大数据的特点
数据量大- 数据种类多- 结构化数据- 表- 半结构化数据- xml- json- 非结构数据- 文本数据
- 数据低价值密度- 分析用户的消费习惯- 用户注册基本信息 姓名,性别,年龄 1个- 用户的购买信息 订单数据 手机,2023-10-22 100个- 用户浏览信息 浏览哪些商品 100个- 用户访问信息 访问网站时间,地点,设备 100000条- 1000201条数 有价值的数据200条
- 增长速度快- 每天都会产生大量数据
- 数据结果质量高- 对海量数据结果更接近真实情况
7、大数据软件生态[了解]
存储:Apache Hadoop HDFS、Apache HBase、Apache Kudu、云平台
计算:Apache Hadoop MapReduce、Apache Spark、Apache Flink
传输:Apache Kafka、Apache Pulsar、Apache Flume、Apache Sqoop
8、Apache Hadoop概述[了解]
** 1)Hadoop的功能组件**
HDFS分布式文件存储系统: 负责海量数据的存储工作
MapReduce分布式计算框架: 负责海量数据的计算工作
Yarn分布式资源调度工具: 负责分布式集群的资源调度工作
** 2)Hadoop发展**
创始人: 道格·卡丁
Hadoop发行时间: 2008年
hadoop的发展受谷歌的三篇论文影响, 后被称为大数据发展的三驾马车
** 3)Hadoop版本**
社区版: 开源免费
- 优点: 更新速度快,技术新
- 缺点: 兼容性差不稳定
商业版: CDH 将所有大数据相关组件都重写了一遍并进行了精细测试解决了兼容性问题和稳定性问题
- 优点: 兼容稳定性好
- 确定: 技术旧,收费
注意: 在企业级开发中我们使用的大多是商业版hadoop, CDH版本Hadoop在6.2.4版本之前是不收费的.
9、为什么需要分布式存储[了解]
数据体量过大,存储在同一台服务器上空间不足,所以需要对于服务器进行扩展,多台服务共同存储超大文件
存储原理就是将大文件进行分割,分割后,将数据存储在不同的服务器内部
此时不仅可以提供多台服务器的存储空间,同时可以增加服务器的读写效率,cpu,内存,网络带宽等.
版权归原作者 一只新手白 所有, 如有侵权,请联系我们删除。