
背景
公司的在线设计稿平台的画板列表页开发时由于数据量不足,未能测出关于画板列表页性能问题,在经过用户一段时间的使用后出现了关于初始化卡顿、缩放卡顿等问题,画板列表页采用了
vue-konva
原因
关于画板列表为何卡顿有如下几点原因
1、首先最简单的,在菜单列表的更多按钮下有「移动分组」的操作,此操作按钮下是一个列表大概类似下图
比较致命的缺陷是这个「更多菜单」及其子项都是循环渲染出来的,在数据量较大情况下就会执行大量渲染工作从而阻塞js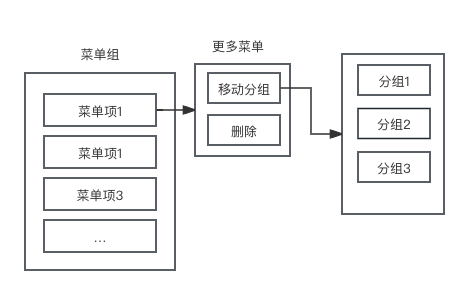
2、新增了一个关于鹰眼地图的功能,此功能的一个子功能有一个可以支持多张画板快速对齐的功能,此操作会非常耗时,即使只有两张画板执行此操作也是。
3、画板列表加载问题,在画板列表页初始化加载的时候会获取所有的画板,每个画板其实就是一个image,设计之初为了加载速度将图片的质量下降为1/2倍图,但是后来经过多次迭代后低倍图无法满足用户需求,所以追加了一条逻辑是当图片加载完毕后加载4倍图,这就导致请求直接翻倍,而且图片大小也激增,这也导致我们初始化加载的时候感觉到异常卡顿
4、缩放卡顿问题这是如下原因导致
- 图片数量过多:如果你在 Canvas 上绘制了几百个图片,那么每次进行缩放操作时,浏览器需要重新计算和渲染所有的图像。这个计算和渲染的过程对于大量图片来说是非常耗时的,导致卡顿。
- 图片大小过大:如果你的图片尺寸过大,绘制并缩放这些图片会消耗更多的计算和内存资源。这会导致性能下降,因为浏览器需要处理更多的数据。
解决方案
1、关于「更多菜单」这个优化是将其从循环中提取出来根据鼠标hover的元素的位置将其定位到该元素旁,这样只需要渲染一次「更多菜单」
2、鹰眼地图功能不涉及DOM结构的改动所以我们将他下放到worker中去执行,如下所示
主线程
const worker =newWorker('worker.js');
worker.onmessage=function(event){const{ updateList }= event.data;// 更新坐标等操作...};consthandleSetLayout=async()=>{if(selectArtBoardList.value.length <2)return;let artboardList = artboardListResult.value.filter((item)=>
selectArtBoardList.value.includes(item.objectId));
worker.postMessage({ artboardList });};
子线程:
self.onmessage=function(event){const{ artboardList }= event.data;// 计算最大最小x, yconstxyMaxAndMinFun=(list)=>{//... };const xyMaxAndMin =xyMaxAndMinFun(artboardList);// 原本逻辑...
self.postMessage({ updateList });};
3、画板列表加载&缩放卡顿问题,将初始化加载倍率下调至1/4倍提升加载速度。改造加载高清图逻辑,我们只需要加载「视口内」的图片为高清图即可。根据用户的「缩放比例」加载不同倍率的高清图。
我们首先要解决的问题是视口问题,我们如何知道那些元素在视口中呢?所以我们首先需要在canvas上绘制一个与画布一样大小的矩形,如下所示:
<v-layer><v-rect ref="rect":config="{ ...collisionBox }"></v-rect></v-layer>/** 这会得到一个永远将画布覆盖的矩形 **/const collisionBox =ref({
width: stageConfigW.value / size.value,// 舞台宽度 / 当前比例
height: stageConfigH.value / size.value,
x:-stageConfig.value.x / size.value,// 舞台位置 / 当前比例
y:-stageConfig.value.y / size.value
});
解决了获取视口问题,我们还需要检查那些画板是被包含在「视口内」的,思路很简单我们只需要判断这个矩形包不包含某个画板的其中一个角即可,代码如下所示:
/**
@desc 判断是否在可视区域
@params1 矩形位置信息
@params2 画板位置信息
*/functioncheckArtINView(poi:any, art:any){const rectw = poi.x + poi.width;if((art.x > poi.x && art.x < rectw)||(art.x + art.width > poi.x && art.x < rectw)|| art.x < rectw){const recth = poi.y + poi.height;if((art.y > poi.y && art.y < recth)||(art.y + art.height > poi.y && art.y < recth)|| art.y < recth){returntrue;}}returnfalse;}
现在我们只需要再处理一下用户缩放时加载高清图的逻辑这里的优化就差不多了,我们需要通过当前的画布比例大小判断加载不同倍率的图片,代码如下所示:
/** 更新图片 */functionupdateArt(art: IArtboard, scale:string|number, width:number){if(art.nowImgScale == scale){return;}const img =newImage();
img.src =getImageCosPath(art.imagePath,50, width);
img.onload=()=>{
art.image = img;};
art.nowImgScale = scale;}/** 获取还在视口中的画板 */functiongetInViewArt(artList: IArtboard[]){const list = artList.filter(item =>{const isVisible =checkArtINView(collisionBox.value, item);if(isVisible){return item;}});
selectArtBoardList.value = list;
list.forEach((art: IArtboard)=>{/** 1/4倍图 */if(size.value <0.25){updateArt(art,0.25, art.width /4);}elseif(size.value >0.25&& size.value <0.8){updateArt(art,0.5, art.width /2);}elseif(size.value >0.8&& size.value <1.2){updateArt(art,1, art.width);}elseif(size.value >1.2&& size.value <1.8){updateArt(art,2, art.width *2);}else{updateArt(art,4, art.width *4);}});}
经过上述一系列改动后发现画板列表已经没有那么卡顿了,CPU平均占用率来到了60%~70%左右,比未优化前降低了30% 。
经过一系列优化我们的画板列表页已经流畅了许多但是这并不是极致的优化。
待优化
1、采用离屏渲染技术。
2、缩放防抖&拖拽防抖在这两个操作执行的过程中会进行大量的计算,计算后的数据会影响视图导致重绘,而且由于缩放事件和拖拽事件会连续触发很多次,所以需要加入防抖让其运算操作和重绘次数减少。
3、缩放逻辑不再使用原生的canvas的缩放,转而采用css3的transform,之所以这样做,是因为用css3的transform属性可以利用上GPU开启硬件加速。
总结
由于本次优化时间较短且中途方案有所改动,所以有很多待优化的点,不过就现在画板列表的性能表现来看已经流畅了许多,我们的目的已经达到了。
版权归原作者 SCE林木夕 所有, 如有侵权,请联系我们删除。