

文章链接:https://arxiv.org/pdf/2410.16770
项目链接:: https://ai.stanford.edu/˜yzzhang/projects/scene-language/
代码链接:https://github.com/zzyunzhi/scene-language

亮点直击
- 提出了一种场景表示方法,即场景语言,通过程序、词汇和 embeddings 来捕捉视觉场景的结构、语义和身份。
- 提出了一种无需训练的方法,利用预训练语言模型从文本和/或图像中推理表示。
- 提出一个通用渲染模块,将场景语言渲染成图像。
- 在文本和图像条件下的场景生成和编辑任务上获得了实证结果。
总结速览
解决的问题
- 现有的场景图表示方法在生成复杂场景时存在保真度不足的问题,缺乏精确的控制和编辑能力。
提出的方案
- 场景语言:引入了一种新的场景表示方法,通过程序、自然语言词汇和 embeddings 来描述视觉场景的结构、语义和身份。
- 无需训练的推理技术:利用预训练语言模型,从文本和/或图像中推理场景表示。
应用的技术
- 预训练语言模型:用于从文本和图像中推理场景表示。
- 图形渲染器:结合传统、神经网络或混合渲染技术,将场景语言转化为图像。
达到的效果
- 实现了高质量3D和4D场景的自动化生成系统。
- 在场景生成和编辑任务中,场景语言表现出更高的保真度和精确的控制能力。
- 提供了一个通用渲染模块,能够有效地将场景语言渲染成图像。
场景语言
旨在设计一种视觉场景表示方法,以编码场景的结构、语义和视觉内容。为此,提出了场景语言(Scene Language),它通过三个组件来表示场景:一个程序,用于通过指定场景组件(我们称之为实体)的存在和关系来编码场景结构;自然语言中的词汇,用于表示场景中每个实体的语义群组;以及神经 embeddings ,用于通过允许一个富有表现力的输入参数空间来体现实体的低层次视觉细节和身份。在接下来的内容中,将首先给出这种表示方法的正式定义,然后介绍作为其实现的领域特定语言(DSL)。
定义
场景语言对于场景 ,记作 ,其形式定义如下:

这里, 是自然语言短语的集合,被称为词语,例如,,如下图 2 所示。 是一个程序,由一组实体函数 组成,并由 索引。每个实体函数 定义了场景中的一个实体类;它由相关联的 唯一标识,简洁地总结了定义类的语义含义。每个 将神经 embeddings 映射到场景中的特定实体 ,其中 指定了 的属性和身份,例如棋子的特定颜色,而 指定了其子实体的身份。因此,特定场景 的完整场景语言 还包含一个有序的神经 embeddings 集合 ,对应于场景 中的 个特定实体 ,其中 是通过将实体函数应用于输入 计算得到的。

关键的是,程序 从三个方面捕捉场景结构。首先,每个实体函数 转换并组合多个子实体(例如,64 个方格)为一个新的、更复杂的实体(例如,一个棋盘),自然反映了场景中的层次结构和部分-整体关系,如上图 2 中的箭头所示。其次,多个实体 可能属于同一个语义类 (例如,方格),因此可以通过复用相同的实体函数 并使用不同的 embeddings 来表示。最后,每个实体函数还通过指定子实体在组合过程中的相对位置来捕捉其精确的空间布局,例如 64 个方格形成一个 的网格。
接下来,我们将详细说明如何定义 中的函数,然后是计算所表示场景 的程序执行过程。符号在下表 1 中进行了总结。

实体函数定义。 实体函数 输出一个语义类别为 的实体 。函数 接受两个输入:一个 embedding ,用于指定 的身份,以及一个有序集合 ,其中包含 的所有后代实体的 embeddings。记 为 的 个子实体,其中 是由 确定的常数。那么,我们有 ,其中 和 分别是 的 embeddings和 的后代实体的 embeddings。因此, 递归定义为
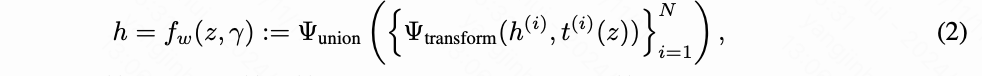
其中, 是 的一个子实体, 指定其姿态。这里, 通过两种操作指定从 个子实体 获取输出 的计算过程: 应用一个依赖于输入的姿态 到子实体 上,将其从其标准框架转换到 的世界框架中; 将多个子实体组合成一个单一的实体。每个子实体 是通过递归应用实体函数 计算得出的,该函数也使用方程 (2) 定义。例如,设 表示生成上图 2 中棋盘的实体函数(即,)。这个函数 由 64 个相同类别的子实体 组成,这些子实体通过执行相同的实体函数 ,但使用不同的 embeddings 和 获得。
程序执行。 为了从场景语言 中获取场景 ,程序执行器识别出一个根实体函数 ,该函数在 中不依赖于任何其他函数(例如,上图 2 中的 ),并使用第一个 embeddings 和其余 embeddings作为其后代,,来评估这个根函数以获得 。评估 会将计算递归扩展到其子函数 ,如方程 (2) 所定义,从而获得场景中所有实体 的完整序列,其中 。在 中的顺序对应于从 开始的计算图的深度优先搜索。上图 2 右侧展示了一个示例计算图。
场景语言作为编程语言
现在通过下表2中指定的领域特定语言(DSL)来具体化前文中的定义。为了在DSL中定义实体函数,我们引入了宏操作:用于 的
union
,在for循环中对实体调用
union
的
union-loop
,以及用于 的
transform
。我们使用这四个宏操作和依赖函数的函数调用来定义实体函数。实体函数通过两种特殊形式与DSL中的关联词汇进行识别:
bind
,将实体函数 绑定到词汇 ;
retrieve
,给定 检索 并将 应用于实际的 embeddings参数。如果 从未绑定到一个函数,它对应于没有子实体的实体函数(即,方程(2)中的 ),在这种情况下,调用返回一个没有子节点的原始实体。

实体 (方程(2))的数据类型表示为
Entity
。它存储两个数据字段
Word
和
Embedding
,分别描述实体的语义组和身份,并将每个子实体及其在 框架中的位置一起存储。特别地,
Embedding
捕捉视觉细节,需要一种高度表达的表示,例如神经 embeddings。我们采用OpenCLIP-ViT/H的文本 embeddings空间进行参数化,记为 。它的优势在于 embeddings可以直接从自然语言编码,或通过文本反演从图像推理。上表1总结了与上节符号相对应的表达式和数据类型。
渲染
将所提出的场景表示应用于图像生成任务需要将场景语言 渲染为图像。为此,首先,程序解释器评估 以获得类型为
Entity
的数据对象。随后,图形渲染器将
Entity
数据对象映射到其渲染参数空间,并将其渲染为最终图像。
渲染器规格。我们定义图形渲染器的规格,这是所提表示中的一个模块,如下所示。图形渲染器由原始参数空间 和渲染操作 确定,其中 是表示姿态的 3D 仿射变换空间, 表示所有可能的子集,而 是渲染图像的空间。为了确定从程序执行输出类型
Entity
(下图 3b)到渲染操作 的可接受输入域(下图 3c)的映射,我们假设访问重参数化函数 ,该函数将从
Tuple[Word, Embedding]
映射到 ,并通过沿实体层次结构中从原始到场景(根)的路径相乘所有矩阵值来计算原始的姿态 ,类似于在运动学树中计算肢体姿态。

渲染器实例化。一个渲染器实例化的例子是使用 Score Distillation Sampling (SDS) 指导,其中 是一个可微的 3D 表示,我们指定 如下。回忆一下,一个实体与一个
Word
值相关联,例如,上图 1 和 上3 中的一个雕像的
moai
,以及一个
Embedding
值,例如
<z2>
。对于每个原始实体(即没有子实体的实体),给定这两个值字段以及其祖先的字段,我们使用手动指定的语言模板 ,例如
<z2> moai
,风格为
<z1>
,在此例中为 3D 模型,将它们 embeddings到 ,其中 是预训练的 CLIP 文本编码器。然后, 对应于 SDS 指导的优化,以在 中找到与输入条件 对齐的解决方案。通过编辑 embeddings,例如控制上图 1 中全局风格的
<z1>
,可以个性化输出的 3D 场景。
对于基础的3D表示,我们使用3D高斯散射,其中图像通过将一组3D高斯投影到图像平面上进行渲染;其他可微的3D表示,如神经场,也同样适用。我们的实现基于GALA3D,并使用MVDream和深度条件的ControlNet进行指导。
我们将上述渲染器称为高斯渲染器。其他可能的渲染器包括基于原始图形的渲染器,例如使用立方体、球体和圆柱体等图形原语的Mitsuba;基于资产的游戏引擎,例如Minecraft;以及布局条件的文本到图像(T2I)扩散模型的前馈推理,例如MIGC,通过控制Stable Diffusion的注意力层实现二维边界框条件。下表3展示了总结。

通过预训练语言模型进行推理
我们介绍了一种无需训练的方法,从场景的文本或图像描述中推理表示。如下面所述,我们首先提示一个预训练的语言模型(LM)生成非神经组件,然后通过CLIP文本编码器从文本中获取神经 embeddings,或者通过预训练的文本到图像扩散模型从图像中获取神经 embeddings。
语言模型在使用常见编程语言(如Python)进行代码生成方面表现出色。在我们的实现中,我们提示语言模型生成Python脚本。我们使用输入条件提示语言模型,即文本或图像中的场景描述;从上表2中的DSL转换而来的辅助函数的Python脚本;以及使用辅助函数的示例脚本。我们在所有实验中使用Claude 3.5 Sonnet作为我们的方法和依赖于LM的基线。
在语言模型生成的脚本中,函数参数(数值或字符串标记)使用语言模板和CLIP文本编码器从转换为 embeddings。例如,在原始语言模型输出中,上图2中的白色棋子的函数调用具有输入属性{"color":(.9,.9,.9)},我们提示语言模型将颜色值描述为一个词,并将该词输入到中以计算。对于图像条件任务,对于的执行输出中的每个基本实体,我们首先使用GroundingSAM分割出与实体相关的词定义的区域。然后,我们使用文本反演优化一个 embeddings,以扩散模型的训练目标重建裁剪后的图像。
应用领域
将前文中的方法应用于文本条件的3D场景生成和编辑、图像条件的场景生成以及4D场景生成任务。
文本条件场景生成
基线。 为了评估所提出的表示方法,将我们的推理流程与使用其他中间表示(例如场景图)的3D场景生成方法进行比较。特别地,将其与GraphDreamer作为示例方法进行比较,该方法通过语言模型提示从输入文本生成场景图,然后在SDS引导下生成基于图的场景。进一步通过将我们的结构表示与基于SDS的渲染器的骨干方法MVDream进行比较,来研究结构表示在此任务中的作用,后者是一种直接的场景生成方法。
结果。 使用基于SDS的渲染器渲染的文本条件场景生成结果如下图4所示。与直接3D场景生成方法MVDream相比,我们的方法具有组合性,并且在涉及多个对象的场景中更紧密地遵循输入提示。与场景图表示相比,其中实体关系被限制为两个对象之间,并且受到自然语言描述粗糙程度的限制,例如“排列成一排”,基于程序的表示提供了更灵活和精确的关系规范,例如下图4中特定的可乐罐排列。这带来了实用的好处,即将涉及复杂实体关系的场景生成的负担从T2I模型(用于我们的方法和GraphDreamer的SDS指导)转移到语言模型上,从而实现准确和详细的生成结果。
为了定量比较我们的方法与基线方法,我们进行了用户研究。在研究中,用户被要求从我们的方法和两个基线方法随机生成的三个动画场景中选择一个与文本提示最为一致的场景。我们还报告了合成场景中对象数量是否正确。如下表4所示,我们的方法在提示对齐方面比基线方法更具优势,并且在计数准确性上有明显的优势。

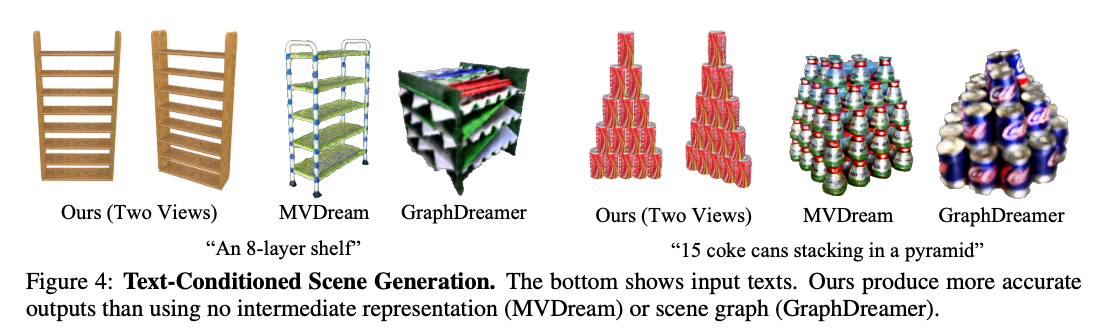
文本指导的场景编辑
从我们提出的表示方法生成的场景可以通过使用语言模型(LM)和自然语言编辑指令对其先前生成的脚本进行编辑。结果如下图5所示。我们的表示方法为场景编辑提供了一个可解释且直观的界面,因为函数具有与词语相关的明确语义意义,并且函数重用显著提高了程序的可读性。此外,由于程序的结构反映了场景的结构,编辑程序参数会导致场景发生变化,同时保留原有结构,例如下图5中的楼梯的环形排列。涉及多个基本体的理想编辑效果,例如在这个例子中所有楼梯,可以通过在程序空间中进行微小的更改来有效实现。最后,程序结构本身,例如Jenga积木集示例中的函数头,可以进行调整以实现仅影响场景相关部分的局部编辑。
我们的表示方法的组合性直接有利于局部场景编辑。相比之下,前文的MVDream不适用于此任务,因为整个场景是用单一的3D表示进行参数化的。精确编码场景组件的几何关系进一步增强了生成场景的可控性。相比之下,GraphDreamer使用粗略的语言描述来表示场景组件的二元关系,因此不适用于涉及精确几何控制的编辑任务,如上图5中的第一个例子所示。
图像调节场景生成
该表示方法可以用于图像解析和生成与解析后图像结构和内容一致的3D场景。我们通过与下图6中展示的GraphDreamer进行比较来评估我们的表示方法。我们的表示方法明确编码了从输入图像中解析出的语义组件、高层次的场景结构(例如可乐罐的重复)以及视觉细节(如具有特定形状和颜色的玻璃瓶)。我们的方法保留了输入图像的结构和视觉内容。相比之下,GraphDreamer仅从输入图像中重建语义信息;由于中间场景图表示中的信息丢失,它忽略了实体的姿态和身份。

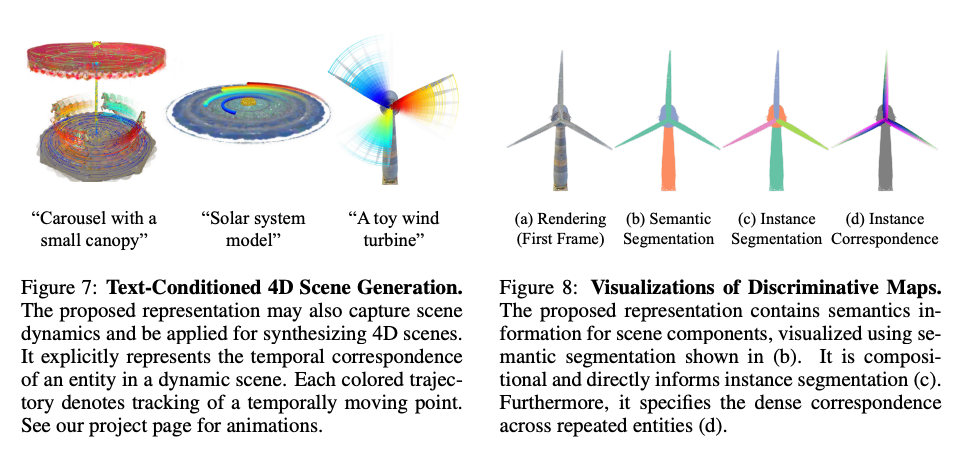
文本调节 4D 场景生成
应用前文中的推理方法来生成4D场景。在此任务中,4D场景表示与公式(1)中的定义相同,只是程序中增加了一个4D实体函数。
允许使用灵活的原始实体集合对于使我们的表示适用于生成不同规模的4D场景至关重要,包括具有活动部件的物体(例如图7中的风力涡轮机)和具有移动物体的场景(例如旋转木马)。具体而言,原始实体的粒度根据所表示的特定场景进行调整,而不是从固定集合中选择(或像场景图那样以对象为中心)。
此外,基于程序的表示所封装的层次化场景结构使得可以紧凑地表示4D场景,作为生成输出的正则化。多个实体,例如图7中旋转木马场景中来自函数horse的输出,可以组合成一个函数horses,从而共享相同的时间变换。为实体分组编写可组合函数有效地降低了时间运动空间的维度,并提高了运动的保真度。
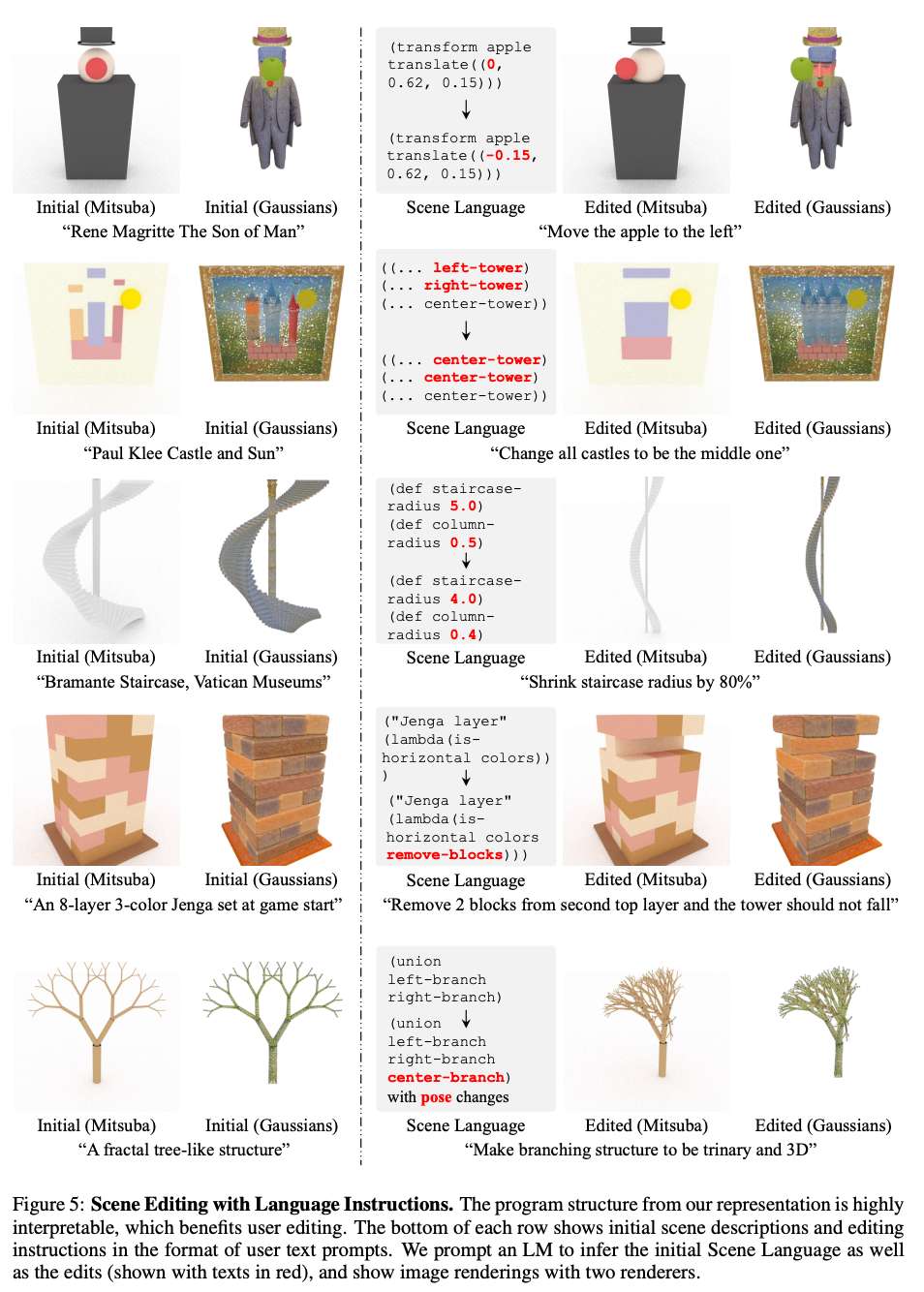
不同的图形渲染器
相同的程序可以用前文中描述的不同渲染器进行渲染,展示了所提出表示方法的多功能性。结果如下图9所示,实验设置与前文相同。
歧视性信息的可视化
如下图8所示,使用所提出的场景语言可以直接获得多种区分性信息:下图8b中的语义图,因为单词表示每个实体的语义;图8c中的实例分割,因为该表示是由可分离的实例组成的;下图8d中的重复实例的对应关系,因为程序指定了场景中存在的重复;以及下图7中显示的4D场景的密集时间对应关系。
结论
本文引入了一种视觉场景表示方法,称为场景语言,它编码了视觉场景的三个关键方面:通过程序指定的场景结构,如层次结构和重复;通过单词简洁概括的个体组件语义;以及通过神经 embeddings精确捕捉的每个组件的身份。将这种表示形式化为使用DSL定义的编程语言。展示了场景语言可以通过预训练的语言模型从文本和图像输入中高效推理。一旦程序执行,生成的场景可以通过多种图形渲染器渲染为图像。与现有方法相比,场景语言能够生成具有显著更高保真度的3D和4D场景,保留复杂的场景结构,并实现轻松和精确的编辑。
参考文献
[1] The Scene Language: Representing Scenes with Programs, Words, and Embeddings
版权归原作者 AI生成未来 所有, 如有侵权,请联系我们删除。