
上一期说到索引的原理其实就是B+树,这期我们来聊一下索引的分类。
一、索引分类
1.按存储引擎存储形式分类
按存储引擎存储形式可以分为聚集索引和二级索引,这两种索引也是索引的两大类。
** 1.1聚集索引**
将数据与索引存储到一块,索引结构的叶子节点存储行数据。聚集索引有且只能有一个,我们常说的主键就是聚集索引。
聚集索引的选取规则:
- 如果存在主键,那么主键就是聚集索引。
- 如果主键不存在,那么第一个唯一索引将作为聚集索引。
- 如果没有唯一索引,存储引擎Innodb将自动生成一个rowid作为隐藏的聚集索引。
1.1.1聚集索引结构
可以看到叶子节点下分别都挂载了行数据,这就是我们在上面所说的索引与数据存储到一起,如下图所示:

执行一条语句,来看下查找的过程是怎么样的:
select * from user where id='12';
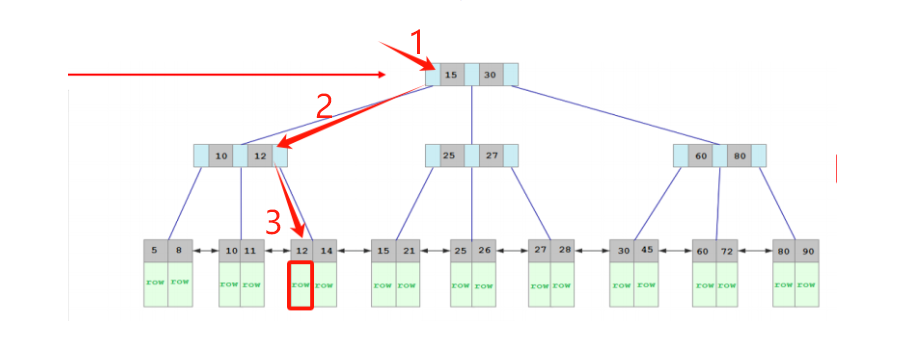
通过聚集索引,可以快速找到行数据。
** 1.2 二级索引**
** **将数据与索引分开存储,索引结构的叶子节点存储的是对应的主键。
除了主键索引,其他都是二级索引,二级索引可以有多个。
下面通过两张图来了解聚集索引和二级索引是如何存储行数据和主键:
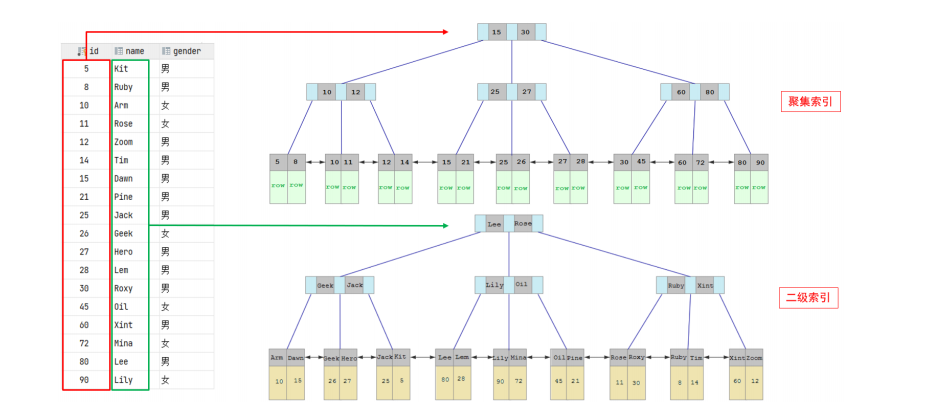
在最左边我们可以看到有三列数据,假设这张表为user,对应的字段分别为id,name,gender,id作为主键,name字段添加了二级索引,我们先来看最上面的聚集索引:
1.2.1二级索引结构
索引结构的叶子节点存储的是对应的主键,如下图所示:

当通过name作为条件去检索数据时:
select * from user where name='Arm';
查询过程如下:
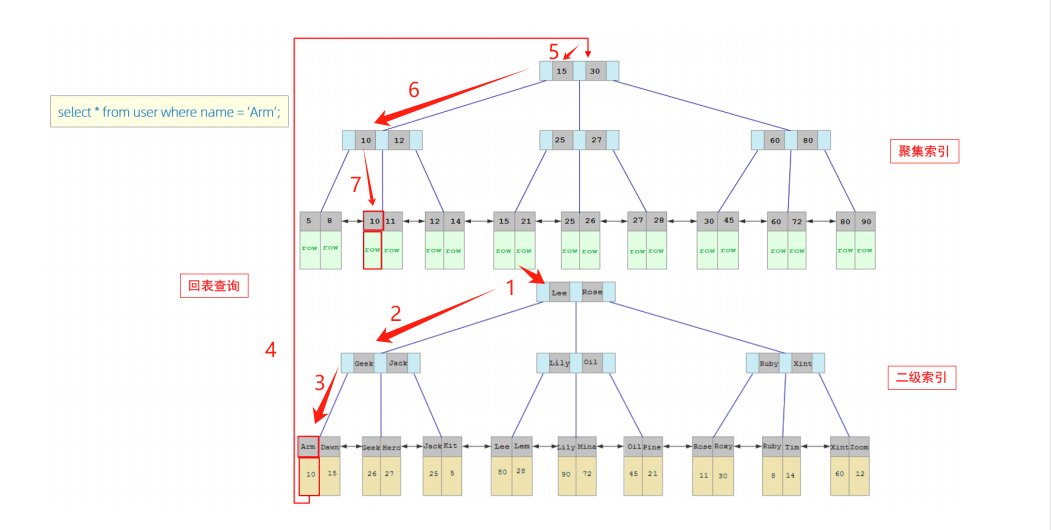
- 第一步,通过Arm去检索,Arm首先Lee进行对比,A小于L,往左走。
- 第二步,Arm再和Geek对比,A小于G,继续往左走。
- 第三步,Arm等于Arm,再通过Arm下挂载的主键(10)去聚集索引下找。
- 最后找到主键10,主键10下挂载着对应的行数据。
这就是通过二级索引去检索的过程,相比于主键索引,二级索引的检索出现了回表。
那么什么是回表呢?
回表就是通过二级索引找到主键值,再通过主键值找到行数据。
从上图可以看出,二级索引的检索效率会低于主键索引,那么如何解决回表的问题呢?我们在下期二级索引的使用中会说到。
2.按数据库分类
按照数据库可以分为主键索引、唯一索引、常规索引、联合索引、全文索引。
除了主键索引为第1点所说的聚集索引,其他均为二级索引。
2.1 主键索引
即聚集索引。主键索引有且只有一个,关键字primary,主键索引是查询效率最高的索引。
创建语法:
create primary index on table_name(column);
2.2 唯一索引
唯一索引可以避免字段值不重复,可以有多个,关键字unique。
创建语法:
create unique index on table_name(column);
2.3 常规索引
我们常定义的索引只要不加上某个关键字都是常规索引。
创建语法:
create index on table_name(column);
2.4 联合索引
一个索引创建在多个列上。
创建语法:
create index on table_name(column1,column2);
2.5 全文索引
全文索引检索的是文本中的关键字,而不是比较值,常用于海量数据的模糊查询。
创建语法:
create fulltext index on table_name(column1,column2);
全文索引的使用语法和其他不一样,如上给column1,column2创建了全文索引。
使用方法:
select * from tale_name where match(column1,column2) against('值1','值2');
match()函数指定的列和创建全文索引的列要完全匹配,否则会报错,against匹配的为要查询的值
总结:
按存储形式可将索引分为聚集索引和二级索引,聚集索引和二级索引的结构及查询的过程。
二级索引产生回表的问题.
按数据库分类的5种索引及创建语法。
这一期索引分类、索引的存储结构分享到这里,我们下一期来聊索引的使用及如何解决回表的问题,下期见!
公众号:【积极向上的阿虫】
版权归原作者 积极向上的ACC 所有, 如有侵权,请联系我们删除。