
1.Hadoop生态圈相关组件
HDFS(Hadoop分布式文件系统)。它是Hadoop的核心存储系统,提供高容错性和可扩展性,用于存储和管理大规模数据。
MapReduce。一个分布式计算框架,用于处理和分析大规模数据集。
YARN(Yet Another Resource Negotiator)。作为集群资源管理器,负责管理和调度集群上的资源。
Hive。一个基于Hadoop的数据仓库工具,提供类似SQL的查询语言(HiveQL)来进行数据分析和查询。
Pig。一个用于大规模数据分析的高级编程语言和平台,可以将复杂的数据处理流程转化为简单的脚本。
HBase。一个分布式、可扩展的列式数据库,适用于大规模结构化数据的实时读写操作。
ZooKeeper。一个分布式协调服务,提供配置管理、命名服务、分布式同步和组服务等功能。
Sqoop。一个用于在Hadoop和关系型数据库之间进行数据传输的工具。
Oozie。一个用于协调和管理Hadoop作业流程的工作流调度系统。
Mahout。一个用于实现大规模机器学习和数据挖掘的库。
Spark。一个高速大数据处理框架,支持内存计算和更广泛的数据处理模型。
Kafka。一个高吞吐量的分布式消息系统,用于发布和订阅流数据。
Flume。一个用于可靠地收集、聚合和移动大规模日志和事件数据的分布式系统。
Storm。一个用于处理实时流数据的分布式计算系统,提供容错性和可扩展性。
2.MapReduce的特点及运行架构
特点:
易于编程。MapReduce模型由两个主要操作组成:映射(Map)和归约(Reduce),开发人员只需实现这两个操作,并定义输入和输出格式,即可完成数据处理任务。
良好的扩展性。MapReduce可以在集群中并行执行任务,通过水平扩展,可以处理PB级别的数据,满足高性能和高吞吐量的需求。
高容错性。MapReduce在处理数据时具有容错机制,它可以检测和自动恢复失败的任务,确保整个作业的稳定执行。
适合批处理。MapReduce主要用于批处理任务,适合处理离线数据。
数据本地性。MapReduce充分利用数据本地性原则,即将计算任务分配到存储有数据的节点上执行,以减少数据传输和网络开销。
类型输入/输出。MapReduce支持不同类型的输入和输出。
易于使用。框架提供了用于二次开发的接口,简化了分布式程序的开发过程。
生态系统支持。MapReduce模型有丰富的生态系统支持,包括Hadoop、Apache Spark等,这些工具和框架提供了额外的功能和优化,使MapReduce更易于使用和管理。
需要注意的是,MapReduce也有其不擅长之处,例如实时计算、流式计算和DAG(有向图)计算等。
运行架构:

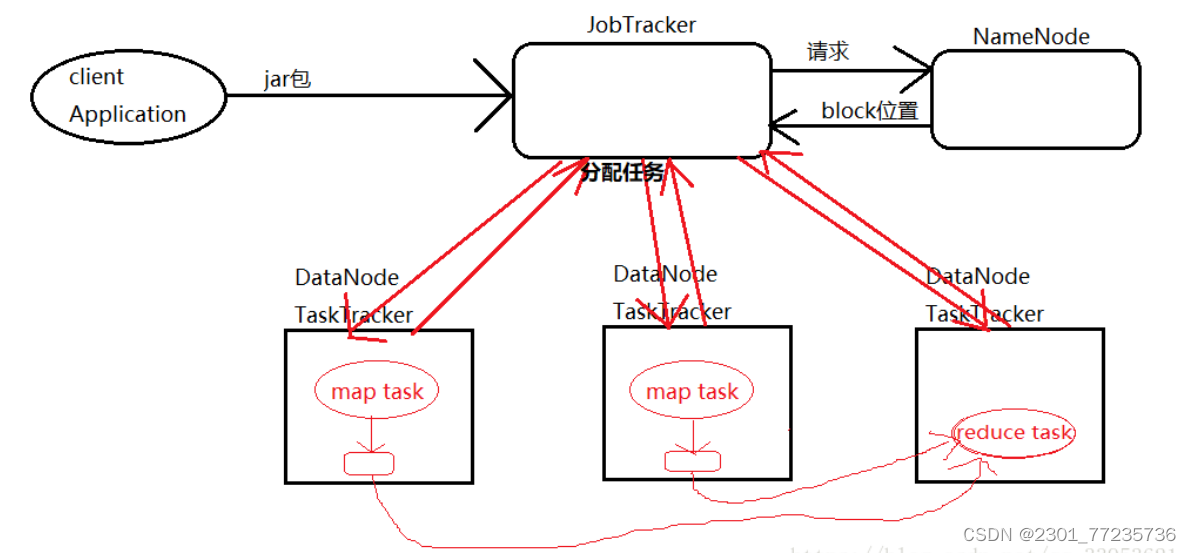
3.spark的特点:
Spark具有以下几个显著的特点:
1、速度快
小生根据官方数据统计,与Hadoop相比,Spark基于内存的运算效率要快100倍以上,基于硬盘的运算效率也要快10倍以上。Spark实现了高效的DAG执行引擎,能够通过内存计算高效地处理数据流。
2、易用性
Spark编程支持Java、Python、Scala及R语言,并且还拥有超过80种高级算法,除此之外,Spark还支持交互式的Shell操作,开发人员可以方便地在Shell客户端中使用Spark集群解决问题。
3、通用性
Spark提供了统一的解决方案,适用于批处理、交互式查询(SparkSQL)、实时流处理(SparkStreaming)、机器学习(SparkMLlib)和图计算(GraphX),它们可以在同一个应用程序中无缝地结合使用,大大减少大数据开发和维护的人力成本和部署平台的物力成本。
4、兼容性
Spark开发容pSpark可以运行在Hadoop模式、Mesos模式、Standalone独立模式或Cloud中,并且还可以访问各种数据源,包括本地文件系统、HDFS、Cassandra、HBase和Hive等。
与MapReduce的区别:
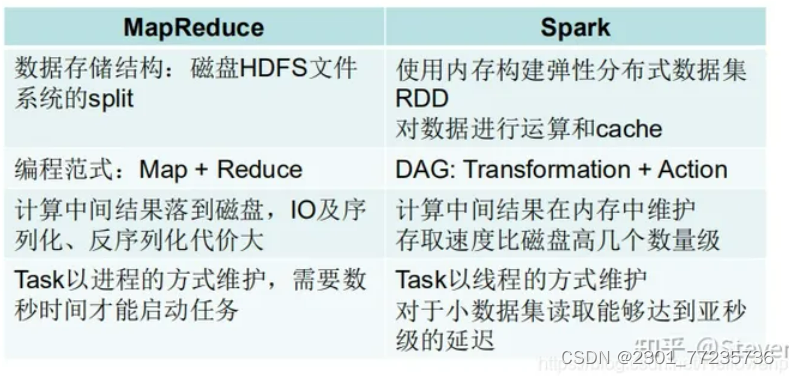
1. Spark处理数据是基于内存的,而MapReduce是基于磁盘处理数据的。
MapReduce是将中间结果保存到磁盘中,减少了内存占用,牺牲了计算性能。Spark是将计算的中间结果保存到内存中,可以反复利用,提高了处理数据的性能。
2. Spark在处理数据时构建了DAG有向无环图,减少了shuffle和数据落地磁盘的次数。
Spark 计算比 MapReduce 快的根本原因在于 DAG 计算模型。一般而言,DAG 相比MapReduce 在大多数情况下可以减少 shuffle 次数。Spark 的 DAGScheduler 相当于一个改进版的 MapReduce,如果计算不涉及与其他节点进行数据交换,Spark 可以在内存中一次性完成这些操作,也就是中间结果无须落盘,减少了磁盘 IO 的操作。但是,如果计算过程中涉及数据交换,Spark 也是会把 shuffle 的数据写磁盘的!有一个误区,Spark 是基于内存的计算,所以快,这不是主要原因,要对数据做计算,必然得加载到内存,Hadoop 也是如此,只不过 Spark 支持将需要反复用到的数据给 Cache 到内存中,减少数据加载耗时,所以 Spark 跑机器学习算法比较在行(需要对数据进行反复迭代)
3.Spark是粗粒度资源申请,而MapReduce是细粒度资源申请。
粗粒度申请资源指的是在提交资源时,spark会提前向资源管理器(yarn,mess)将资源申请完毕,如果申请不到资源就等待,如果申请到就运行task任务,而不需要task再去申请资源。 MapReduce是细粒度申请资源,提交任务,task自己申请资源自己运行程序,自己释放资源,虽然资源能够充分利用,但是这样任务运行的很慢。
4.Linux的操作命令及演示说明
1.pwd 命令
格式:pwd
功能:显示当前所在目录(即工作目录)。

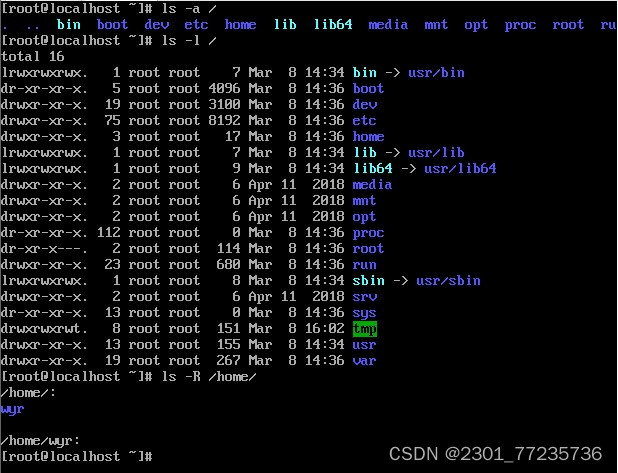
2.ls 命令
格式:ls [选项] [文件|目录]
功能:显示指定目录中的文件或子目录信息。当不指定文件或目录时,显示 当前工作目录中的文件或子目录信息。
命令常用选项如下:
-a :全部的档案,连同隐藏档( 开头为 . 的档案) 一起列出来。
-l :长格式显示,包含文件和目录的详细信息。
-R :连同子目录内容一起列出来。
说明:命令“ls –l”设置了别名:ll,即输入 ll 命令,执行的是 ls –l
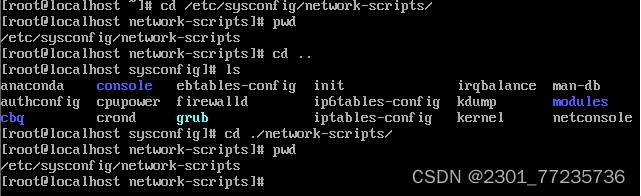
3.cd 命令
格式:cd <路径>
功能:用于切换当前用户所在的工作目录,其中路径可以是绝对路径也可以 是相对路径。
4.mkdir 命令
格式: mkdir [选项] 目录
功能:用于创建目录。创建目录前需保证当前用户对当前路径有修改的权 限。参数 -p 用于创建多级文件夹。

5. rm 命令
格式: rm [选项] <文件>
功能:用于删除文件或目录,常用选项-r -f,-r 表示删除目录,也可以用于 删除文件,-f 表示强制删除,不需要确认。删除文件前需保证当前用户对当 前路径有修改的权限。

6.cp 命令
格式: cp [选项] <文件> <目标文件>
功能:复制文件或目录。

7.mv 命令
格式:mv [选项] <文件> <目标文件>
功能:移动文件或对其改名。常用选项-i -f -b,-i 表示若存在同名文件,则向用户 询问是否覆盖;-f 直接覆盖已有文件,不进行任何提示;-b 当文件存在时,覆盖 前为其创建一个备份。

8.cat 命令
格式:cat [选项] [文件]
功能:查看文件内容。常用选项:-n 显示行号(空行也编号)。
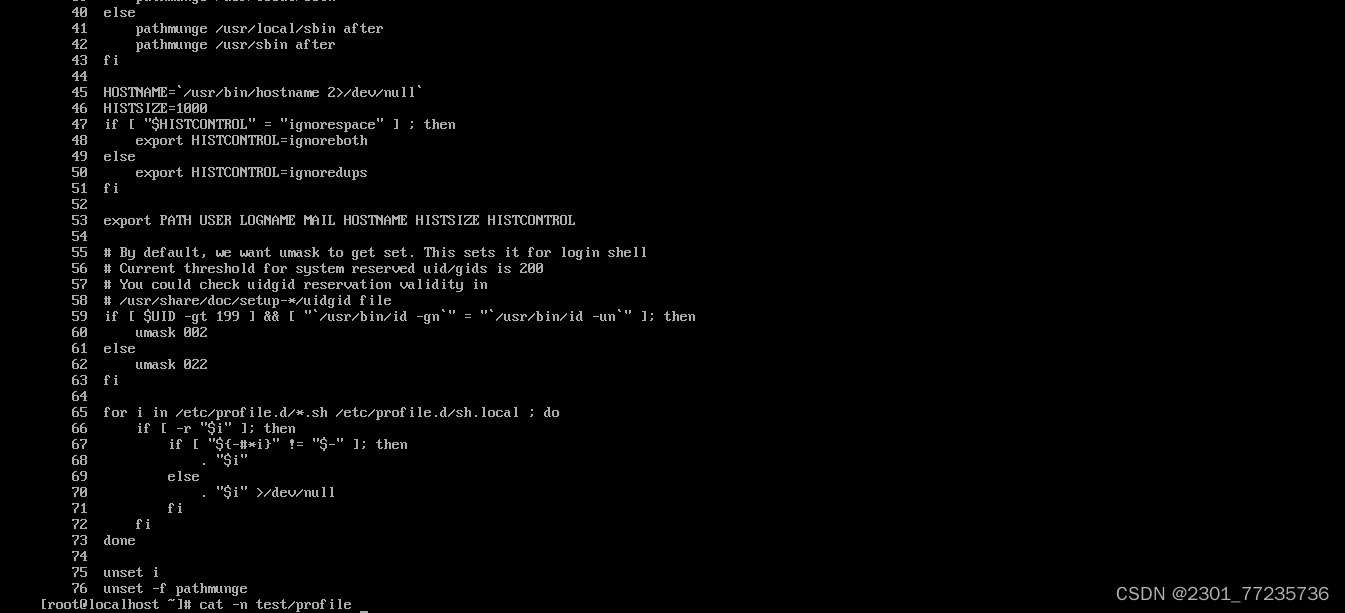
9.tar 命令
格式:tar [选项] [档案名] [文件或目录]
功能:为文件和目录创建档案。利用 tar 命令,可以把一大堆的文件和目录 全部打包成一个文件,这对于备份文件或将几个文件组合成为一个文件以便 于网络传输是非常有用的。该命令还可以反过来,将档案文件中的文件和目 录释放出来。
常用选项:
-c 建立新的备份文件。
-C 切换工作目录,先进入指定目录再执行压缩/解压缩操作,可用于 仅压缩特定目录里的内容或解压缩到特定目录。
-x 从归档文件中提取文件。
-z 通过 gzip 指令压缩/解压缩文件,文件名为*.tar.gz。
-f 指定备份文件。
-v 显示命令执行过程。

10.useradd 命令
格式:useradd 用户名
功能:创建新用户,该命令只能由 root 用户使用

11.passwd 命令
格式:passwd 用户名
功能:设置或修改指定用户的口令。

12.chown 命令
格式:chown [选项]
功能:将文件或目录的拥有者改为指定的用户或组,用户可以是用户名或者 用户 ID,组可以是组名或者组 ID,文件是以空格分开的要改变权限的文件 列表支持通配符。选项“-R”表示对目前目录下的所有文件与子目录进行相同的拥有者变更。
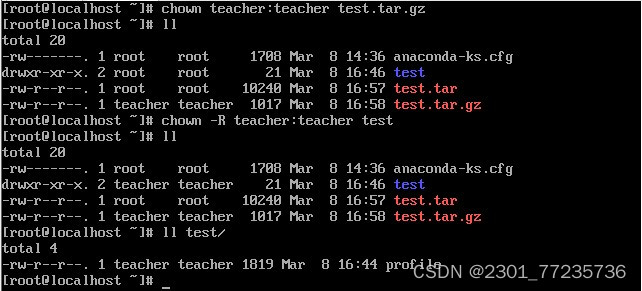
13.chmod 命令
格式:chmod [-R] 模式 文件或目录
功能:修改文件或目录的访问权限。选项“-R”表示递归设置指定目录下的所 有文件和目录的权限。
模式为文件或目录的权限表示,有三种表示方法。
(1)数字表示
用 3 个数字表示文件或目录的权限,第 1 个数字表示所有者的权限,第 2个 数字表示与所有者同组用户的权限,第 3 个数字表示其他用户的权限。每类 用户都有 3 类权限:读、写、执行,对应的数字分别是 4、2、1。一个用户 的权限数字表示为三类权限的数字之和,如一个用户对 A 文件拥有读写权 限,则这个用户的权限数字为 6(4+2=6)。

(2)字符赋值
用字符 u 表示所有者,用字符 g 表示与所有者同组用户,用字符 o 表示其他 用户。用字符 r、w、x 分别表示读、写、执行权限。用等号“=”来给用户赋 权限。

(3)字符加减权限
用字符 u 表示所有者,用字符 g 表示与所有者同组用户,用字符 o 表示其他 用户。用字符 r、w、x 分别表示读、写、执行权限。用加号“+”来给用户加 权限,加号“-”来给用户减权限。

14.su 命令
格式:su [-] 用户名
功能:将当前操作员的身份切换到指定用户。如果使用选项“-”,则用户切换 后使用新用户的环境变量,否则环境变量不变。

15.文本操作
格式:vi [文件名]
功能:vi 是 Linux 的常用文本编辑器,vim 是从 vi 发展出来的一个文本编辑器, 其在代码补全、编译等方便的功能特别丰富,在程序员中被广泛使用。
[root@localhost ~]# cd test
[root@localhost test]# vi profile
16.clear 命令
格式:clear
功能:清除屏幕。实质上只是让终端显示页向后翻了一页,如果向上滚动屏 幕还可以看到之前的操作信息。
[root@localhost test]# clear
17.hostname 命令
格式:hostname [选项]
功能:用于显示和设置系统的主机名称。在使用 hostname 命令设置主机名 后,系统并不会永久保存新的主机名,重新启动机器之后还是原来的主机 名。如果需要永久修改主机名,需要同时修改/etc/hostname 的相关内容。
常用选项: -a 显示主机别名,-i 显示主机的 ip 地址。

18.hostnamectl 命令
格式 1:hostnamectl
功能:显示当前主机的名称和系统版本。
格式 2:hostnamectl set-hostname <host-name>
功能:永久设置当前主机的名称。

19.ip 命令
CentOS 7 已不使用 ifconfig 命令,其功能可通过 ip 命令代替。
格式 1:ip link <命令选项> dev <设备名>
功能:对网络设备(网卡)进行操作,选项 add、delete、show、set 分别对应增加、删除、查看和设置网络设备。

格式 2:ip address <命令选项> dev <设备名>
功能:对网卡的网络协议地址(IPv4/IPv6)进行操作,选项 add、change、 del、show 分别对应增加、修改、删除、查看 IP 地址。
20.systemctl 命令
格式:systemctl <命令选项> service_name.service
功能:管理系统中的服务,“.service”表示管理的服务均包含了一个 以 .service 结尾的文件,存放于 /lib/systemd/目录中,可以省略。命令选项 有 start、restart、reload、stop、status,分别对应服务的启动、重启、重 新加载、停止和显示状态。另外选项 enable 表示开机时启动,disable 表示撤销开机启动。

21.reboot 命令
格式: reboot
功能:用于重新启动计算机,但是机器重启必须要 root 用户才有权限。
[root@master ~]# reboot
22.:poweroff 命令
格式:poweroff
功能:用来关闭计算机操作系统并且切断系统电源。如果确认系统中已经没 有用户存在且所有数据都已保存,需要立即关闭系统,可以使用 poweroff命令。
[root@master ~]# poweroff
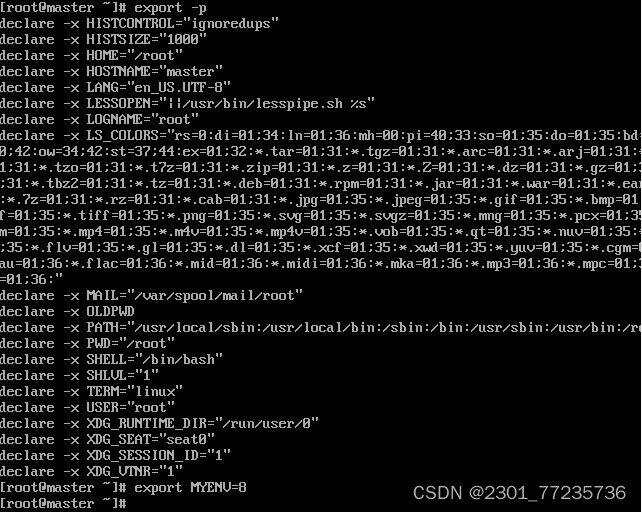
23.export 命令
格式:export [选项] [变量名]
功能:用于将 Shell 变量输出为环境变量,或者将 Shell 函数输出为环境变 量。一个变量创建时,它不会自动地为在它之后创建的 Shell进程所知,而 命令export 可以向后面的 Shell 传递变量的值。当一个Shell 脚本调用并执行 时,它不会自动得到父脚本(调用者)里定义的变量的访问权,除非这些变 量已经被显式地设置为可用。export 命令可以用于传递一个或多个变量的值到任何子脚本。
常用选项:
-f 代表[变量名称]中为函数名称。
-n 删除指定的变量。变量实际上并未删除,只是不会输出到后续指令的执行 环境中。
-p 列出所有的 Shell 赋予程序的环境变量。
24.echo 命令
格式:echo [字符串]
功能:用于在终端设备上输出字符串或变量提取后的值。一般使用在变量前 加上$符号的方式提取出变量的值,例如:$PATH然后再用 echo 命令予以出。

25.source 命令
格式:source [文件]
功能:用于重新执行刚修改的初始化文件,使之立即生效,而不必注销用户,重新登录。

5.冷备、温备、热备
冷备:
也称为冷备用,是指在电气或计算机系统中的一种备用状态,其中备用设备(通常是主设备的备份)处于关闭或非运行状态。备用设备通常配置与主设备相同,但不会在正常情况下运行,以节省能源和维护成本。在主设备发生故障时,备用设备才会被启动并接管主设备的工作。
温备:
温备份是一种备份方法,它将备份系统安装配置成与当前使用的系统相同或相似的系统和网络运行环境。在这种环境下,应用系统的业务会定期进行数据备份。这种方法可以在系统运行时进行,因此也被称为在线备份或动态备份。在温备份过程中,新的数据会不断产生,用户可以随时访问数据库,并且在用户允许的情况下,新版本的备份才会替换旧版本。由于需要持续的数据保护,温备份需要大量的存储空间。
热备:
热备(Hot Standby)是指在主设备(活动设备)发生故障或停机时,备用设备(热备设备)能够立即接管工作并承担原设备的功能,确保服务的连续不间断。
热备是一种高可用性(High Available)的配置方式,在这种方式下,备用设备始终处于工作状态,可以实时监控主设备的状态,并在检测到主设备故障时立即开始工作。这种配置方式有助于减少因主设备故障而导致的服务中断时间,保证服务的高可用性和连续性。
6.数据类型
Java中定义了3类8种基本数据类型
数值型- byte、 short、int、 long、float、 double程序员
字符型- charweb
布尔型-boolean
1.整数数据类型
整型用于表示没有小数部分的数值,它容许是负数。整型的范围与运行Java代码的机器无关,这正是Java程序具备很强移植能力的缘由之一。与此相反,C和C++程序须要针对不一样的处理器选择最有效的整型。

2.浮点数数据类型
带小数的数据在Java中称为浮点型。浮点型可分为float类型和double类型。

3.字符数据类型

Java 语言中还容许使用转义字符 ‘\’ 来将其后的字符转变为其它的含义。
经常使用的转义字符及其含义和Unicode值如表所示。

4.boolean数据类型
boolean类型有两个常量值,true和false,在内存中占一位(不是一个字节),不可使用 0 或非 0 的整数替代 true 和 false ,这点和C语言不一样。 boolean 类型用来判断逻辑条件,通常用于程序流程控制 。

版权归原作者 2301_77235736 所有, 如有侵权,请联系我们删除。