
简介: 在本篇博客中,我们将介绍如何使用Python编写一个简单的网络爬虫,从指定网站上获取图书信息,并将这些信息存入数据库。这个项目涉及到Python编程、selenium爬虫技术以及数据库操作等内容,适合对这些领域感兴趣的初学者。
1. 什么是网络爬虫? 网络爬虫(也称为网络蜘蛛、网络机器人)是一种自动获取网页内容的程序,它模拟人的行为去各个网站抓取数据或返回数据。通过网络爬虫技术,我们可以从互联网中获取丰富的数据,为后续的数据分析和处理提供支持。
2. 项目概述: 本次项目爬取的是一个图书网站:scrape book,我们的项目包括四个主要部分:

- CONN.py:连接数据库模块,负责与MySQL数据库建立连接。
- create_table.py:创建数据表模块,创建一个名为book_info的数据表,用于存储图书信息。
- insert_info.py:插入数据模块,向数据表中插入图书信息。
- main.py:主程序模块,负责爬取网页数据,并调用插入数据模块将信息存入数据库。
3. 项目详解:
具体爬取内容:
爬取一个网站的前提是了解这个网站的内容,以及网页布局,最后确定自己需要爬取的内容等。

首先准备工作:
工具(主要是方便查看数据库内容):Navicat Premium 是一款功能强大的数据库管理工具,提供了用户友好的图形用户界面,使数据库管理变得更加简单和直观。为了更直观的查看数据库里面各种信息,建议安装这个软件,连接也很简单,点新建连接,就会弹出如下页面,连接名随意,其他都不用改,密码就是你安装mysql时设置的密码,我的就是123456,之后的连接数据库等的password也都是这个

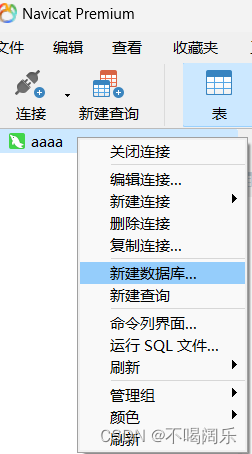
然后,如果没有数据库需要先创建一个数据库,具体方法有很多,可以直接用navicat premium,直接右键连接,再点新建数据库,便创建好了,也可以用代码连接并创建数据库。
#此代码为数据库的创建,如果已经有数据库,则可忽略
import pymysql
conn = pymysql.connect(
host='localhost',
port=3306,
user='root',
password='123456',
charset='utf8mb4',
)
# 创建数据库test
create_db_sql = "CREATE DATABASE IF NOT EXISTS Scrape_book;"#此处创建了名为:Scrape_book的数据库
cursor = conn.cursor()
cursor.execute(create_db_sql)
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
接下来便是主要的代码:
- CONN.py:这个模块定义了一个函数
connect_mysql(),用于连接MySQL数据库,并返回连接对象。我们需要提供数据库的主机地址、用户名、密码、数据库名以及字符集等信息。 - 注意:此处是Scrape_book这个数据库是已经存在的,如果没有数据库的请先创建数据库。
import pymysql
def connect_mysql():
#建立与MySQL数据库的连接
conn = pymysql.connect(
host='localhost',
user='root',
password='123456',
db='Scrape_book',
charset='utf8mb4'
)
return conn
- create_table.py:在这个模块中,我们使用了CON.py中定义的连接函数,连接到MySQL数据库。然后,我们使用SQL语句创建了一个名为
book_info的数据表,用于存储图书信息。
import CONN
def create_tables():
conn = CONN.connect_mysql()
cursor = conn.cursor()
# 创建数据表
create_table_sql = '''
CREATE TABLE IF NOT EXISTS book_info (
`key` INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(50),
score VARCHAR(20),
typeN VARCHAR(50),
price VARCHAR(20),
author VARCHAR(50),
published_at VARCHAR(50),
page_number VARCHAR(50),
publisher VARCHAR(50),
isbm VARCHAR(50)
)
'''
cursor.execute(create_table_sql)
conn.commit()
conn.close()
cursor.close()
create_tables()
- insert_info.py:这个模块定义了一个函数
insert_info(info),用于向数据库中插入图书信息。我们需要提供待插入的图书信息作为参数,并通过SQL语句执行插入操作。
import CONN
def insert_info(info):
conn =CONN.connect_mysql()
cursor =conn.cursor()
sql = "INSERT INTO book_info(title,score,typeN,price,author,published_at,publisher,page_number,isbm) VALUES(%s,%s,%s,%s,%s,%s,%s,%s,%s)"
values = (info)
cursor.execute(sql, values)
conn.commit()
cursor.close()
conn.close()
- main.py:这是项目的核心模块,主要负责爬取网页数据。我们使用了Selenium库来模拟浏览器行为,从指定的网站获取图书信息。然后,我们调用插入数据模块将信息存入数据库。
# 导入所需的库
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import time
import insert_info
# 初始化一个 Chrome WebDriver 实例
driver = webdriver.Chrome()
driver.maximize_window()# 设置浏览器全屏
driver.get('https://spa5.scrape.center')# 打开目标网站
time.sleep(2)# 等待 2 秒,确保页面加载完成
# 定义函数,用于获取书籍信息
def get_info():
# 初始化一个空列表,用于存放书籍的标签
ty=[]
# 获取书籍标签
try:
# 使用 XPath 定位符找到包含标签信息的按钮元素
t = driver.find_elements(by=By.XPATH, value="//button[@class='el-button el-button--primary el-button--mini']/span")
for i in t:# 遍历按钮元素,提取其中的文本信息,将标签存入列表中
ty.extend(i.text)
ty.extend('/')
# 将列表中的标签信息拼接为一个字符串,并删除最后一个字符(因为最后一个字符是多余的斜杠)
tag =''.join(ty)[:-1]
except:
tag = 'N/A'
# 获取评分信息
try:
score = driver.find_element(by=By.XPATH, value="//span[@class='score m-r']").text
except:
score = 'N/A'
# 获取书籍标题信息
try:
title = driver.find_element(by=By.XPATH, value="//h2[@class='m-b-sm name' ]").text
except:
title = 'N/A'
# 获取价格信息
try:
price = driver.find_element(by=By.XPATH, value="//div[@class='info']/p[@class='price']").text
except:
price = 'N/A'
# 获取作者信息
try:
author = driver.find_element(by=By.XPATH, value="//div[@class='info']/p[@class='authors']").text
except:
author = 'N/A'
# 获取出版日期信息
try:
published_at = driver.find_element(by=By.XPATH,value="//div[@class='info']/p[@class='published-at']").text
except:
published_at='N/A'
# 获取出版社信息
try:
publisher = driver.find_element(by=By.XPATH,value="//div[@class='info']/p[@class='publisher']").text
except:
publisher = 'N/A'
# 获取页数信息
try:
page_number = driver.find_element(by=By.XPATH,value="//div[@class='info']/p[@class='page-number']").text
except:
page_number='N/A'
# 获取ISBN信息
try:
isbm = driver.find_element(by=By.XPATH, value="//div[@class='info']/p[@class='isbn']").text
except:
isbm = 'N/A'
# 将所有信息组合成一个列表并返回
full_info = [title,score,tag,price,author,published_at, publisher,page_number,isbm]
return full_info
# 设置一个循环,用于爬取多页数据
o = 0
while o < 10:
o += 1
# 等待页面元素加载完成
WebDriverWait(driver, 30).until(EC.presence_of_element_located((By.XPATH, "//div[@class='top el-row']/div[@class='el-col el-col-24']/a")))
time.sleep(3)
book_page = driver.find_elements(By.XPATH, "//div[@class='top el-row']/div[@class='el-col el-col-24']/a")
for i in range(len(book_page)):
# 点击链接,进入书籍详情页面
driver.execute_script("arguments[0].click();", book_page[i])
WebDriverWait(driver, 30).until(EC.presence_of_element_located((By.XPATH, "//div[@class='info']")))
# 调用 get_info 函数获取书籍信息,并插入数据库
insert_info.insert_info(get_info())
#返回上一页
driver.back()
# 再次等待书籍列表页面加载完成
WebDriverWait(driver, 30).until(EC.presence_of_element_located((By.XPATH, "//div[@class='top el-row']/div[@class='el-col el-col-24']/a")))
book_page = driver.find_elements(By.XPATH, "//div[@class='top el-row']/div[@class='el-col el-col-24']/a")
# 等待翻页按钮加载完成
WebDriverWait(driver, 30).until(EC.presence_of_element_located((By.XPATH, "//div[@class='top el-row']/div[@class='el-col el-col-24']/a")))
# 找到并点击下一页按钮
next_btn = driver.find_element(By.CLASS_NAME, "btn-next") # 修改为 next_btn,避免拼写错误
driver.execute_script("arguments[0].click();", next_btn)
# 关闭浏览器
driver.close()
4. 实现过程:
- 我们首先运行
main.py,它会打开一个Chrome浏览器窗口,并访问指定的网站(https://spa5.scrape.center)。 - 然后,通过Selenium模拟点击页面中的链接,进入到具体的图书信息页面。
- 在每个图书信息页面中,我们使用Selenium获取图书的标题、评分、标签、价格、作者、出版日期、出版社、页数和ISBN等信息。
- 接着,我们调用插入数据模块,将获取到的信息存入MySQL数据库中的
book_info表中。 - 最后,我们在循环中重复以上步骤,直到获取了足够的图书信息为止。
5. 结果展示:

6. 总结:
通过这个项目,我们学习了如何使用Python编写一个简单的网络爬虫,从网站上获取数据并存入数据库。我们掌握了Selenium库的基本用法,学会了如何模拟浏览器行为。同时,我们也学习了如何使用MySQL数据库进行数据存储和管理。这些都是在数据处理和分析过程中非常重要的技能,希望本文对初学者有所帮助。
以上就是本篇博客的全部内容,希望读者能够通过学习这个项目,对网络爬虫技术有所了解,并且能够进一步探索更多有趣的项目和应用。
关于作者: 作者是一个对Python编程和数据科学感兴趣的初学者,希望通过自己的学习和实践,与大家一起分享有趣的技术和项目。如果您对本文有任何问题或建议,欢迎在评论区留言,作者会尽快回复。
版权归原作者 不喝阔乐 所有, 如有侵权,请联系我们删除。