
提示:避雷Hadoop完全分布式集群搭建的各种坑!
Hadoop3.X完全分布式集群搭建详细过程
前言
提示:不是小白你别来!我不允许我跳的坑 你还跳!!!
提示:以下是本篇文章正文内容,下面案例仅供参考
一、基础环境的下载
1: 系统环境 Ubuntu18.04
链接:https://pan.baidu.com/s/1mfjMoHl7SKFh9Jr85vQ_Ag
提取码:9802
2: jdk1.8.0_321 下载地址
链接:https://pan.baidu.com/s/1hvGmAISZTVRRTVhLOilYrw
提取码:9802
3: hadoop-3.3.0 下载地址
链接:https://pan.baidu.com/s/1uhlGQ0BMfi9NVuAOjoW51w
提取码:9802
4、远程工具 xshell 可到官网下载
二、基础环境安装
2.1 ubuntu18.4 安装
英文中文两种版本选择 没啥区别 但中文在之后的其他方面路径写不好会出现很多问题,建议安装英文版
2.1.1 ubuntu18.04安装
具体安装操作流程可参考:
https://blog.csdn.net/whatiscode/article/details/109153474?msclkid=ba7a5683ad6d11ecb0a0e0d6f24bbd65
2.1.2 输入法配置:
英文版 输入法默认只有英文 需要后期配置 配置具体教程可参考:
2.1.3 更换国内源
vi /etc/apt/sources.list
将原有源注释掉,换成国内镜像,此处换成 阿里云源
deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
2.1.4 创建root用户
这个坑给我重点看!!!此坑!你要是非跳!我不拦着!!!
因版本不同,此操作可根据自己情况自行选择
目前ubuntu18.04版本在安装系统的过程中,没有设置root密码的过程(如果安装过程中有设置roor用户密码的过程,此步骤可以跳过!!!),只有创建用户的过程,此时创建的用户只是有了root的权限,并不是root!!!但其实系统内部是存在root用户并且有默认的密码,只是没公布且每次安装随机,所有不为人知,所以这时候一定要更新root用户密码!!!(切记:此密码不是你安装系统时侯创建用户的密码!!!)
追根溯源可参考:
https://blog.csdn.net/linjcai/article/details/81316573
sudo passwd #创建/重置root密码 即 将系统默认的root密码改为自己的密码
su root #切换root用户 输入密码测试一下 切换成功即表示设置密码成功
2.2 jdk安装与环境配置
解压 这里是直接解压到根目录下的
tar -zxvf jdk-8u321-linux-x64.tar.gz
配置环境变量
sudo gedit /etc/profile=sudo vim /etc/profile
末尾加上
export JAVA_HOME=/home/jdk1.8.0_321 #此处根据自己的jdk安装目录填写 ——实在不知道自己安装怎么写 进入jdk目录下 **pwd** 复制粘贴即可
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
保存退出 esc+:wq OR 不保存强制退出 esc+:qa!
终端输入 使配置文件生效
source /etc/profile
2.3 hadoop安装
解压
sudo tar -zxf hadoop-3.3.0.tar.gz -C /usr/local #解压文件到系统文件/usr/local文件下
检验安装是否成功
cd /usr/local/hadoop-3.3.0/bin #定位到hadoop的bin目录下
hadoop version #输入命令,出现版本号即表示成功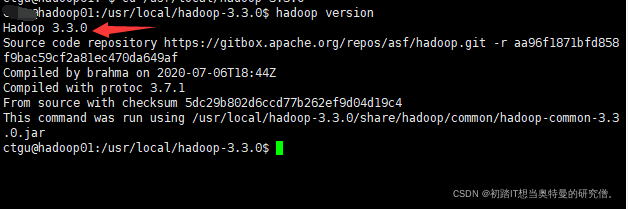
此时你会发现只能定位到hadoop的bin目录下 你输入hadoop version才能识别到,在其他部位输入就会出现 hadoop:命令找不到——因为没有配置系统文件
hadoop系统文件的配置
vim /etc/profile
export HADOOP_HOME=/usr/local/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
此时无论在哪个位置,输入hadoop version都可以定位到
三、集群搭建
3.1 Hadoop集群架构
hadoop0hadoop01/hadoop02NameNodeDataNodeResourceManagerNodeManagerSecondaryNameNode–
3.2 IP映射
修改hosts文件、存储主机和ip映射
在每台linux机器上分别编辑hosts文件
sudo vim etc/hosts

测试各节点的互通性
3.3 SSH免密登录设置
安装SSH服务
sudo apt-get update
sudo apt-get install vim
sudo apt-get install openssh-server
实现免密登录 每台机器上都执行下面操作
ssh-keygen -t rsa # 生成密钥对,会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 将公钥加入认证文件
ssh-copy-id hostname #此处的hostname为自己的主机名 在三台不同机器上执行时,这个hostname要改成相应的机器的主机名
验证免密登陆是否成功
ssh hadoop01 #hadoop01根据你要连接 测试的主机名来更改
我这里想测试与hadoop01的免密登录是否成功
其他的 也可供参考:https://blog.csdn.net/weixin_61963604/article/details/121930965?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164863092116780357297779%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=164863092116780357297779&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allfirst_rank_ecpm_v1~rank_v31_ecpm-4-121930965.142v5pc_search_insert_es_download,143v6register&utm_term=hadoop+%E4%B8%ADssh%E9%85%8D%E7%BD%AE&spm=1018.2226.3001.4187
3.4 集群环境配置
3.4.1 修改主从配置文件
修改workers文件 #hadoop2.x 叫slaves,hadoop3.x更名为workers 根据自己版本进行选择 添加自己的从节点名称
cd /usr/local/hadoop-3.3.0/etc/hadoop
vim workers


3.4.2 修改hadoop集群配置文件
此操作只在主机上进行 我这里的主机是hadoop0—这里架构设定NameNode只在主机Hadoop0上存储
cd /usr/local/hadoop-3.3.0/etc/hadoop
修改core-site.xml
sudo vim/gedit core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop0:9000</value> #hadoop0是自己的主机名
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/data/tmp</value>#临时文件存放位置 可自己更改
<description>Abase for other temporary directories.</description>
</property>
</configuration>
修改hdfs-site.xml
sudo vim/gedit hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop0:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/data/tmp/name</value>#namenode临时文件存放位置
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/data/tmp/data</value>#datanode临时文件存放位置
</property>
</configuration>
修改mapred-site.xml
sudo vim/gedit mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop0:10020</value>#hadoop0 自己的主机名
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop0:19888</value>#hadoop0 自己的主机名
</property>
</configuration>
修改yarn-site.xml
sudo vim/gedit yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostsname</name>
<value>hadoop0</value>#hadoop0 自己的主机名
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
主机上配置完毕以后,将此配置文件发送至两个从机
scp -r /usr/local/hadoop/ hadoop01:/usr/local #hadoop01指的是你要发送过去的那台机器的名称
下面的4个配置文件不要是不改!启动集群的时候必然出现这个错误:ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation. Starting datanodes 不出错误 你来找我!!必须给我改!
修改start-dfs.sh、stop-dfs.sh
cd /usr/local/hadoop-3.3.0/etc/hadoop/sbin #定位到sbin目录下
在start-dfs.sh和stop-dfs.sh最上面添加
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
修改start-yarn.sh、stop-yarn.sh
在start-yarn.sh和stop-yarn.sh最上面添加
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
四、集群搭建完毕 验证测试
4.1 启动集群
hdfs namenode -format #格式化
切忌:
不要多次格式化,多次格式化会使得临时文件中的id号版本不对应,导致集群没有datanode 解决办法:删除因为格式化而生成的临时文件logs+tmp 删除完毕 再次格式化即可
在主机上启动集群
start-all.sh #all 全部启动 也可分开 先启动dfs start-dfs.sh
在每台主机上查看节点状况——与上面表格中的集群架构对应 看是否正确
4.2 web页面查看状况
4.2.1查看NameNode的web页面
http://ip地址:端口号 #hadoop版本不同,端口号不同,我这里是hadoop3.x
具体参考:https://blog.csdn.net/qq_31454379/article/details/105439752
http://ip地址:9870
4.2.2查看HDFS信息页面

4.2.3 查看集群状态
http://ip地址:8088 #打开web控制台,可以查看集群状态
五、总结
其他错误总结:
1、启动节点以后,没有datanode节点 删除临时文件 即删除hadoop下的tmp 和logs两个文件
解决办法 具体可参考:
https://blog.csdn.net/qq_44962429/article/details/105119701?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&utm_relevant_index=1
https://blog.csdn.net/qq_44962429/article/details/105119701?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&utm_relevant_index=1
2、测试jdk是否成功安装的时候,出现 java not found
配置系统文件
解决办法 具体可参考:
https://blog.csdn.net/sun8112133/article/details/79901527
3、无法创建临时文件logs
错误提示:localhost: mkdir: 无法创建目录"/usr/local/hadoop/logs": 权限不够
解决办法 具体参考:
https://blog.csdn.net/weixin_30354675/article/details/95887074
4、Linux服务器配置root用户ssh远程登录
解决办法 具体可参考:
https://blog.csdn.net/qq_41331466/article/details/123796610
4、推荐参考书籍
https://max.book118.com/html/2020/1214/6013134055003034.shtm
版权归原作者 初踏IT想当奥特曼的研究僧。 所有, 如有侵权,请联系我们删除。