
1.C/C++关键字
1.1 static(静态)变量
在C中,关键字static是静态变量:
- 静态变量只会初始化一次,然后在这函数被调用过程中值不变。
- 在文件内定义静态变量(函数外),作用域是当前文件,该变量可以被文件内所有函数访问,不能被其他文件函数访问。为本地的全局变量,只初始化一次。
在C++中,类内数据成员可以定义为static
- 对于非静态数据成员,每个对象有一个副本。而静态数据成员是类的成员,只存在一个副本,被所有对象共享。
- 静态成员变量没有实例化对象也可以使用,“类名:静态成员变量”
- 静态成员变量初始化在类外,但是private和protected修饰的静态成员不能类外访问。
classStu{public:staticint age;private:staticint height;};//初始化静态成员变量int Stu::age =19;int Stu::height =180;intmain(){
cout<<Stu::age<<endl;//输出19;
cout<<Stu::height<<endl;//错误的,私有无法访问。
Stu s;
cout<<s::age<<endl;//输出19;
cout<<s::height<<endl;//错误的,私有无法访问。return0;}
- 在类中,static修饰的函数是静态成员函数。静态成员函数一样属于类,不属于对象,被对象共享。静态成员函数没有this指针,不能访问非静态的函数和变量,只能访问静态的。
与全局变量相比,静态数据成员的优势:
- 全局变量作用域是整个工程,而static作用域是当前文件,避免命名冲突
- 静态数据成员可以是private成员,而全局变量不能,实现信息隐藏
为什么静态成员变量不能在类内初始化?
因为类的声明可能会在多处引用,每次引用都会初始化一次,分配一次空间。这和静态变量只能初始化一次,只有一个副本冲突,因此静态成员变量只能类外初始化。
为什么static静态变量只能初始化一次?
所有变量都只初始化一次。但是静态变量在全局区(静态区),而自动变量在栈区。静态变量生命周期和程序一样,只创建初始化一次就一直存在,不会销毁。而自动变量生命周期和函数一样,函数调用就进行创建初始化,函数结束就销毁,所以每一次调用函数就初始化一次。
在头文件中定义静态变量是否可行?
不可行,在头文件中定义的一个static变量,对于包含该头文件的所有源文件,实质上在每个源文件内定义了一个同名的static变量。造成资源浪费,可能引起bug
1.2 const的作用
常量类型也称为const类型,使用const修饰变量或者对象
在C中,const的作用为:
- 定义变量(局部或者全局)为常量
constint a =10;//常量定义时,必须初始化
- 修饰函数的参数,函数体内不能修改这个参数的值
- 修饰函数的返回值 - const修饰的返回值类型为指针,返回的指针不能被修改,而且只能符给被const修饰的指针
constchar*GetString(){//...}intmain(){char*str =GetString();//错误,str没被const修饰constchar*str =GetString();//正确}- const修饰的返回值类型为引用,那么函数调用表达式不能做左值(函数不能被赋值)constint&add(int&a ,int&b){//..}intmain(){add(a,b)=4;//错误,const修饰add的返回引用,不能做左值}- const修饰的返回值类型为普通变量,由于返回是普通临时变量,const修饰没意义。
在c++中,const还有作用为:
- const修饰类内的数据成员。表示这个数据成员在某个对象的生命周期是常量,不同对象的值可以不一样,因此const成员函数不能在类内初始化。
- const修饰类内的成员函数。那么这个函数就不能修改对象的成员变量
const的优点?
- 进行类型检查,使编译器对处理内容有更多了解。
- 避免意义模糊的数字出现,类似宏定义,方便对参数进行修改。
- 保护被修饰的内容,防止被意外修改
- 为函数重载提供参考
classA{voidf(int i){...}//非const对象调用voidf(int i)const{...}//const对象调用}
5.节省内存
6.提高程序效率(编译器不为普通const常量分配存储空间,而保存在符号表中。称为一个编译期间的常量,没有存储和读内存的操作)
什么时候使用const?
- 修饰一般常量
- 修饰对象
- 修饰常指针
constint*p;intconst*p;int*const p;constint*const p; - 修饰常引用
- 修饰函数的参数
- 修饰函数返回值
- 修饰类的成员函数
- 修饰另一文件中引用的变量
externconstint j;
const和指针(常量指针、指针常量)
- 常量指针(const 修饰常量,const在*的左边)
constint*p =&a;// const修饰int,指针的指向可以修改,但是指针指向的值不能改intconst*p;//同上p =&b;//正确*p =10;//错误 - 指针常量(const修饰指针,const在*的右边)
int*const p =&a;//const修饰指针,指针的指向不可以改,但是指针指向的值可以改*p =10;//正确p =&b;//错误 - const都修饰指针和常量(指针和常量都不能修改)
constint*const p;intconst*const p;
1.3 switch语句中case结尾是否必须加break
一般必须在case结尾加break。因为通过switch确认入口点,一直往下执行,直到遇见break。否则会执行完这个case后执行后面的case,default也会执行。****注,switch(c),c可以是int、long、char等,但是不能是float
1.4 volatile 的作用
volatile 关键字是一种类型修饰符,用它声明的类型变量表示可以被某些编译器未知的因素更改,比如:操作系统、硬件或者其它线程等。
- 编译器不再进行优化,从而可以提供对特殊地址的稳定访问。
- 系统总是重新从它所在的内存读取数据,不会利用cache中原有的数值。
- 用于多线程被多个任务共享的变量,或者并行设备的硬件寄存器
1.5 断言ASSERT()是什么?
是一个调试程序使用的宏。定义在<assert.h>中,用于判断是否出现非法数据。括号内的值 为false(0),程序报错,终止运行。
ASSERT(n !=0);// n为0的时候程序报错
k =10/n;
ASSERT()在Debug中有,在Release中被忽略。 ASSERT()是宏,assert()是ANSCI标准中的函数,但是影响程序性能。
1.6 枚举变量的值计算
#include<stdio.h>intmain(){enum{a,b=5,c,d=4,e};printf("%d %d %d %d %d",a,b,c,d,e);return0;}
输出为 0 5 6 4 5
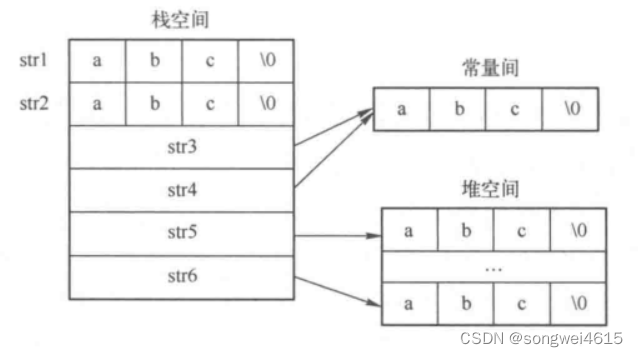
1.7 字符串存储方式
- 字符串存储在栈中
char str1[]="abc";char str2[]="abc";
- 字符串存储在常量区
char*str3 ="abc";char*str4 ="abc";
- 字符串存储在堆中
char*str5 = (char*)malloc(4);strcpy(str5,"abc");char*str6 = (char*)malloc(4);strcpy(str6,"abc");
- 字符串是否相等
- str1 != str2 ,str1和str2是两个字符串的首地址。
- str3 == srt4 , str3和str4是常量的地址,同样字符串在常量区只存在一份。
- str5 != str6 ,str5 和str6是指向堆的地址。
1.8 程序内存分区
内存高地址栈区堆区全局/静态区 (.bss段 .date段)常量区内存低地址代码区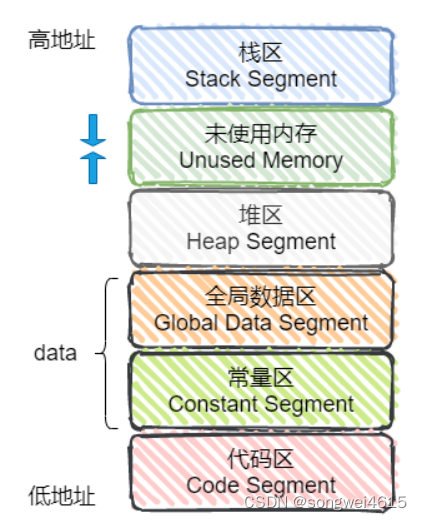
- 栈区(stack)
- 临时创建的局部变量存放在栈区。
- 函数调用时,其入口参数存放在栈区。
- 函数返回时,其返回值存放在栈区。
- const定义的局部变量存放在栈区。
- 堆区(heap)
- 堆区用于存放程序运行中被动态分布的内存段,可增可减。
- malloc函数分布的内存,必须用free进行内存释放,否则会造成内存泄漏。
- 全局区(静态区)
- (c语言中)全局区有.bss段和.data段组成,可读可写。
- C++不分bss和data
- .bss段
- 未初始化的全局变量存放在.bss段。
- 初始化为0的全局变量和初始化为0的静态变量存放在.bss段。
- .bss段不占用可执行文件空间,其内容有操作系统初始化。
- .data段
- 已经初始化的全局变量存放在.data段。
- 静态变量存放在.data段。
- .data段占用可执行文件空间,其内容有程序初始化。
- const定义的全局变量存放在.rodata段。
- 常量区
- 字符串存放在常量区。
- 常量区的内容不可以被修改。
- 代码区
- 程序执行代码(二进制代码文件)存放在代码区。
1.9 p++ 和 (p)++ 的区别
- *p++ 先完成取地址,然后对指针地址进行++,再取值
- (*p)++,先完成取值,再对值进行++
1.10 new / delete 与 malloc / free的异同
- 相同点- 都可用于内存的动态申请和释放
- 不同点- new / delete 是C++运算符,malloc / free是C/C++语言标准库函数- new自动计算要分配的空间大小,malloc需要手工计算- new是类型安全的,malloc不是。例如:
int*p =newfloat[2];//编译错误int*p =(int*)malloc(2*sizeof(double));//编译无错误- new调用名为operator new的标准库函数分配足够空间并调用相关对象的构造函数,delete对指针所指对象运行适当的析构函数;然后通过调用名为operator delete的标准库函数释放该对象所用内存。malloc / free均没有相关调用- malloc / free需要库文件支持,new / delete不用- new是封装了malloc,直接free不会报错,但是这只是释放内存,而不会析构对象
1.11 exit()和return 的区别
- return是语言级的,标志调用堆栈的返回。是从当前函数的返回,main()中return的退出程序
- exit()是函数,强行退出程序,并返回值给系统
- return实现函数逻辑,函数的输出。exit()只用来退出。
1.12 extern和export的作用
变量的声明有两种情况:
- 一种是需要建立存储空间的。例如:int a 在定义的时候就已经建立了存储空间。
- 另一种是不需要建立存储空间的。 例如:extern int a 其中变量a是在别的文件中定义的。
- 总之就是:把建立空间的声明成为“定义”,把不需要建立存储空间的成为“声明”。
- extern - 普通变量、类。结构体
- export(C++中新增) - 和exturn类似,但是用作模板- 使用该关键字可实现模板函数的外部调用- 模板实现的时候前面加上export,别的文件包含头文件就可用该模板
1.13 C++中,explicit的作用
- 隐式转换
String s1 ="hello";//进行隐式转换,等价于String s1 =String("hello"); - explicit阻止隐式转换
classTest1{public: Test1(int n){ num = n }private:int num;}classTest2{public: explicitTest2(int n){ num = n }private:int num;}intmain(){ Test1 t1 =1;//正确,隐式转换 Test2 t2 =1;//错误,禁止隐式转换 Test2 t2(1);//正确,可与显示调用}
1.14 C++的异常处理
C++中的异常处理机制主要使用try、throw和catch三个关键字
#include<iostream>usingnamespace std;intmain(){double m =1, n =0;try{
cout <<"before dividing."<< endl;if(n ==0)throw-1;//抛出int型异常elseif(m ==0)throw-1.0;//拋出 double 型异常else
cout << m / n << endl;
cout <<"after dividing."<< endl;}catch(double d){
cout <<"catch (double)"<< d << endl;}catch(...){
cout <<"catch (...)"<< endl;}
cout <<"finished"<< endl;return0;}//运行结果//before dividing.//catch (...)//finished
代码中,对两个数进行除法计算,其中除数为0。可以看到以上三个关键字,
- 程序的执行流程是先执行try包裹的语句块,如果执行过程中没有异常发生,则不会进入任何catch包裹的语句块,如果发生异常,则使用throw进行异常抛出,再由catch进行捕获,
- throw可以抛出各种数据类型的信息,代码中使用的是数字,也可以自定义异常class。catch根据throw抛出的数据类型进行精确捕获(不会出现类型转换),如果匹配不到就直接报错,可以使用catch(…)的方式捕获任何异常(不推荐)。
- 当然,如果catch了异常,当前函数如果不进行处理,或者已经处理了想通知上一层的调用者,可以在catch里面再throw异常。
1.15 回调函数
- 把一段可执行的代码像参数传递那样传给其他代码,而这段代码会在某个时刻被调用执行,这就叫做回调。
- 如果代码立即被执行就称为同步回调,如果过后再执行,则称之为异步回调。
- 回调函数就是一个通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。
- 主函数和回调函数是在同一层的,而库函数在另外一层。如果库函数对我们不可见,我们修改不了库函数的实现,也就是说不能通过修改库函数让库函数调用普通函数那样实现,那我们就只能通过传入不同的回调函数
- sort(),中自定义的cmp就是回调函数
2. 内存分配
2.1 C++内存分配
见 1.8
2.2 内存泄漏
内存泄露的原因
内存泄漏是指堆内存的泄漏。使用malloc,、realloc、 new等函数从堆中分配到块内存,使用完后,程序必须负责相应的调用free或delete释放该内存块,如果没有释放内存这块内存就不能被再次使用,我们就说这块内存泄漏了
避免内存泄露的几种方式
- 计数法:使用new或者malloc时,让该数+1,delete或free时,该数-1,程序执行完打印这个计数,如果不为0则表示存在内存泄露
- 一定要将基类的析构函数声明为虚函数(这样子类的析构函数必须重新实现,避免忘记释放内存)
- 对象数组的释放一定要用delete []
- 有new就有delete,有malloc就有free,保证它们一定成对出现
内存泄漏检测工具
- 从Linux下可以使用Valgrind工具
- Windows下可以使用CRT库
2.3 栈默认的大小
- Windows 下是2MB
- Linux下是8MB(ulimit-s 设置)
2.4 sizeof() 和 strlen()的区别
int a ,b;
a =strlen("\0");
b =sizeof("\0");// a = 0 , b = 2;
- sizeof()是c关键字,计算内存大小,字节单位
- strlen()是函数,计算字符串的长度,到\0结束
- sizeof是编译确定的,strlen是运行确定的
int a,b,c;char str[20]="0123456789";constchar*str2 ="0123456789";a =strlen(str);b =sizeof(str);c =sizeof(&str);d =strlen(str2);e =sizeof(str2);// a = 10 , b = 20 , c = 4(指针大小);// d = 10 , e = 4(指针大小)
2.5 struct结构体的数据对齐
为什么结构体的sizeof返回值一般大于期望?
- struct的sizeof是所有成员数据对其后长度相加
- union的sizeof是取最大的成员长度(所有成员共用一个内存)
struct数据对其的目的?
- 是编译器的一种计算手段,在空间和复杂度上的平衡,在空间浪费可接收的前提下cpu运算最快处理
- 32位数据传输是4字节(数据字长),struct进行4的倍数对其。64位数据传输是8字节,8的倍数对其
- 对齐的目的是要让数据访问更高效,一般来说,数据类型的对齐要求和它的长度是一致的,比如,
char 是 1 short 是 2 int 是 4 double 是 8- 这不是巧合,比如short,2对齐保证了short只可能出现在一个读取单元的0, 2, 4, 6格,而不会出现在1, 3, 5, 7格;- 再比如int,4对齐保证了一个读取单元可以装载2个int——在0或者4格。- 从根本上杜绝了同一个数据横跨读取单元的问题。
修改默认的数据对齐
- #pragma pack(n),编译器按照n字节对其
- #pragma pack( ),取消自定义对其
- _attribute((aligned(n))) ,让结构体成员对其在n字节自然边界上,如果成员大于n,按照最大成员长度
- _attribute((packed)),取消编译过程的对齐,按照实际占用字节对其
3. 指针
3.1 指针的优点?
指针变量和一般变量区别,一般变量是包含的是数据,而指针变量包含的是地址
- 动态分配内存,直接操作内存,效率高
- 实现动态数据结构(树、链表)
- 高效的“复制”数据
3.2 引用和指针
- 指针是一个变量,存储的是一个地址,引用跟原来的变量实质上是同一个东西,是原变量的别名
- 指针可以有多级,引用只有一级
- 指针可以为空,引用不能为NULL且在定义时必须初始化
- 指针在初始化后可以改变指向,而引用在初始化之后不可再改变
- sizeof指针得到的是本指针的大小(4字节),sizeof引用得到的是引用所指向变量的大小
- 当把指针作为参数进行传递时,也是将实参的一个拷贝传递给形参,两者指向的地址相同,但不是同一个变量,在函数中改变这个变量的指向不影响实参,而引用却可以。
- 引用本质是一个指针,同样会占4字节内存;指针是具体变量,需要占用存储空间(具体情况还要具体分析)。
- 引用在声明时必须初始化为另一变量;指针声明和定义可以分开,可以先只声明指针变量而不初始化,等用到时再指向具体变量。
3.3 数组和指针
- 数组在内存中是连续存放的,开辟一块连续的内存空间;数组所占存储空间:sizeof(数组名);数组大小:sizeof(数组名)/sizeof(数组元素数据类型);
- 用运算符sizeof 可以计算出数组的容量(字节数)。sizeof( p ),p 为指针得到的是一个指针变量的字节数(4),而不是p 所指的内存容量。
- 编译器为了简化对数组的支持,实际上是利用指针实现了对数组的支持。具体来说,就是将表达式中的数组元素引用转换为指针加偏移量的引用。
- 在向函数传递参数的时候,如果实参是一个数组,那用于接受的形参为对应的指针。也就是传递过去是数组的首地址而不是整个数组,能够提高效率;
- 在使用下标的时候,两者的用法相同,都是原地址加上下标值,不过数组的原地址就是数组首元素的地址是固定的,指针的原地址就不是固定的。
3.4 指针的加法
指针加上n,为加上n个指针类型的长度
unsignedchar*p1 =0x801000;unsignedint*p2 =0x810000;
p1+=5;//p1 = 0x801000 + 5*1 = 0x801005;
p2+=5;//p2 = 0x810000 + 5*4 = 0x810000;
3.5 空指针、野指针和悬空指针
- 空指针 空指针不会指向任何地方,它不是任何对象或函数的地址
int*p =NULL;int*p2 =nullptr; - 野指针 指的是没有被初始化过的指针
intmain(void){int* p;// 未初始化 std::cout<<*p << std::endl;// 未初始化就被使用return0;} - 悬空指针 最初指向的内存已经被释放了的一种指针
intmain(void){int* p =nullptr;int* p2 =newint; p = p2;delete p2;}此时 p和p2就是悬空指针,指向的内存已经被释放。继续使用这两个指针,行为不可预料### 野指针和悬空指针的产生和解决 - 野指针:指针变量未及时初始化 => 定义指针变量及时初始化,要么置空。
- 悬空指针:指针free或delete之后没有及时置空 => 释放操作后立即置空。 或使用智能指针(避免悬空指针产生)
3.6 指针函数和函数指针的区别
指针函数
- 返回值为指针类型的函数
#include<stdio.h>int*fun(int* x)//传入指针 {int* tmp = x;//指针tmp指向xreturn tmp;//返回tmp指向的地址}intmain(){int b =2;int* p =&b;//p指向b的地址printf("%d",*fun(p));//输出p指向的地址的值return0;}
函数指针
- 函数指针是 指向函数的指针 。主体是指针,指向的是一个函数的地址
- 两种方法赋值:指针名 = 函数名; 指针名 = &函数名
#include<stdio.h>intadd(int x,int y){return x + y;}intmain(){int(*fun)(int,int);//声明函数指针 fun =&add;//fun函数指针指向add函数//fun = add; //同上,等价fun = &add;printf("%d ",fun(3,5));printf("%d",(*fun)(4,2));return0;}
4. 预处理
为编译做准备工作,处理#开头的指令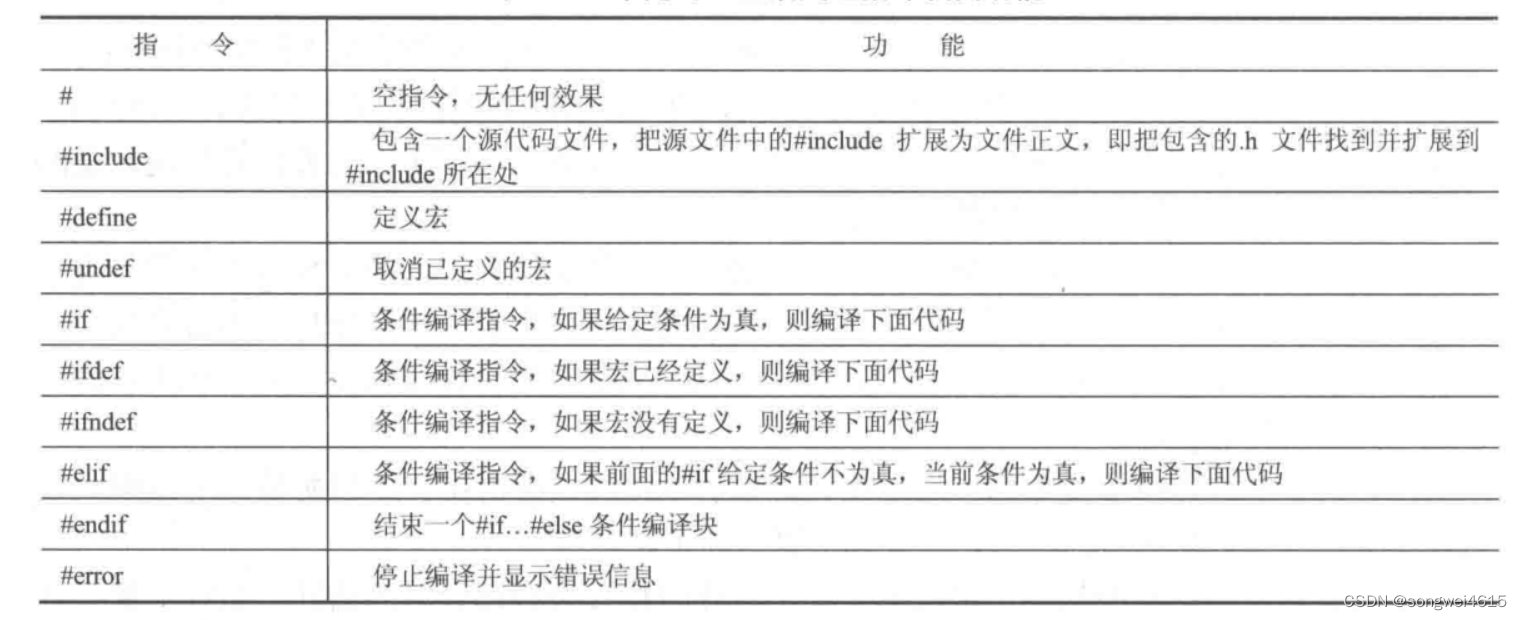
4.1 ifndef/define/endif的作用
防止头文件被重复包含和编译。头文件重复包含会增大程序大小,重复编译增加编译时间
4.2 #include< > 和 #include“ ”的区别
- <>和" "表示编译器在搜索头文件时的顺序不同,
- <>表示从系统目录下开始搜索,然后再搜索PATH环境变量所列出的目录,不搜索当前目录,
- ""是表示从当前目录开始搜索,然后是系统目录和PATH环境变量所列出的目录。 所以,系统头文件一般用<>,用户自己定义的则可以使用"",加快搜索速度。
4.3 #define 的缺点
#define只能进行字符替换
- 无法类型检查
- 由于优先级的不同,会产生潜在问题
#defineMAX_NUM100+1int a = MAX_NUM *10;//a=110//等价于int a =100+1*10;//正确定义为#defineMAX_NUM(100+1)int a = MAX_NUM *10;//a=1010 - 无法单步调试
- 导致代码膨胀
4.4 写一个标准宏MIN
#defineMIN(A,B)((A)<=(B)?(A):(B))
每个括号都是必须的,如果没有结果无法预测
4.5 #define和typdef的区别
- define主要用于定义常量及书写复杂的内容;typedef主要用于定义类型别名。
- define替换发生在编译阶段之前,属于文本插入替换;typedef是编译的一部分。
- define不检查类型;typedef会检查数据类型。
- define不是语句,不在在最后加分号;typedef是语句,要加分号标识结束。
- 对指针的操作不同
#defineINTPTR1int*typedefint* INTPTR2;INTPTR1 p1, p2;//声明一个指针变量p1和一个整型变量p2INTPTR2 p3, p4;//声明两个指针变量p3、p4``````#defineINTPTR1int*typedefint* INTPTR2;int a =1;int b =2;int c =3;const INTPTR1 p1 =&a;//const INTPTR1 p1是一个常量指针const INTPTR2 p2 =&b;//const INTPTR2 p2是一个指针常量INTPTR2 const p3 =&c;//INTPTR2 const p3是一个指针常量
4.6 宏定义和内联函数的区别
- 宏定义是在预处理阶段进行代码替换,内联函数是编译阶段插入代码
- 宏定义没有类型检查,内敛函数有类型检查
内联函数和普通函数的区别
- 编译器将内联函数的位置进行函数展开,避免函数调用的开销,提高效率
- 普通函数被调用,跳跃到函数入口地址,执行结束后跳转回调用地方
- 内敛函数不需要寻址,执行N次内联函数,代码就复制N次
- 函数体过大,编译器放弃内联,变的和普通函数一样
- 内联函数不能递归,编译器无法预知深度,变成普通函数
4.7 定义常量用#define和const谁更好?
- #define只能单纯文本替换,不分配周期,寸在代码段
- const常量在程序数据段,分配内存
- #define没有数据类型,const有数据类型
- #define没法调试,const可以调试
5.结构体与类
5.1 struct和union的区别
- 联合体所有成员共用一块内存,结构体成员占用空间累加
- 对联合体的不用成员赋值,对其他成员重写;结构体成员互相不影响
union{int i;char x[2];}intmain(){
a.x[0]=10;
a.x[1]=1;printf("%d",a.i);//输出为266}
其中 a.x[0]=10=00001010 ;a.x[1] = 1 = 00000001。
输出 i 的时候,将a.x[0] a.x[1] 看作一个整数,为00000001 00001010,为256+8+2 = 266

5.2 C++中struct和class的区别
相同点
- 两者都拥有成员函数、公有和私有部分
- 任何可以使用class完成的工作,同样可以使用struct完成
不同点
- 两者中如果不对成员不指定公私有,struct默认是公有的,class则默认是私有的
- class默认是private继承, 而struct默认是public继承
C++和C的struct区别
- C语言中:struct是用户自定义数据类型(UDT);C++中struct是抽象数据类型(ADT),支持成员函数的定义,(C++中的struct能继承,能实现多态)
- C中struct是没有权限的设置的,且struct中只能是一些变量的集合体,可以封装数据却不可以隐藏数据,而且成员不可以是函数
- C++中,struct增加了访问权限,且可以和类一样有成员函数,成员默认访问说明符为public(为了与C兼容)
- struct作为类的一种特例是用来自定义数据结构的。一个结构标记声明后,在C中必须在结构标记前加上struct,才能做结构类型名(除:typedef struct class{};);C++中结构体标记(结构体名)可以直接作为结构体类型名使用,此外结构体struct在C++中被当作类的一种特例
6. 位操作
6.1 最有效的计算2乘8的方法
int a =2;
a = a<<3;//a乘上2的三次方
计算乘7倍
int a =2;
a = (a<<3)-a;
6.2 位操作求两个数的平均值
int a =2.b =3;int c ;
c =(a&b)+((a^b)>>1);
- 对于表达式(x&y)+(xy)>>1), x&y表示的是取出x与y二进制位数中都为1的所有位, xy表示的是x与y中有一个为1’的所有位,右移1位相当于执行除以2运算。
- 整个表达式实际上可以分为两部分,第一部分是都为1的部分,求平均数后这部分的值保持不变;而第二部分是x为1、y为0的部分,以及y为1、x为0的部分,两部分加起来再除以2,然后跟前面的相加就可以表示两者的平均数了
6.3 什么是大端和小端,如何判断?
- 小端存储:字数据的低字节存储在低地址中(数据存储从低字节到高字节)
- 大端存储:字数据的高字节存储在低地址中(数据存储从高字节到低字节) 例如:32bit的数字0x12345678

代码判断
- 方式一:使用强制类型转换-这种法子不错
#include<iostream>usingnamespace std;intmain(){int a =0x1234;//由于int和char的长度不同,借助int型转换成char型,只会留下低地址的部分char c =(char)(a);if(c ==0x12)
cout <<"big endian"<< endl;elseif(c ==0x34)
cout <<"little endian"<< endl;}
- 方式二:巧用union联合体
#include<iostream>usingnamespace std;//union联合体的重叠式存储,endian联合体占用内存的空间为每个成员字节长度的最大值union endian
{int a;char ch;};intmain(){
endian value;
value.a =0x1234;//a和ch共用4字节的内存空间if(value.ch ==0x12)
cout <<"big endian"<<endl;elseif(value.ch ==0x34)
cout <<"little endian"<<endl;}
版权归原作者 songwei4615 所有, 如有侵权,请联系我们删除。