
1. es介绍
1.1 什么是es
elasticsearch是一个基于Lucene的分布式全文检索服务器,它隐藏了Lucene的复杂性,对外提供Restful 接口来操作索引、搜索。
1.2 es原理
** 1. 索引结构**
下图是ElasticSearch的索引结构,右边黑蓝色色部分是原始文档,左边黄色部分是逻辑结构,逻辑结构也是为了更好的去描述ElasticSearch的工作原理及去使用物理结构中的索引文件。

** 2. 倒排索引**
正排索引:查字典时从第一页开始找,直到找到为止(文档--->关键字)
倒排索引:也常被称为反向索引,倒排索引是**从关键字到文档**的映射(已知关键字求文档)。
倒排索引表的组成: trem:关键字 term------>document:页码 document:文档 分词列表的特点: 1)不重复 2)不搜索的field(图片)不参加分词 3)“的、地、得、a、an、the” 语气词不参加分词
1.3 es的启动器
elasticsearch-rest-high-level-client
2. es的安装和启动
2.1 安装
1. 设置虚拟机内存>1.5G,并重启
2. 创建admin账户,并把upload和local目录的拥有者设置为admin
#从5.0开始,ElasticSearch 安全级别提高了,不允许采用root帐号启动,所以我们要添加一个用户。
groupadd elk #创建elk 用户组
useradd admin
passwd admin
usermod -G elk admin #将admin用户添加到elk组
chown -R admin:elk /usr/upload
chown -R admin:elk /usr/local #chown将指定文件的拥有者改为指定的用户或组 -R处理指定目录以及其子目录下的所有文件
su admin
3. 解压安装包
d /usr/upload
tar -zxvf elasticsearch-6.2.3.tar.gz -C /usr/local
4. 修改elasticsearch.yml,用于配置Elasticsearch运行参数
vim /usr/local/elasticsearch-6.2.3/config/elasticsearch.yml:
cluster.name: power_shop
node.name: power_shop_node_1
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
discovery.zen.ping.unicast.hosts: ["192.168.204.132:9300", "192.168.204.133:9300"]
path.data: /usr/local/elasticsearch-6.2.3/data
path.logs: /usr/local/elasticsearch-6.2.3/logs
http.cors.enabled: true
http.cors.allow-origin: /.*/
5. 修改jvm.options,用于配置Elasticsearch JVM设置
vim /usr/local/elasticsearch-6.2.3/config/jvm.options:
-Xms512m
-Xmx512m
6. 修改文件创建权限,给admin用户增加权限
su root
vim /etc/security/limits.conf:#追加以下下内容
* soft nofile 65536
* hard nofile 65536
7. 修改虚拟内存大小,ES需要开辟一个262144字节以上空间的虚拟内存
su root
vim /etc/sysctl.conf:
vm.max_map_count=655360 #限制一个进程可以拥有的VMA(虚拟内存区域)的数量
sysctl -p #让sysctl.conf配置生效
2.2 启动和关闭
su admin
启动:
./elasticsearch
#或
./elasticsearch -d
关闭:
ps -ef | grep elasticsearch
kill -9 pid
2.3 测试
#访问http://192.168.204.132:9200,返回以下结果:
{
"name" : "power_shop_node_1", # node name 结点名称。随机分配的结点名称
"cluster_name" : "power_shop", # cluster name 集群名称。 默认的集群名称
"cluster_uuid" : "RqHaIiYjSoOyrTGq3ggCOA", # 集群唯一 ID
"version" : {
"number" : "6.2.3", #版本号
"build_hash" : "c59ff00",
"build_date" : "2018-03-13T10:06:29.741383Z",#发布日期
"build_snapshot" : false,#是否快照版本
"lucene_version" : "7.2.1",#lucene版本号
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
3. 安装kibana
3.1 kibana介绍
Kibana是ES提供的一个基于Node.js的管理控制台, 可以很容易实现高级的数据分析和可视化,以图标的形式展现出来。解压即安装,下载地址:https://www.elastic.co/cn/
kibana可以用来编辑请求语句的,方便学习操作es的语法。有时在进行编写程序,写到查询语句时,往往我会使用kibana进行书写,然后再粘贴到程序中。(不容易出错)
3.2 修改配置
server.port: 5601
server.host: "0.0.0.0" #允许来自远程用户的连接
elasticsearch.url: http://192.168.204.132:9200 #Elasticsearch实例的URL
3.3 启动测试
浏览器访问:http://127.0.0.1:5601
4. 安装head
4.1 head介绍
head插件是ES的一个可视化管理插件,用来监视ES的状态,并通过head客户端和ES服务进行交互,比如创建映射、创建索引等。从ES6.0开始,head插件支持使得node.js运行。下载地址:https://github.com/mobz/elasticsearch-head
4.2 启动测试
运行: npm run start
浏览器访问:http://127.0.0.1:9100/
5. es入门案例
5.1 index管理
** 1. 创建index**
索引库。包含若干相似结构的 Document 数据,相当于数据库的database。
语法:
PUT /index_name
如:
PUT /java06
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1
}
}
** number_of_shards** - 表示一个索引库将拆分成多片分别存储不同的结点,提高了ES的处理能力
** number_of_replicas** - 是为每个 primary shard分配的replica shard数,提高了ES的可用性,如果只有一台机器,设置为0
** 2. 修改index**
注意:索引一旦创建,primary shard 数量不可变化,可以改变replica shard 数量。
语法:
PUT /index_name/_settings
如:
PUT /java06/_settings
{
"number_of_replicas" : 1
}
ES 中对 shard 的分布是有要求的,有其内置的特殊算法:
Replica shard 会保证不和他的那个 primary shard 分配在同一个节点上;如过只有一个节点,则此案例执行后索引的状态一定是yellow。
** 3. 删除index**
DELETE /java06[, other_index]
5.2 mapping管理
映射,创建映射就是向索引库中创建field(类型、是否索引、是否存储等特性)的过程,下边是document和field与关系数据库的概念的类比:
elasticsearch关系数据库index(索引库)database(数据库)type(类型)table(表)document(文档)row(记录)field(域)column(字段)
注意:6.0之前的版本有type(类型)概念,type相当于关系数据库的表,ES6.x 版本之后,type概念被弱化ES官方将在ES7.0版本中彻底删除type。
** 1. 创建mapping**
语法:
POST /index_name/type_name/_mapping
如:
POST /java06/course/_mapping
{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text"
},
"studymodel": {
"type": "keyword"
}
}
}
效果:
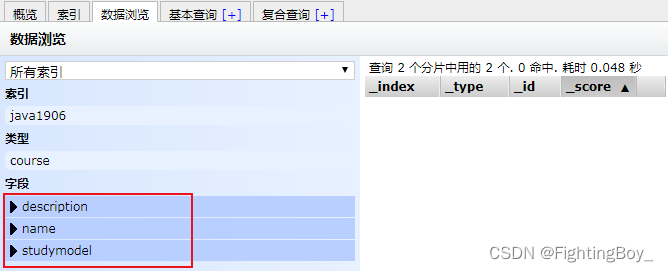
** 2. 查询mapping**
查询所有索引的映射:GET /java06/course/_mapping
** 3.更新mapping**
映射创建成功可以添加新字段,已有字段不允许更新。
** 4.删除mapping**
通过删除索引来删除映射
5.3 document管理
** 1. 创建document**
** **ES中的文档相当于MySQL数据库表中的记录。
PSOT语法
此操作为 ES 自动生成 id 的新增 Document 方式。 语法:
POST /index_name/type_name/id
如:
POST /java06/course/1
{
"name":"python从入门到放弃",
"description":"人生苦短,我用Python",
"studymodel":"201002"
}
POST /java06/course
{
"name":".net从入门到放弃",
"description":".net程序员谁都不服",
"studymodel":"201003"
}
PUT语法
此操作为手工指定 id 的 Document 新增方式。 语法:PUT/index_name/type_name/id{field_name:field_value} 如:
PUT /java06/course/2
{
"name":"php从入门到放弃",
"description":"php是世界上最好的语言",
"studymodel":"201001"
}
结果:
{
"_index": "test_index", 新增的 document 在什么 index 中,
"_type": "my_type", 新增的 document 在 index 中的哪一个 type 中。
"_id": "1", 指定的 id 是多少
"_version": 1, document 的版本是多少,版本从 1 开始递增,每次写操作都会+1
"result": "created", 本次操作的结果,created 创建,updated 修改,deleted 删除
"_shards": { 分片信息
"total": 2, 分片数量只提示 primary shard
"successful": 1, 数据 document 一定只存放在 index 中的某一个 primary shard 中
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
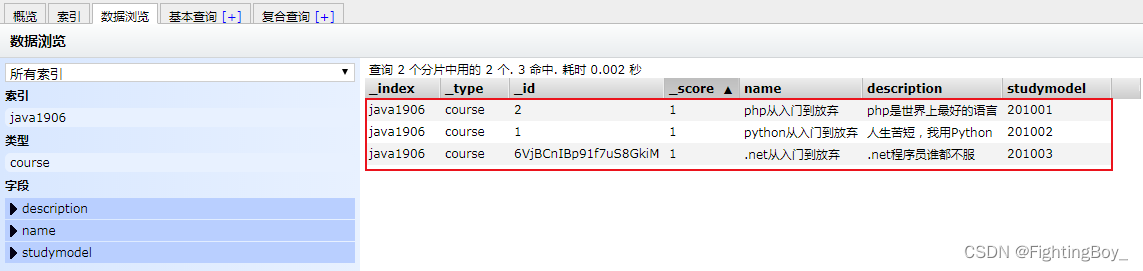
通过head查询数据:
** 2. 查询document**
语法:
GET /index_name/type_name/id
或
GET /index_name/type_name/_search?q=field_name:field_value
如:根据课程id查询文档
GET /java06/course/1
如:查询所有记录
GET /java06/course/_search
如:查询名称中包括php 关键字的的记录
GET /java06/course/_search?q=name:门
结果:
{
"took": 1, # 执行的时长。单位毫秒
"timed_out": false, # 是否超时
"_shards": { # shard 相关数据
"total": 1, # 总计多少个 shard
"successful": 1, # 成功返回结果的 shard 数量
"skipped": 0,
"failed": 0
},
"hits": { # 搜索结果相关数据
"total": 3, # 总计多少数据,符合搜索条件的数据数量
"max_score": 1, # 最大相关度分数,和搜索条件的匹配度
"hits": [# 具体的搜索结果
{
"_index": "java06",# 索引名称
"_type": "course", # 类型名称
"_id": "1",# id 值
"_score": 1, # 匹配度分数,本条数据匹配度分数
"_source": { # 具体的数据内容
"name": "php从入门到放弃",
"description": "php是世界上最好的语言",
"studymodel": "201001"
}, {
"_index": "java06",
"_type": "course",
"_id": "2",
"_score": 0.13353139,
"_source": {
"name": "php从入门到放弃",
"description": "php是世界上最好的语言",
"studymodel": "201001"
}
}, {
"_index": "java06",
"_type": "course",
"_id": "6ljFCnIBp91f7uS8FkjS",
"_score": 0.13353139,
"_source": {
"name": ".net从入门到放弃",
"description": ".net程序员谁都不服",
"studymodel": "201003"
}
}
]
}
}
** 3. 删除document**
ES 中执行删除操作时,ES先标记Document为deleted状态,而不是直接物理删除。当ES 存储空间不足或工作空闲时,才会执行物理删除操作,标记为deleted状态的数据不会被查询搜索到(ES 中删除 index ,也是标记。后续才会执行物理删除。所有的标记动作都是为了NRT(近实时)实现)
语法:
DELETE /index_name/type_name/id
如:
DELETE /java06/course/3
5.4 es读写过程
** 1.documnet routing(数据路由)**
当客户端创建document的时候,es需要确定这个document放在该index哪个shard上,这个过程就是document routing。
路由过程:
路由算法:shard = hash(5) %number_of_primary_shards
id:document的_id,可能是手动指定,也可能是自动生成,决定一个document在哪个shard上
number_of_primary_shards:主分片数量。
** 2.为什么primary shard数量不可变?**
原因:假如我们的集群在初始化的时候有5个primary shard,我们往里边加入一个document id=5,假如hash(5)=23,这时该document 将被加入 (shard=23%5=3)P3这个分片上。如果随后我们给es集群添加一个primary shard ,此时就有6个primary shard,当我们GET id=5 ,这条数据的时候,es会计算该请求的路由信息找到存储他的 primary shard(shard=23%6=5) ,根据计算结果定位到P5分片上。而我们的数据在P3上。所以es集群无法添加primary shard,但是可以扩展replicas shard。
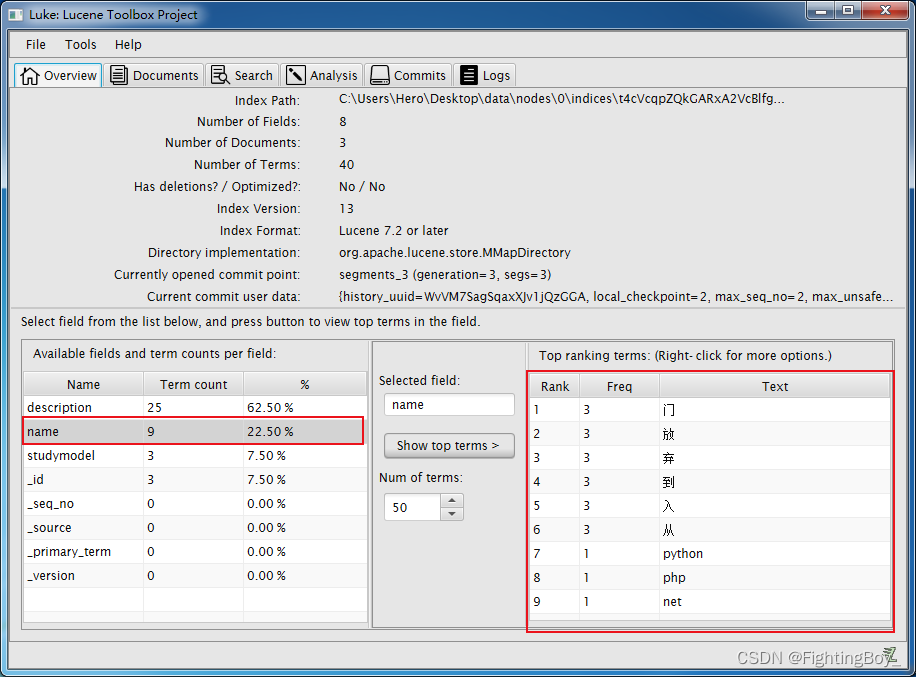
** 3.luke查看ES的逻辑结构**
- 拷贝elasticsearch-6.2.3/data到windows
- 双击luke.bat,启动luke
- 使用luke打开data\nodes\0\indices路径
版权归原作者 一行代码俩BUG 所有, 如有侵权,请联系我们删除。