

添加spark的相关依赖和打包插件
步骤1 打开pom.xmlà添加的以下依赖,点击右下角enable auto-import自动下载
<!--设置依赖版本号-->
<properties>
<scala.version>2.11.8</scala.version>
<hadoop.version>2.7.1</hadoop.version>
<spark.version>2.0.0</spark.version>
</properties>
<dependencies>
<!--Scala-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!--Spark-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!--Hadoop-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
添加完依赖后选择自动载入

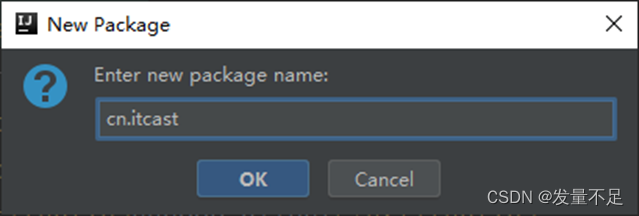
步骤2 右击main下的Scala文件先创建一个package并命名为cn.itcast
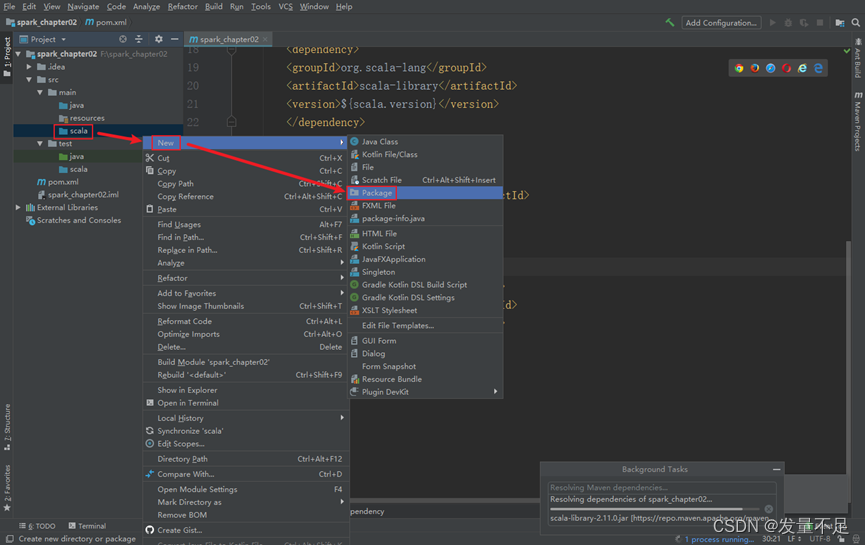
步骤3 创建WordCount.scala文件用于词频统计 alt+回车:选择导入包
问题:没有scala文件创建选项
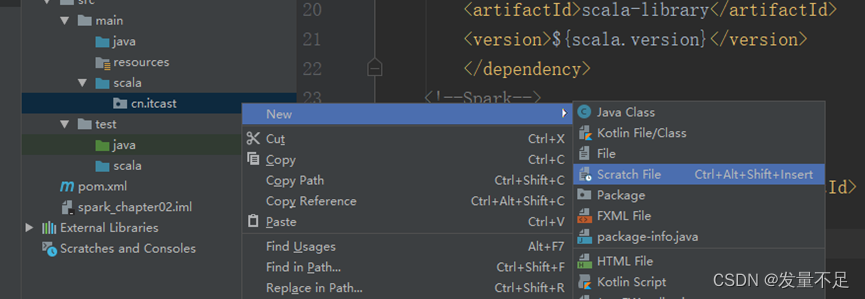
解决方法:
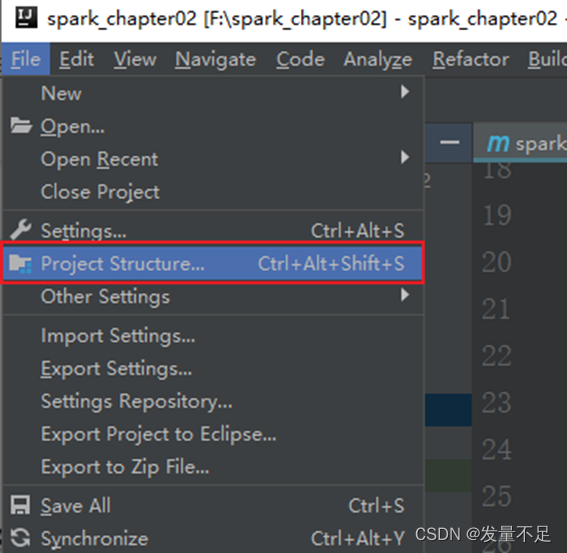
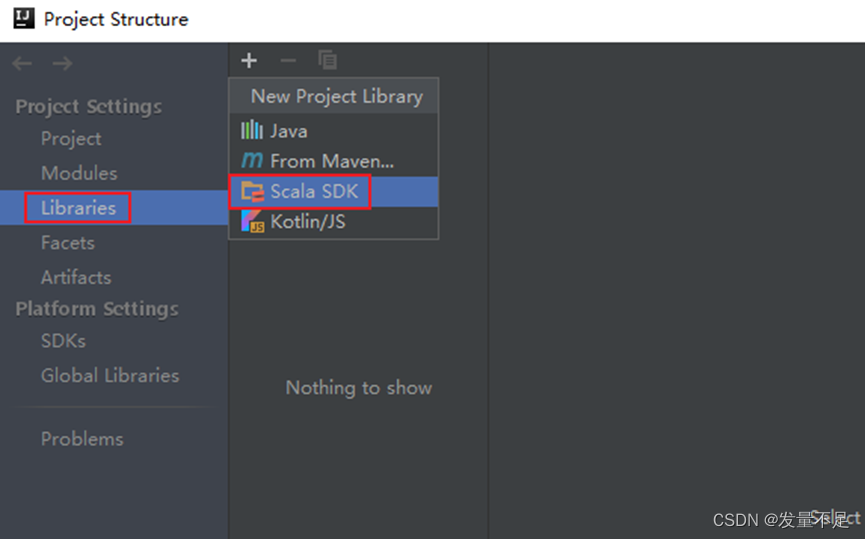
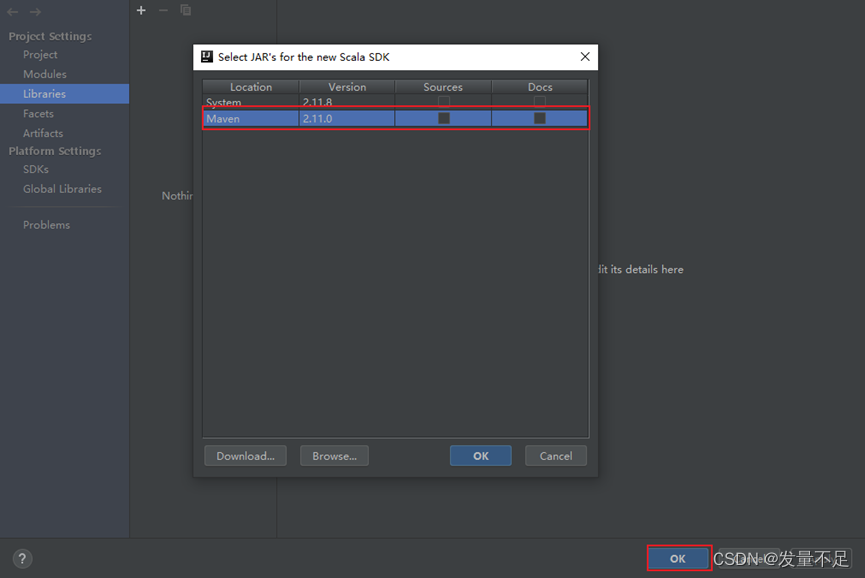

添加完插件包后即可: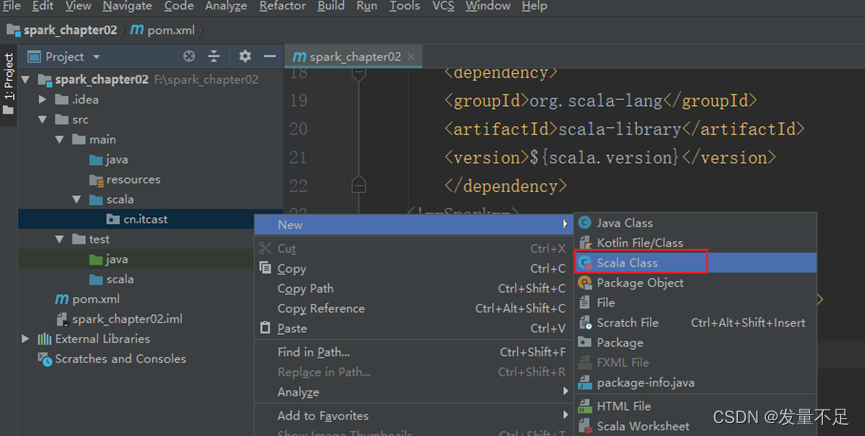
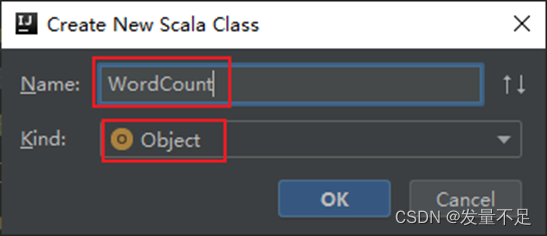
步骤3 创建WordCount.scala文件用于词频统计 alt+回车:选择导入包
注意:需要事先在D盘创建word文件夹下的words.txt里面内容如下:(最好不要用中文路径)
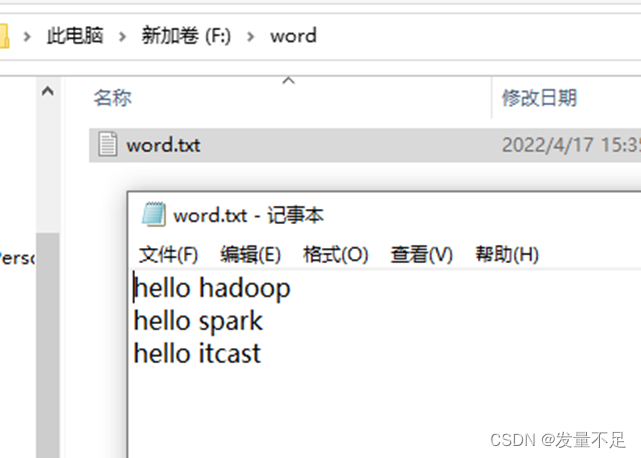
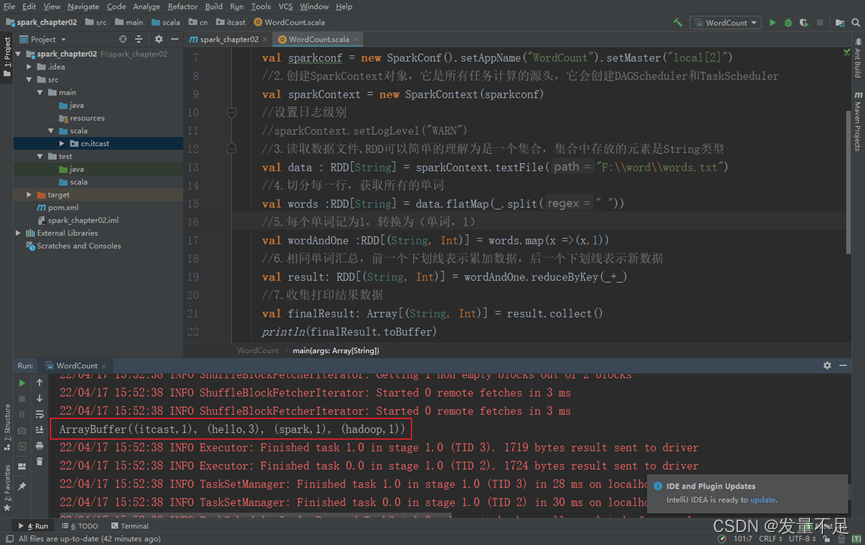
package cn.itcast
# 导入包
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//1.创建SparkConf对象,设置appName和Master地址
val sparkconf = new SparkConf().setAppName("WordCount").setMaster("local[2]")
//2.创建SparkContext对象,它是所有任务计算的源头,它会创建DAGScheduler和TaskScheduler
val sparkContext = new SparkContext(sparkconf)
//设置日志级别
//sparkContext.setLogLevel("WARN")
//3.读取数据文件,RDD可以简单的理解为是一个集合,集合中存放的元素是String类型
val data : RDD[String] = sparkContext.textFile("D:\\word\\words.txt")
//4.切分每一行,获取所有的单词
val words :RDD[String] = data.flatMap(_.split(" "))
//5.每个单词记为1,转换为(单词,1)
val wordAndOne :RDD[(String, Int)] = words.map(x =>(x,1))
//6.相同单词汇总,前一个下划线表示累加数据,后一个下划线表示新数据
val result: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
//7.收集打印结果数据
val finalResult: Array[(String, Int)] = result.collect()
println(finalResult.toBuffer)
//8.关闭sparkContext对象
sparkContext.stop()
}
}
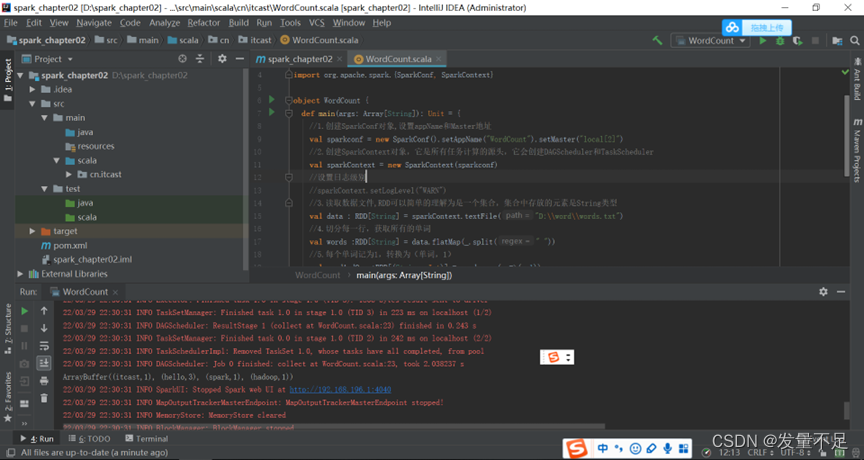
可以看到计算出的单词频数itcast(1)Hadoop(1)spark(1)hello(3)
可能碰到的问题:
如果遇到运行结果报错或者结果没出来,则是没放Scala-sdk-2.11.8
解决方法:

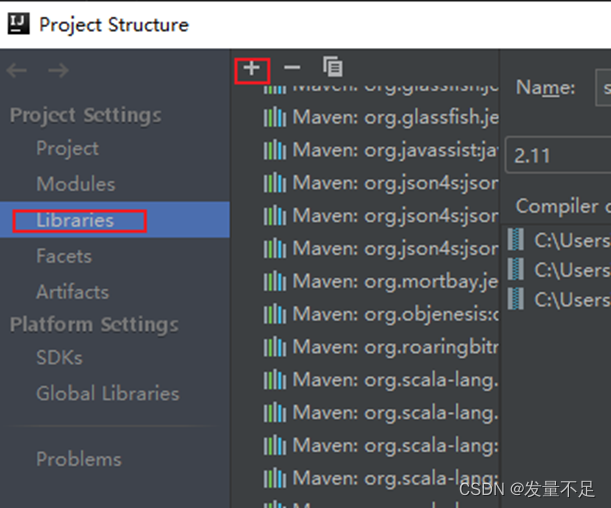
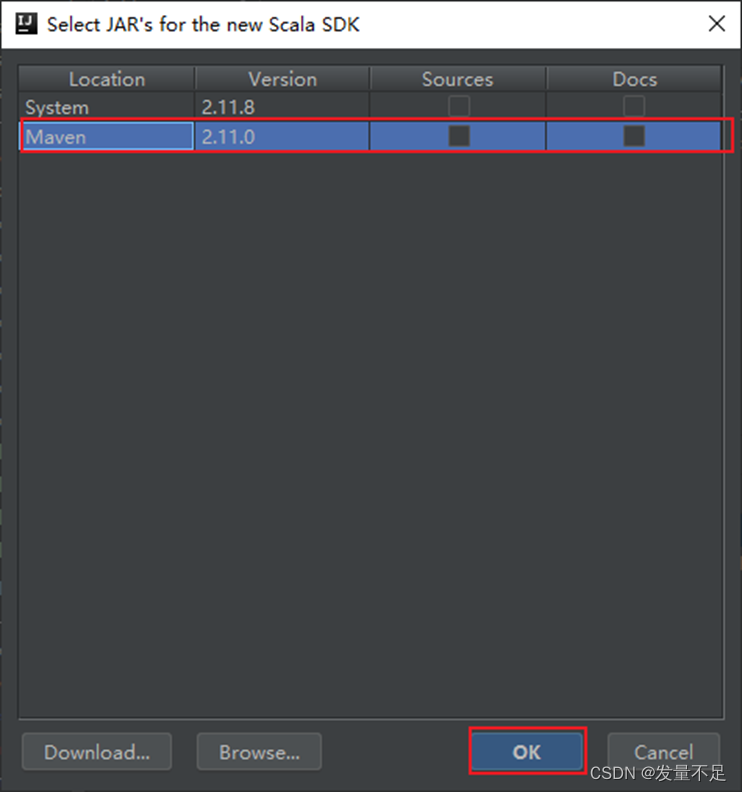
如果没有则需要手动添加:
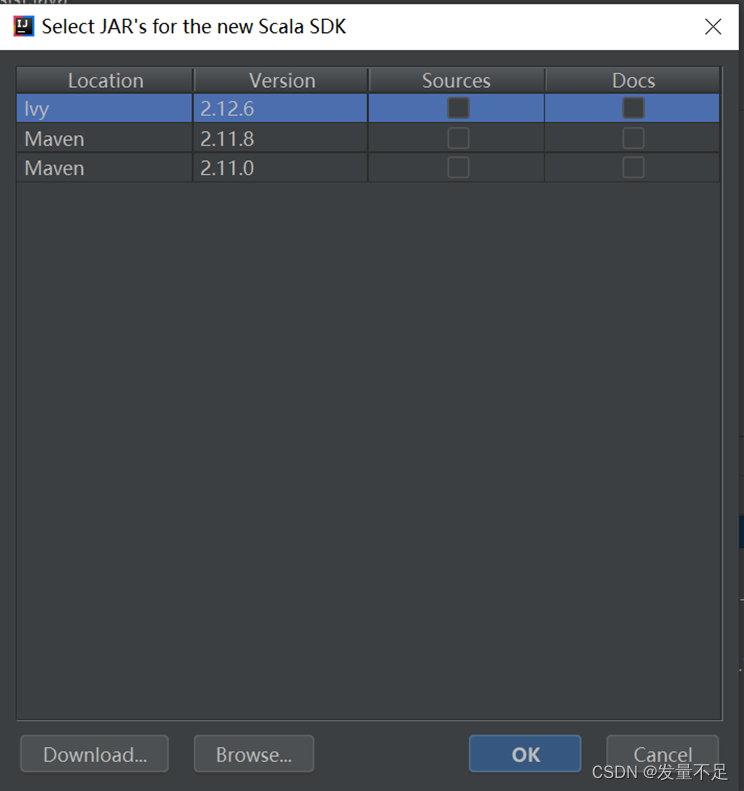
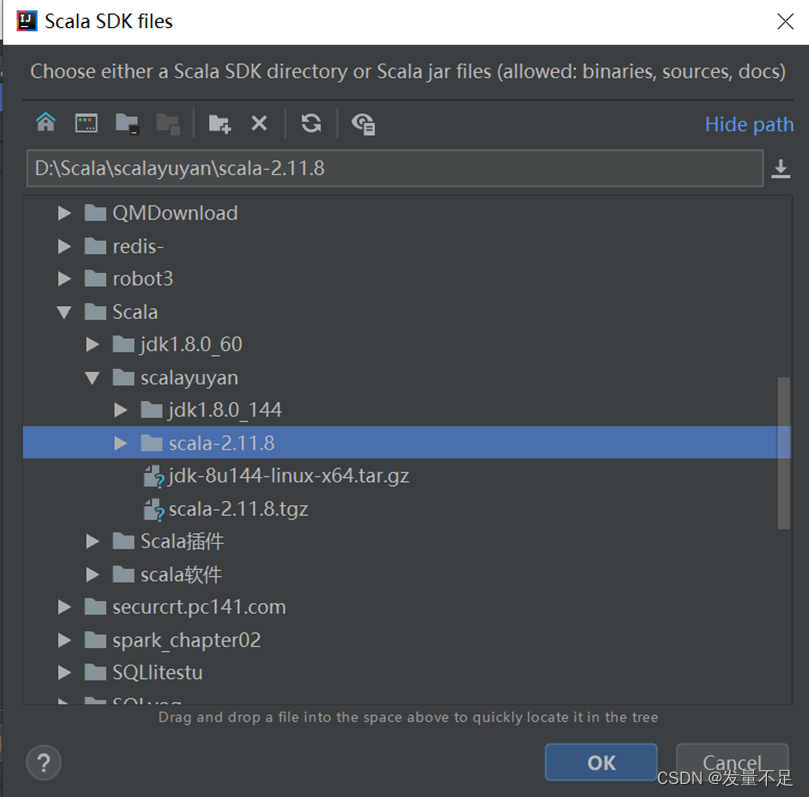
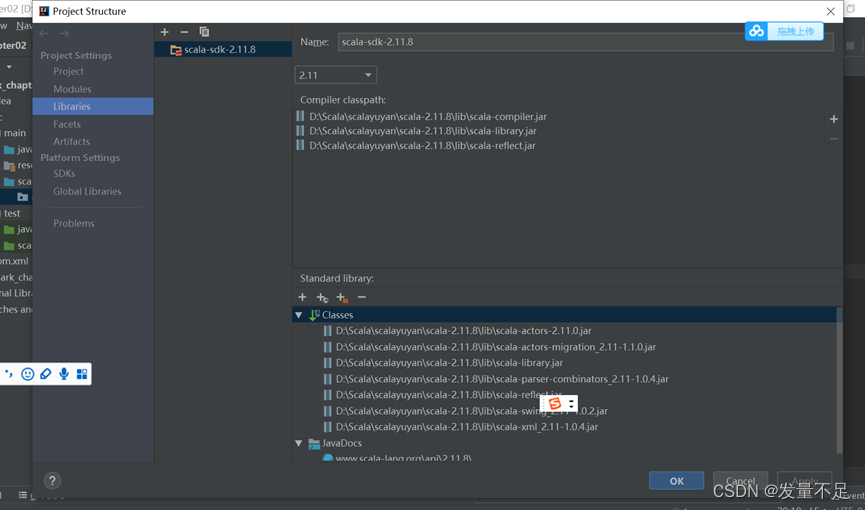
解决以上问题,运行结果如下
可以看到计算出的单词频数itcast(1)Hadoop(1)spark(1)hello(3)
本文转载自: https://blog.csdn.net/m0_57781407/article/details/126256183
版权归原作者 发量不足 所有, 如有侵权,请联系我们删除。
版权归原作者 发量不足 所有, 如有侵权,请联系我们删除。