
HDFS集群搭建-伪分布式模式
前言
博主语录:一文精讲一个知识点,多了你记不住,一句废话都没有
经典语录:美好的事情不是没有裂痕,而是满是裂痕而没有崩开
一、实操&理论验证
- HDFS安装配置
- HDFS命令行使用
- 理论知识点验证
二、官网导读
Hadoop - Apache Hadoop 2.6.5https://hadoop.apache.org/docs/r2.6.5/
- 支持最好的平台:GNU/Linux
- 依赖的软件:java,ssh
- 部署模式:
- Local (Standalone) Mode
- Pseudo-Distributed Mode
- Fully-Distributed Mode
三、思路
- 基础设施
- 部署配置
- 初始化运行
- 命令行使用
四、基础设施
操作系统、环境、网络、必要软件
1、设置IP及主机名
注意:大家看看自己的vm的编辑->虚拟网络编辑器->观察 NAT模式的地址
设置网络和设置IP
vi /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0 #HWADDR=00:0C:29:42:15:C2 TYPE=Ethernet ONBOOT=yes NM_CONTROLLED=yes BOOTPROTO=static IPADDR=192.168.150.11 NETMASK=255.255.255.0 GATEWAY=192.168.150.2 DNS1=223.5.5.5 DNS2=114.114.114.114
设置主机名
vi /etc/sysconfig/network
NETWORKING=yes HOSTNAME=node01
2、关闭防火墙&selinux
关闭防火墙
service iptables stop
chkconfig iptables off
关闭 selinux
vi /etc/selinux/config
SELINUX=disabled
3、设置hosts映射
设置本机的IP到主机名的映射关系
vi /etc/hosts
192.168.150.11 node01 192.168.150.12 node02
4、时间同步
yum install ntp -y
vi /etc/ntp.conf
server ntp1.aliyun.com
service ntpd start
chkconfig ntpd on
5、安装JDK
注意:有一些软件只认:/usr/java/default
rpm -i jdk-8u181-linux-x64.rpm
vi /etc/profile
export JAVA_HOME=/usr/java/default export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile | . /etc/profile
6、设置SSH免秘钥
ssh免密:
ssh localhost
**注意: **
**1)验证自己还没免密 **
2)被动生成了 /root/.ssh
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
白话解释SSH免秘钥
如果A 想 免密的登陆到B:
A:ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
B:cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
结论:
B包含了A的公钥,A就可以免密的登陆
生活案例:
你去陌生人家里得撬锁
去女朋友家里:拿钥匙开门
五、部署配置
伪分布式: (单一节点)
1、部署路径
mkdir /opt/bigdata
tar xf hadoop-2.6.5.tar.gz
mv hadoop-2.6.5 /opt/bigdata/
pwd
/opt/bigdata/hadoop-2.6.5
vi /etc/profile
export JAVA_HOME=/usr/java/default
export HADOOP_HOME=/opt/bigdata/hadoop-2.6.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
2、 配置文件
cd $HADOOP_HOME/etc/hadoop
注意:必须给hadoop配置javahome要不ssh过去找不到
vi hadoop-env.sh
export JAVA_HOME=/usr/java/default
给出NN角色在哪里启动
vi core-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://node01:9000</value> </property>
因为是伪分布式集群,故配置HDFS 副本数为1,如果是真实集群就配置2-3的副本数量
vi hdfs-site.xml
<property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/var/bigdata/hadoop/local/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/var/bigdata/hadoop/local/dfs/data</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>node01:50090</value> </property> <property> <name>dfs.namenode.checkpoint.dir</name> <value>/var/bigdata/hadoop/local/dfs/secondary</value> </property>
配置DN这个角色再那里启动
vi slaves
node01
3、初始化&启动
格式化namenode操作(只要一次就够了)
hdfs namenode -format
**简单过程: **
- 创建配置文件设置的目录
- 并初始化一个空的fsimage
- VERSION文件里生成一个CID
sh start-dfs.sh
第一次:datanode和secondary角色会初始化创建自己的数据目录
修改windows: C:\Windows\System32\drivers\etc\hosts
** 192.168.150.11 node01
192.168.150.12 node02
192.168.150.13 node03
192.168.150.14 node04**
可以通过以下地址访问:
http://node01:50070http://node01:50070
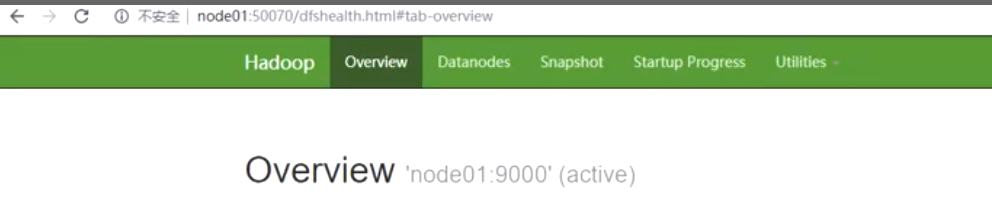
4、简单使用
hdfs dfs -mkdir /bigdata
hdfs dfs -mkdir -p /user/root
5、验证知识点
**观察 editlog的id是不是再fsimage的后边 **
cd /var/bigdata/hadoop/local/dfs/name/current
**SNN 只需要从NN拷贝最后时点的FSimage和增量的Editlog **
cd /var/bigdata/hadoop/local/dfs/secondary/current
**验证上传的大文件是否分块,分块最大文件是否128M **
hdfs dfs -put hadoop*.tar.gz /user/root
cd /var/bigdata/hadoop/local/dfs/data/current/BP-281147636-192.168.150.11-1560691854170/current/finalized/subdir0/subdir0

for i in `seq 100000`;do echo "hello hadoop $i" >> data.txt ;done
hdfs dfs -D dfs.blocksize=1048576 -put data.txt
cd /var/bigdata/hadoop/local/dfs/data/current/BP-281147636-192.168.150.11-1560691854170/current/finalized/subdir0/subdir0
检查data.txt被切割的块,数据是什么样子的

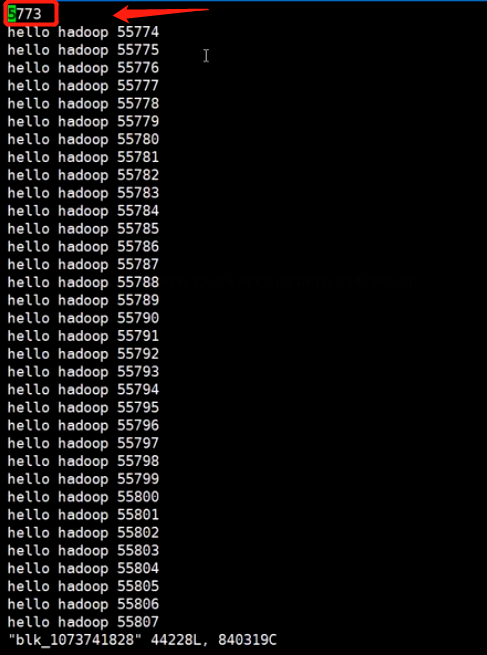
可以看到两个文件的数据直接切开,一行数据被切成一小段,这样的数据到计算会有问题吗?
其实是不影响的,至于什么原理,会在后面的笔记里详细给大家说明
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
版权归原作者 Lansonli 所有, 如有侵权,请联系我们删除。