
前言
爬虫走到今天,我们已经学习过不少方法,来解析网页源代码、抓包、审查元素、加密解密......但是我们有时会不会这样想:可不可以直接拿到浏览器直接显示的信息呢???
因为我们经常看到,数据明明就摆在我们浏览器的页面上,但是苦于源代码的空洞,我们不得不翻箱倒柜的去找json,去找js请求等等。很多时候数据特别隐蔽,令人十分崩溃,有时甚至会想直接在浏览器CV了之!
所以,有想法,那就解决!你不是能显示在浏览器上吗?你不是能CV不能截取信息吗?OK,我让Python自动帮我运行浏览器,拿我想要的内容:selenium就这样应运而来了。
什么是selenium?
来自百度百科:
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。这个工具的主要功能包括:测试与浏览器的兼容性——测试应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成.Net、Java、Perl等不同语言的测试脚本。
由上述简介可得,selenium可以帮助我们自动打开浏览器运行打开想要的网页,并且模仿人的CV操作、输入操作等,进而获取一大堆我们需要的信息。
配置selenium
selenium需要两方面,第一个当然就是安装对应的库,而另一方面就是要安装浏览器对应的驱动程序,并移动到Python解释器所在路径。
安装selenium库

安装就很简单了,直接在Terminal中pip install selenium,当然在cmd里、anaconda里都是一样的
安装浏览器驱动(以Chrome为例)
- 访问ChromeDriver - WebDriver for Chrome - Downloads (chromium.org)
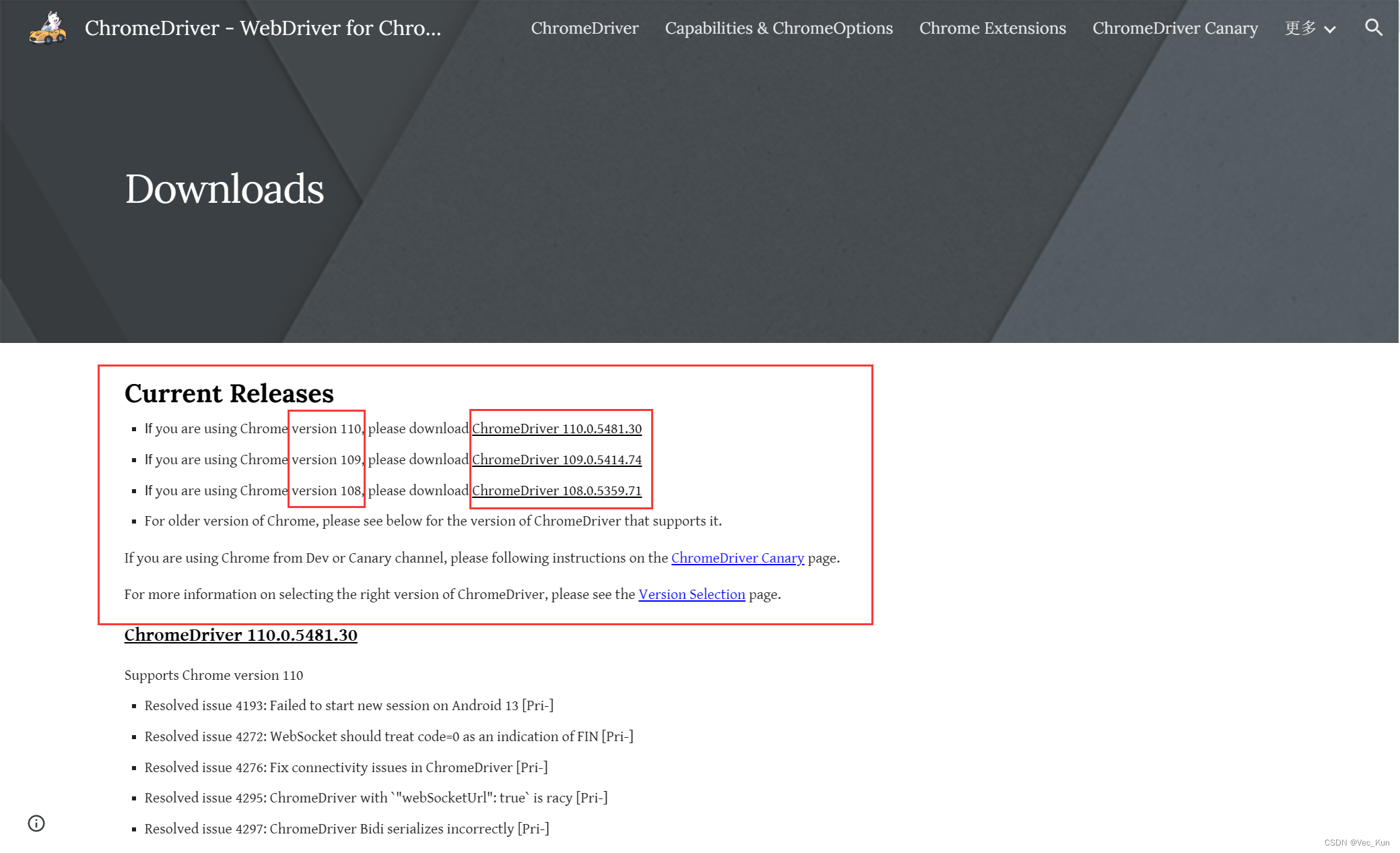
- 根据自己Chrome浏览器的版本号选择驱动文件(找不到就向下取最接近的,比如你是109.0.9,但是没有,那就下载109.0.5,一般都是向下兼容的)
如何查看浏览器版本号?
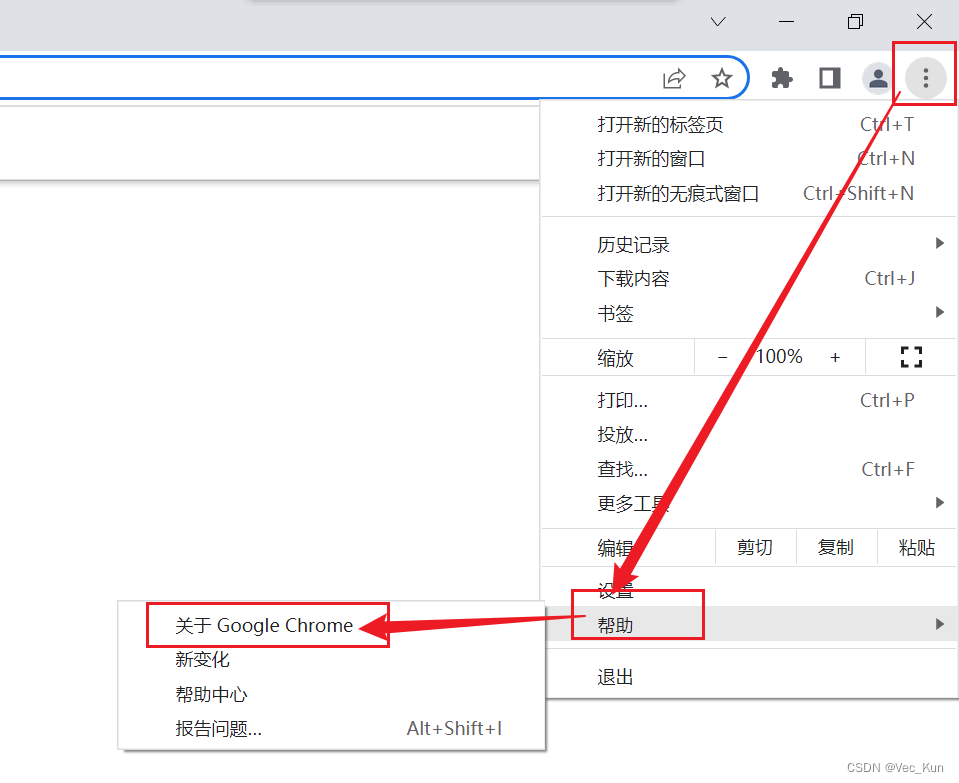
按上图所示,点击关于Google Chrome,弹出以下界面:
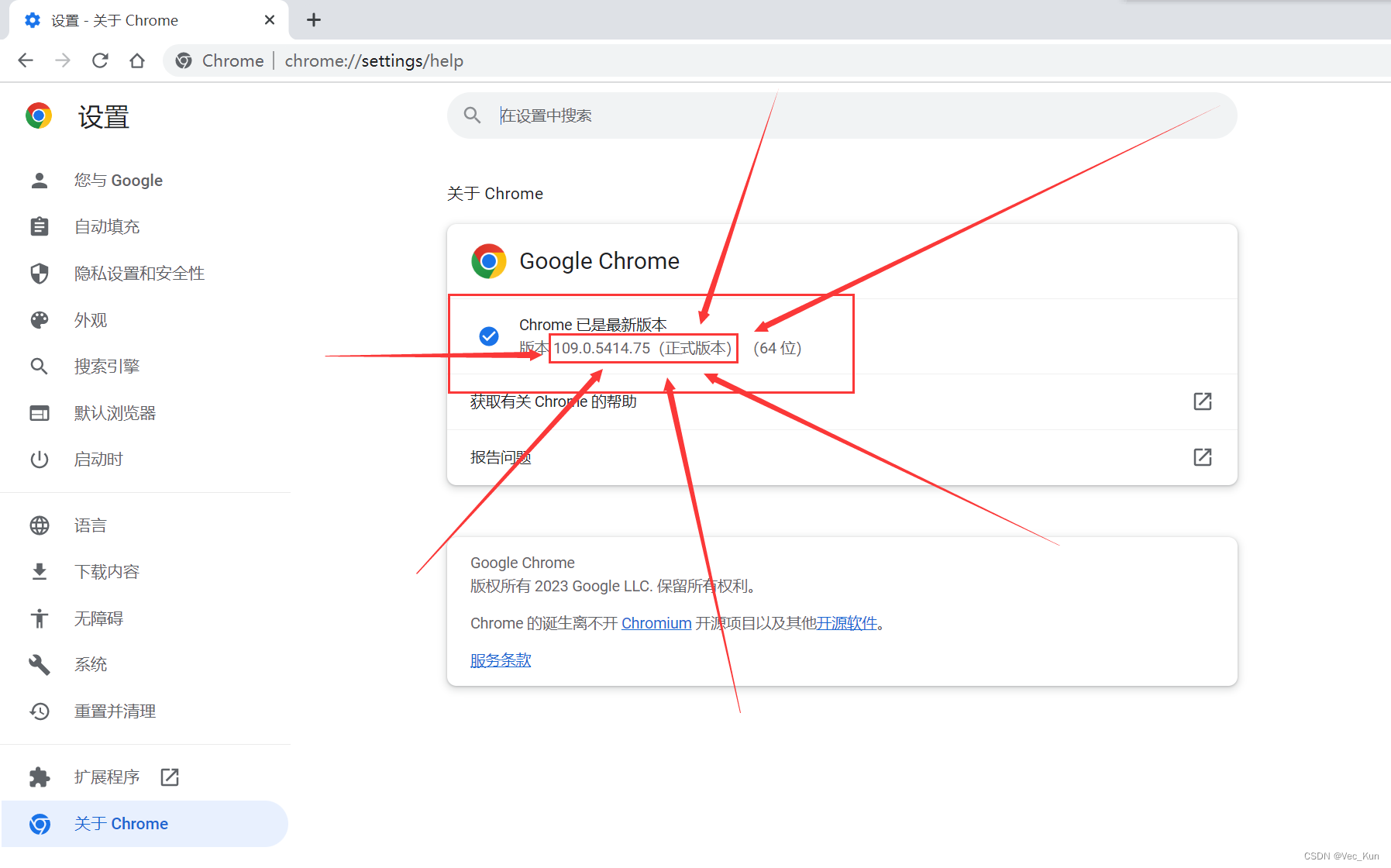 这里显示的就是版本号了,依据这个到第一点所说的网站里去选驱动,这里我根据版本号选择109版本的:
这里显示的就是版本号了,依据这个到第一点所说的网站里去选驱动,这里我根据版本号选择109版本的:
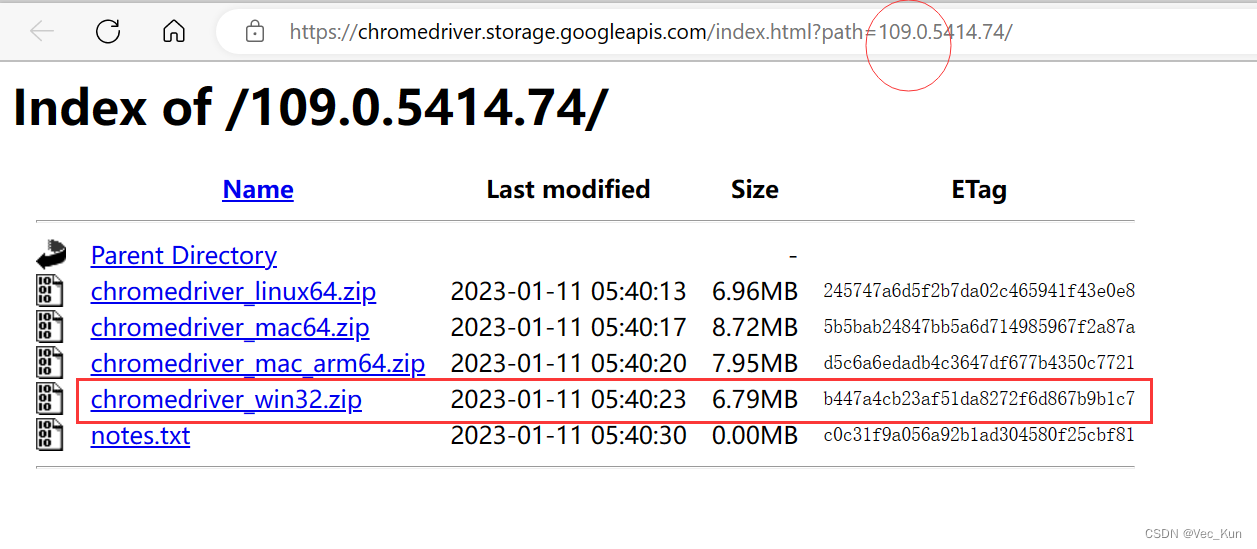
由于我是Windows系统,所以选择第四个,mac的同学自行选择前面对应的
(别担心,32位64位都可选win32,再说也没win64选项嘛)
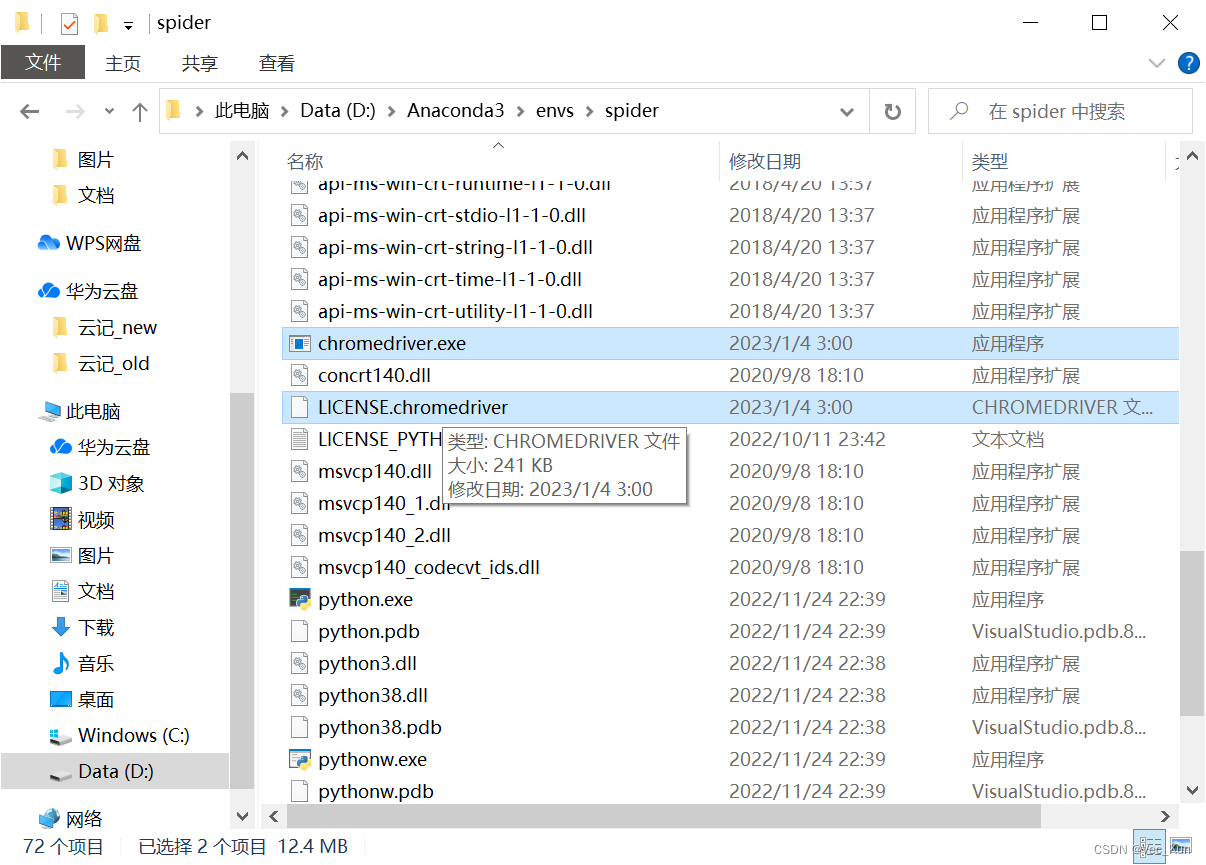
- 下载解压

如图所示,解压出来是两个文件,将它们剪切,粘贴到Python解释器所在路径。
**不知道解释器在哪里? **
1. 如果你是Anaconda虚拟环境,直接去“Anaconda3/envs/虚拟环境名”路径就行
2. 其他渠道环境:只需要在PyCharm或者其他软件里运行一下就看得到解释器位置了:
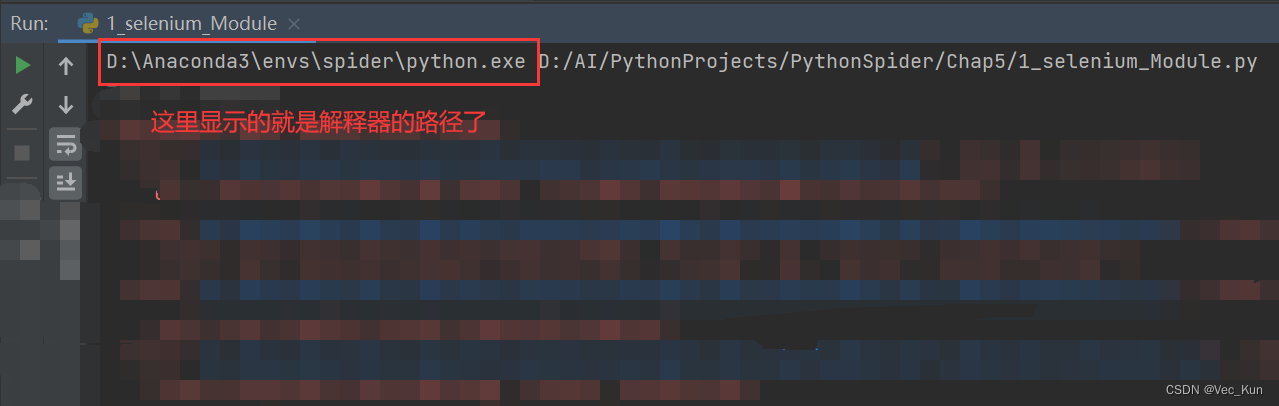
复制进去,配置完毕。(我的是Anaconda环境,仅供参考)
使用selenium库
例1:实现打开网页拿取网页标题
from selenium import webdriver
# 让selenium启动谷歌浏览器
# 1.创建浏览器对象
# 设置
options = webdriver.ChromeOptions()
options.add_experimental_option('detach', True)
options.add_argument('--start-maximized') # 浏览器窗口最大
web = webdriver.Chrome(options=options)
# 2.打开一个网址
web.get("http://www.baidu.com")
print(web.title)
由于当前Python3.8版本会默认在执行完任务后关闭浏览器,我们如果想看效果会转瞬即逝,所以我们需要配置一下webdriver:
第一项就是控制执行完毕以后不关闭浏览器窗口,第二项就是让浏览器弹出时是最大化窗口。
运行效果

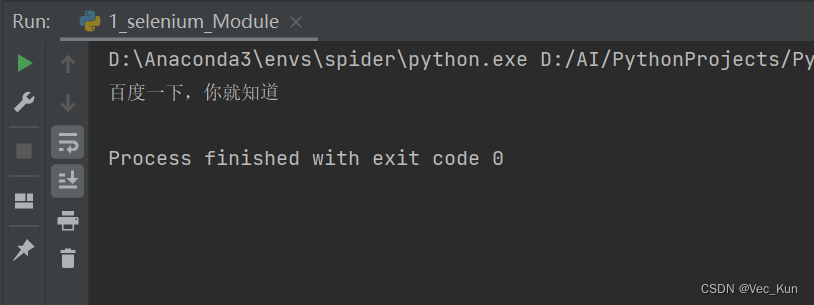
可以看到效果是非常成功的,浏览器自动运行了,并且输出了期望结果,也说明环境搭建成功。
例2:实现抓取某招聘网站Python岗位的职位信息
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
# 让selenium启动谷歌浏览器
# 1.创建浏览器对象
# 设置
options = webdriver.ChromeOptions()
options.add_experimental_option('detach', True)
options.add_argument('--start-maximized') # 浏览器窗口最大
web = webdriver.Chrome(options=options)
# 2.打开一个网址
web.get("http://lagou.com")
# 找到某个元素. 点击它
el = web.find_element(By.XPATH, '//*[@id="changeCityBox"]/ul/li[1]/a')
el.click() # 点击事件
time.sleep(1) # 让浏览器缓一会儿
# 找到输入框. 输入python => 输入回车/点击搜索按钮
web.find_element(By.XPATH, '//*[@id="search_input"]').send_keys("python", Keys.ENTER)
time.sleep(1)
# 查找存放数据的位置. 进行数据提取
# 找到页面中存放数据的所有的li
item_list = web.find_elements(By.XPATH, '//*[@id="jobList"]/div[1]/div')
for item in item_list:
job_name = item.find_element(By.XPATH, "./div[1]/div[1]/div[1]/a").text
job_price = item.find_element(By.XPATH, "./div[1]/div[1]/div[2]/span").text
company_name = item.find_element(By.XPATH, './div[1]/div[2]/div[1]/a').text
print(company_name, job_name, job_price)
这里结合了XPath的知识,我们只需要根据在当前页面的操作,然后在审查元素中找到对应的XPath路径,套入函数就可以了。
我们是要先点击选择所在城市,然后输入要搜索的文本(python),最后获取页面中存放数据的所有li,打印输出即可。
这里只是一个粗糙的例子,目的是为了让大家了解selenium的功能,完善这个小项目大家可以自己动手试一试,后面有时间的话我也会写一写补充下来。
运行效果

可以看到也是成功抓取到了,更加细化的工作交给大家来完成,我就不赘述了。
例3:实现抓取推荐新闻的标题和正文(涉及子页面的切换)
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 让selenium启动谷歌浏览器
# 1.创建浏览器对象
# 设置
options = webdriver.ChromeOptions()
options.add_experimental_option('detach', True)
options.add_argument('--start-maximized') # 浏览器窗口最大
web = webdriver.Chrome(options=options)
# 2.打开一个网址
web.get("http://tuijian.hao123.com/")
# 拿到新闻标题
news_header = web.find_element(By.XPATH, '//*[@id="sdIndex"]/ul/li[1]/a/span').text
# 点击进入首页推荐的第一个横幅新闻
web.find_element(By.XPATH, '//*[@id="sdIndex"]/ul/li[1]/a/span').click()
time.sleep(1)
# 进入到进窗口中进行提取
# 注意, 在selenium的眼中. 新窗口默认是不切换过来的!
web.switch_to.window(web.window_handles[-1])
# 在新窗口中提取内容
news_detail = web.find_element(By.XPATH, '//*[@id="main-content"]/div[1]/div/div[2]').text
print(news_header)
print(news_detail)
time.sleep(1)
# 关掉子窗口
web.close()
# 变更selenium的窗口视角. 回到原来的窗口中
web.switch_to.window(web.window_handles[0])
print(web.title)
这个就和上一个例子大同小异,最大的不同点就在于新闻内容是在子页面获取的,并且获取完毕以后切换回了主页面,可以继续爬取其他新闻。
这里使用的是web.switch_to.window这个api,用web.window_handles[num]来代指第num+1个浏览器标签页。
运行效果

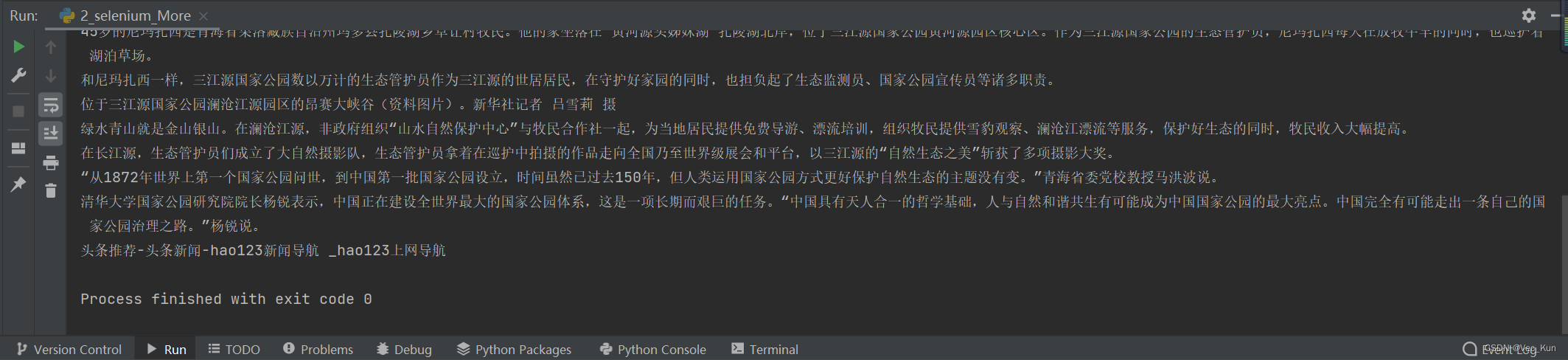
成功拿到了想要的数据,这个自动化的过程还是非常有B格的!
例4:处理iframe内联框架(视频播放器、表格数据等常见)
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 如果页面中遇到了 iframe如何处理
web.get("https://www.csdn.net/?spm=1010.2135.3001.4476")
time.sleep(3)
# 处理iframe的话. 必须先拿到iframe. 然后切换视角到iframe . 再然后才可以拿数据
iframe = web.find_element(By.XPATH, '//*[@id="kp_box_589"]/iframe')
web.switch_to.frame(iframe) # 切换到iframe
time.sleep(1)
print(web.find_element(By.XPATH, '//*[@id="1001319"]/div/div/span').text)
web.switch_to.default_content() # 切换回原页面
time.sleep(1)
print(web.find_element(By.XPATH, '//*[@id="www-home-right"]/div[1]/div[1]/div[2]/div/span').text)
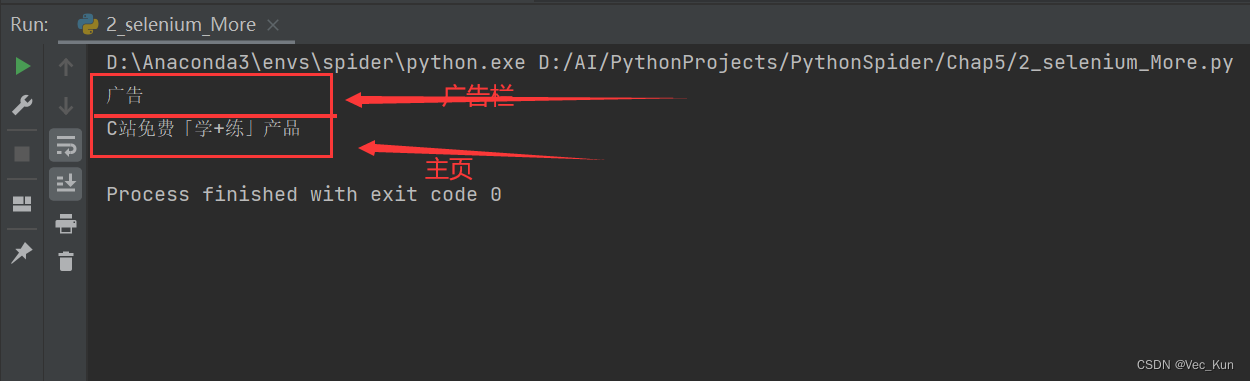
以我们C站的主页与广告栏为例,我们可以看到已经可以成功切换进广告栏(iframe)并且切出来
运行效果

例5:“无头浏览器”,即浏览器在后端运行抓取数据,效果等同低效率的爬虫程序
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.select import Select
from selenium.webdriver.common.by import By
import time
# 准备好参数配置
opt = Options()
opt.add_argument("--headless")
opt.add_argument("--disable-gpu")
web = Chrome(options=opt) # 把参数配置设置到浏览器中
web.get("https://www.endata.com.cn/BoxOffice/BO/Year/index.html")
time.sleep(2)
# 定位到下拉列表
sel_el = web.find_element(By.XPATH, '//*[@id="OptionDate"]')
# 对元素进行包装, 包装成下拉菜单
sel = Select(sel_el)
# 让浏览器进行调整选项
for i in range(len(sel.options)): # i就是每一个下拉框选项的索引位置
sel.select_by_index(i) # 按照索引进行切换
time.sleep(2)
table = web.find_element(By.XPATH, '//*[@id="TableList"]/table')
print(table.text) # 打印所有文本信息
print("===================================")
print("运行完毕. ")
web.close()
# 如何拿到页面代码Elements(经过数据加载以及js执行之后的结果的html内容)
print(web.page_source)
其实“无头”的实现很简单,也是通过配置浏览器接口的设置参数,headless就是不显示页面,disable-gpu就是为了节约算力,不去调用gpu资源。
其余代码很明显,按部就班获取XPath,然后拿到对应的数据即可。
这里涉及到一个下拉菜单的知识点,我们先用XPath定位到这个元素,随后用Select接口将其包装成下拉菜单元素就可以让selenium将其识别了,从而进行一系列切换操作。注意切换以后一定要等待几秒钟,否则数据加载不全就完了。
运行发现我们所需要的电影票房记录已经全部按年份拿到了:
运行效果

总结
通过本节学习,我们认识了selenium模块并用它写了五个可完善的实例,让自动化测试工具代替爬虫繁琐的解密抓包等过程,在特定场景下是有奇效的。
版权归原作者 Vec_Kun 所有, 如有侵权,请联系我们删除。