
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于大数据招聘岗位可视化系统
课题背景和意义
对高校毕业生就业情况进 行研究,为求职者提供准确直观的应 聘方案。系统基于Hadoop大数据平台 运行,通过数据采集、数据清洗、数 据分析、数据可视化等步骤,对于主 流招聘网站的招聘信息和相应区域租 房信息进行采集分析,对招聘岗位的 平均薪资、招聘岗位数量,学历工作 经验要求,以及制品区域附近房源价 格等信息,采用数据可视化技术直接 展示,使用协同过滤推荐算法进行精 准推荐。
大数据技术是获取数据价值极为重 要的途径,而招聘大数据能让应聘者更 直观地了解人才市场需求。目前大多数 招聘平台仅具有基础的招聘信息筛选功 能[1],缺乏为求职者进行精准信息推荐 功能,无法提供及时且高质量的招聘信 息。此外,招聘网站都没有关联相应区 域的住房租赁信息,求职者需使用其他 软件进行房租价格和周边配套信息的查 询,因此该系统根据采集的招聘企业所 在地点信息,智能地将附近租房信息推 荐给用户。本文提出一种基于大数据技 术的招聘服务平台,通过数据可视化对 招聘单位的人才需求及招聘区域的租房 信息通过图表展示,旨在为广大在求职 者特别是初出校园的毕业生进行智能就 业推荐服务。
实现技术思路
相关技术
Scrapy是用python实现的为了爬取 网站数据、提取结构性数据而编写的应 用框架。使用Twisted高效异步网络框 架来处理网络通信,其主要由调度器、 下载器、爬虫、实体管道、Scrapy引擎 构成。
借助Scrapy爬虫框架从主流招聘网 站上爬取职位信息和招聘企业信息, 其中职位信息包括职位名称、薪资、 工作经验、学历要求、招聘人数、发 布时间等,招聘企业信息包括企业名 称、行业类型、具体地点(省、区) 等。为了保证数据的准确性,还需对 数据进行去重等操作。
数据清洗技术
Hadoop是Apache公司中一个可 靠、可扩展并且开源的分布式计算软 件。HDFS文件分布式系统是其核心组 件之一,主要用来存储文件,通过统 一的命名空间和目录树来定位文件。 HDFS为Hadoop集群提供了分布式的存 储机制,同时也提供了可线性增长的 海量存储的强大能力.
可视化展示技术
Echarts是一款使用JavaScript实现 的开 源可 视 化 库,可以流畅 地 运 行 在 P C和移动设备上,兼容当前绝大部分 浏览器,底层依赖轻量级的矢量图形库 Z R e n d e r,提供直观、交互丰富、可高 度 个 性 化 定 制的数 据 可 视 化图表,如 ECharts提供了常规的折线图、柱状图、 散点图等,还有用于统计、地理数据可 视化、关系数据可视化、多维数据可视 化的多种图表,并且支持图与图之间的混搭。
智能推荐算法
推荐算法的实现过程一般都要经 过以下几个步骤:首先获取数据,接 着对获取的数据进行清洗,然后使用 处理过的元数据进行数据建模,最后 根据训练的模型产生推荐结果以及计 算推荐系统的相关指标。
(1)提取用户的行为历史数据;
(2)数据预处理,从杂乱的数据 中提取需要的数据,并切分出训练集 和测试集;
(3)获得用户-职位的评分矩 阵,并做相关的统计工作;
(4)用训练集训练模型;
(5)利用测试集对模型指标进行 测试统计;
(6)按照算法的规则,获得前N 个职位向用户进行推荐。
数据采集
台使用Scrapy框架,对主流 招聘网站和租房网站进行数据采集, 如前程无忧、链家网等,对网站中的 职位名称、薪资、工作经验、学历要 求、招聘人数、发布时间等信息,以 及招聘企业名称、行业类型、具体地 点等信息进行爬取。数据采集流程为先通过HTTP库 向目标站点发起请求,也就是发送一 个Request,请求可以包含额外的头部 信息编写。如果服务器能正常响应, 返回正确的网站信息,会得到一个 Response,Response的内容便是所要 获取的页面内容。分析返回信息,可 以用Xpath解析处理,页面解析库进行 解析,然后开始采集数据并存入到数 据库的相应表中,直到采集了规定的 页数为止。
数据清洗
数据清洗是对于字段的处理,将 具有空字段的数据剔除,将一些需要 被SQL调用的数据从String类型改为int 或float类型,将一些不符合规则的字 段,按照清洗规则统一等。数据清洗的流程为:先打开待 清洗的数据,将本地数据库文件导出 为csv格式文件并通过sftp上传到服务 器,在服务器上操作HDFS将文件上 传到HDFS,Spark访问时会直接访问 HDFS上的文件,将源数据的第一行标 题去除,判断源数据字段数据是否满 足10个字段,如果不满则数据存在空 值,作为脏数据剔除。以岗位薪资为 例,可判断薪资字段是否包含“-”与 “、”,如果不包含则作为脏数据剔 除掉;对于薪资格式进行统一,把所 有薪资格式替换成元/月,把薪资一栏 变成最低工资,最高工资重新排列, 将数据保存,导入数据库。
数据分析
数据分析是对于数据可视化的 需求进行分析,并且编写SQL语句查询 数据,提取出所需要的数据。即根据 对最终呈现数据的字段要求,编写相 应SQL语句,如展示某城市各区某岗位 的招聘数,需编写查询语句,如查询 结果符合要求,则保留SQL并将查询结 果交付后端。
可视化展示
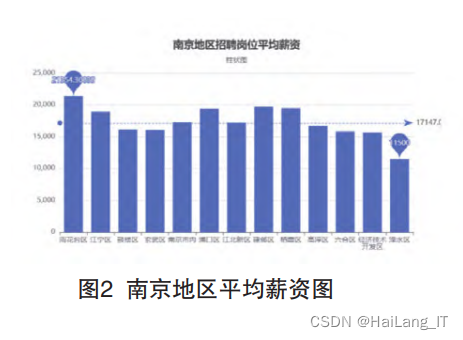
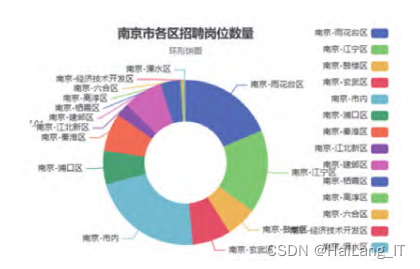
数据可视化分为后端调用和前端 展示两个方面,后端调用采用Spring Boot框架,对于MySQL数据库进行访 问,SQL查询采用Mybatis-plus插件简 化查询代码,然后根据查询结果编写 相对应的接口以供前端调用,后端数 据检测采用postman对于接口提供的数据进行核实;前端展示采用了Vue的框 架,展示内容分为详细信息展示与大 数据图表展示两个模块,通过Echarts 组件将数据库信息通过图表展示出 来,其中包括南京地区平均薪资展 示、地区招聘岗位数量展示等功能, 展示图表类型包括柱状图、饼图、雷 达图、南丁格尔玫瑰图、环图等。
实现效果图样例
我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!
最后
版权归原作者 HaiLang_IT 所有, 如有侵权,请联系我们删除。