
spark安装
IP
192.168.42.121
192.168.42.122
192.168.42.123
映射名
master
slave1
slave2
- 1.用xftp上传spark压缩包到/usr/local/src/中,解压到此目录中,
tar -zxvf spark-2.3.1-bin-hadoop2.7.tgz

2.改名为spark
mv spark-2.3.1-bin-hadoop2.7 spark

3.将spark-env.sh.template配置模板文件复制一份并命名为spark-env.sh
cp spark-env.sh.template spark-env.sh

4.修改spark-env.sh文件,在该文件最后位置添加以下内容:(其中的master是主机映射的IP)
#配置java环境变量
export JAVA_HOME=/usr/local/src/jdk1.8
#指定master的IP
export SPARK_MASTER_HOST=master
#指定Master的端口
export SPARK_MASTER_PORT=7077

修改配置文件
复制slaves.template文件,并重命名为slaves
cp slaves.template slaves
修改spark-env.sh文件,在该文件添加以下内容:通过“vi slaves”命令编辑slaves配置文件,主要是指定spark集群中的从节点IP,由于在hosts文件中已经配置了IP和主机名的映射关系,因此直接使用主机名代替IP,添加内容如下:

slave1
slave2

分发文件
修改完成配置文件后,将spark目录分发至slave1和slave2节点
scp -r /usr/local/src/spark/ root@slave1:/usr/local/src/spark
scp -r /usr/local/src/spark/ root@slave2:/usr/local/src/spark
启动spark集群
切换到spark目录(usr/local/src/spark)
sbin/start-all.sh

master集群进程

Slave1集群进程
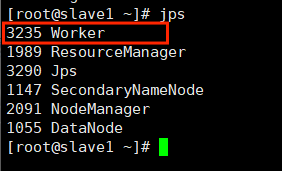
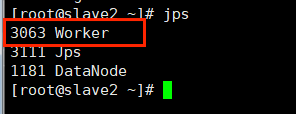
Slave2集群进程

HA高可用
原理:
Spark standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着master单点故障的问题?
如何解决这个问题呢?Spark提供了两种方案:
- 基于文件系统的单点恢复(Single-Node Recovery with Local File System)只能用于开发或测试环境。
- 基于zookeeper的Standby Master(Standby Master with Zookeeper)可用于生产环境
配置HA
首先启动一个Zookeeper集群,然后在不同节点上启动master,注意这些节点需要具有相同的zookeeper配置。
先停止spark集群(**/usr/local/src/spark/sbin**下)
stop-all.sh

在master节点上配置:
vi /usr/local/src/spark/conf/spark-env.sh
注释掉master配置

继续在里面添加内容
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=master:2182,slave1:2181,slave2:2181
-Dspark.deploy.zookeeper.dir=/spark"

分发配置文件到slave1和slave2


启动zk集群
zkServer.sh start
在master节点上启动spark集群
start-all.sh
在slave1节点中启动master:要加上“./”
./start-master.sh
注意:
在普通模式下启动spark集群,只需要在主节点上执行start-all.sh就可以了
在高可用模式下启动spark集群,先需要在任意一台主节点(master)执行start-all.sh,然后再另外一台主节点(slave1)单独执行start-master.sh
master节点上是ALIVE


Slave1上是STANDBY



关闭master节点上的master进程,或者通过jps查看master进程端id,在杀死它,任选一种即可。
1.杀死master节点master进程端口id

2.停止master节点的master进程
./stop-master.sh


刷新slave1的web界面,显示成ALIVE

再次启用master节点的master进程,显示master节点是STANDBY

启动spark的命令是(在usr/local/src/spark中):
./bin/spark-shell

版权归原作者 大大柚子 所有, 如有侵权,请联系我们删除。