
前言
es是大数据存储的必备中间件之一,通过flink可以读取来自日志文件,kafka等外部数据源的数据,然后写入到es中,本篇将通过实例演示下完整的操作过程;
一、前置准备
1、提前搭建并开启es服务(本文使用docker搭建的es7.6的服务);

2、提前搭建并开启kibana服务(便于操作es的索引数据);
3、提前创建一个测试用的索引
PUT test_index
注意点:
使用docker搭建的es,可能会出现创建完毕索引后,插入数据报错的问题,即提示无操作权限的问题,如果出现这个问题,请执行下面的这段,否则在运行flink代码的时候也会报错;
PUT _settings
{
"index": {
"blocks": {
"read_only_allow_delete": "false"
}
}
}
二、编写程序
1、导入基础的pom依赖
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
<dependency>
<groupId>com.alibaba.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>1.2.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.75</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<!--新引入的包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch7_2.11</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.11.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>1.12.0</version>
</dependency>
</dependencies>
2、准备一个外部文件用于程序读取
csv 文件内容如下

3、核心程序代码
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction;
import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
import org.apache.flink.streaming.connectors.elasticsearch7.ElasticsearchSink;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.Requests;
import java.util.ArrayList;
import java.util.HashMap;
public class SinkEs {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//从环境的集合中获取数据
String path = "E:\\code-self\\flink_study\\src\\main\\resources\\userinfo.txt";
DataStreamSource<String> inputStream = env.readTextFile(path);
SingleOutputStreamOperator<UserInfo> dataStream = inputStream.map(new MapFunction<String, UserInfo>() {
@Override
public UserInfo map(String value) throws Exception {
String[] fields = value.split(",");
return new UserInfo(fields[0], fields[1]);
}
});
ArrayList<HttpHost> httpHosts = new ArrayList<>();
httpHosts.add(new HttpHost("IP",9200));
ElasticsearchSink.Builder<UserInfo> result =new ElasticsearchSink.Builder<UserInfo>(httpHosts, new ElasticsearchSinkFunction<UserInfo>() {
@Override
public void process(UserInfo element, RuntimeContext runtimeContext, RequestIndexer requestIndexer) {
//具体数据写入的操作
HashMap<String, String> dataSource = new HashMap<>();
dataSource.put("id",element.getId());
dataSource.put("name",element.getName());
//创建请求作为向es写入的请求命令
IndexRequest indexRequest = Requests.indexRequest().index("test_index").source(dataSource);
//发送请求
requestIndexer.add(indexRequest);
}
});
result.setBulkFlushMaxActions(1);
dataStream.addSink(result.build());
env.execute();
System.out.println("数据写入es成功");
}
}
上面代码中涉及到的一个UserInfo对象
public class UserInfo {
private String id;
private String name;
public UserInfo() {
}
public UserInfo(String id, String name) {
this.id = id;
this.name = name;
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
运行上面的程序,观察控制台输出

4、使用kibana查询结果
执行下面的查询语句
GET test_index/_search
{
"query": {
"match_all": {}
}
}
看到下面的结果,说明数据成功写入到es

程序运行过程中的问题总结
本次编写代码向es导入数据时,遇到了2点问题,在此做一下记录,避免后面的踩坑
1、报错截图如下
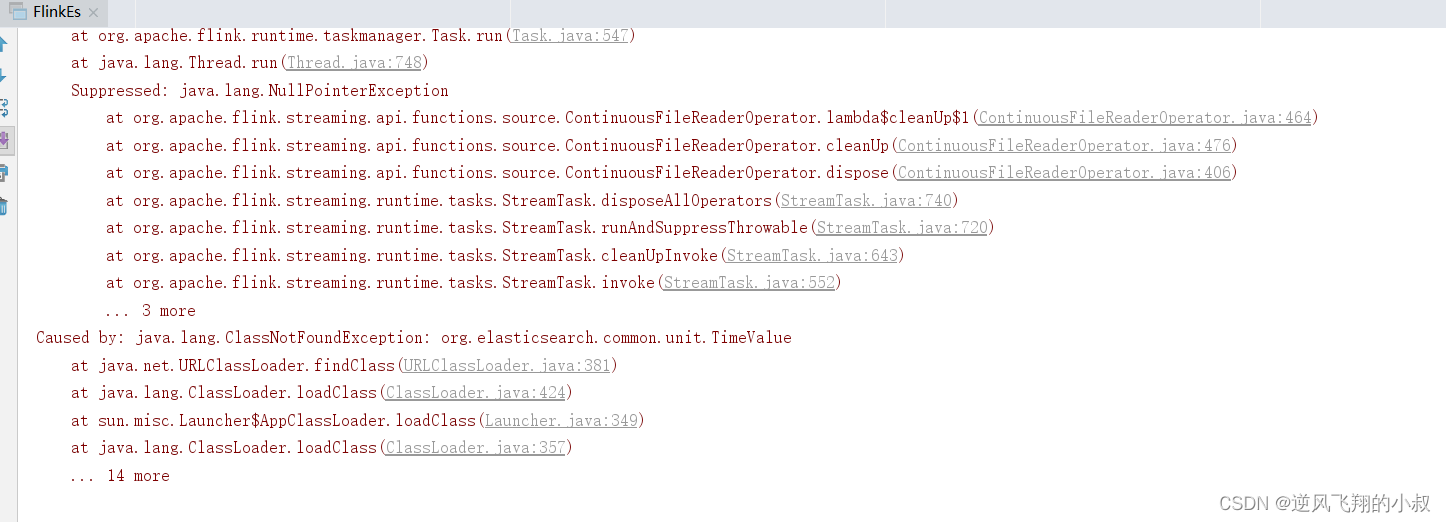
大概的意思是通过flink程序写入到es的时候,时间类型对不上,解决办法是,在程序中添加如下的代码:
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
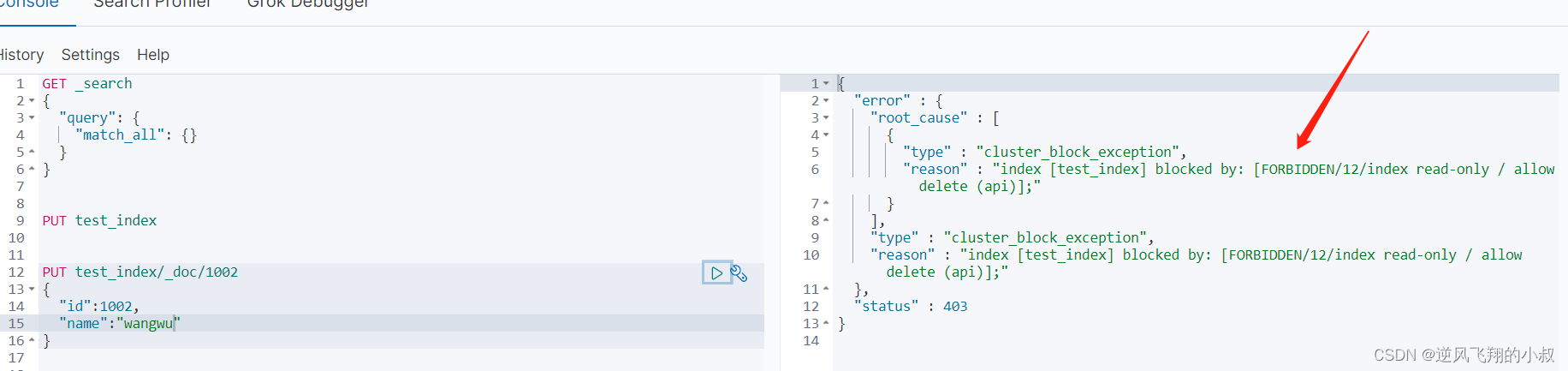
2、报错截图如下
大概的意思是:ElasticSearch进入“只读”模式,只允许删除,网上给出了一些解决方案说是内存不足导致的,但是我设置了好像不行,最后的解决办法就是文章开头说的那样,做一下设置即可,即设置为false;
PUT _settings
{
"index": {
"blocks": {
"read_only_allow_delete": "false"
}
}
}
本文转载自: https://blog.csdn.net/congge_study/article/details/127822270
版权归原作者 逆风飞翔的小叔 所有, 如有侵权,请联系我们删除。
版权归原作者 逆风飞翔的小叔 所有, 如有侵权,请联系我们删除。