

🐼一、TCP协议特点
TCP :Transmission Control Protocol,传输控制协议.
在之前已经介绍过了TCP协议的特点,简单回顾一下:
有连接 可靠传输 面向字节流 全双工
**有连接:**TCP类似于打电话,需要建立连接,才可以发送消息.
**可靠传输:**发送方发送的数据,并不是百分百发送给接收方,而是尽力而为,尽可能的把数据传输过去,同时,如果还是传输不过去,至少能知道.
**面向字节流:**数据传输与文件读写类似,是"流式"的(一次可以读一个字节或者十个字节或者一百个字节)
**全双工:**一个通信通道,可以双向传输.(既可以发送,也可以接收)
🐳二、TCP协议段格式
首先来看一下TCP协议段格式
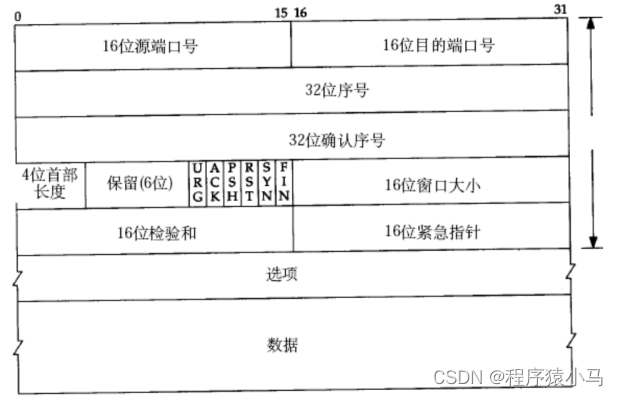
和UDP一样,都是表示源端口和目的端口

任何一条数据都是有序号的,但是确认序号只有应答报文有. (序号和确认序号已经应答报文后面会详细介绍)

** 4位首部长度:**
一个TCP报头长度是可变的,并不是像UDP的报头一样固定8个字节.
因此,首部长度就描述了TCP报头具体多长,另外,选项部分之前的固定是20个字节.
首部长度-20字节 = 选项长度
注:首部长度这里的单位不是字节,而是4字节.
如果首部长度的值是5,此时表示整个TCP报头的长度是 4*5 = 20字节(此时相当于没有选项) 如果首部长度的值是15,此时表示整个TCP报头的长度是4*15 = 60字节(此时相当于选项是40个字节)
保留(6位)
在进行程序开发的时候,其中一个重点考虑的事情就是可扩展性(有些功能现在不需要,以后可能用得到).此处,TCP的保留6位,也是为了以后的扩展来考虑的.
为什么要有保留位呢?
这是因为,对于网络协议来说,扩展升级是一件成本极高的事情.以UDP为例,UDP报文长度是2个字节,因此一个包最大是64kb,现在想要升级一下UDP协议,让它支持更大的长度,比如使用4个字节表示报文长度,理论上是可行的,但是实际操作成本极高.
比如:全世界上百亿能上网的计算机/路由器等等..此时这个设备的操作系统里,就是支持2个字节的UDP,要想进行升级,就需要让这些设备的操作系统都升级为能够支持4个字节的UDP.显然,这样做的成本极高.
如果引入了"保留位",此时升级操作成本就会降低不少,如果后续TCP引入了一些新的功能,就可以使用这些保留位字段,此时,对于原来TCP的报头结构的影响是最小的,老的设备即使不升级也更容易兼容.
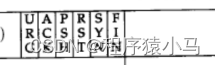
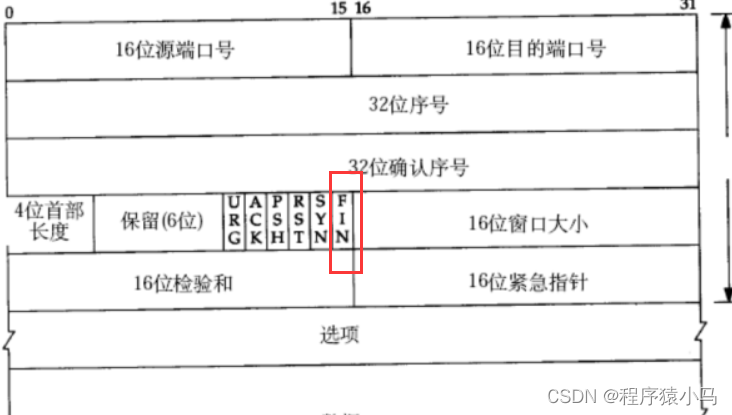
6位标志位:
URG:紧急指针是否有效
ACK:确认序号是否有效,标志位为1表示是应答报文,为0则不是应答报文
PSH:提示接收端应用程序立刻从TCP缓冲区把数据读走
RST:对方要求重新建立连接;我们把携带RST标识的称为**复位报文段 **
SYN:请求建立连接;我们把携带SYN标识的称为**同步报文段 **
FIN:通知对方,本端要关闭了,我们称携带FIN标识的为结束报文段
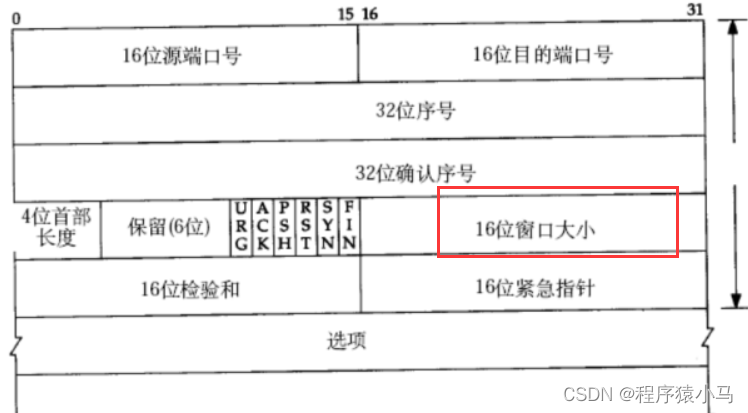
16位窗口大小:
不需要等待就能直接发送的数据的最大的量称为"窗口大小".(后面会详细介绍)
16位校验和:
和UDP的校验和一样,作用都是验证传输的数据是否正确
16位紧急指针:
标识哪部分数据是紧急数据;
选项:
相当于是对这个TCP报文的一些属性进行解释说明.
🐯三、TCP的10个核心机制
接下来,学习一下TCP内部的工作机制.
TCP是一个复杂的协议,里面有很多东西很多机制,这里介绍TCP提供的10个比较核心的机制.
1.确认应答
2.超时重传
3.连接管理
4.滑动窗口
5.流量控制
6.拥塞控制
7.延时应答
8.捎带应答
9.面向字节流
10.异常情况
1.确认应答
以小马给女神在qq发消息为例,解释一下确认应答,以及相关知识点.
故事背景:小马和女神已经认识了很久,互生情愫,只差捅破窗户纸.
有一天,小马打开了和女神的聊天框,拨通了qq电话,女神接通以后,对女神说:女神,你今天的照片口红画歪了.然后女神回了:6

此时,女神回复的"6",就称为"应答报文",也叫做"ack"(acknowledge缩写).
当小马收到"6"这条消息的时候,就可以知道,他发送的消息已经被女神收到了(并没有丢包),
如果隔了一天,女神还没有回消息,那就说明发出的消息大概率丢包了.
TCP进行可靠传输,最主要的就是靠这个确认应答机制:
A给B发送了个消息,B收到之后就会返回一个应答报文(ACK),此时,A收到应答报文之后,就可以知道刚才发的数据成功到达B了.
接下来,考虑更复杂一点的情况:
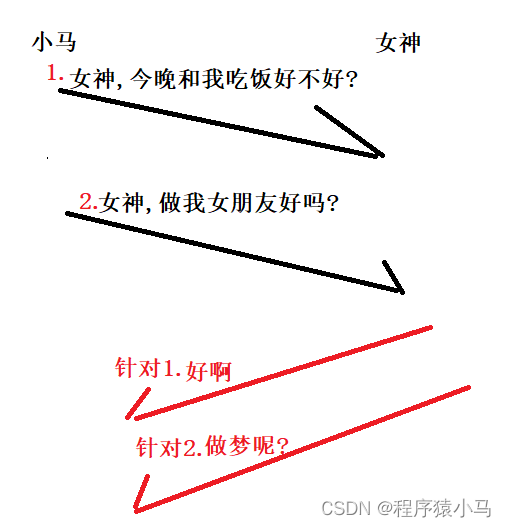
小马蓄谋已久,酝酿了半天,点开和女神的聊天框,发送了第一条消息:女神,今晚和我吃饭好不好.然后又发送了第二条消息:女神,做我女朋友好吗. 然后女神在看到消息之后,**先发送了一条:好啊.然后发送了:做梦呢? 但是,由于网络原因,在小马收到的两条消息中,先接收到了"做梦呢?" 然后又收到了"好啊",**此时,小马的女神梦主观意识上已经成了,但是实际上出现了问题.

这种情况称之为"后发先至",在网络上,可能存在"先发后至",两个主机之间,路线存在多条,数据报1和数据报2走的都是不同路线,数据报1转发路径上的路由器/交换机和数据报2转发路径上的路由器/交换机也不一样,此时,这俩数据报到达顺序会有变数.
网络上后发先至这个现象是客观存在的,无法避免的,因此,应答报文到达的顺序也是有变数的,此时就需要考虑如何避免这种情况的出现.
那么,如何解决上述"后发先至"的问题呢?
给所有数据都进行编号(传输数据和应答报文)
此时,再来看刚刚的情况:
此时,小马的女神梦主观意识上就泡汤了.
当引入了序号以后,此时就不担心顺序乱了,即使顺序乱了,也可以通过序号来区分当前应答报文是针对哪个数据进行的了.
任何一条数据(传输的数据和应答报文)都是有序号的,但是,确认序号,只有应答报文有(普通报文里确认序号字段里的值无意义).
一条报文是不是应答报文,取决于ACK这个标志位,如果标志位1,就是应答报文,否则不是.
实际上,TCP的序号并不是按照一条两条这样的方式来编号的,TCP是面向字节流的,TCP的序号也是按照字节来进行编号的.
假设A给B发送了一条数据,共100个字节.
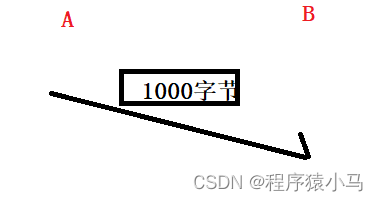
假设字节的序号是从1开始编号,第一个字节编号1,第二个字节2....最后一个字节编号是1000,但是,由于这1000个字节都是属于同一个TCP报文,TCP报头里就只记录当前的第一个字节的序号,也就是说,此处的报头的序号是1.
接下来,如果A要继续给B发送数据,此时第二条TCP数据报的第一个字节序号就是1001,假设长度还是1000字节,此时最后一个字节的序号就是2001,第二条TCP报头里的序号就是1001.
TCP的字节的序号是依次累加起来的,这个依次累加,是基于上一条TCP数据报的最后一个字节的序号,起始字节序号就是上一条TCP数据报的最后一个字节序号+1.
每个TCP数据报报头填写的序号只需要写TCP数据的头一个字节序号即可.
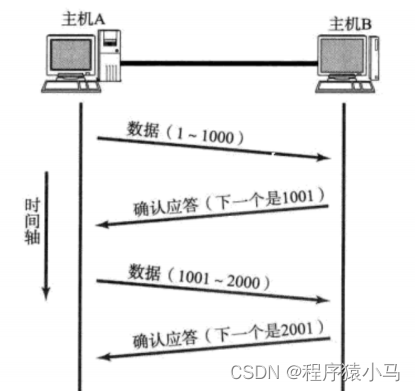
观察上图:应答报文中填写的序号是1001和1002,就是在1000和2000的基础上+1,
针对确认序号是1001的应答报文来说,表示的含义有两个:
1.小于1000的数据都已经确认收到了.
2.主机A接下来应该从1001这个序号开始继续发送.
确认序号的取值,是收到的数据的最后一个字节序号+1.
** 小结:**
TCP可靠传输能力,最主要的就是靠确认应答机制来保证的.
通过应答报文,就可以让发送方清楚的知道数据是否传输成功.
进一步的引入了序号和确认序号,针对多组数据进行详细的区分.
**2.超时重传 **
超过一定时间,还没响应,就重新传输.
确认应答考虑的是数据成功传输的情况,如果数据传输过程中丢包了呢?这就是超时重传机制要解决的问题.
丢包涉及到两种情况:
1).发的数据丢了
2).返回的ack丢了
对于发送方而言,就是没有收到ack,区分不了是哪种情况.此时,就都会认为是丢包了.
丢包是一个概率性问题(通常情况下,丢包的概率是比较小的),因此,如果重新发一下这个数据报,还是有很大的概率传输成功的.
因此,TCP就引入了重传机制,在丢包的时候,就要重新发送一次同样的数据.
TCP直接引入了一个时间阈值,发送方发送了一个数据之后,就要等待ACK,此时开始即使,如果在时间阈值之内,ack都没有到达,说明此时丢包了.
由于重传机制的引入,这又会带来一个新问题:这会导致接收方重复的消息,可能收到多次.
如下图:
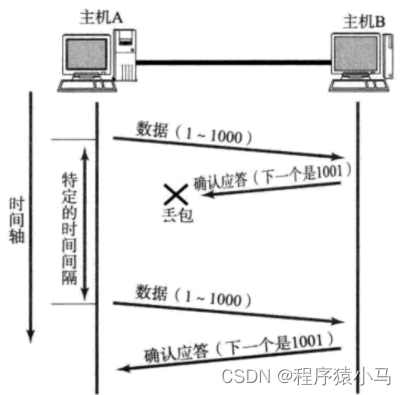
如果这是一个支付请求,造成的影响是非常大的,值得庆幸的是TCP针对这种重复数据的传输,会特殊处理:去重.
TCP存在一个"接收缓冲区"这样的存储空间(接收方操作系统内核里的一部分),每个TCP对应的socket对象都有一个接收缓冲区和一个发送缓冲区.
主机B收到主机A的数据,实际上是主机B的网卡读到了数据,然后将这个数据放到主机B对应的socket对象的接收缓冲区中,这个接收缓冲区可以想象成一个阻塞队列,根据数据的序号,TCP很容易识别出当前接收缓冲区里的两条数据是否重复,如果重复,就将后来的这份数据就直接丢弃.保证了应用系统调用read读取到的数据,一定是不重复的.
TCP使用这个接收缓冲区,对收到的数据进行重新排序,使应用程序read到的数据是保证有序的(和发送顺序一致)
由于去重和重新排序机制的存在,发送方只要发现ack没有按时到达,就会重传数据,即使重复了,顺序乱了,接收方也能很好的处理(去重和排序都依赖TCP报头的序号)
重传的数据是否有可能又丢包了呢?
答案是有可能的.因此超时重传可能会重传多次,重传的次数也并非很多次,这是因为,当重传几次都没传过去,再重传也就意义不大了.
假设一次丢包的概率是10%,传输成功的概率是90%,如果第一次丢包,第二次重传也丢包的概率是1%,第三次重传又丢包的概率是0.1%.连续重传都丢包的概率是非常低的.
因此,重传达到一定的次数,就不会重传了,会认为网络出现故障.接下来,TCP会尝试重置连接(相当于断开重连一样),如果重置还是失败,就彻底断开连接了.
小结:
TCP的可靠传输就是靠确认应答和超时重传来进行体现的.
其中确认应答描述的是传输顺利的情况,超时重传描述的是传输出现问题的情况.
这两者相互配合,共同支撑整体的TCP可靠性.
注:
TCP的可靠性是通过三次握手来保证的,这句话是错误的!!!!!!!
三次握手与TCP的可靠性有关,但是起到的效果是与超时重传和确认应答相比是微乎其微的.
3.连接管理
先来解释一下连接管理:
TCP建立连接

** 当这两部分信息都被维护好以后,此时连接就有了,此时,也把保存这部分信息的这个空间(数据结构)称为**连接
断开连接:A和B将自己存储的连接信息(数据结构)删了,此时连接就断开了.
管理:描述了连接如何建立,如何断开
TCP建立连接的过程是:三次握手
TCP断开连接的过程是:四次挥手
由于三次握手和四次挥手比较重要,博主放到第四部分重点介绍.
** 4.滑动窗口**
确认应答 超时重传 连接管理 都是给TCP的可靠性提供支持.
引入了可靠性,其实付出了代价,会降低传输效率.
TCP会在保证可靠的基础上,尽可能的提高传输效率(尽量降低效率的折损)
对于基本确认应答的情况来说,每次发一个数据,都需要等,等ack到了再发下一个.

滑动窗口的本质就是不等待的批量发送一批数据,然后用一份时间来等待这一组数据的多个ack.
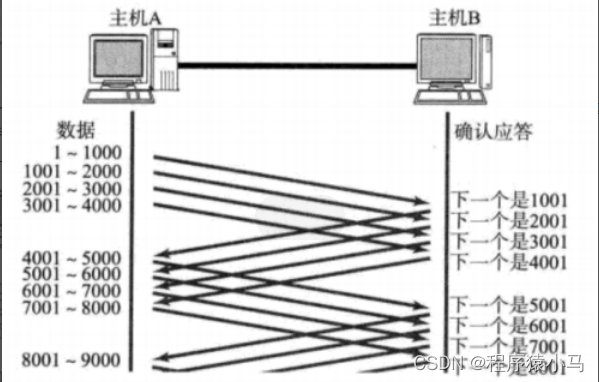
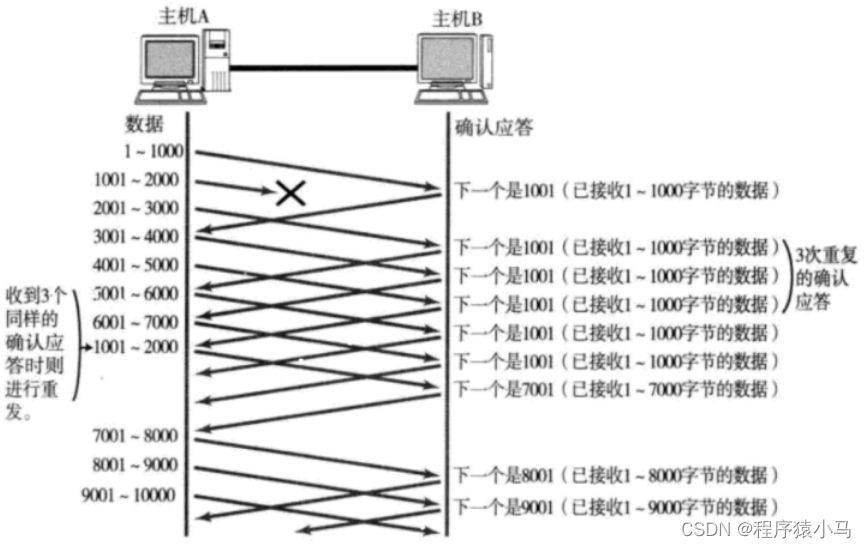
把不需要等待就能直接发送的数据的最大的量称为**"窗口大小"**.
图中的窗口大小就是4000.

** 当批量发送了窗口大小的数据之后,发送方就要等待ack了,并不是等待所有的ack都到达才继续往下发数据,而是收到一条ack,然后发送一条数据,这样就保证了此处等待的ack始终都是固定的值.**
比如上图,当发送了窗口大小4000的数据,然后开始等待,收到一条ack以后,继续往下发数据,但是等待的ack始终是4条.

观察上图来理解"滑动":
主机A 本来等待的是ack是1001 - 5000 ,接下来收到了2001这个ack,这说明之前的数据( 1001 -2000) 的数据已经确认收到了,此时就立刻发送5001 - 6000的数,此时意味着等待ack的范围是2001-6000.窗口大小始终是4000,但是等待的ack一直在向后滑动.
设想一下,如果上述发生丢包的情况下,该如何处理?
1.如果ack丢了
如果丢失一部分ack,不需要做任何处理,丢了就丢了,不会有任何影响.
** 理解这里的确认序号的含义****:**
确认序号表示:该序号往前的所有数据都已经确认到达了.
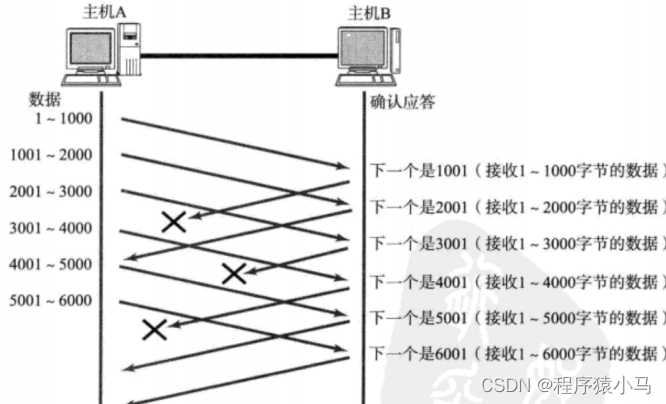
比如上图中:1001这个ack丢了,但是2001这个ack没丢,2001表示:1-1000 和 1001-2000的数据都到达了.2001这个ack其实涵盖了上一个1001这个ack.
实际上,这里的ack并不是老老实实的全部都发的,可能会故意少发一部分(并不影响可靠性,同时节省系统资源),但是不至于全部丢完ack.
2.如果发的数据丢了.
由于1001-2000丢包了,接下来2001-3000到达主机B后,B给A返回的ACK确认序号仍然是1001,意思就是在索要1001开头的数据.接下来的几个数据,B返回的ACK确认序号都是1001,此时,A收到3个同样的确认序号,于是对1001-2000的数据开始重传.接下来,由于2000-7000的数据B都已经收到了,B会开始索要7001开头的数据.
上述丢包重传的方式,叫做**"快速重传".**
可以视为是"超时重传"机制在滑动窗口下的变形.
如果当前传输数据密集,按照滑动窗口的方式来传输,此时按照快速重传来处理丢包.
如果当前传输数据稀疏,不再按照滑动窗口方式了,此时按照之前的超时重传来处理丢包.
5.流量控制
这是一种干预发送的窗口大小的机制.
滑动窗口,窗口越大,传输效率就越高(一份时间等的ack就多了),但是,窗口的大小不能无限大.
这是因为:
1).完全不等ack,可靠性的保障就会出现问题.
2).窗口太大也会消耗太多的系统资源,
3).发送方发送的太快,接收方可能处理不过来,此时发了也白发.
流量控制要做的工作就是第三点,根据接收方的处理能力,协调发送方的发送速率.
如何衡量接收方的处理能力呢?
直接看接收方的接收缓冲区的剩余大小!!.
每次主机A给主机B发送个数据,B就需要计算一下接受缓冲区的剩余大小,然后把这个值,通过ack报文返回给A,A就根据这个返回的值决定接下来的发送速率是多少,也就是窗口大小是多少.这个窗口大小也就是之前TCP报文结构报头中的窗口大小(报文是ack的时候,才有效)
** 16位窗口大小,并不是意味着,窗口的大小最大是64Kb.TCP为了让窗口更大,在选项部分引入了窗口扩展因子.**
比如窗口的大小已经是64kb,窗口扩展因子中写了个2,意思就是让 64kb << 2 = 256kb
** 发送方的窗口大小并不是固定的,而是随着传输过程的进行,动态调整的.**
当窗口大小为0的时候,发送方就要暂停发送数据,开始等待ack,在等待ack的过程中,会给B发送窗口探测报文,这个报文不具备任何业务逻辑,只是为了触发ack查询窗口大小.

6.拥塞控制
** 流量控制和拥塞控制共同决定了发送方的窗口大小是多少.**
流量控制:考虑的是接收方的处理能力.
拥塞控制:描述的是传输过程中中间节点的发送能力.
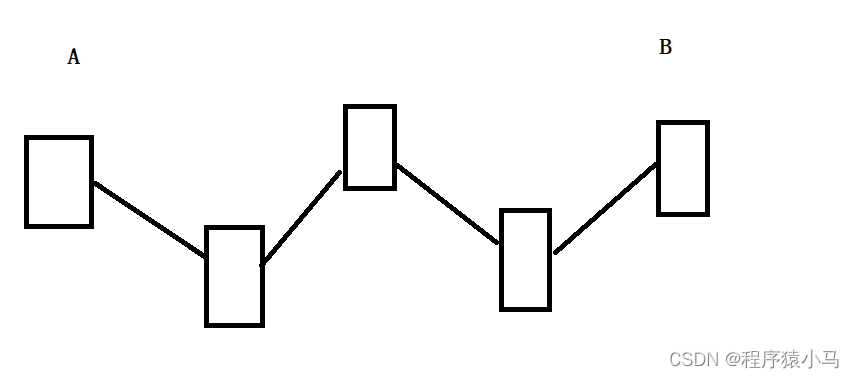
在数据传输过程中,有很多个节点,如上图.在介绍流量控制的时候,只考虑了接收方和发送方,但是没有考虑中间节点.
如果要考虑数据传输的效率,就不能忽略中间节点的发送能力.
类似于木桶效应,一个木桶的储水能力,取决于最短的木块,而非最长的木块.
接收方的处理能力,好量化衡量,但是,中间节点却不好衡量.
于是,设计TCP的大佬们就通过"实验"的方式,来测试出合适的值.
简而言之,就是在危险的边缘跃跃欲试(丢包的边缘)
初始阶段,由于初始窗口比较小,每一轮不丢包都会使窗口扩大一倍(指数增长),当增长速率达到阈值之后,此时指数增长就成了线性增长,增长的前提是不丢包.
接下来,传输过程丢包了,说明此时的发送速率已经接近网络极限了,此时就把窗口大小缩小成很小的值,然后重复上面指数增长和线性增长的过程.
拥塞窗口不是一个固定的值,而是一直动态变化的,随着时间的推移,逐渐达到一个动态平衡的过程.

拥塞窗口和流量控制的窗口,共同决定了发送方实际的发送窗口(拥塞窗口和流量控制窗口的较小值)
** 7.延时应答**
延时应答也是提高效率的机制,也是基于滑动窗口做一些处理.
延时应答是接收方在收到数据以后,不是立即返回ACK了,而是等待一段时间再返回.
在等待的这段时间里,接收方的应用程序就能够把接收缓冲区的数据给消费一些,这样接收缓冲区剩余空间就更大了.

实际上,延时应答采用的方式,就是在滑动窗口的方式下,ack不再每条数据都返回了,比如上图:隔一条返回一个ack.
实际上 剩余空间大小变化是一个复杂的过程,既取决于发送方的发送,又取决于接收方的处理.
8.捎带应答
捎带应答也是提高效率的方式,是在延时应答的基础之上引入的.
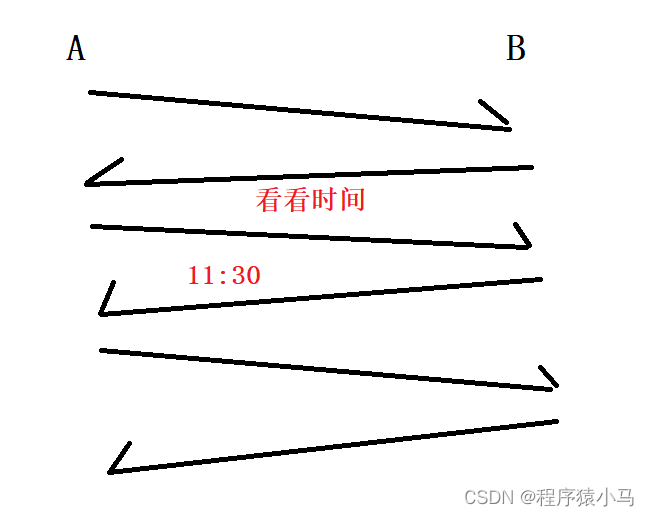
服务器客户端程序,最典型的模型就是"一问一答".
以业务上的请求和响应为例:
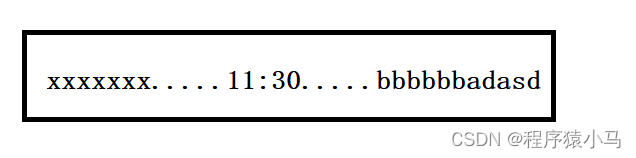
A给时间服务器B发送了一个请求"现在几点了".当服务器B收到了这个请求之后,立即发送一个ack"我看看".
然后一段时候后回复"11:30",这也是个业务上的响应,是在B的应用程序里发送的,于是A收到之后,就会立刻给B返回一个ack"我知道了".

在上图中,红色部分内容都是ack,ack是由系统内核立刻返回的.
** 这个业务上的响应"11:30" 和 "我看看" 本身是不同的时机,但是由于TCP存在延时应答,就导致等待ACK("我看看")的过程中,B就已经要给A发送业务响应("11:30")了,于是就可以让业务数据捎带上这个ACK("我看看")一起发送过去了.**
9.面向字节流
由于TCP是面向字节流的,这引入了一个问题:粘包问题.
比如客户端A和服务器B进行了多次交互.
接收缓冲区将刚刚收到的多个数据报都放到一起了
应用程序read读取的时候,读到哪里才算一个完整的应用层数据报呢?
由于TCP是面向字节流的,一次读一个字节/N个字节都是可以的,这就导致一次读到的数据可能是半个应用层数据报,也有可能是一个应用层数据报,还有可能是多个应用层数据报,把这个问题称之为"粘包问题".

假设接收到上述三条数据,应用层调用read的时候:
如果read的是6个字节,此时就正好读出了 aaaaaa,这是一个完整的应用层数据报.
如果read的是7个字节,此时就读出了aaaaaab,这是"一个半"应用层数据报.
如果read的是5个字节,此时就读出了aaaaa,这是"半个"应用层数据报.
在TCP层次,没有socket api告诉我们应该读几个字节,具体怎么读,取决于程序猿自己.
在传输层可以看到上述是三个不同的数据报,但是应用层看到的是完整的字节流 abc都是连在一起的,所以说,需要在应用层做出区分.
那么,该如何读取到一个完整的应用层数据报呢?
解决方案其实很简单,在应用层进行处理,约定好应用层协议,尤其是明确应用层数据报和应用层数据报之间的边界就好了.方法主要有两个:
1)约定好分隔符
2)约定每个包的长度
比如:在每个应用层数据最前面加上长度.


**10.异常情况 **
传输过程中出现了不可抗力,导致出现下面几种情况.
- 进程崩溃了
- 主机关机(按照正常流程关机)
- 主机掉电
- 网线断开
1)和2) 是一类(正常情况):
1):
进程没了,对应的PCB就没了,对应的文件描述符表就释放了,相当于socket.close()
此时内核会继续完成四次挥手,此时其实仍然是一个正常断开的流程.
2):
主机关机要先杀进程,然后才正式关机(杀死进程的过程中,也是和上面一样触发四次挥手)
3)和4)是一类(非正常情况):
显然来不及挥手.
假设是接收方掉电了,发送方仍然在发送数据,发完数据要等待ACK,ack等不到就超时重传,N次重传也收不到ACK.
重传几次,还没有应答,就尝试重置TCP连接(复位报文段..RST).显然这个重置也会是失败,放弃连接(单方面放弃了)
如果是发送方掉电.
接收方发现没数据了,没数据是发送方挂了还是发送方要等会再发,接收方不知道,就先等待.接收方就要周期性的给发送方发送一个消息,确认下对方是否还工作正常.
接收方发送的这个消息就是心跳包.
心跳包也是一个形象的比喻:1.心跳是周期性的 2.如果心跳无了也就挂了.
心跳包来确认通信双方处在正常的工作状态中.
🐝四、三次握手和四次挥手
1.TCP建立连接:三次握手
通信双方要各自记录对方的信息.彼此之间要认同.
还是以之间小马和女神聊天为例来解释三次握手.
首先,小马对女神表白,女神接受了小马的表白,此时,小马和女神建立了一个认同:女神是小马的枕边人.
但是,要想称为男女朋友,就需要彼此都认同.
此时,女神也对小马表白,小马也接受了,此时,小马和女神又建立了一个认同:小马是女神的枕边人.
这个时候,小马和女神就是男女朋友关系了,相当于连接建立完成.
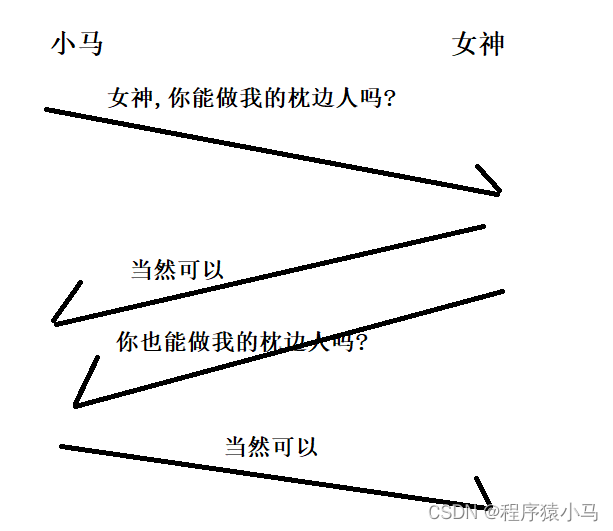
此处,就把上述过程中的每次通信,都称为是一次"握手".
看到这里,提出一个疑惑:上述过程不是四次交互吗?为什么是三次握手?
这是因为:上述过程中确实是进行了四次交互,但是中间两次交互是可以合并成一次的.
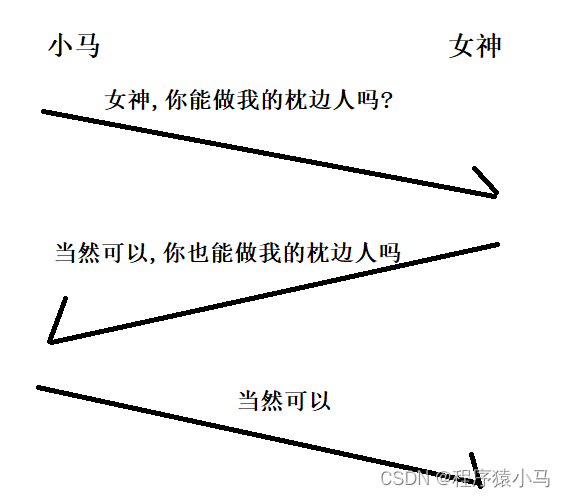
三次握手,本质上是四次交互.
**通信双方要各自向对方发送一个"建立连接"的请求,也要各自向对方回应一个ack.**这里其实一共有四次信息交互,但是,中间的两次交互是可以合并成一次的,因此就构成了"三次握手".
为什么要把中间的两次交互合并呢?不合并行不行?
不行!!必须合并,这里关系到封装分用,封装分用两次一定比封装分用一次的成本更高.
如果是两次握手,能否完成建立连接的过程?
不行!!! 还是以上述小马和女神为例.

如果少了最后一次握手,此时,小马已经知道了:女神是小马的枕边人 小马也是女神的枕边人
但是,女神只知道了:女神是小马的枕边人, 不知道小马是不是答应做她的枕边人,此时,在女神看来,小马可能就是个渣男了.
三次握手另一个重要的作用:
验证通信双方各自的接收能力和发送能力是否正常.
三次握手一定程度上保证了TCP的可靠性,但是起到的作用仅仅只是辅助作用,并不是关键作用.
三次握手的意义:
1).让通信双方各自建立对对方的"认同".(保存对方的信息)
2).验证通信双方各自的接收能力和发送能力是否正常.
3).在三次握手过程中,双方协商一些重要参数.
TCP通信过程中,有些数据需要通信双方相互同步,此时就需要这样的交互过程,恰好可以利用三次握手的机会,来完成数据的同步.
接下来,观察一下TCP建立连接的详细流程图:

客户端是主动的一方,服务器是被动的一方.一定是客户端先向服务器发起"建立连接请求".
客户端和服务器这个身份概念,只是按照主不主动进行区分的,同一个程序,在不同的场景下可能是作为服务器也可能作为客户端.
客户端主动给服务器发送的建立连接请求,称为"SYN"(同步报文段)
也就是之前在TCP报头结构中看到的6个标志位中的一个.

TCP也是有状态的,TCP的状态是很复杂的,要远远超过之前介绍的线程的状态.
下面介绍建立连接阶段的两个重要状态:
1).LISTEN** 服务器的状态**
表示服务器已经准备就绪,随时可以有客户端来建立连接了.
2).ESTABLISHED 客户端和服务器都有
表示连接建立完成,可以进行通信了.
**小结:**三次握手的基本流程图

2.断开连接:四次挥手
"挥手"和"握手"一样,都是形象的叫法,都是客户端和服务器之间的数据交互.
四次挥手和三次握手类似,通信双方各自向对方发送一个断开连接的请求,然后再给一个回应.
还是以小马和女神为例,解释四次挥手:
书接上回,小马和女神在一起以后,突然发现,女神和心中白月光的形象有很大差距,于是,再经过深思熟虑之后,小马决定对女神提出分手,于是对女神说:女神,你不再是我的枕边人了,女神回复:嗯好的,女神对小马失望至极,于是经过一段时间的冷静,也对小马说:你也不再是我的枕边人了,小马回复:好的.
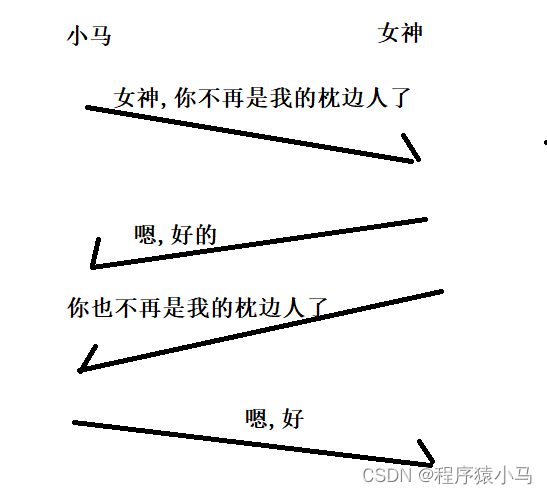
于是呢,小马和女神就从情侣变成了路上,世间好物不坚牢,彩云易碎琉璃脆,小马和女神的恋爱史到此已经结束了.
此时,连接就彻底断开了.
通过观察,会发现,断开连接也是四次信息交互,中间两次也能合并吗?
通常情况下不能(特殊情况下可以)
两个数据发送的时机相同才能合并,如果是不同时机,就不能合并.
三次握手的中间两次能够合并,是因为这两次信息交互是同一时机.
具体来说,**三次握手这三次信息交互过程,是纯内核完成的(**应用程序感知不到,也干预不了)
服务器的系统内核收到syn之后,会立即发送一个ack也会立即发送一个syn
上述是四次挥手的流程图:
FIN是**结束文段 ,**在TCP报头结构的6个标志位中也有
FIN的发起,不是由内核控制的,而是由应用程序调用socket的close方法(或者进程退出) ,才会触发FIN
ack是由系统内核控制的,当服务器收到FIN之后,会立刻返回一个ack.
服务器发送的FIN,只有服务器的应用程序执行到对应的close方法,才会触发FIN,和上面立刻发送的ACK是有一个时间差的,时机不同,通常情况下不能合并.
接下来,通过观察之前写过的基于TCP的简单客户端服务器网络通信程序的代码来加深理解.
(10条消息) 简单客户端服务器网络通信程序_程序猿小马的博客-CSDN博客
观察TCP版本的回显服务器的代码
这里的break决定循环退出,break的原因是因为上面hasNext的结果是false,当流对象读到了EOF(文件结束标记)时,hasNext的结果就是false.
为什么会读到EOF呢?
是因为内核接收到了对方发来的FIN数据报,这里客户端的代码并没有显式的写close,但是当客户端进程退出以后,就会触发socket.close,也就触发FIN.
当循环结束以后,就会执行服务器这里的close操作,此时,服务器就会触发FIN.
在上述代码中,当前循环一结束,就会立即执行close操作触发FIN,此时的ack和FIN之间时间间隔就比较短,此时系统可能就会把这两个合并成一个了.
但是,如果之间间隔比较长,在close之前执行别的工作,比如:睡眠1000ms,此时就无法合并了.
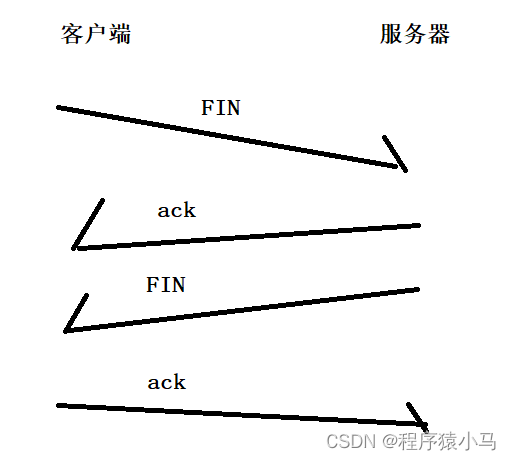
接下来,观察一下断开连接阶段(四次挥手)的详细流程图:
四次挥手也涉及两个TCP的重要状态:
1.CLOSE_WAIT
出现在被动断开连接的一方.
等待关闭(等待socket调用close方法)
建立连接请求一定是客户端先发起的,但是断开连接请求可能是客户端主动发起,也有可能是服务器主动发起.
2.TIME_WAIT
出现在主动断开连接的一方.
TIME_WAIT要保持当前的TCP连接状态不要立即断开.
为什么不立即释放?
这是因为:此时最后一个ack刚发送出去,可能还未到达,万一这个ack丢包了,就没法处理了.于是
TIME_WAIT会等,如果等了一段时间后,还没有收到重传的FIN,此时就认为这个ack已经到达了,然后就彻底释放连接了.
(但是,有没有可能这个重传的FIN恰好也丢包了?有可能!但是这种情况概率比较低,如果真的发生了,就只能自认倒霉了.)
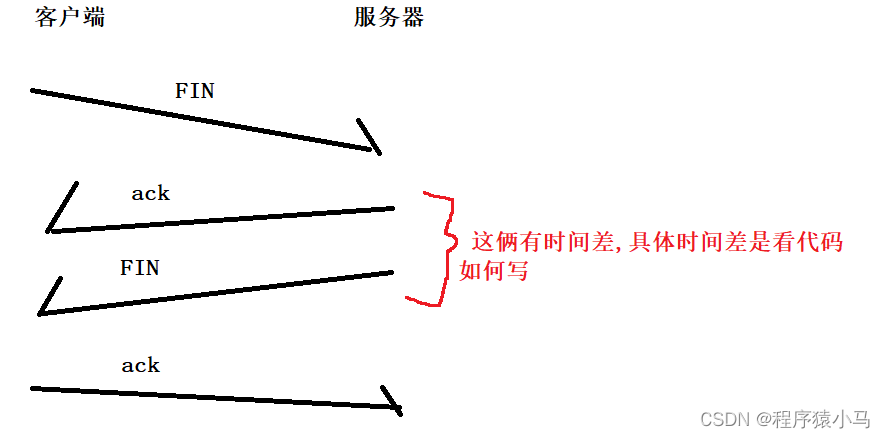



在三次握手和四次挥手的过程中,同样是存在超时重传的.
如果是最后一个ack丢包了,在服务器的角度来看,服务器不知道是因为自己发的FIN丢了,还是ack丢了,所以统一视为是FIN丢了,进行重传操作.
既然服务器可能要重传FIN,那么客户端就要对这个重传的FIN进行ACK响应.很明显,如果直接将TCP连接释放了,这样的ACK就无法进行了,因此,使用TIME_WAIT会保留一段时间,就是为了能够处理最后一个ACK丢包的情况,能够在收到重传的FIN之后,进行ACK响应.
TIME_WAIT保留2MSL,之后就真正释放了.
这个MSL是一个约定时间.指的是互联网上,两个节点之间,数据传输消耗的最大时间,通常情况下MSL的值是60s.
小结:四次挥手的流程图:
版权归原作者 程序猿小马 所有, 如有侵权,请联系我们删除。