
端午假期,夏日炎炎,温度连续40度以上,在家学习Flink相关知识,记录下来,方便备查。
开发工具:IntelliJ Idea
Flink版本:1.13.0
本次主要用Flink实现批处理(DataSet API) 和 流处理(DataStream API)简单实现。
第一步、创建项目与添加依赖
1)新建项目
打开Idea,新建Maven项目,包和项目命名,点击确定进入项目。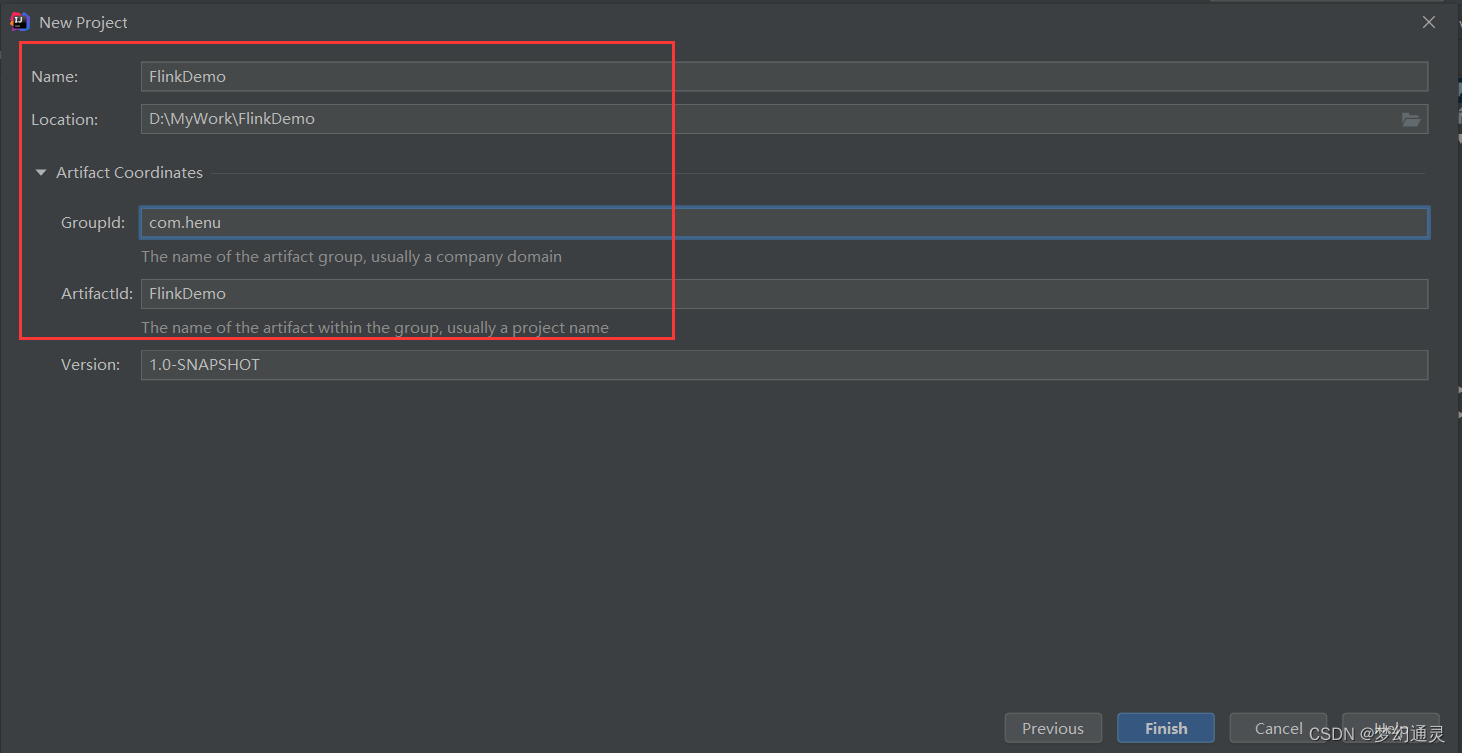
2)引入依赖
在pom.xml文件中添加依赖,即Flink-java、flink-streaming、slf4j等, 可参考以下代码。
<properties><flink.version>1.13.0</flink.version><java.version>1.8</java.version><scala.binary.version>2.12</scala.binary.version><slf4j.version>1.7.2</slf4j.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><!-- 日志--><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-to-slf4j</artifactId><version>2.16.0</version></dependency></dependencies>
3)添加日志文件
在resource目录下添加日志文件log4j.properties,内容如下所示。
log4j.rootLogger=error,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayoutlog4j.appender.stdout.layout.ConversionPattern=@-4r [%t]%-5p %c %x -%m%n
第二步、构造数据集
在项目下新建 input 文件夹,用于存放数据集,在其下新建 words.txt 文件,即测试的数据集,如下图所示。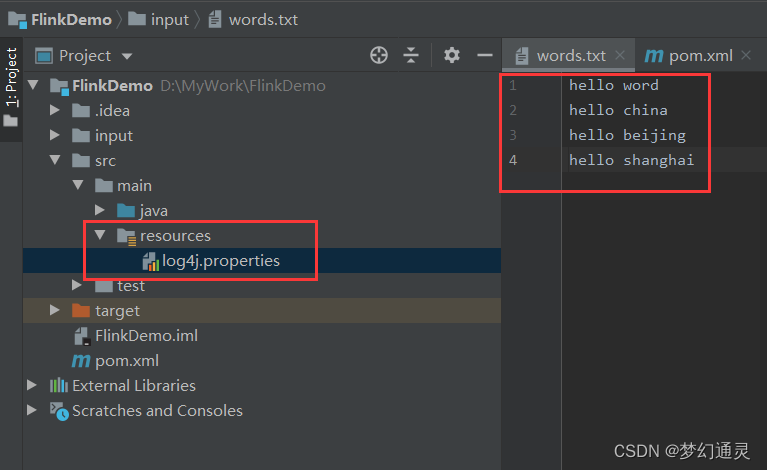
第三步、编写业务代码
读取数据集中内容,并进行单词的字数统计。新建 BatchWordCout 类,引入分6个步骤实现数据集的读取与打印。
方式一、批处理 DataSet API
主要处理步骤为
1)创建执行环境;
2)从环境中读取数据;
3)将每行数据进行分词,转化成二元组类型 扁平映射;
4)按照word进行分组;
5)分组内进行聚合统计;
6)打印结果
批处理 DataSet API 写法如下所示。
importorg.apache.flink.api.common.typeinfo.Types;importorg.apache.flink.api.java.ExecutionEnvironment;importorg.apache.flink.api.java.operators.AggregateOperator;importorg.apache.flink.api.java.operators.DataSource;importorg.apache.flink.api.java.operators.FlatMapOperator;importorg.apache.flink.api.java.operators.UnsortedGrouping;importorg.apache.flink.api.java.tuple.Tuple2;importorg.apache.flink.util.Collector;publicclassBatchWordCount{publicstaticvoidmain(String[] args)throwsException{//1、创建执行环境ExecutionEnvironment env =ExecutionEnvironment.getExecutionEnvironment();// 2、从环境中读取数据DataSource<String> lineDataSource = env.readTextFile("input/words.txt");// 3、将每行数据进行分词,转化成二元组类型 扁平映射FlatMapOperator<String,Tuple2<String,Long>> wordAndOneTuple = lineDataSource.flatMap((String line,Collector<Tuple2<String,Long>> out)->{// 将每行文本进行拆分String[] words = line.split(" ");// 将每个单词转化成二元组for(String word : words){
out.collect(Tuple2.of(word,1L));}}).returns(Types.TUPLE(Types.STRING,Types.LONG));// 4、按照word进行分组UnsortedGrouping<Tuple2<String,Long>> wordAndOneGroup = wordAndOneTuple.groupBy(0);// 5、分组内进行聚合统计AggregateOperator<Tuple2<String,Long>> sum = wordAndOneGroup.sum(1);// 6、打印结果
sum.print();}
控制台打印效果如下图所示。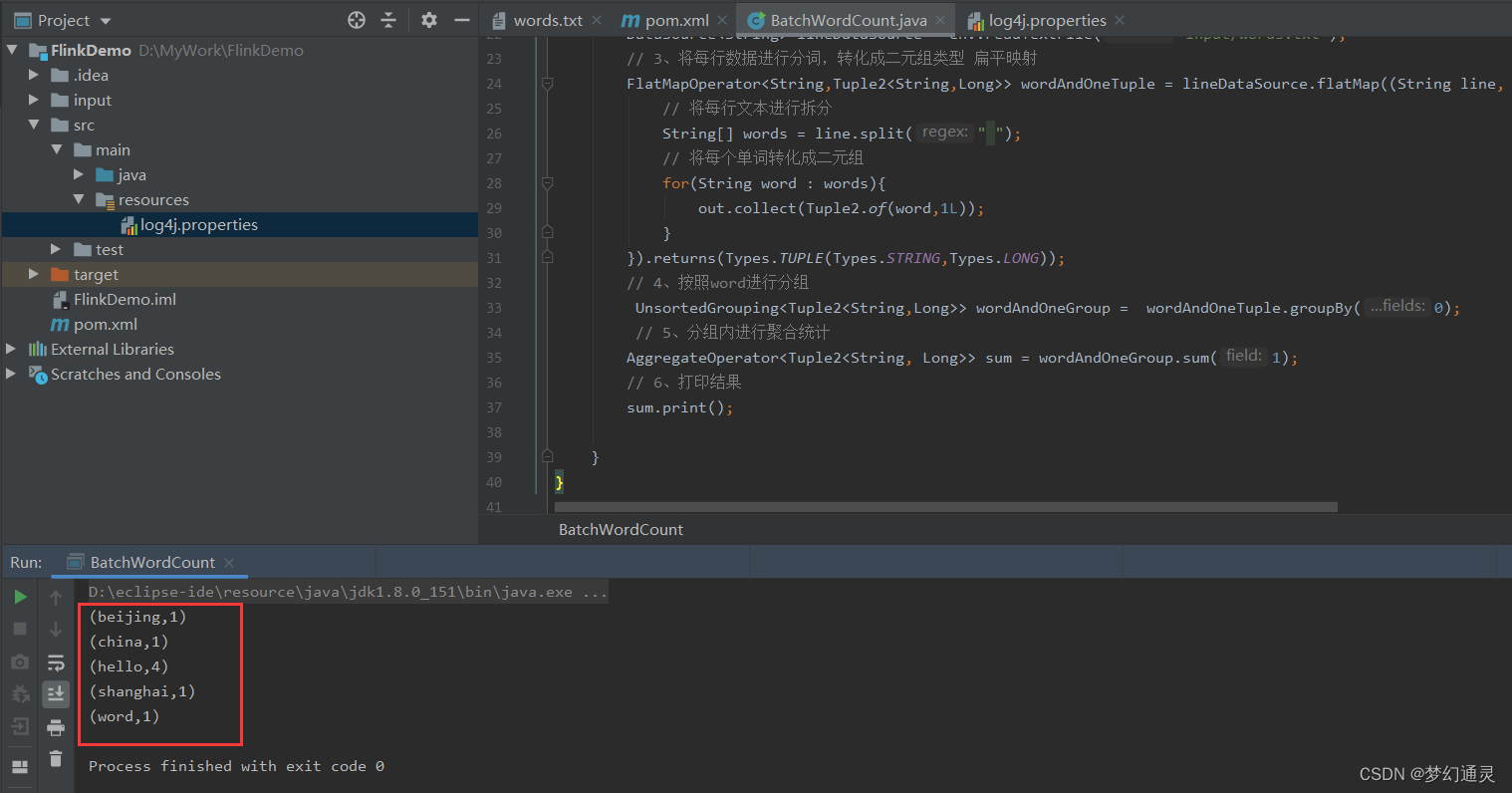
在Flink 1.12 版本后,官方推荐做法是直接使用 DataSet API 即提交任务时将执行模式更改为BATCH来进行批处理
$bin/flink run -Dexecution.runtime-mode=BATCH batchWordCount.jar
方式二、流处理 DataStream API
流处理的处理步骤与批处理流程类似,主要区别是执行环境不一样。
importorg.apache.flink.api.common.typeinfo.Types;importorg.apache.flink.api.java.tuple.Tuple2;importorg.apache.flink.streaming.api.datastream.DataStreamSource;importorg.apache.flink.streaming.api.datastream.KeyedStream;importorg.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.util.Collector;publicclassBatchSteamWordCount{publicstaticvoidmain(String[] args)throwsException{// 1、创建流式执行环境StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();// 2、读取文件DataStreamSource<String> lineDataStreamSource = env.readTextFile("input/words.txt");// 3、转换计算SingleOutputStreamOperator<Tuple2<String,Long>> wordAndOneTuple = lineDataStreamSource.flatMap((String line,Collector<Tuple2<String,Long>> out)->{// 将每行文本进行拆分String[] words = line.split(" ");// 将每个单词转化成二元组for(String word : words){
out.collect(Tuple2.of(word,1L));}}).returns(Types.TUPLE(Types.STRING,Types.LONG));// 4、分组KeyedStream<Tuple2<String,Long>,Object> wordAndOneKeyedStream = wordAndOneTuple.keyBy(data -> data.f0);// 5、求和SingleOutputStreamOperator<Tuple2<String,Long>> sum = wordAndOneKeyedStream.sum(1);// 6、打印结果
sum.print();// 7、启动执行
env.execute();}}
控制台输出结果如下图所示。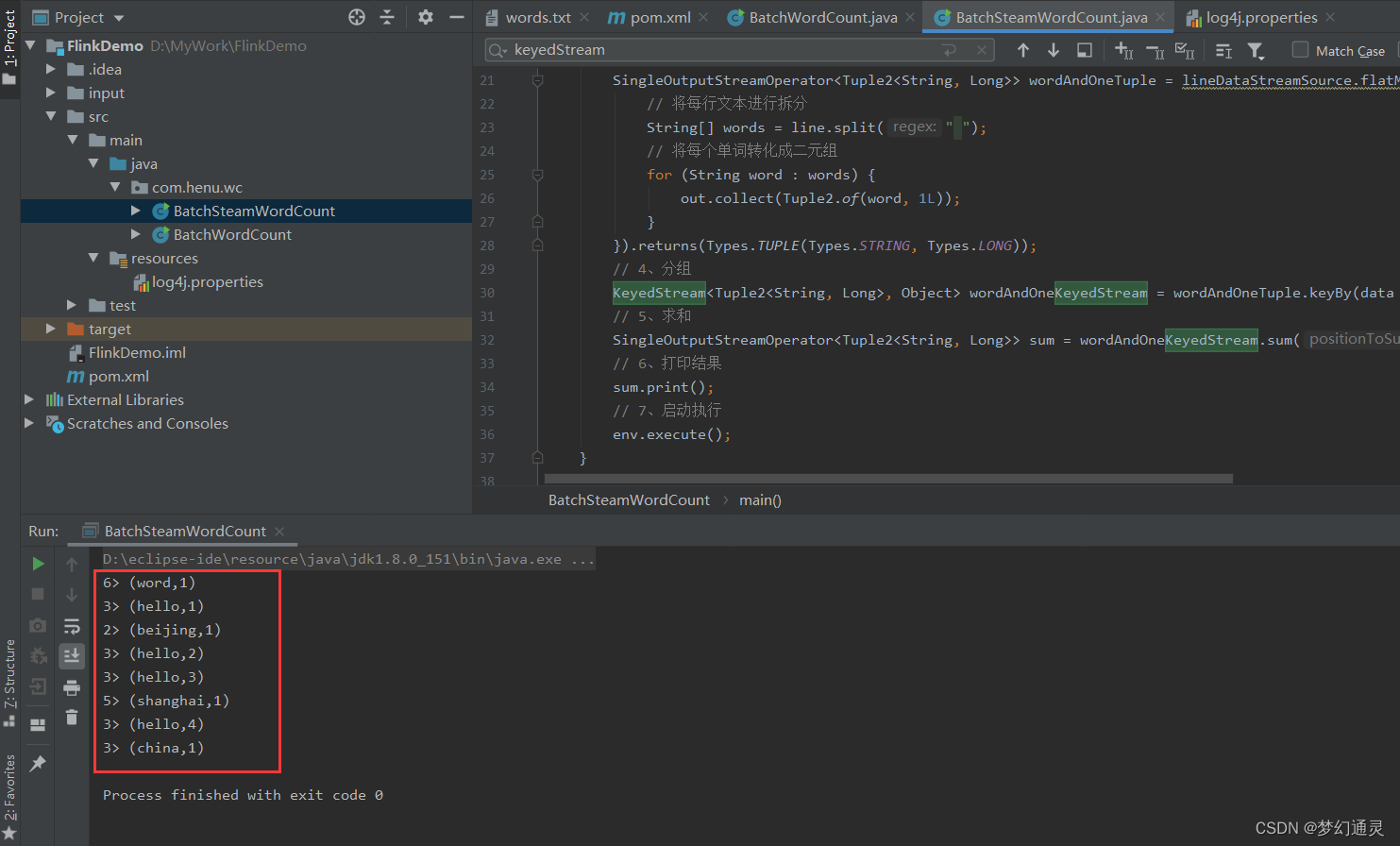
从打印结果可以看出 多线程执行,结果是无序;第一列数字与本地运行环境的CPU核数有关;
参考文档
【1】https://www.bilibili.com/video/BV133411s7Sa?p=9&vd_source=c8717efb4869aaa507d74b272c5d90be
版权归原作者 梦幻通灵 所有, 如有侵权,请联系我们删除。